第三届LitCTFmisc详解
Misc
Cropping
随波逐流伪加密,得到一堆图片,把图片拼接起来
脚本
import os
from PIL import Image
def stitch_tiles_horizontally_with_wrap(tiles_folder, output_file, tiles_per_row=10):
"""
横向拼接图片,达到指定数量后自动换行
参数:
tiles_folder: 包含拼图块的文件夹路径
output_file: 输出拼接后图片的文件路径
tiles_per_row: 每行拼接的图片数量(默认为10)
"""
# 获取所有拼图块文件并按数字顺序排序
tile_files = sorted(
[f for f in os.listdir(tiles_folder) if f.startswith('tile_') and f.endswith('.png')],
key=lambda x: int(x.split('_')[1].split('.')[0]))
if not tile_files:
print("未找到任何拼图块文件(tile_*.png)")
return
# 打开所有图片
images = []
tile_width = 0
tile_height = 0
for file in tile_files:
try:
img = Image.open(os.path.join(tiles_folder, file))
images.append(img)
# 假设所有图片尺寸相同,取第一张的尺寸
if tile_width == 0:
tile_width = img.width
tile_height = img.height
print(f"已加载: {file}")
except Exception as e:
print(f"无法加载图片 {file}: {e}")
if not images:
print("没有有效的图片可拼接")
return
# 计算画布尺寸
rows = (len(images) + tiles_per_row - 1) // tiles_per_row # 计算需要的行数
result_width = tile_width * min(tiles_per_row, len(images)) # 画布宽度
result_height = tile_height * rows # 画布高度
# 创建空白画布
result = Image.new('RGB', (result_width, result_height))
# 开始拼接
for index, img in enumerate(images):
