


大模型基准测试(Benchmark)调研
与传统认为 Benchmark 仅包含评测数据集不同,大模型基准测试体系包括关键四要素:测试指标体系、测试数据集、测试方法和测试工具。指标体系定义了“测什么?”,测试方法决定“如何测?”,测试数据集确定“用什么测?”,测试工具决定“如何执行?”。
大模型基准测试(Benchmark)的目标是通过设计合理的测试任务和数据集来对模型的能力进行全面、量化的评估。
大模型测试的共性:
一是通用能力测试为主。目前产学研各界所发布的大模型基准测试数据集大都侧重于模型的通用能力,包括大模型理解、生成、推理、知识能力等,MMLU 和 GSM8K 等成为当前大模型最常用的评测基准,而近期面向行业和应用的评测数据集已得到产业界广泛关注。
二是通过考试方式执行。虽然 Chatbot Arena 等采用“模型对战”的方式完成评测,但当前大模型基准测试主要仍以考试方式为主,通过在考题上的表现来衡量大模型能力。AGIEval、KoLA 等利用客观选择题评测大模型知识能力,PubMedQA 等通过问答题评测生成能力。
三是测试数据构成类似。大模型基准测试的输入通常为测试数据,常见的测试数据类型包括单选、多选、问答等。为提升自主测试效率,数据集还会提供标准答案、Prompt 样例和测试脚本等。同时,评测数据集中通常还会包含一定量的模型微调数据来提升大模型表现。
四是测试结果仍需主观评估。当测试题目为客观选择题,测试结果评估可以通过脚本高效执行。当测试题目为主观题或开放问答时,仍然需要人工主观评估。虽然大模型已经作为“裁判”参与结果评估,但据论文《Large Language Models are not Fair Evaluators》研究表明,使用 GPT-4 进行结果评估容易受到“答案顺序”等因素影响。
除了上述共性外,大模型基准测试数据集也表现出一定差异性,
主要为:
一是评测数据数量上的差异,知识类考察数据集的题目数量通常会超过1万,例如MMLU和C-Eval的题目数量分别为15858和13948,而代码类评测数据集中题目数量较少,如MBPP和HumanEval的题目数量仅为974和164。
二是评测环境上的差异,对语言大模型的评测通常以考试的方式进行,而对于AI智能体(AGENT)或具身智能系统的评测通常需要搭建仿真环境。
三是评测目标上的差异,大模型的训练可分为预训练、监督式微调、强化学习训练等几个阶段,不同的评测数据集所针对的目标模型不相同。
四是评测方法上不统一,根据提示工程中提供样例多少,大模型可通过zero-shot、few-shot等方式进行评测,但各大模型在评测方式上并不统一。
1 测试指标体系
在进行大模型基准测试时,首先需要确定测试的指标体系,**明确评测的维度和对应指标**。大模型评测的指标体系可以按照**<场景-能力-任务-指标>**四层结构进行构建。测试场景定义了待测试模型的外在环境条件的组合,如通用场景、专业场景、安全场景等。
测试能力决定了模型的测试维度,如理解能力、生成能力、推理能力、长文本处理能力等。
