


大模型API调用价格
2025年11月最佳AI大模型排行
这是一份AI大模型评测报告,提供多个行业流行的测试基准评分, 测试基准详见:Chatbot Arena 、MMLU(5-shot)、 Arena-Hard-Auto。
见大模型性能榜单表格。
1 Openai
全球领先的人工智能公司,其 GPT 系列模型具备强大的自然语言处理和生成能力,广泛应用于对话、内容生成和代码辅助等场景。数据来源:https://openai.com/zh-Hans-CN/api/pricing/
性能:GPT-5位于ArenaElo的第三。


| 模型名称 | 描述 | 输入价格 (US$/1M 令牌) | 缓存输入价格 (US$/1M 令牌) | 输出价格 (US$/1M 令牌) |
|---|---|---|---|---|
| GPT-5 | 我们最先进的跨行业编码与智能体任务模型 | 1.250 | 0.125 | 10.000 |
| GPT-5 mini | 适用于明确任务的更快速、更实惠 GPT-5 版本 | 0.250 | 0.025 | 2.000 |
| GPT-5 nano | 适用于摘要生成与分类任务的最快速、最实惠版本 | 0.050 | 0.005 | 0.400 |
| GPT-5 pro | 最智能、最精准的模型 | 15.00 | - | 120.00 |
2 Claude
Claude 模型以复杂推理和长上下文能力见长,适用于企业智能化需求。性能:Claude Opus 4.1 (thinking-16k)位于ArenaElo的第10。
数据源:https://claude.com/pricing#api
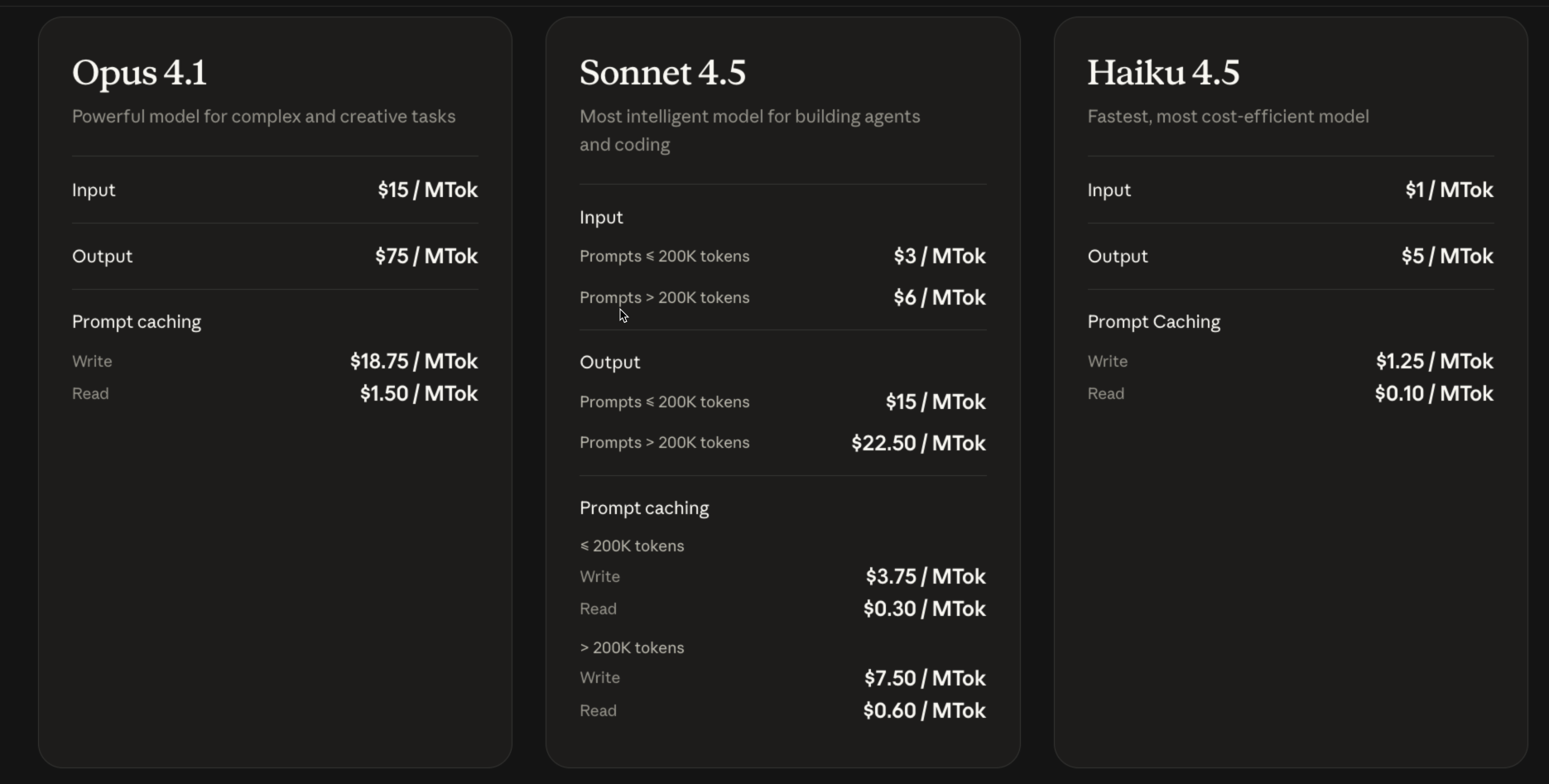
| 模型名称 | 描述 | 输入价格 ($/MTok) | 输出价格 ($/MTok) | 缓存输入价格 ($/MTok) | 缓存输出价格 ($/MTok) |
|---|---|---|---|---|---|
| Opus 4.1 | Powerful model for complex and creative tasks | 15 | 75 | 18.75 (Write) | 1.50 (Read) |
| Sonnet 4.5 | Most intelligent model for building agents and coding | 3 (< 200K tokens) | 15 (< 200K tokens) | 3.75 (< 200K tokens, Write) | 0.30 (< 200K tokens, Read) |
| 6 (> 200K tokens) | 22.50 (> 200K tokens) | 7.50 (> 200K tokens, Write) | 0.60 (> 200K tokens, Read) | ||
| Haiku 4.5 | Fastest, most cost-efficient model | 1 | 5 | 1.25 (Write) | 0.10 (Read) |
3 谷歌Gemini
数据来源:[https://ai.google.dev/gemini-api/docs/pricing?hl=zh-cn](https://ai.google.dev/gemini-api/docs/pricing?hl=zh-cn)谷歌推出的多功能 AI 平台,覆盖多种自然语言和视觉任务,提供部分免费服务以吸引开发者。
谷歌的Gemini API部分免费。具体来说,Gemini 1.5 Flash、Flash-8B和Pro模型的API都是免费的,包括输入、输出和微调服务。
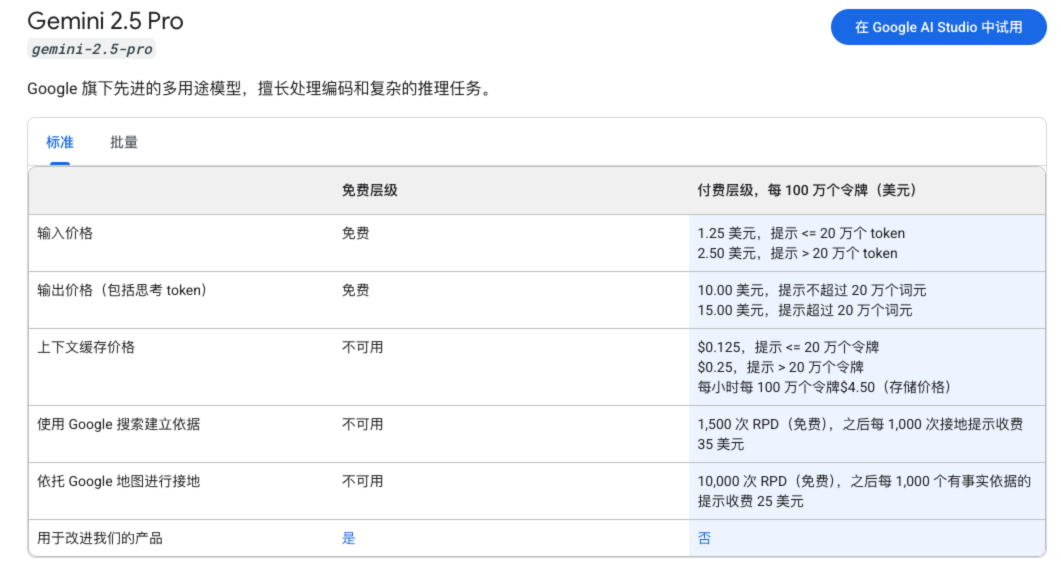

Gemini 2.5 Pro
| 功能 | 付费层级,每 100 万个令牌(美元) |
|---|---|
| 输入价格 | 1.25 美元,提示 <= 20 万个 token |
| 2.50 美元,提示 > 20 万个 token | |
| 输出价格(包括思考 token) | 10.00 美元,提示不超过 20 万个词元 |
| 15.00 美元,提示超过 20 万个词元 | |
| 上下文缓存价格 | $0.125,提示 <= 20 万个令牌 |