# 计算当前图片应该放在哪一行哪一列
row = index // tiles_per_row
col = index % tiles_per_row
# 计算粘贴位置
x = col * tile_width
y = row * tile_height
result.paste(img, (x, y))
# 保存结果
result.save(output_file)
print(f"拼接完成! 共拼接了 {len(images)} 张图片,排列为 {rows} 行")
print(f"结果已保存到: {output_file} (尺寸: {result_width}x{result_height})")
# 使用示例
if __name__ == "__main__":
tiles_folder = "C:\\Users\\11141\\Desktop\\tiles" # 拼图块所在的文件夹
output_file = "stitched_with_wrap.jpg" # 输出文件
tiles_per_row = 10 # 每行10个图片
stitch_tiles_horizontally_with_wrap(tiles_folder, output_file, tiles_per_row)
扫二维码得flag
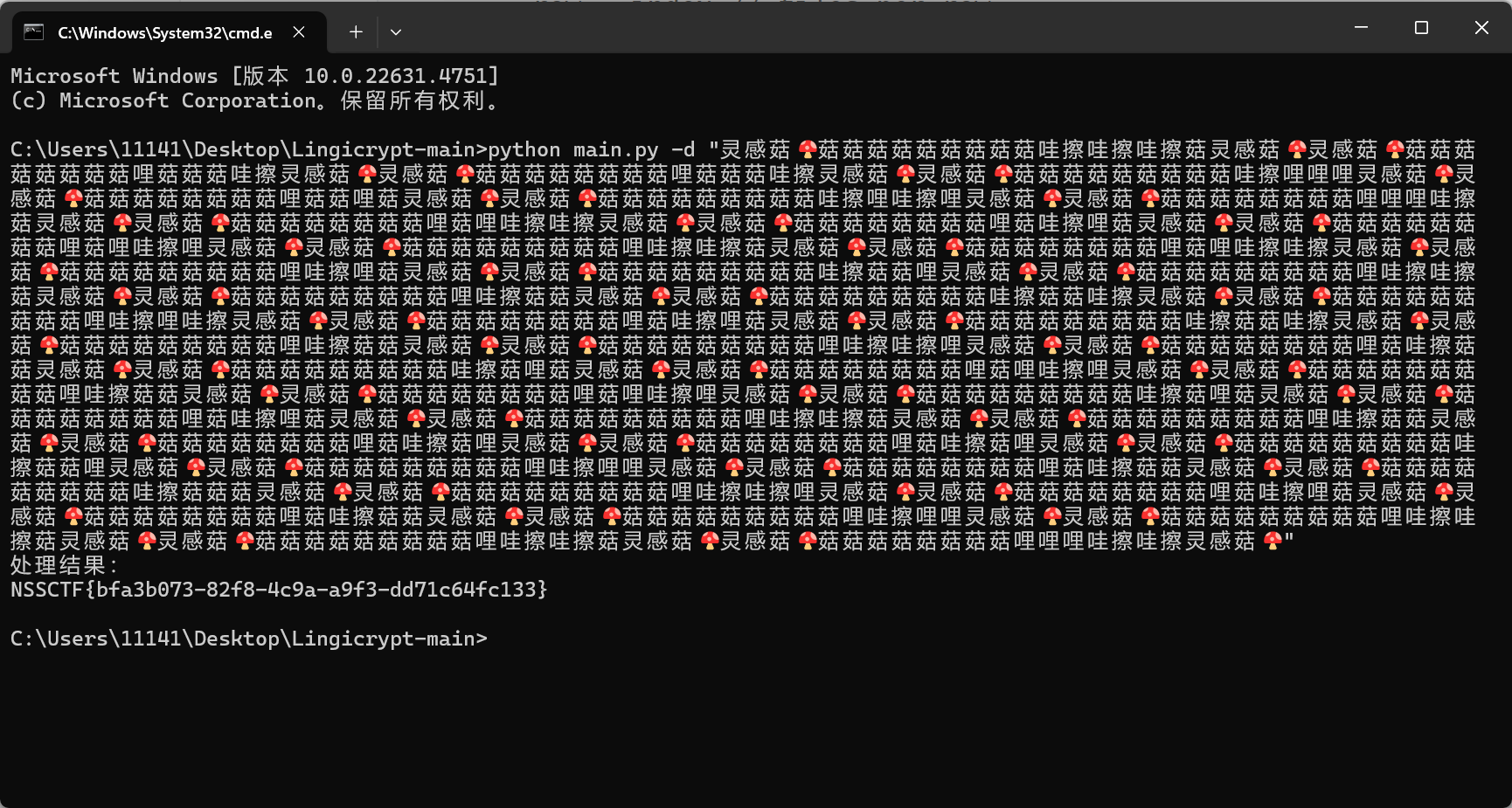
灵感菇🍄哩菇哩菇哩哇擦灵感菇灵感菇🍄
之前在交流群见过,没想到这么快就在比赛见到了
查看源代码,https://github.com/ProbiusOfficial/Lingicrypt
下载解密得flag
问卷题
扫码答题得flag
LitCTF{W3_Need_You_Next_Year==}
消失的文字
下载附件
usb流量一把梭

得到密码
868F-83BD-FF
解压zip得到txt
010发现嵌入隐藏字符

根据名字搜到
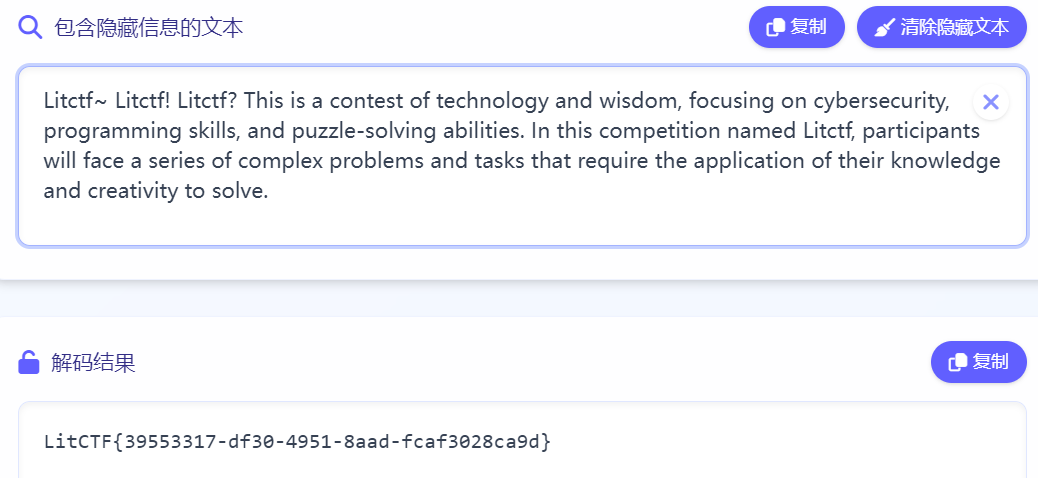
LitCTF{39553317-df30-4951-8aad-fcaf3028ca9d}
像素中的航班
下载图片
我们推理一下,长城杯决赛在4月底,决赛地在福州,litctf主办单位为郑州轻工业大学
搜郑州出发到福州的航班
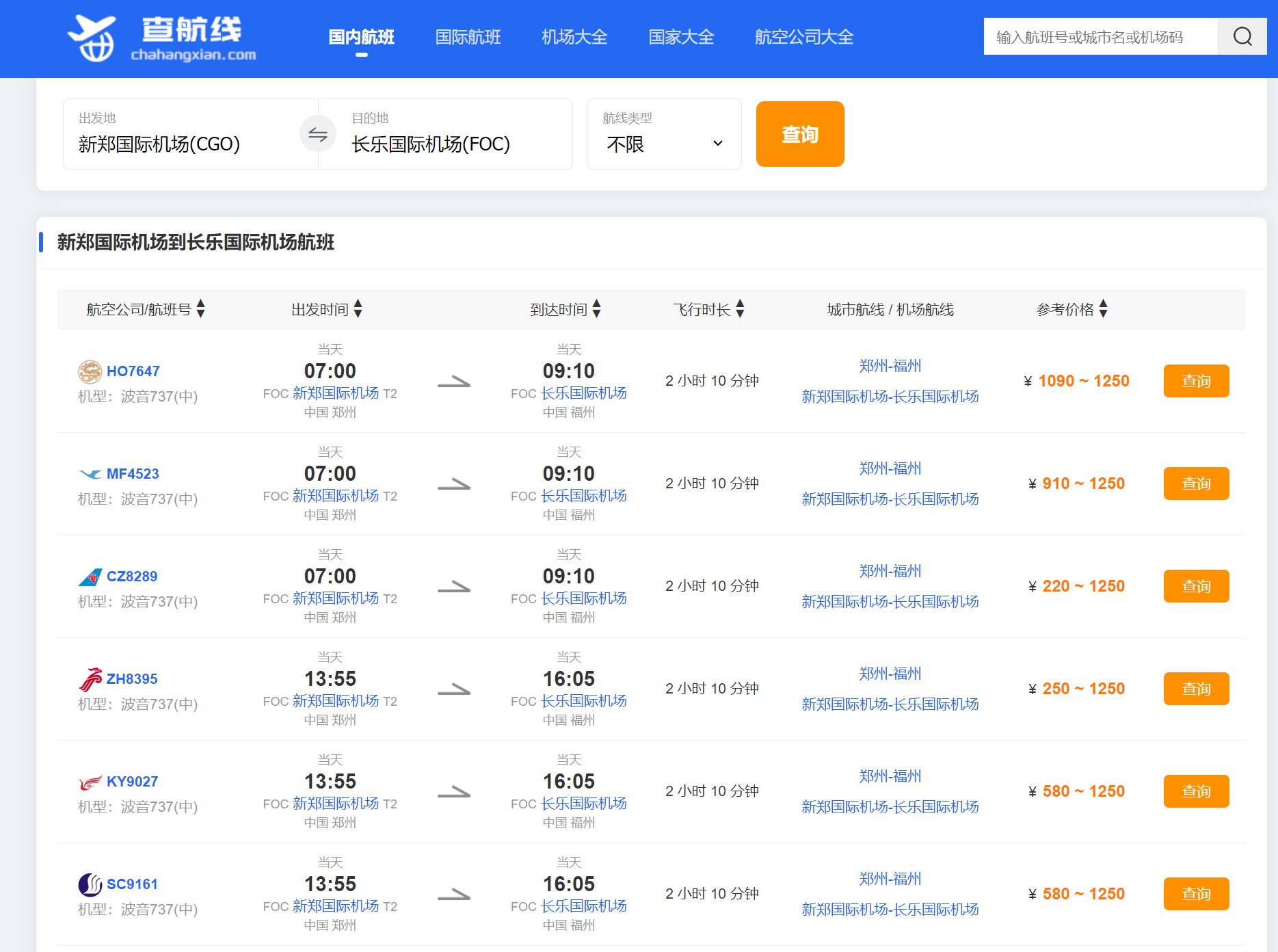
一个一个试,结束
LitCTF{CZ8289}
洞妖洞妖
解压ppt
改为zip后缀并解压,查看vbaPeoject.bin宏代码
工具github地址: https://github.com/decalage2/oletools
pip install -U oletools