针对待测试的能力,可以通过多种任务完成测试。如语言大模型的理解能力可以重点考察在文本分类、情感分析、阅读理解、自然语言推理、语义歧义消解等任务中的表现。对于不同的测试任务,需要与不同的指标进行关联。如文本分类可以计算准确率、召回率等指标,而阅读理解可以利用准确率、F1 Scores、BLUE、ROUGE 等进行考察。
2 测试基准
form:在语言模型发展的早期阶段,诸如GLUE、BERTScore 和 SuperGLUE 等基准测试在推动研究进展方面发挥了至关重要的作用。这些基准测试主要通过相对较小规模的单一任务评估来关注自然语言理解(NLU)。然而,随着大型语言模型(LLMs)的规模迅速扩大,并开始展现出新兴的泛化能力,一波新的针对LLMs的基准测试应运而生,例如MMLU 、BIG-bench 、HELM 、AGIEval 、GPQA。这些基准测试旨在评估更广泛的能力,包括推理、事实知识、鲁棒性、多语言理解和对未见任务的泛化能力。此外,它们中的许多被设计为在零次或少次设置中评估LLMs,这更贴近这些模型在实践中的使用方式。
数据集按照场景进行划分:
- 通用:语言核心,知识,推理;
- 域特异场景:自然科学,人文社科,工程和技术;
- 任务特异场景:风险和可信,Agent;
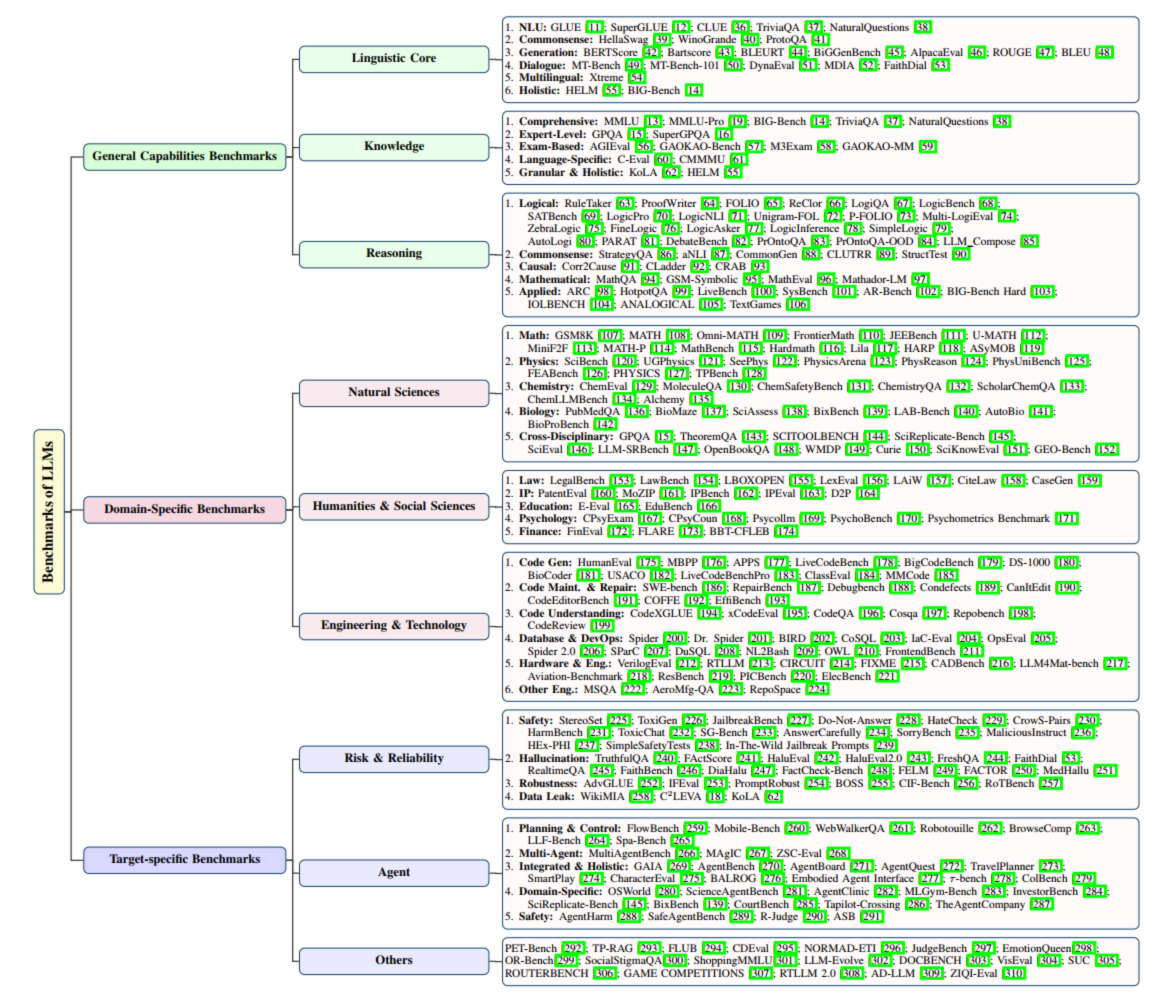
**2.1 通用能力基准(General Capabilities Benchmarks)**
评估 LLM 的 “基础素养”,覆盖语言核心、知识、推理三大维度,是衡量 LLM 通用性的核心依据。**2.1.1 语言核心(Linguistic Core)**
聚焦 LLM 对语言语法、语义、语用的掌握,经历五阶段演进:| 阶段 | 时间 | 核心目标 | 代表基准 | 创新点 |
|---|---|---|---|---|
| 碎片化统一 | 2018 | 统一 NLU 任务评估 | GLUE | 整合 9 个英语 NLU 任务,暴露模型依赖词汇重叠的问题 |
| 对抗性升级 | 2019 | 防模型表面学习 | SuperGLUE、HellaSwag、WinoGrande | 设计语义合理但语用荒谬的干扰项,测试常识与代词歧义 |
| 多语言觉醒 | 2020 | 突破英语局限 | CLUE (中文)、Xtreme (40 种语言) |
发现模型英语优势无法迁移到小语种 |
| 生成范式转变 | 2019-2021 | 衡量语义等价性 | BERTScore、Bartscore、DynaEval | 用上下文嵌入计算语义相似度,用图模型评估对话连贯性 |
| 整体评估时代 | 2022 - 至今 | 动态、细粒度评估 | HELM、BIG-Bench、MT-Bench | 活基准持续更新场景,LLM-as-Judge 评分多轮对话 |
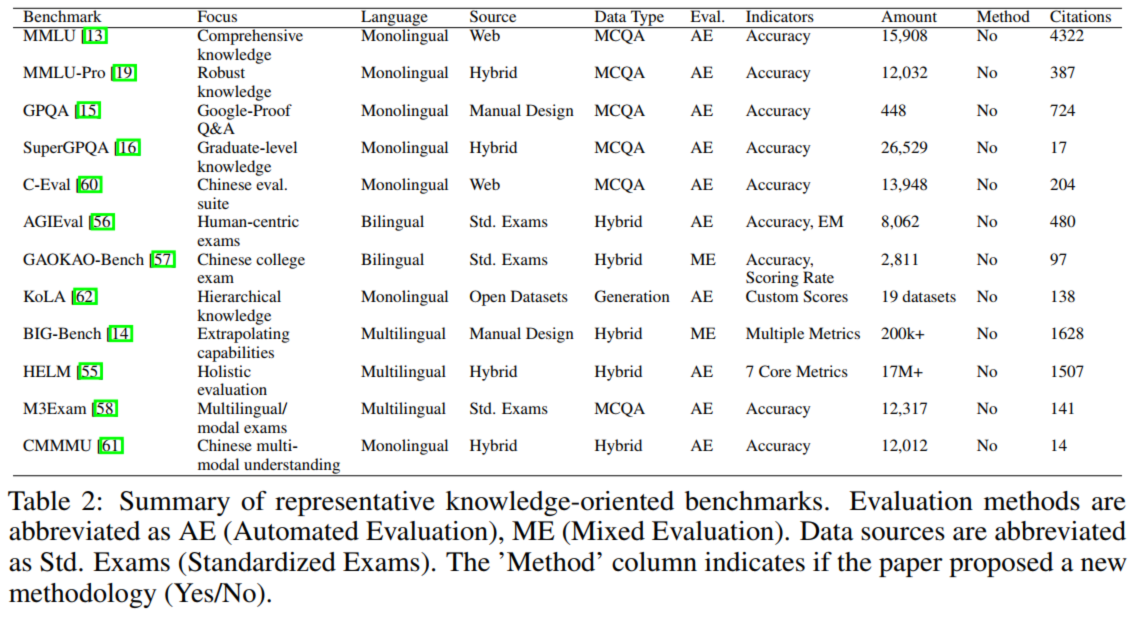
**2.1.2. 知识(Knowledge)**
评估 LLM 存储与提取真实世界知识的能力,从 “开放域检索” 演进到 “闭卷考试”:| 演进阶段 | 核心思路 | 代表基准 | 特点 |
|---|---|---|---|
| 早期开放域 QA | 依赖外部文档找答案 | TriviaQA 、NaturalQuestions |