| $0.25,提示 > 20 万个令牌 | |
| 每小时每 100 万个令牌 $4.50(存储价格) |
Gemini 2.5 Flash
| 功能 | 付费层级,每 100 万个令牌(美元) |
|---|---|
| 输入价格 | $0.30(文字 / 图片 / 视频) |
| $1.00(音频) | |
| 输出价格(包括思考 token) | $2.50 |
| 上下文缓存价格 | $0.03(文本/图片/视频) |
| $0.1(音频) | |
| 每小时每 100 万个 token $1.00(存储价格) |
国内大模型
4 DeepSeek
数据来源:https://api-docs.deepseek.com/zh-cn/quick_start/pricing/
下表所列模型价格以“百万 tokens”为单位。Token 是模型用来表示自然语言文本的的最小单位,可以是一个词、一个数字或一个标点符号等。我们将根据模型输入和输出的总 token 数进行计量计费。
扣减费用 = token 消耗量 × 模型单价,对应的费用将直接从充值余额或赠送余额中进行扣减。 当充值余额与赠送余额同时存在时,优先扣减赠送余额。

| 模型 | deepseek-chat | deepseek-reasoner | |
|---|---|---|---|
| 模型版本 | DeepSeek-V3.2-Exp ****(非思考模式) | DeepSeek-V3.2-Exp ****(思考模式) | |
| 上下文长度 | 128K | ||
| 输出长度 | 默认 4K,最大 8K | 默认 32K,最大 64K | |
| 功能 | Json Output | 支持 | 支持 |
| Function Calling | 支持 | 不支持(1) | |
| 对话前缀续写(Beta) | 支持 | 支持 | |
| FIM 补全(Beta) | 支持 | 不支持 | |
| 价格 | 百万tokens输入(缓存命中) | 0.2元 | |
| 百万tokens输入(缓存未命中) | 2元 | ||
| 百万tokens输出 | 3元 |
5 Qwen
数据来源:[https://help.aliyun.com/zh/model-studio/model-pricing?spm=a2c4g.11186623.help-menu-2400256.d_0_0_3.402b2e66auo3Rw&scm=20140722.H_2987148._.OR_help-T_cn~zh-V_1](https://help.aliyun.com/zh/model-studio/model-pricing?spm=a2c4g.11186623.help-menu-2400256.d_0_0_3.402b2e66auo3Rw&scm=20140722.H_2987148._.OR_help-T_cn~zh-V_1)
通义千问Max
| 模型名称 | 模式 | 单次请求的输入Token数 | 输入单价(每千****Token) | 输出单价(每千Token) |
|---|---|---|---|---|
| qwen3-max |
仅非思考模式 | 0<Token≤32K | 0.006元 | 0.024元 |
| 32K<Token≤128K | 0.01元 | 0.04元 | ||
| 128K<Token≤252K | 0.015元 | 0.06元 | ||
| qwen3-max-2025-09-23 | 仅非思考模式 | 0<Token≤32K | 0.006元 | 0.024元 |
| 32K<Token≤128K | 0.01元 | 0.04元 | ||
| 128K<Token≤252K | 0.015元 | 0.06元 | ||
| qwen3-max-preview |
非思考和思考模式 | 0<Token≤32K | 0.006元 | 0.024元 |
| 32K<Token≤128K | 0.01元 | 0.04元 | ||
| 128K<Token≤252K | 0.015元 | 0.06元 |
更多模型
| 模型名称 | 模式 | 单次请求的输入Token数 | 输入单价(每千****Token) | 输出单价(每千Token) |
|---|---|---|---|---|