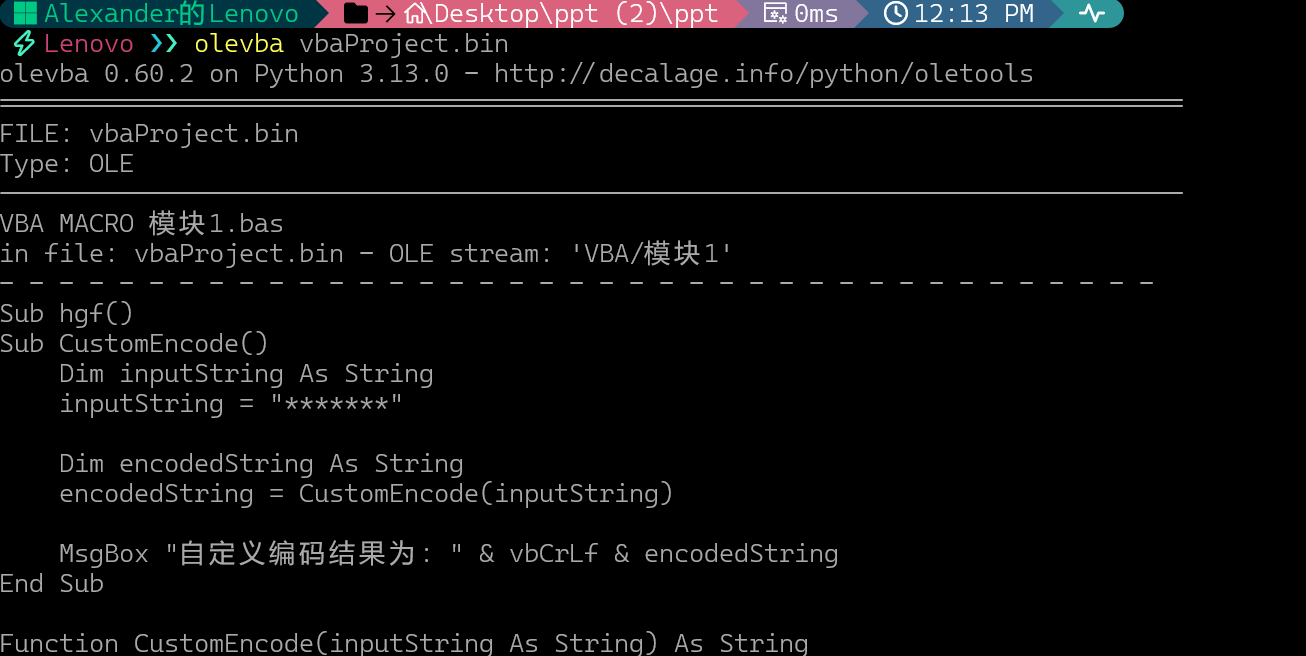
olevba 0.60.2 on Python 3.13.0 - http://decalage.info/python/oletools
===============================================================================
FILE: vbaProject.bin
Type: OLE
-------------------------------------------------------------------------------
VBA MACRO 模块1.bas
in file: vbaProject.bin - OLE stream: 'VBA/模块1'
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
Sub hgf()
Sub CustomEncode()
Dim inputString As String
inputString = "*******"
Dim encodedString As String
encodedString = CustomEncode(inputString)
MsgBox "自定义编码结果为: " & vbCrLf & encodedString
End Sub
Function CustomEncode(inputString As String) As String
Dim charSet As String
charSet = "*******************"
Dim byteArray() As Byte
byteArray = StrConv(inputString, vbFromUnicode)
Dim encodedString As String
encodedString = ""
Dim i As Integer
Dim n As Long
For i = 1 To LenB(byteArray) Step 3
n = 0
n = (n Or (ByteToInt(MidB(byteArray, i, 1)) << 16))
If i + 1 <= LenB(byteArray) Then
n = (n Or (ByteToInt(MidB(byteArray, i + 1, 1)) << 8))
End If
If i + 2 <= LenB(byteArray) Then
n = (n Or ByteToInt(MidB(byteArray, i + 2, 1)))
End If