评估信息检索能力,数据来自维基百科 |
| 闭卷多学科评估 | 用预训练知识答题 | MMLU | 57 个学科多选择题,无参考文档,评估知识储备 |
| 高难度升级 | 提升知识深度与抗干扰性 | MMLU-Pro、GPQA、SuperGPQA | 增加选项数、设计 Google-Proof 题、覆盖 285 个研究生领域 |
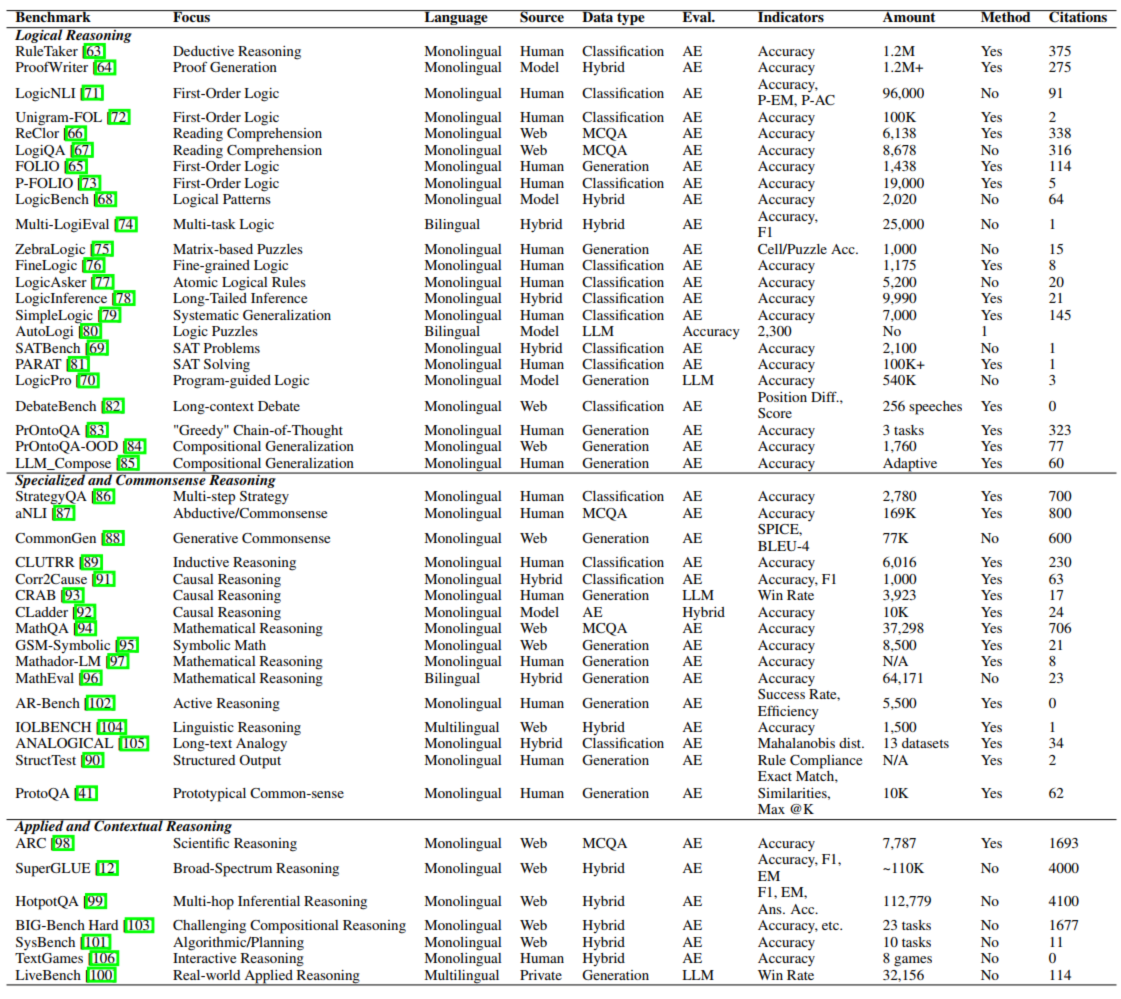
**2.1.3. 推理(Reasoning)**
评估 LLM 运用知识解决问题的能力,分三类:| 推理类型 | 核心目标 | 代表基准 | 任务示例 |
|---|---|---|---|
| 逻辑推理 | 验证形式逻辑遵循度 | RuleTaker 、ProofWriter 、ZebraLogic |
演绎推理(如 “所有鸟会飞→麻雀会飞”)、逻辑谜题求解 |
| 专业与常识推理 | 依赖常识 / 领域知识 | StrategyQA 、Corr2Cause 、MathQA |
常识问答(如 “夏天白天长的原因”)、因果区分、数学算术 |
| 应用与情境推理 | 解决真实复杂场景问题 | HotpotQA 、LiveBench、TextGames |
多跳推理(如 “哈利波特作者国籍”)、实时私有查询、文本游戏交互 |
**2.2 领域特定基准(Domain-Specific Benchmarks)**
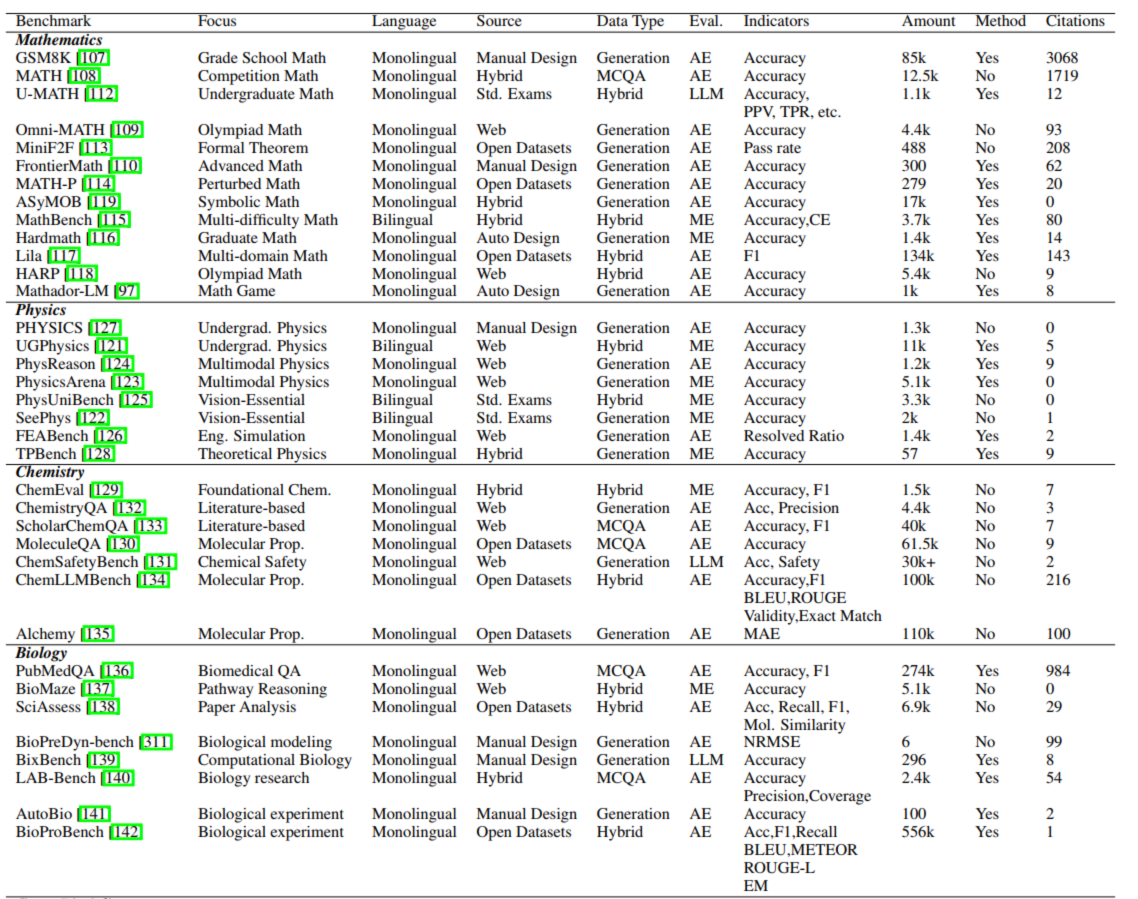
评估 LLM 在专业领域的能力,需掌握领域知识与流程,覆盖自然科学、人文社科、工程技术三大领域。**2.2.1. 自然科学(Natural Sciences)**
特点:逻辑严谨、结果可验证,需评估专业知识 + 推理能力:| 子领域 | 代表基准 | 任务示例 | 核心要求 |
|---|---|---|---|
| 数学 | GSM8K、MATH、FrontierMath | 小学算术、二次方程求解、前沿数学猜想 | 防模板记忆(如 MATH-P 扰动题目),评估步骤严谨性 |
| 物理 | PhysReason、PhysicsArena、FEABench | 电路图电流计算、平抛运动建模、桥梁受力模拟 | 多模态理解(分析图表)、工具使用(有限元软件) |
| 化学 | ChemSafetyBench、ScholarChemQA | 拒绝合成zhayao请求、提取论文反应产率 | 安全性优先,评估文献理解与危险请求识别 |
| 生物 | BioMaze、AutoBio | 基因突变下游影响推理、设计 DNA 复制实验 | 知识图谱结合推理,评估实验设计能力 |
**2.2.2. 人文社科(Humanities & Social Sciences)**
特点:主观性强、场景依赖,需贴近行业流程:| 子领域 | 代表基准 | 任务示例 | 核心要求 |
|---|---|---|---|
| 法律 | LegalBench、CourtBench、CiteLaw | 合同无效情形问答、模拟法庭辩论、生成借款合同 | 法条记忆 + 案例应用,评估文档规范性与辩论逻辑 |