| qwen-max Batch调用半价 |
仅非思考模式 | 无阶梯计价 | 0.0024元 | 0.0096元 |
| qwen-max-latest Batch调用半价 |
仅非思考模式 | 无阶梯计价 | 0.0024元 | 0.0096元 |
| qwen-max-2025-01-25 | 仅非思考模式 | 无阶梯计价 | 0.0024元 | 0.0096元 |
| qwen-max-2024-09-19 | 仅非思考模式 | 无阶梯计价 | 0.02元 | 0.06元 |
| qwen-max-2024-04-28 | 仅非思考模式 | 无阶梯计价 | 0.04元 | 0.12元 |
| qwen-max-2024-04-03 | 仅非思考模式 | 无阶梯计价 | 0.04元 | 0.12元 |
通义千问Plus
| 模型名称 | 单次请求的输入Token范围 | 输入单价(每千****Token) | 输出单价(每千Token) | |
|---|---|---|---|---|
| 非思考模式 | 思考模式(思维链+回答) | |||
| qwen-plus Batch调用半价 |
0<Token≤128K | 0.0008元 | 0.002元 | 0.008元 |
| 128K<Token≤256K | 0.0024元 | 0.02元 | 0.024元 | |
| 256K<Token≤1M | 0.0048元 | 0.048元 | 0.064元 | |
| qwen-plus-latest Batch调用半价 |
0<Token≤128K | 0.0008元 | 0.002元 | 0.008元 |
| 128K<Token≤256K | 0.0024元 | 0.02元 | 0.024元 | |
| 256K<Token≤1M | 0.0048元 | 0.048元 | 0.064元 | |
| qwen-plus-2025-09-11 | 0<Token≤128K | 0.0008元 | 0.002元 | 0.008元 |
| 128K<Token≤256K | 0.0024元 | 0.02元 | 0.024元 | |
| 256K<Token≤1M | 0.0048元 | 0.048元 | 0.064元 | |
| qwen-plus-2025-07-28 | 0<Token≤128K | 0.0008元 | 0.002元 | 0.008元 |
| 128K<Token≤256K | 0.0024元 | 0.02元 | 0.024元 | |
| 256K<Token≤1M | 0.0048元 | 0.048元 | 0.064元 | |
| qwen-plus-2025-07-14 | 无阶梯计价 | 0.0008元 | 0.002元 | 0.008元 |
| qwen-plus-2025-04-28 | 无阶梯计价 | 0.0008元 | 0.002元 | 0.008元 |
文本生成-通义千问-开源版
| 模型名称 | 模式 | 输入单价(每千****Token) | 输出单价(每千Token) | |
|---|---|---|---|---|
| 非思考模式 | 思考模式(思维链+回答) | |||
| qwen3-235b-a22b-thinking-2507 | 仅思考模式 | 0.002元 | - | 0.02元 |
| qwen3-235b-a22b-instruct-2507 | 仅非思考模式 | 0.002元 | 0.008元 | - |
| qwen3-30b-a3b-thinking-2507 | 仅思考模式 | 0.00075元 | - | 0.0075元 |
| qwen3-30b-a3b-instruct-2507 | 仅非思考模式 | 0.00075元 | 0.003元 | - |
| qwen3-235b-a22b | 非思考和思考模式 | 0.002元 | 0.008元 | 0.02元 |
| qwen3-32b | 非思考和思考模式 | 0.002元 | 0.008元 | 0.02元 |
Qwen-VL
| 模型名称 | 模式 | 输入单价(每千****Token) | 输出单价(每千Token) 思维链+回答 |
|---|---|---|---|