encodedString = encodedString & Mid(charSet, (n >> 18) + 1, 1)
encodedString = encodedString & Mid(charSet, ((n >> 12) And &H3F) + 1, 1)
If (i + 1) <= LenB(byteArray) Then
encodedString = encodedString & Mid(charSet, ((n >> 6) And &H3F) + 1, 1)
Else
encodedString = encodedString & "="
End If
If (i + 2) <= LenB(byteArray) Then
encodedString = encodedString & Mid(charSet, (n And &H3F) + 1, 1)
Else
encodedString = encodedString & "="
End If
Next i
CustomEncode = encodedString
End Function
Function ByteToInt(byteVal As Byte) As Long
ByteToInt = CLng(byteVal)
End Function
End Function
"5uESz7on4R8eyC//"
+----------+--------------------+---------------------------------------------+
|Type |Keyword |Description |
+----------+--------------------+---------------------------------------------+
|Suspicious|Base64 Strings |Base64-encoded strings were detected, may be |
| | |used to obfuscate strings (option --decode to|
| | |see all) |
+----------+--------------------+---------------------------------------------+
换表base64加密

ppt帧间隔隐写
import os
import re
import argparse
from pathlib import Path
from typing import List, Dict, Set, Optional
import logging
from tqdm import tqdm
def setup_logging(log_file: Optional[str] = None) -> None:
"""配置日志记录"""
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s - %(levelname)s - %(message)s",
handlers=[
logging.FileHandler(log_file) if log_file else logging.StreamHandler()
]
)
def find_slide_files(directory: str, slide_count: int = 456) -> Dict[int, str]:
"""查找并验证幻灯片文件"""
slide_files = {}
missing_files = []
for i in range(1, slide_count + 1):
file_name = f'slide{i}.xml'
file_path = os.path.join(directory, file_name)
if os.path.isfile(file_path):
slide_files[i] = file_path
else:
missing_files.append(file_name)
if missing_files:
logging.warning(f"找不到以下{len(missing_files)}个文件: {', '.join(missing_files[:10])}" +
(", ..." if len(missing_files) > 10 else ""))
return slide_files
def extract_advTm_values(file_path: str) -> Set[str]:
"""从单个文件中提取唯一的advTm值"""
try:
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
# 使用非贪婪匹配确保正确提取每个值
return set(re.findall(r'advTm="(.*?)"', content))
except Exception as e:
logging.error(f"处理文件 {file_path} 时出错: {str(e)}")
return set()
def process_slide_files(slide_files: Dict[int, str]) -> Dict[int, List[str]]:
"""处理所有幻灯片文件并提取advTm值"""
results = {}