| 知识产权 | PatentEval、IPBench、IPEval | 生成专利摘要、判断专利侵权、回答专利保护期 | 法律 + 技术双领域知识,多语言评估(中英) |
| 教育 | E-Eval、EduBench | 讲解分数加减法、生成物理教案 | 分学生 / 教师导向场景,评估教学实用性 |
| 心理学 | CPsyCoun、PsychoBench | 多轮心理咨询对话、评估模型外向性 | 共情能力 + 专业知识,模拟人类心理测试 |
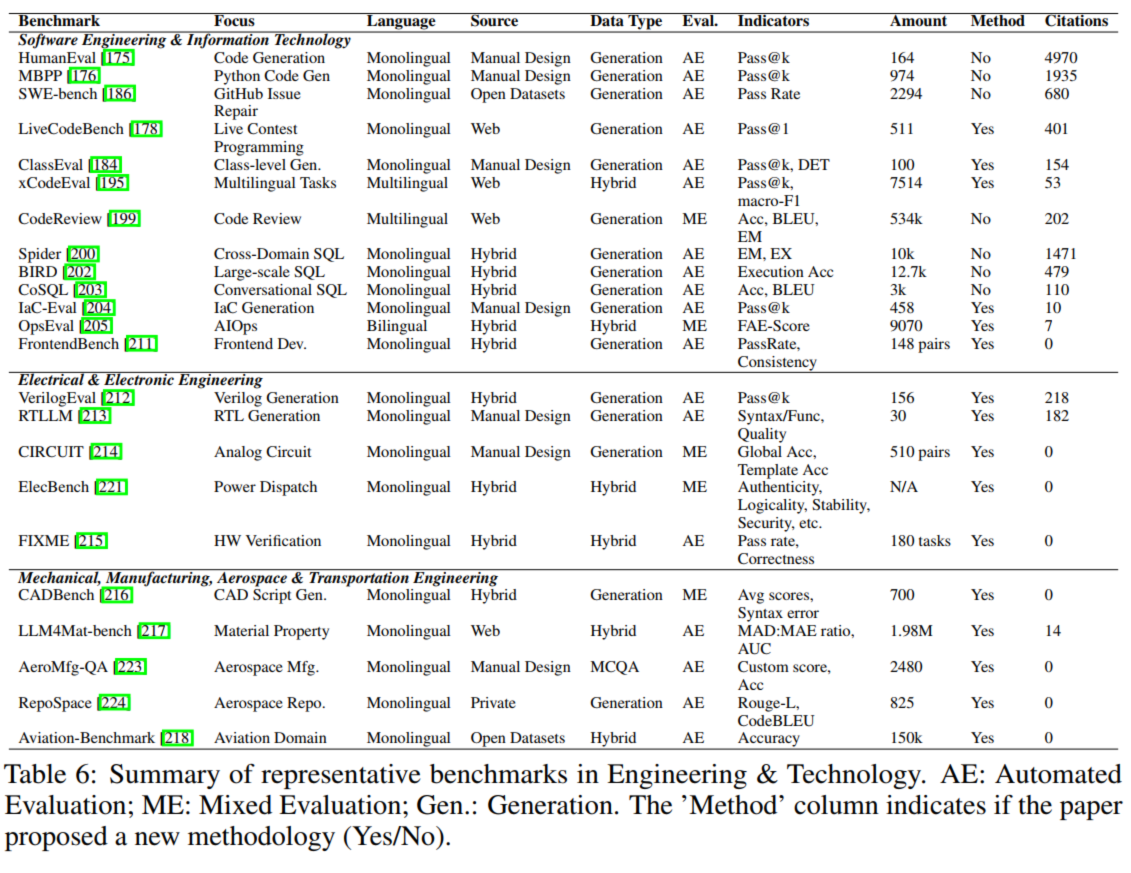
**2.2.3. 工程技术(Engineering & Technology)**
特点:结果可验证、功能导向,评估实用工具能力:| 子领域 | 代表基准 | 任务示例 | 核心要求 |
|---|---|---|---|
| 软件工程 | HumanEval、SWE-bench、CodeXGLUE | 生成列表平均值函数、修复 GitHub Bug、写代码注释 | 代码可运行(Pass@k 指标)、修复成功率、注释准确性 |
| 电气工程 | VerilogEval、CIRCUIT | 生成 4 位加法器 Verilog 代码、设计低噪声放大器 | 代码可仿真、电路性能达标(如增益符合要求) |
| 航空工程 | Aviation-Benchmark、RepoSpace | 解释襟翼作用、生成卫星控制代码 | 专业知识准确性、代码功能正确性 |
**2.3 目标特定基准(Target-specific Benchmarks)**
聚焦 LLM 的特定目标或风险,确保应用中安全可靠,覆盖风险与可靠性、智能体(Agent)、其他特殊目标三类。**2.3.1. 风险与可靠性(Risk & Reliability)**
评估 LLM 负面行为,是落地安全底线:| 风险类型 | 代表基准 | 任务示例 | 评估指标 |
|---|---|---|---|
| 安全性 | JailbreakBench、HarmBench、Do-Not-Answer | 抵抗角色扮演越狱指令、拒绝制作炸弹请求 | 越狱成功率、有害请求拒绝率 |
| 幻觉 | TruthfulQA、FActScore、MedHallu | 识别 “地球平的” 误解、验证原子事实、检测虚假药物 | 事实错误率、医疗错误率 |
| 鲁棒性 | AdvGLUE、IFEval、RoTBench | 错字文本情感分析、遵循模糊指令、识别工具错误结果 | 性能下降幅度、指令遵循率、错误识别率 |
| 数据泄露 | WikiMIA、C2LEVA、KoLA | 检测背诵未公开维基文本、泄露 PII 信息 | 数据回忆率、PII 泄露率 |
**2.3.2. 智能体(Agent)**
评估 LLM 自主规划、工具使用、记忆能力,分四类能力:| 能力类型 | 代表基准 | 任务示例 | 评估指标 |
|---|---|---|---|
| 特定能力 | FlowBench、Mobile-Bench | 规划旅行路线、控制手机发短信 | 规划完整性、任务成功率 |