| qwen3-vl-235b-a22b-thinking | 仅思考模式 | 0.002元 | 0.02元 |
| qwen3-vl-235b-a22b-instruct | 仅非思考模式 | 0.002元 | 0.008元 |
| qwen3-vl-32b-thinking | 仅思考模式 | 0.002元 | 0.02元 |
| qwen3-vl-32b-instruct | 仅非思考模式 | 0.002元 | 0.008元 |
| qwen3-vl-30b-a3b-thinking | 仅思考模式 | 0.00075元 | 0.0075元 |
| qwen3-vl-30b-a3b-instruct | 仅非思考模式 | 0.00075元 | 0.003元 |
更多模型
| 模型名称 | 输入单价(每千****Token) | 输出单价(每千Token) |
|---|---|---|
| qwen2.5-vl-72b-instruct | 0.016元 | 0.048元 |
| qwen2.5-vl-32b-instruct | 0.008元 | 0.024元 |
| qwen2.5-vl-7b-instruct | 0.002元 | 0.005元 |
| qwen2.5-vl-3b-instruct | 0.0012元 | 0.0036元 |
6 字节-豆包
**计费公式** 在线推理费用 = 输入单价 × 输入token + 输出单价 × 输出token,其中输出 token 包括模型输出`content`内容和思维链- doubao-seed-1.6 系列支持按照每次请求的输入长度(及输出长度),划分模型单价,如下表所示。
- 举例,调用 doubao-seed-1.6 模型,当1个请求的输入长度为 200k,输出长度为 14k 时,满足 输入长度 (128, 256] 条件,模型产生的所有 token 按照:输入2.4 元/百万 token,输出 24 元/百万 token 单价计费。
来源:https://www.volcengine.com/docs/82379/1544106?redirect=1
深度思考模型:计费单价
| 模型名称 | 条件 ****千 token | 输入 ****元/百万 token | 缓存存储 ****元/百万 token /小时 | 缓存命中 ****元/百万 token | 输出 ****元/百万 token |
|---|---|---|---|---|---|
| doubao-seed-code | 输入长度 [0, 32] | 1.2 | 0.017 | 0.24 | 8.00 |
| 输入长度 (32, 128] | 1.4 | 0.017 | 0.24 | 12.00 | |
| 输入长度 (128, 256] | 2.8 | 0.017 | 0.24 | 16.00 | |
| doubao-seed-1.6 | 输入长度 [0, 32] 且输出长度 [0, 0.2] | 0.80 | 0.017 | 0.16 | 2.00 |
| 输入长度 [0, 32] 且输出长度 (0.2,+∞) | 0.80 | 0.017 | 0.16 | 8.00 | |
| 输入长度 (32, 128] | 1.20 | 0.017 | 0.16 | 16.00 | |
| 输入长度 (128, 256] | 2.40 | 0.017 | 0.16 | 24.00 | |
| doubao-seed-1.6-lite | 输入长度 [0, 32] 且输出长度 [0, 0.2] | 0.30 | 0.017 | 0.06 | 0.60 |
| 输入长度 [0, 32] 且输出长度 (0.2,+∞) | 0.30 | 0.017 | 0.06 | 2.40 | |
| 输入长度 (32, 128] | 0.60 | 0.017 | 0.06 | 4.00 | |
| 输入长度 (128, 256] | 1.20 | 0.017 | 0.06 | 12.00 | |
| doubao-seed-1.6-flash | 输入长度 [0, 32] | 0.15 | 0.017 | 0.03 | 1.50 |
| 输入长度 (32, 128] | 0.30 | 0.017 | 0.03 | 3.00 | |
| 输入长度 (128, 256] | 0.60 | 0.017 | 0.03 | 6.00 | |