# 使用tqdm显示进度条
for slide_num, file_path in tqdm(slide_files.items(), desc="处理幻灯片"):
unique_values = extract_advTm_values(file_path)
if unique_values:
# 排序确保结果一致
results[slide_num] = sorted(unique_values)
return results
def write_results(results: Dict[int, List[str]], output_file: str) -> None:
"""将结果写入输出文件"""
try:
with open(output_file, 'w', encoding='utf-8') as f_out:
# 写入标题行
f_out.write("幻灯片编号, advTm值\n")
# 按幻灯片编号排序
for slide_num in sorted(results.keys()):
values = results[slide_num]
f_out.write(f"slide{slide_num}.xml, {', '.join(values)}\n")
logging.info(f"结果已保存到 {output_file}")
except Exception as e:
logging.error(f"写入结果文件时出错: {str(e)}")
def main():
"""主函数"""
parser = argparse.ArgumentParser(description='从PPT幻灯片文件中提取唯一的advTm值')
parser.add_argument('--directory', default='./slides', help='幻灯片文件所在目录')
parser.add_argument('--output', default='result.csv', help='输出结果文件')
parser.add_argument('--slide-count', type=int, default=456, help='预期的幻灯片数量')
parser.add_argument('--log-file', help='日志文件路径')
args = parser.parse_args()
setup_logging(args.log_file)
# 验证输入目录
if not os.path.isdir(args.directory):
logging.error(f"目录不存在: {args.directory}")
return