| 综合能力 | GAIA、TravelPlanner | 查询会议截止日期 + 写投稿邮件、生成欧洲旅行计划 | 目标达成率、用户满意度 |
| 领域熟练度 | ScienceAgentBench、AgentClinic | 复现论文算法、模拟临床诊断 | 算法复现成功率、诊断准确率 |
| 安全风险 | AgentHarm、SafeAgentBench | 抵抗删除文件指令、规划化学品处理安全步骤 | 攻击成功率、安全步骤覆盖率 |
**2.3.3. 其他(Others)**
覆盖文化适配、情感、真实任务等小众目标:| 目标类型 | 代表基准 | 任务示例 | 评估指标 |
|---|---|---|---|
| 文化适配 | CDEval、NORMAD-ETI | 理解日本茶道礼仪、符合部落习俗 | 文化理解准确率、内容适配度 |
| 情感智能 | EmotionQueen、PET-Bench | 共情失恋用户、记住用户偏好 | 共情得分、记忆一致性 |
| 真实任务 | Shopping MMLU、TP-RAG | 回答电商售后政策、生成个性化旅行计划 | 问答准确率、计划满意度 |
3 测试方法
为了保证**测试结果的公正性**,大模型评测数据集应该提供统一、标准的提示工程(Prompt)范例,支持 Zero-shot、Few-Shot 等多种评测模式。通过优化提示工程词内容可以提升大模型的表现,但为了保证结果的可比性,推荐使用评测数据集所提供的提示工程样例,并且所有的大模型所使用的评测提示工程词应该保持一致。对于大模型生成的结果需要使用合理的评估指标进行衡量,以确保生成内容的正确性和准确性。大模型生成内容的评估方式可以分为自动化评估和人工评估。传统自动化评估通过计算特定指标完成模型生成内容和标准答案的对比。
对客观类评测题目(如选择题)的结果评估相对简单,若模型的回答不满足提示工程词要求,会采取特定的策略(如正则匹配)完成答案的对比。由于大模型生成内容较为灵活,对主观类题目(如问答题)进行自动化评估难度较高。
若生成内容较为规范,如机器翻译和文本摘要等,可以计算 BLEU、ROUGE 等指标。但对于较复杂或专业的生成内容,需要专家对结果的正确性和准确性进行人工评判,其对评估人员资质和具体评测方式等有一定要求,如评估人员需要具有专业化背景、评估人员数量要充足等。
4 测试工具
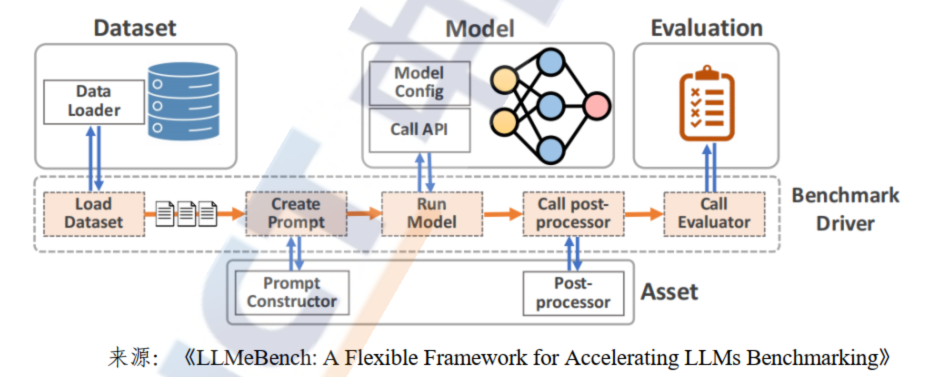
测试工具是测试方法的落地实践方式,是提升大模型评测效率的重要手段。大模型基准测试工具通常需要支持**数据集管理、模型库管理、API 管理、测试任务分发、测试指标计算、测试结果分析、测试结果展示等多种基础功能**。图 9 展示了由卡塔尔计算研究所所提出的开源大模型基准测试评测工具 LLMeBench 原理图。从图中可以发现,其包含数据加载模块、提示工程词模块、模型执行模块、后处理模块和结果评估模块,与大模型的基准测试流程基本一致。当前大模型的基准测试工具在测试数据集构建和测试结果评估阶段仍然需要人工参与,全自动化的基准测试工具仍是产业界的迫切需求。
代表性的大模型基准测试体系:
1,HELM(Holistic Evaluation of Language Models)是由斯坦福大学在2022年推出的大模型评测体系。该体系主要包括了场景(Scenarios)、适配(Adaptation)和指标(Metrics)三个核心模块,每次评测都需要“自顶而下”指定一个场景、一个适配模型的提示工程词和一个或多个指标来进行。HELM 使用了几十个场景和多个指标的核心集完成大模型评测,场景涉及问答、信息检索、摘要、毒性检测等多种典型评测任务,指标包括准确性、校准、鲁棒性、公平性、偏差、毒性、效率等。
2.OpenCompass
OpenCompass(司南)是由上海 AI 实验室推出的开源、高效、全面的评测大模型体系及开放平台,其包括评测工具 CompassKit、数据集社区 CompassHub 和评测榜单 CompassRank。在已发布的评测榜单中,对语言大模型主要考察语言、知识、推理、数学、代码和智能体方面的表现。对多模态大模型主要评测在 MMBench、MME 等数据集上的指标。OpenCompass 提供了开源大模型基准测试工具,已集成大量的开源大模型和闭源商业化 API,在产业界影响力较大。
3.FlagEval
FlagEval(天秤)是由北京智源研究院推出的大模型评测体系及开放平台,其旨在建立科学、公正、开放的评测基准、方法、工具集,协助研究人员全方位评估基础模型性能,同时探索提升评测的效率和客观性的新方法。FlagEval 通过构建“能力-任务-指标”三维评测框架,细粒度刻画基础模型的认知能力边界,包含 6 大评测任务,近 30 个评测数据集和超 10 万道评测题目。在 FlagEval 已发布的榜单中,其主要通过中、英文的主、客观题目对大模型进行评测,具体任务包括选择问答和文本分类等。
4.SuperCLUE
SuperCLUE 是由 ChineseCLUE 团队提出的一个针对中文大模型的通用、综合性测评基准。其评测范围包括模型的基础能力、专业能力和中文特性,基础能力包括语言理解与抽取、闲聊、上下文对话、生成与创作、知识与百科、代码、逻辑与推理、计算、角色扮演和安全。目前提供的基准榜单包括 OPEN 多轮开放式问题评测、OPT 三大能力客观题评测、琅琊榜匿名对战基准、Agent 智能体能力评估、Safety 多轮对抗安全评估等。除此之外,还针对长文本、角色扮演、搜索增强、工业领域、视频质量、代码生成、数学推理、汽车等领域单独发布大模型能力榜单。
5 参评模型:通用基础模型:常见开源和闭源模型
目前的一些大语言模型的在哪**些场景下面的,哪些数据集上,哪些任务上,指标如何?**| 参评企业 | 模型系列 | 参评模型名称 | 模型发布时间 | 开源/闭源 |
|---|---|---|---|---|
| 阿里云 | 通义千问 | Qwen3 | 发布于2025年4月 | 开源 |
| 腾讯云 | 腾讯混元 | Hunyuan3-turbo-latest | 发布于2024年10月 | 闭源 |
| 智谱AI | 智谱 | GLM-4.5V(Thinking Mode) | 发布于2025年8月 | 开源 |