| doubao-seed-1.6-vision | 输入长度 [0, 32] | 0.80 | 0.017 | 0.16 | 8.00 |
| 输入长度 (32, 128] | 1.20 | 0.017 | 0.16 | 16.00 | |
| 输入长度 (128, 256] | 2.40 | 0.017 | 0.16 | 24.00 | |
| doubao-seed-1.6-thinking | 输入长度 [0, 32] | 0.80 | 0.017 | 0.16 | 8.00 |
| 输入长度 (32, 128] | 1.20 | 0.017 | 0.16 | 16.00 | |
| 输入长度 (128, 256] | 2.40 | 0.017 | 0.16 | 24.00 | |
| doubao-seed-1.6-flash | 输入长度 [0, 32] | 0.15 | 0.017 | 0.03 | 1.50 |
| 输入长度 (32, 128] | 0.30 | 0.017 | 0.03 | 3.00 | |
| 输入长度 (128, 256] | 0.60 | 0.017 | 0.03 | 6.00 |
大语言模型:计费单价
| 模型名称 | 输入 ****元/百万token | 缓存存储 ****元/百万token/小时 | 缓存命中 ****元/百万token | 输出 ****元/百万token |
|---|---|---|---|---|
| doubao-1.5-pro-32k | 0.80 | 0.017 | 0.16 | 2.00 |
| doubao-1.5-pro-256k | 5.00 | 不支持 | 不支持 | 9.00 |
| doubao-1.5-lite-32k | 0.30 | 0.017 | 0.06 | 0.60 |
| doubao-pro-32k | 0.80 | 0.017 | 0.16 | 2.00 |
| doubao-lite-32k | 0.30 | 0.017 | 0.06 | 0.60 |
7 Kimi
Kimi是一家专注于超长上下文支持的语言模型开发的公司,提供最高128K长度的输入处理能力,适合大规模文本分析。数据来源:https://platform.moonshot.cn/docs/pricing/chat#%E4%BA%A7%E5%93%81%E5%AE%9A%E4%BB%B7
生成模型 kimi-k2
| 模型 | 计费单位 | 输入价格 ****(缓存命中) | 输入价格 ****(缓存未命中) | 输出价格 | 模型上下文长度 |
|---|---|---|---|---|---|
| kimi-k2-0905-preview | 1M tokens | ¥1.00 | ¥4.00 | ¥16.00 | 262,144 tokens |
| kimi-k2-0711-preview | 1M tokens | ¥1.00 | ¥4.00 | ¥16.00 | 131,072 tokens |
| kimi-k2-turbo-preview推荐 | 1M tokens | ¥1.00 | ¥8.00 | ¥58.00 | 262,144 tokens |
| kimi-k2-thinking | 1M tokens | ¥1.00 | ¥4.00 | ¥16.00 | 262,144 tokens |
| kimi-k2-thinking-turbo | 1M tokens | ¥1.00 | ¥8.00 | ¥58.00 | 262,144 tokens |
- kimi-k2 是一款具备超强代码和 Agent 能力的 MoE 架构基础模型,总参数 1T,激活参数 32B。在通用知识推理、编程、数学、Agent 等主要类别的基准性能测试中,K2 模型的性能超过其他主流开源模型
- kimi-k2-0905-preview 模型上下文长度 256k,在 kimi-k2-0711-preview 能力的基础上,具备更强的 Agentic Coding 能力、更突出的前端代码的美观度和实用性、以及更好的上下文理解能力
