


开源VLM模型一览
0 概述
**VLM可以做的任务类型**- 视觉定位/物体检测(Visual grounding)
- 图像和视频总结(image caption)
- 视觉问答(visual question answering)
- 图像-文本对比学习
- 生成式任务
- 对齐式任务文本解析和手写文档
- 图像分类
- 语义分割
- 图像文本检索
- 动作识别
开源的VLM系列:
- Qwen-VL系列---阿里
- GLM-VL系列---智谱AI
- Intern-VL系列 ---上海Ai Lab
- Kimi -VL----月之暗面
- Deepseek-VL2 ---深度求索
1 Qwen-vl系列
QWenVL是第一个版本,训练的模型较小(~9.6B),并且不支持高清分辨率的图像;QWen2-VL将模型的参数量增加到~70B,支持动态的分辨率;QWen2.5-VL将模型的数据量增加到4.1T token,并且借鉴了LLM中的RL和COT技术。 **Qwen3-VL**是目前 Qwen 家族最强的视觉-[语言模型],上下文长度**原生 256K、可拓展到 1M**,视频理解更强,**GUI 级视觉 Agent** 更稳,OCR 扩到 **32 种语言**;适合复杂多模态工作流与视频/长文档检索总结。1.1 Qwen-VL 2023.8 开创
Qwen系列首个视觉语言模型,基于**Qwen-7B**扩展,支持图像、文本、边界框作为输入,支持**448x448**的高分辨率图像,并对中文光学字符识别进行了优化。小结:QWen-VL和主流多模态框架非常像,对标的模型是Instruct-BLIP和LLaVA。作为初版的模型,QWen-VL的参数量较小、并且不支持动态分辨率的图像。
论文:《Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond》