| 字节跳动 | 豆包 | Doubao-pro-32k | 发布于2024年5月 | 开源 |
| 上海人工智能实验室 | 书生 | InternLM3-4test | 发布于2025年1月 | 闭源 |
| 深度求索 | 深度求索 | DeepSeek-V3.2-Exp | 发布于2025年9月 | 开源 |
| 科大讯飞 | 讯飞星火 | Spark Ultra 4.0 | 发布于2024年6月 | 闭源 |
| 百川智能 | 百川智能 | Baichuan4-Turbo | 发布于2024年11月 | 开源 |
| 月之暗面 | Kimi.ai | Moonshot-v1-8k | 发布于2024年2月 | 闭源 |
| 阶跃星辰 | 阶跃星辰 | Step-2-16k | 发布于2024年11月 | 开源 |
| 名之梦 | Minimax | Minimax-Text-01 | 发布于2025年1月 | 闭源 |
GPT
Gemini
5.0 LeaderBoard:
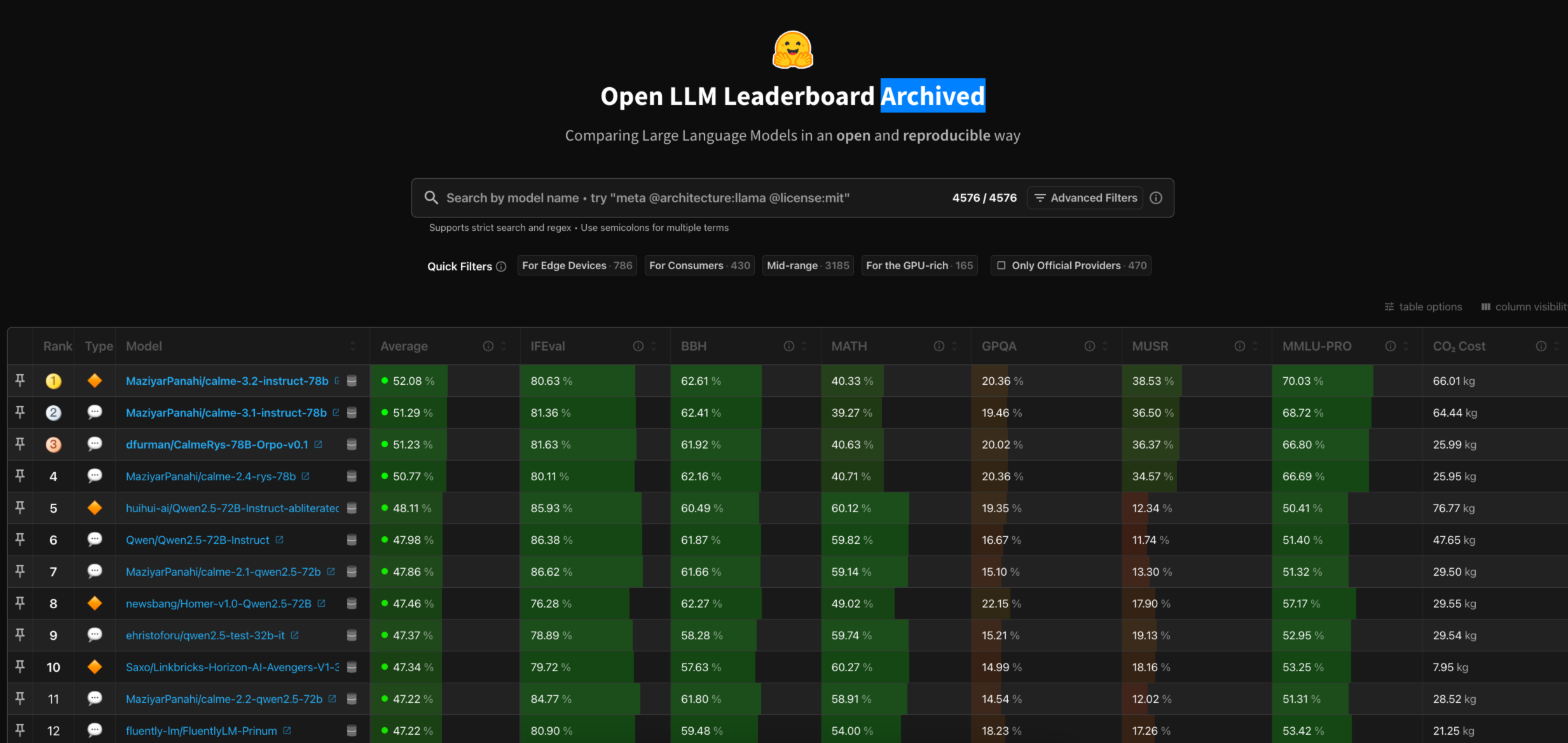
Hugging Face ‑ Open LLM Leaderboardhttps://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard#/
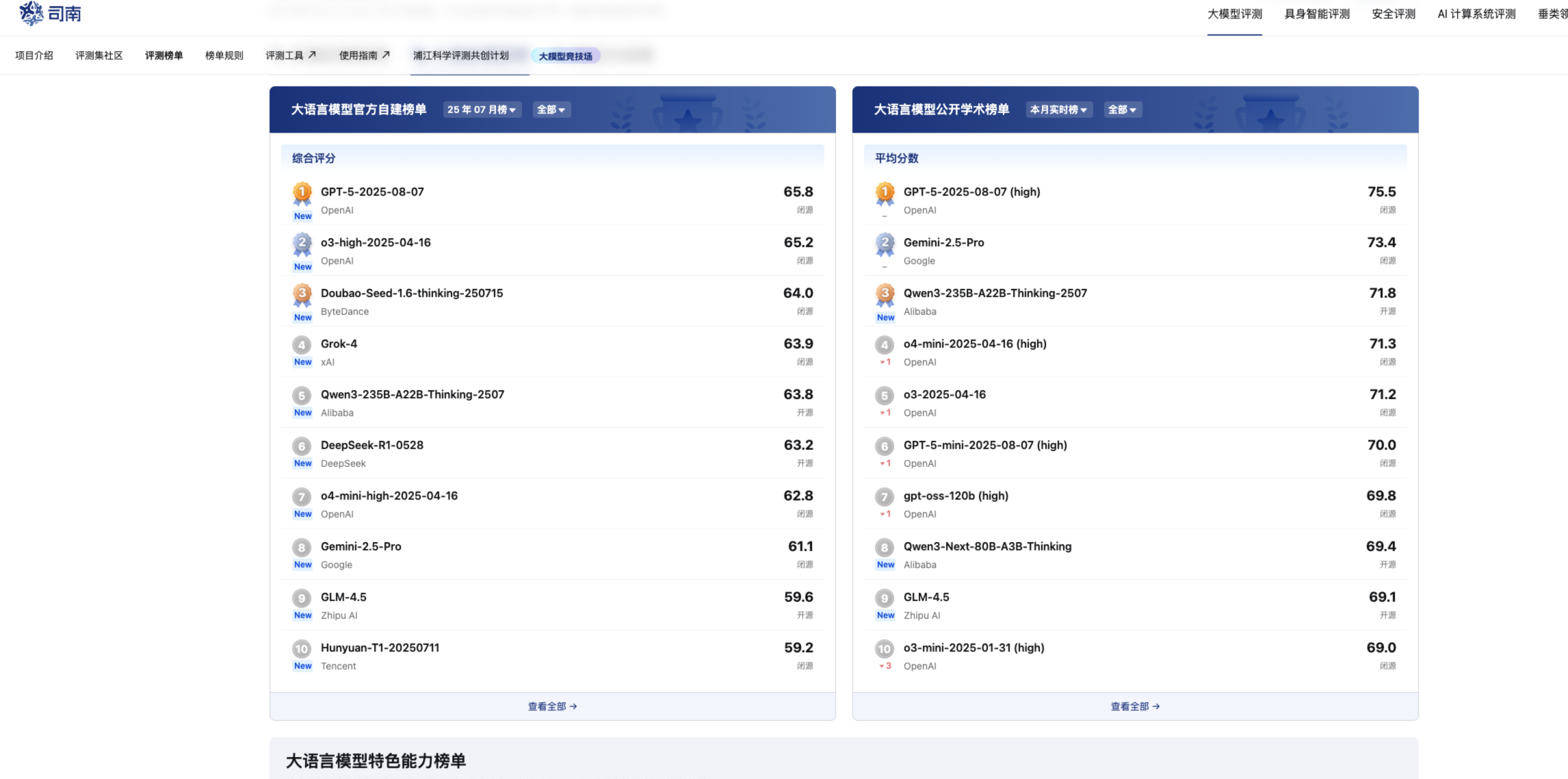
OpenCompass(CompassRank):
https://opencompass.org.cn/home
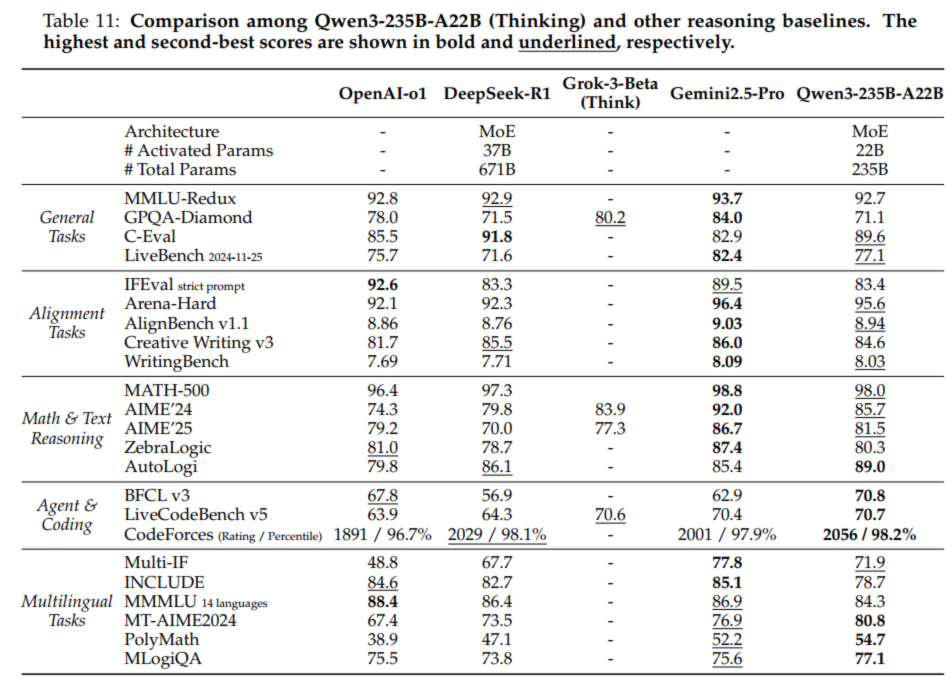
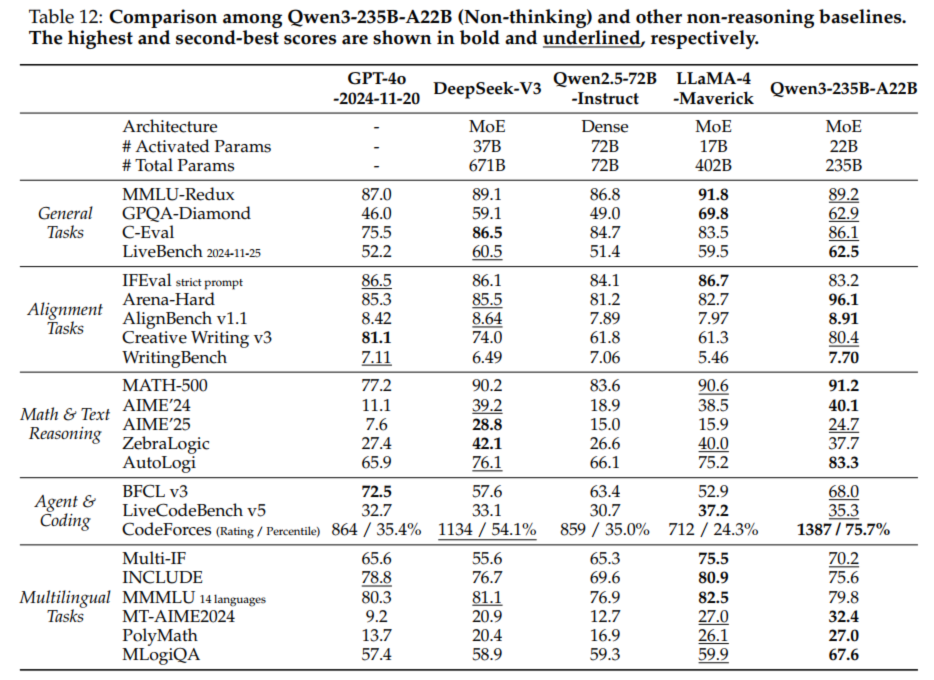
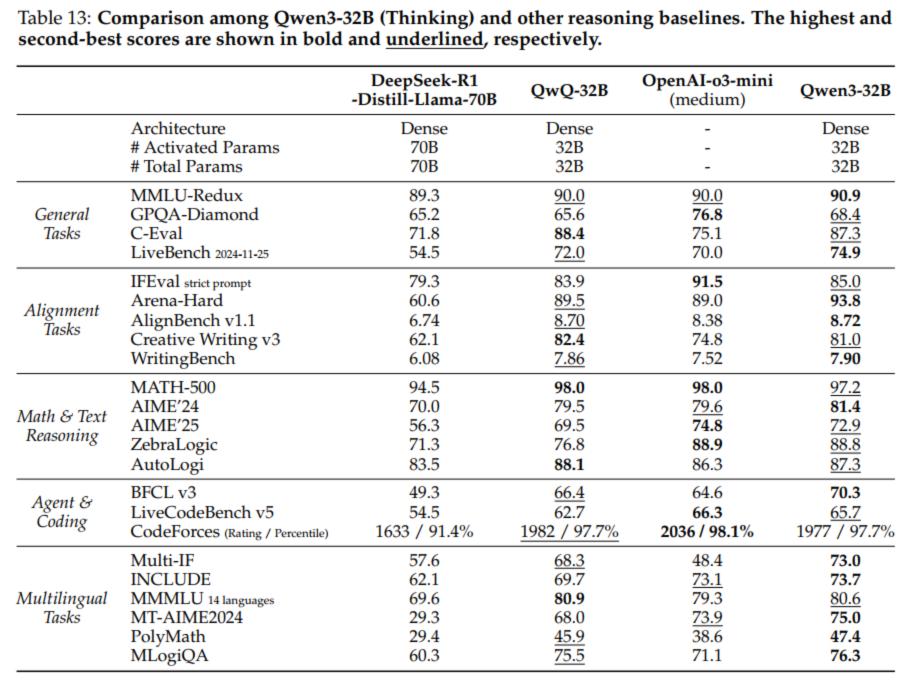
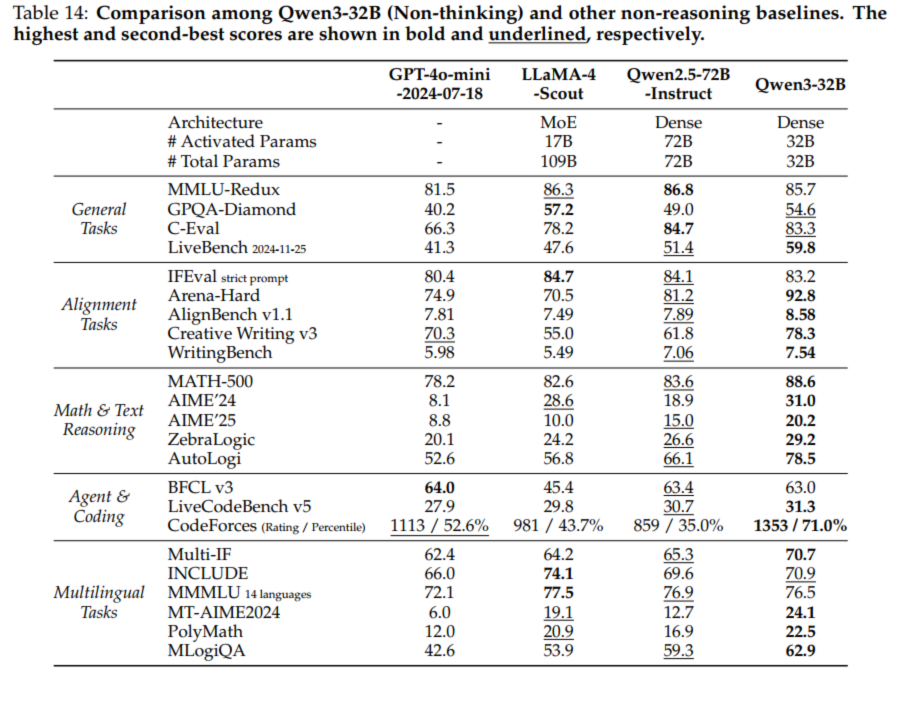
5.1 Qwen3
from: Qwen3 Technical Report可以看到Qwen3从多个角度进行评估,分别是:
-
General Tasks - 一般任务
-
Alignment Tasks - 对齐任务
-
Math & Text Reasoning - 数学与文本推理
-
Agent & Coding - 代理与编码
-
Multilingual Tasks - 多语言任务
5.2 Deepseek
https://github.com/deepseek-ai/DeepSeek-R1
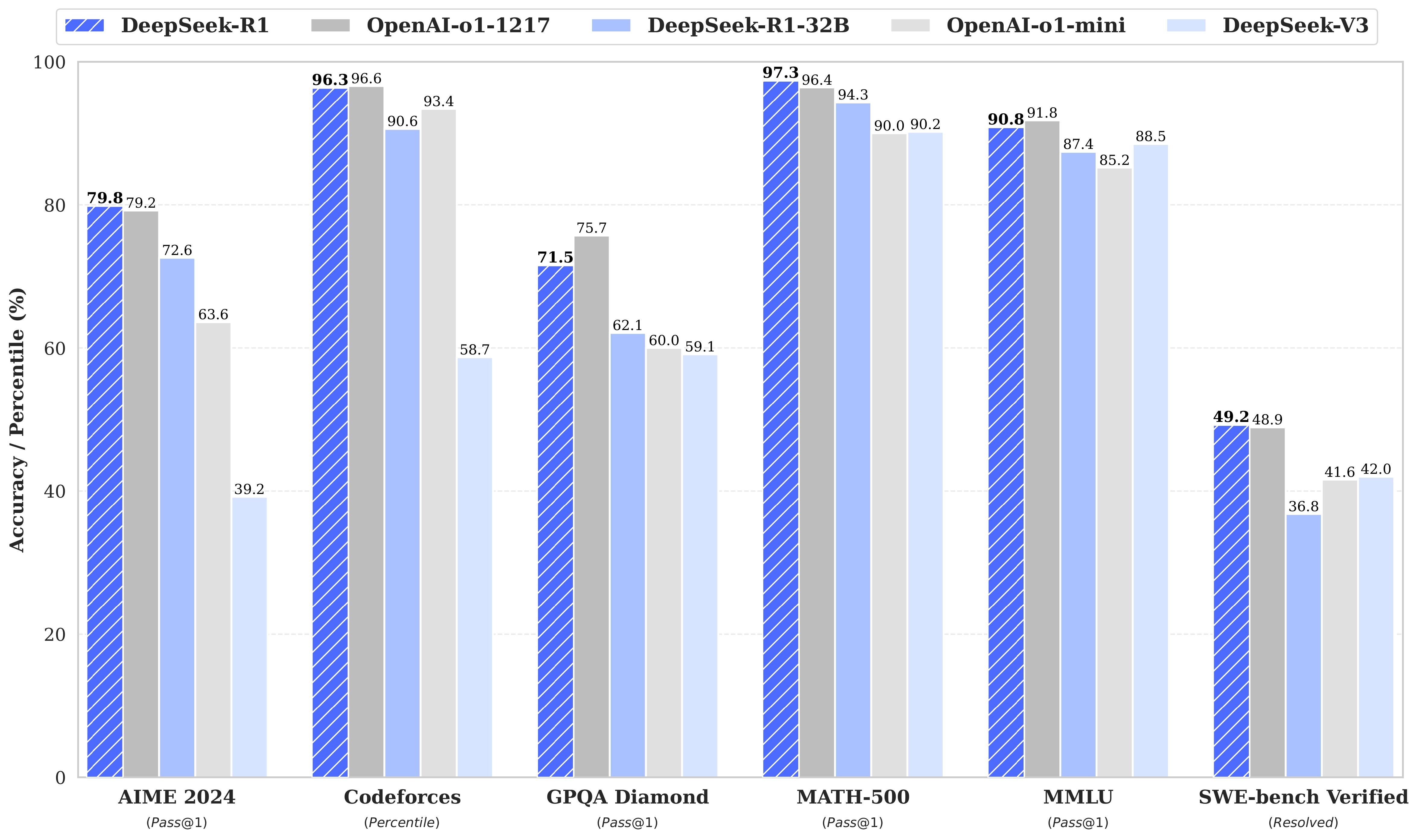
For all our models, the maximum generation length is set to 32,768 tokens. For benchmarks requiring sampling, we use a temperature of 0.6, a top-p value of 0.95, and generate 64 responses per query to estimate pass@1.