- kimi-k2-turbo-preview 模型上下文长度 256k,是 kimi k2 的高速版本模型,始终对标最新版本的 kimi-k2 模型(kimi-k2-0905-preview)。模型参数与 kimi-k2 一致,但输出速度已提至每秒 60 tokens,最高可达每秒 100 tokens
- kimi-k2-0711-preview 模型上下文长度为 128k
- kimi-k2-thinking 模型上下文长度 256k,是具有通用 Agentic 能力和推理能力的思考模型,它擅长深度推理使用须知
- kimi-k2-thinking-turbo 模型上下文长度 256k,是 kimi-k2-thinking 模型的高速版,适用于需要深度推理和追求极致高速的场景
- 支持 ToolCalls、JSON Mode、Partial Mode、联网搜索功能等,不支持视觉功能
- 支持自动上下文缓存功能,缓存命中的 tokens 将按照输入价格(缓存命中)单价收费,您可以在控制台中查看"context caching"类型的费用明细
8 智谱
专注于提供高性价比自然语言处理服务的公司,其GLM系列模型表现卓越,并提供免费模型以降低用户门槛。数据来源:https://open.bigmodel.cn/pricing
GLM-4.6 是智谱最新的旗舰模型,其总参数量 355B,激活参数 32B,上下文提升至 200K,8 大权威基准全面提升。在编程、推理、搜索、写作、智能体应用等核心能力均完成对 GLM-4.5 的超越。
| 模型名称 | 上下文 | 输入单价 (百元/Tokens) | 输出单价 (百元/Tokens) | 缓存命中 (百元/Tokens) | Decode速度 |
|---|---|---|---|---|---|
| GLM-4.6 | 输入长度[0, 32] 输出长度[0, 2] | 2 | 8 | 0.4 | 30~50 |
| 输入长度[0, 32] 输出长度[0, 2] | 3 | 14 | 0.6 | 30~50 | |
| 输入长度[32, 200] | 4 | 16 | 0.8 | 30~50 | |
| GLM-4.5 | 输入长度[0, 32] 输出长度[0, 2] | 2 | 8 | 0.4 | 30~50 |
| 输入长度[0, 32] 输出长度[0, 2] | 3 | 14 | 0.6 | 30~50 | |
| 输入长度[32, 128] | 4 | 16 | 0.8 | 30~50 | |
| GLM-4.5-x | 输入长度[0, 32] 输出长度[0, 2] | 8 | 16 | 1.6 | 60~100 |
| 输入长度[0, 32] 输出长度[0, 2] | 12 | 32 | 2.4 | 60~100 | |
| 输入长度[32, 128] | 16 | 64 | 3.2 | 60~100 | |
| GLM-4.5-Ar | 输入长度[0, 32] 输出长度[0, 2] | 0.8 | 2 | 0.16 | 30~50 |
| 输入长度[0, 32] 输出长度[0, 2] | 0.8 | 6 | 0.16 | 30~50 | |
| 输入长度[32, 128] | 1.2 | 8 | 0.24 | 30~50 | |
| GLM-4.5-64G | 输入长度[0, 32] 输出长度[0, 2] | 4 | 12 | 0.8 | 60~100 |
| 输入长度[0, 32] 输出长度[0, 2] | 4 | 16 | 0.8 | 60~100 | |
| 输入长度[32, 128] | 8 | 32 | 1.6 | 60~100 |
9 腾讯混元
数据来源:[https://cloud.tencent.com/document/product/1729/97731](https://cloud.tencent.com/document/product/1729/97731)| 产品名 | 单位 | 刊例价 |
|---|---|---|
| hunyuan-T1 | 每 百万 tokens | 输入:1元 输出:4元 |
| hunyuan-TurboS | 每 百万 tokens | 输入:0.8元 输出:2元 |
| hunyuan-turbos-longtext-128k | 每 百万 tokens | 输入:1.5元 输出:6元 |
| hunyuan-a13b | 每 百万 tokens | 输入:0.5元 输出:2元 |