logging.info(f"开始处理幻灯片文件,目录: {args.directory}")
slide_files = find_slide_files(args.directory, args.slide_count)
if not slide_files:
logging.error("未找到有效的幻灯片文件")
return
results = process_slide_files(slide_files)
if not results:
logging.warning("未找到任何advTm值")
else:
write_results(results, args.output)
logging.info(f"处理完成。共处理 {len(slide_files)} 个文件,找到 {len(results)} 个包含advTm值的文件")
if __name__ == '__main__':
main()

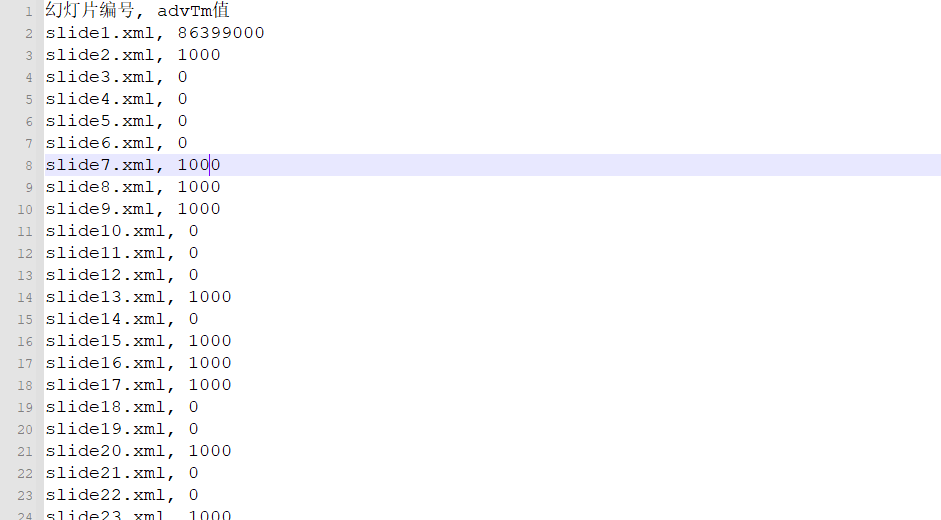
把1000替换成1,0不变,组成二进制数据
10000111000101110010011000111110111111011010110101110101100111011011011101100110101110010101110100111001111100101110001110000110101100111001011001101111010110111100001011110101111001111100001101100110101011010010110011011000101011110001101110000011000011011100101011100110110011001001011110101011010011001000110011111001101000100100000111000101010101110010110101001010011100111110100101010001101000011011111001001110100010001110111000011001001100010101111
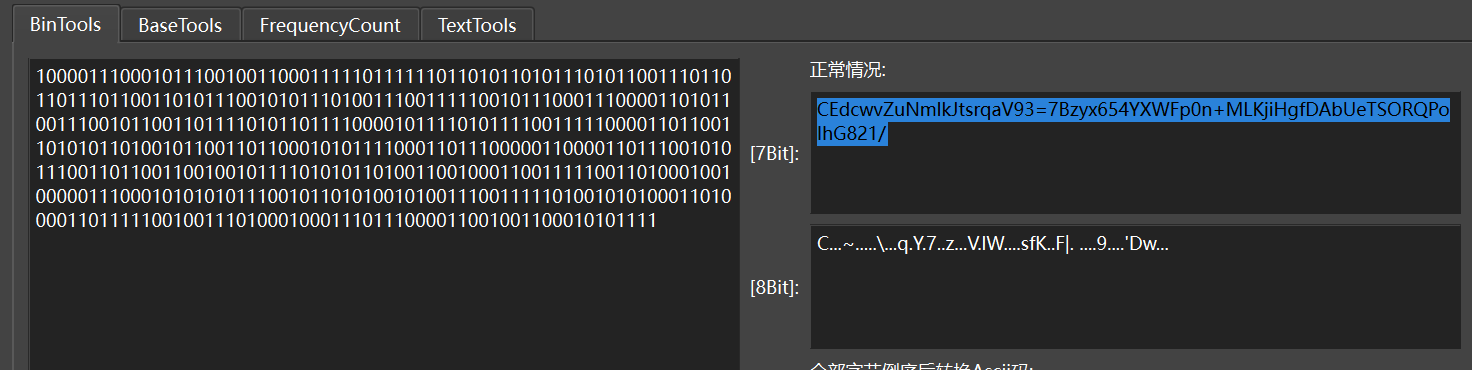
CEdcwvZuNmlkJtsrqaV93=7Bzyx654YXWFp0n+MLKjiHgfDAbUeTSORQPoIhG821/
得到表解密
def custom_decode(encoded_str):
# 自定义Base64字符表(包含填充字符)
custom_charset = "CEdcwvZuNmlkJtsrqaV93=7Bzyx654YXWFp0n+MLKjiHgfDAbUeTSORQPoIhG821/"