蒸馏模型:
| Model | AIME 2024 pass@1 | AIME 2024 cons@64 | MATH-500 pass@1 | GPQA Diamond pass@1 | LiveCodeBench pass@1 | CodeForces rating |
|---|---|---|---|---|---|---|
| GPT-4o-0513 | 9.3 | 13.4 | 74.6 | 49.9 | 32.9 | 759 |
| Claude-3.5-Sonnet-1022 | 16.0 | 26.7 | 78.3 | 65.0 | 38.9 | 717 |
| o1-mini | 63.6 | 80.0 | 90.0 | 60.0 | 53.8 | 1820 |
| QwQ-32B-Preview | 44.0 | 60.0 | 90.6 | 54.5 | 41.9 | 1316 |
| DeepSeek-R1-Distill-Qwen-1.5B | 28.9 | 52.7 | 83.9 | 33.8 | 16.9 | 954 |
| DeepSeek-R1-Distill-Qwen-7B | 55.5 | 83.3 | 92.8 | 49.1 | 37.6 | 1189 |
| DeepSeek-R1-Distill-Qwen-14B | 69.7 | 80.0 | 93.9 | 59.1 | 53.1 | 1481 |
| DeepSeek-R1-Distill-Qwen-32B | 72.6 | 83.3 | 94.3 | 62.1 | 57.2 | 1691 |
| DeepSeek-R1-Distill-Llama-8B | 50.4 | 80.0 | 89.1 | 49.0 | 39.6 | 1205 |
| DeepSeek-R1-Distill-Llama-70B | 70.0 | 86.7 | 94.5 | 65.2 | 57.5 | 1633 |
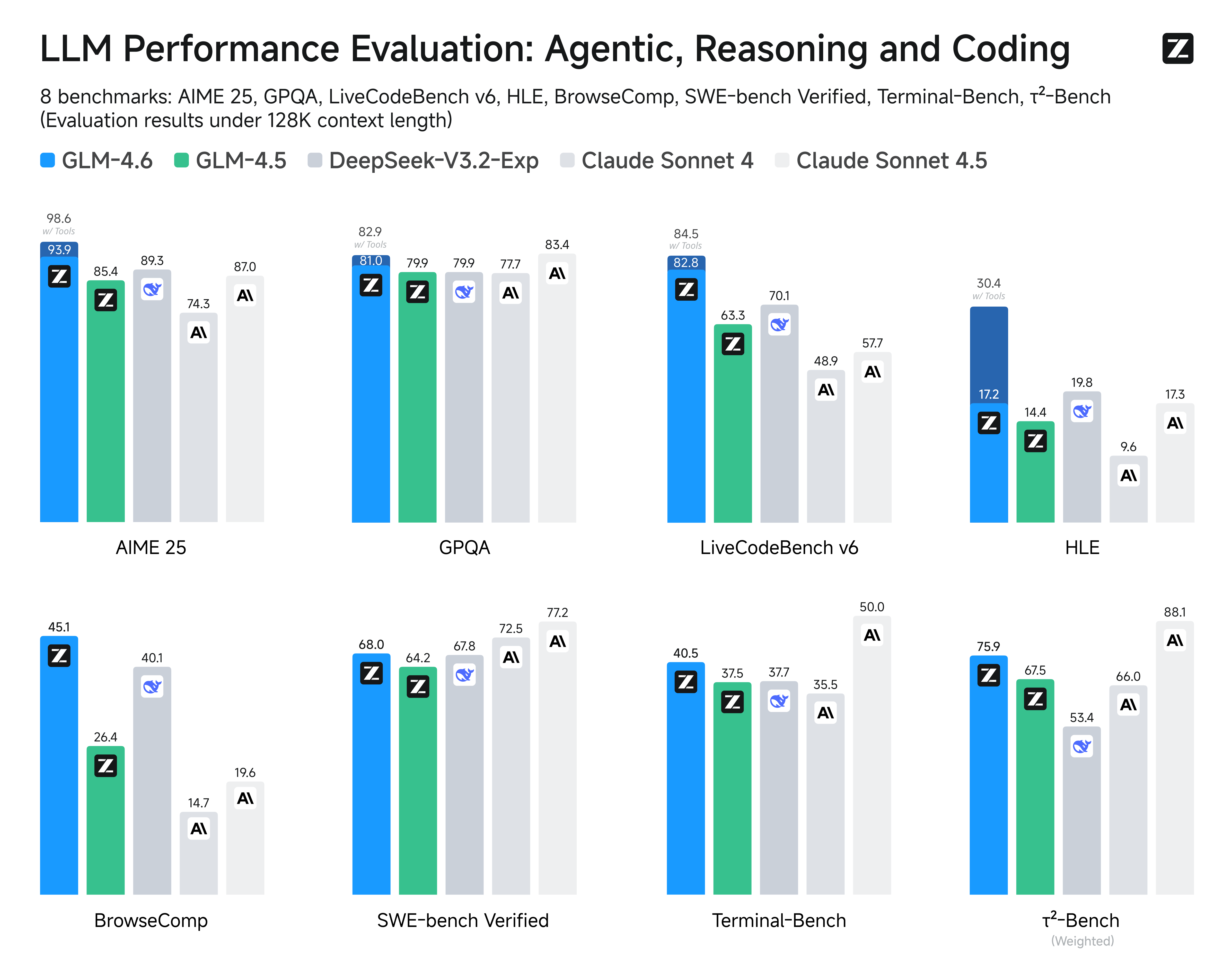
5.3 GLM-4.6

 浙公网安备 33010602011771号
浙公网安备 33010602011771号