| hunyuan-turbo | 每 百万 tokens | 输入:2.4元 输出:9.6元 |
| hunyuan-large | 每 百万 tokens | 输入:4元 输出:12元 |
| hunyuan-large-longcontext | 每 百万 tokens | 输入:6元 输出:18元 |
| hunyuan-standard | 每 百万 tokens | 输入:0.8元 输出:2元 |
| hunyuan-standard-256K | 每 百万 tokens | 输入:0.5元 输出:2元 |
| hunyuan-translation | 每 百万 tokens | 输入:15元 输出:45元 |
| hunyuan-translation-lite | 每 百万 tokens | 输入:1元 输出:3元 |
| hunyuan-role | 每 百万 tokens | 输入:4元 输出:8元 |
| hunyuan-functioncall | 每 百万 tokens | 输入:4元 输出:8元 |
| hunyuan-code | 每 百万 tokens | 输入:3.5元 输出:7元 |
| hunyuan-turbos-vision | 每 百万 tokens | 输入:3元 输出:9元 |
| hunyuan-t1-vision | 每 百万 tokens | 输入:3元 输出:9元 |
| hunyuan-vision | 每 百万 tokens | 输入:18元 输出:18元 |
| hunyuan-embedding | 每 百万 tokens | 输入:0.7元 输出:0.7元 |
10 百度千帆
文心大模型生态覆盖NLP、图像生成等多个领域,侧重大规模场景的深度应用。数据来源:https://cloud.baidu.com/doc/WENXINWORKSHOP/s/Qm9cw2s7m
| 模型名称 | 版本名称 | 服务内容 | 子项 | 在线推理 | 批量推理 | 单位 |
|---|---|---|---|---|---|---|
| ERNIE 4.5 Turbo | ERNIE-4.5-Turbo-128K-Preview ERNIE-4.5-Turbo-128K ERNIE-4.5-Turbo-32K ERNIE-4.5-Turbo-Latest | 推理服务 | 输入 | 0.0008 | 0.00032 | 元/千tokens |
| 命中缓存 | 0.0002 | -- | 元/千tokens | |||
| 输出 | 0.0032 | 0.00128 | 元/千tokens | |||
| 搜索增强 | 触发 | 0.004 | 0.0016 | 元/次 | ||
| ERNIE 4.5 Turbo VL | ERNIE-4.5-Turbo-VL-Preview ERNIE-4.5-Turbo-VL ERNIE-4.5-Turbo-VL-32K ERNIE-4.5-Turbo-VL-32K-Preview ERNIE-4.5-Turbo-VL-Latest | 推理服务 | 输入 | 0.003 | 0.0012 | 元/千tokens |
| 命中缓存 | 0.00075 | -- | 元/千tokens | |||
| 输出 | 0.009 | 0.0036 | 元/千tokens | |||
| ERNIE 4.5 | ERNIE-4.5-8K | 推理服务 | 输入 | 0.004 | 0.0016 | 元/千tokens |
| 输出 | 0.016 | 0.0064 | 元/千tokens | |||
| 搜索增强 | 触发 | 0.004 | 0.0016 | 元/次 | ||
| ERNIE 4.5 | ERNIE-4.5-VL-28B-A3B 如开启思考模式计费详情请查看深度思考 | 推理服务 | 输入 | 0.001 | 0.0004 | 元/千tokens |
| 输出 | 0.004 | 0.0016 | 元/千tokens | |||
| ERNIE 4.5 | ERNIE-4.5-0.3B | 推理服务 | 输入 | 0.0001 | 0.00004 | 元/千tokens |
| 输出 | 0.0004 | 0.00016 | 元/千tokens | |||