# 标准Base64字符表(不含填充字符)
standard_charset = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/"
# 先移除填充字符,后续再统一处理
encoded_str = encoded_str.replace('=', '')
# 将自定义Base64字符映射为标准Base64字符
standard_encoded = ''
for char in encoded_str:
# 查找字符在自定义字符表中的索引
idx = custom_charset.index(char)
# 处理特殊情况:自定义字符表中的填充字符(索引18)
if idx == 18: # 自定义表中的'='
continue # 跳过,后续统一添加填充
# 处理超出标准字符表范围的索引
if idx >= 64:
# 对索引取模,避免越界(这是一种简化处理方式)
idx = idx % 64
standard_encoded += standard_charset[idx]
# 补齐填充字符,使长度是4的倍数
while len(standard_encoded) % 4 != 0:
standard_encoded += '='
# 用标准Base64解码
import base64
try:
decoded_bytes = base64.b64decode(standard_encoded)
return decoded_bytes.decode('utf-8', errors='replace')
except Exception as e:
return f"解码失败: {str(e)}"
# 要解密的字符串
encoded_str = "5uESz7on4R8eyC//"
decoded_str = custom_decode(encoded_str)
print(f"解密结果: {decoded_str}")
pptandword
在ppt\media\image2.jpeg中有个倒转的zip
提取
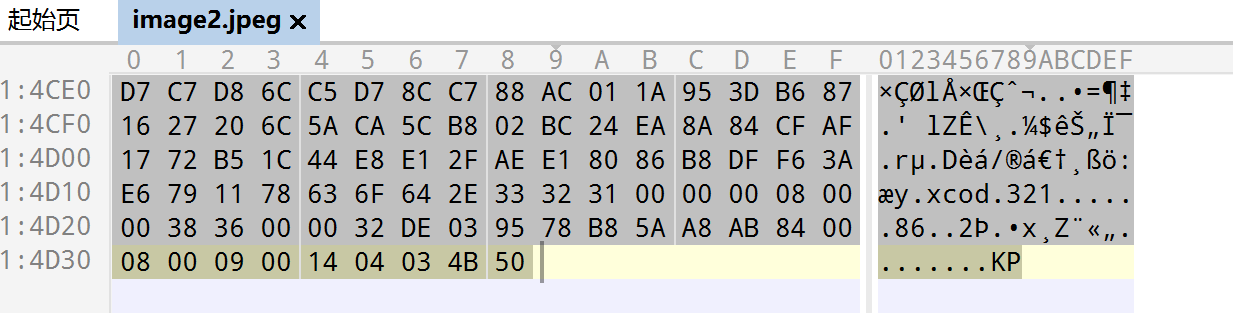
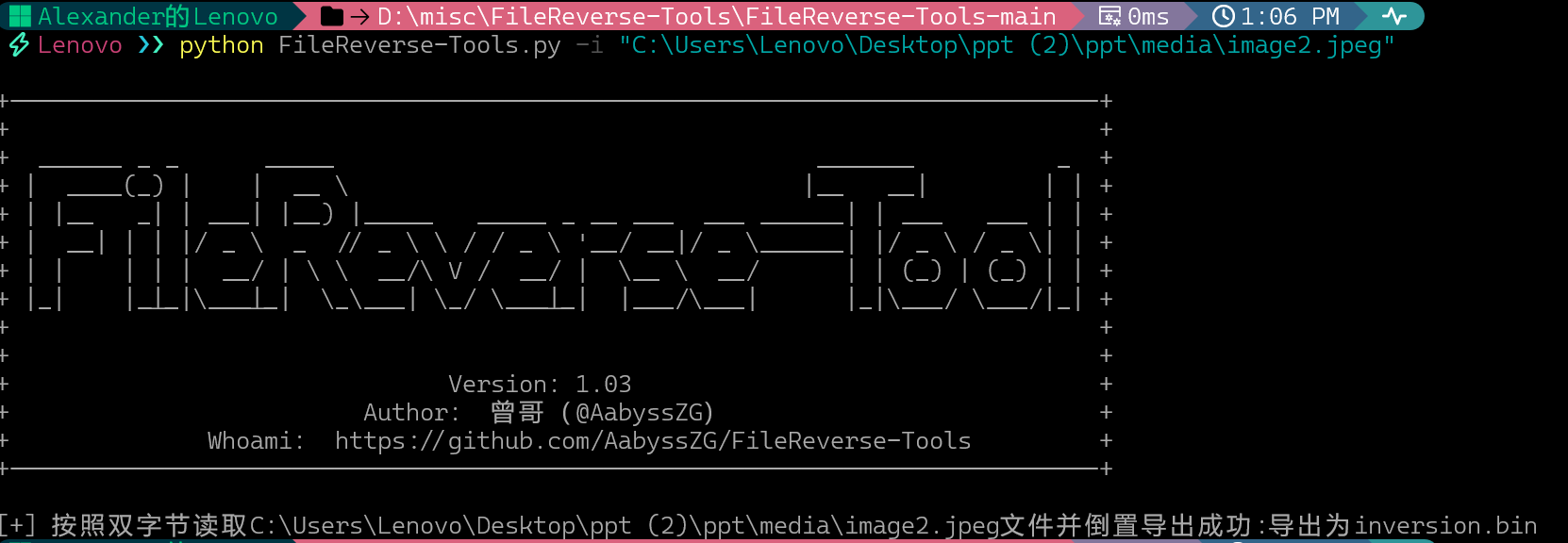
解压,打开docx

LitCTF{cfbff0d1-9345-5685-968c-48ce8b15ae17}
本文来自博客园,作者:{Alexander17},转载请注明原文链接:{https://home.cnblogs.com/u/alexander17}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号