| ERNIE 4.5 | ERNIE-4.5-21B-A3B-Thinking | 推理服务 | 输入 | 0.0005 | - | 元/千tokens |
| 输出 | 0.002 | - | 元/千tokens | |||
| ERNIE 4.5 | ERNIE-4.5-21B-A3B | 推理服务 | 输入 | 0.0005 | 0.0002 | 元/千tokens |
| 输出 | 0.002 | 0.0008 | 元/千tokens |
11 讯飞星火
推出的讯飞星火语言模型,特别适用于教育、办公场景,Lite模型全面免费,主打实用性。版本单价2~3元/百万Tokens


价格总结:
| 序号 | 模型名 | 厂商 | 上下文长度 | 输入(人民币/元)/百万Token | 输出(人民币/元)/百万Token |
|---|---|---|---|---|---|
| 1 | GPT-5 | Openai | 9.0845 | 72.6760 | |
| 2 | Claude Opus 4.1 | Anthropic | 106.79 | 533.95 | |
| 3 | Claude Sonnet 4.5 | Anthropic | < 200K tokens | 21.3558 | 106.79 |
| 4 | Gemini 2.5 Pro | 谷歌 | <= 20 万个 token | 9.0250 | 71.2000 |
| 5 | DeepSeek-V3.2-Exp | DeepSeek | 128K | 2 | 3 |
| 6 | qwen3-max | Qwen | 0<Token≤32K | 6 | 24 |
| 7 | qwen3-max | Qwen | 32K<Token≤128K | 10 | 40 |
| 8 | qwen3-max | Qwen | 128K<Token≤252K | 15 | 60 |
| 9 | qwen3-235b-a22b | Qwen | 2 | 20 | |
| 10 | qwen3-32b | Qwen | 2 | 20 | |
| 11 | qwen3-vl-235b-a22b | 2 | 20 | ||
| 12 | qwen3-vl-30b-a3b | 0.75 | 7.5 | ||
| 13 | qwen2.5-vl-72b-instruct | 16 | 48 | ||
| 14 | doubao-seed-1.6 | [0, 32] | 0.80 | 2.00 | |
| 15 | doubao-seed-1.6 | (32, 128] | 1.20 | 16.00 | |
| 16 | doubao-seed-1.6 | (128, 256] | 2.40 | 24.00 | |
| 17 | doubao-1.5-pro-32k | 0.80 | 2.00 | ||
| 18 | kimi-k2-0905-preview | 262,144 tokens | 4.00 | 16.00 | |
| 19 | kimi-k2-thinking | 262,144 tokens | 4.00 | 16.00 | |
| 20 | GLM-4.6 | [0, 32] | 2 | 8 | |
| 21 | GLM-4.6 | (32, 128] | 3 | 14 | |
| 22 | GLM-4.6 | (128, 256] | 4 | 16 | |
| 23 | GLM-4.5 | [0, 32] | 2 | 8 | |
| 24 | GLM-4.5 | (32, 128] | 3 | 14 | |
| 25 | GLM-4.5 | (128, 256] | 4 | 16 | |
| 26 | hunyuan-turbo | 2.4 | 9.6 | ||
| 27 | hunyuan-standard | 0.8 | 2 | ||
| 28 | hunyuan-large | 4 | 12 | ||
| 29 | ERNIE 4.5 Turbo | 0.8 | 3.2 | ||
| 30 | ERNIE-4.5-8K | 4 | 16 | ||
| 31 | Spark | 总价2~3元/百万Token |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号