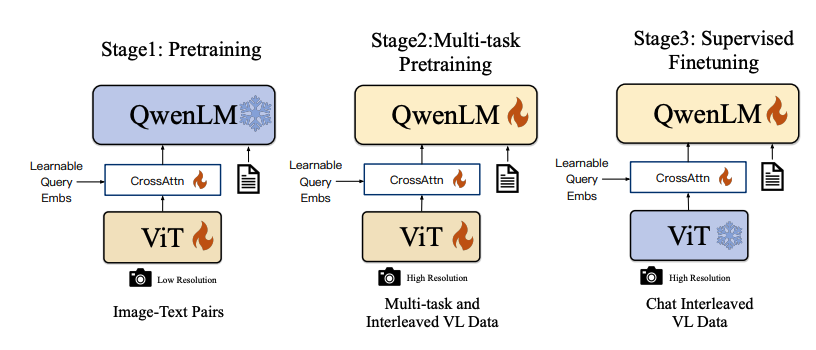
架构:以Qwen-LM作为大型语言模型基座,视觉编码器采用Openclip ViT-bigG,通过交叉注意力层与LLM集成。
• 输入输出:支持图像、文本、边界框作为输入,输出包括视觉问答、图像内文本识别、边界框定位等。
• 分辨率处理:依赖固定的输入分辨率448x448。
• 位置嵌入:采用标准的位置嵌入方式。
• 视频理解:视频理解能力有限,无明确的长视频处理能力。
• 训练方法:采用三阶段训练,包括预训练、多任务预训练和监督微调。

1.2 Qwen2-VL 2024.9 基座
核心创新是**Naive Dynamic Resolution(NDR)**与 **M-RoPE**,统一处理 **图像与视频**,提供 **2B/8B/72B** 尺寸,奠定了后续系列的高分辨率与视频建模底座。参数规模覆盖 **2B/8B/72B**。小结:QWen2-VL在QWen-VL的基础上大大地提升了参数量和数据量,性能可以对标GPT-4o。
论文:《Qwen2-VL: Enhancing Vision-Language Model’s Perception of the World at Any Resolution》
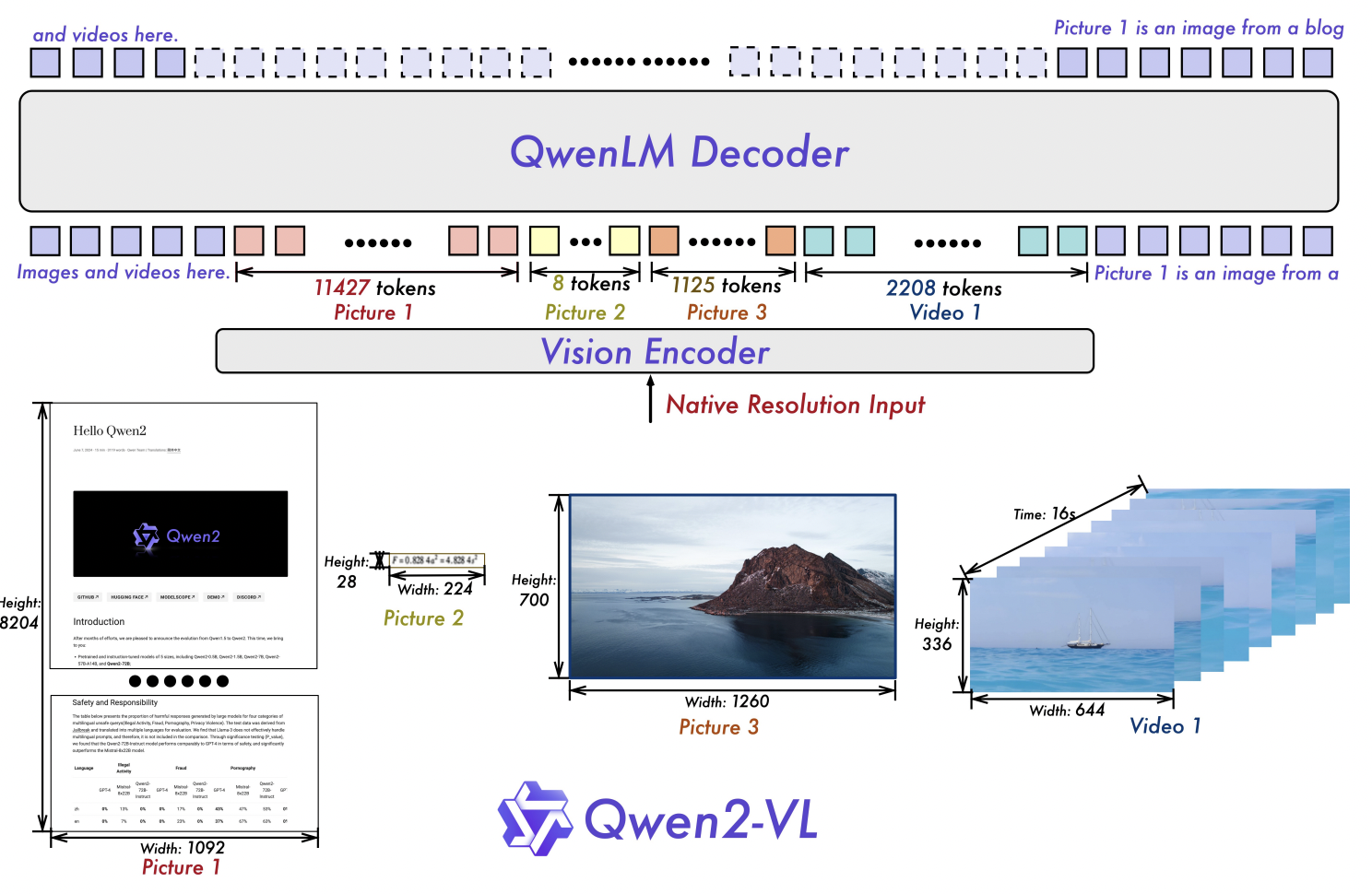
架构:
- 视觉编码器采用重新设计的ViT,参数量为675M,且跨LLM尺寸恒定。
- 输入输出:输入输出能力在Qwen-VL基础上进一步增强,支持更复杂的多模态任务。
- 分辨率处理:引入“朴素动态分辨率”机制,可将任意分辨率的图像处理为动态数量的视觉标记,解决了固定分辨率的局限性。
- 位置嵌入:引入“多模态旋转位置嵌入(M-RoPE)”,用于处理一维文本、二维视觉和三维视频模态的位置信息。
- 视频理解:视频理解能力显著提升,能够处理20分钟以上的视频。
- 训练方法:训练配方更复杂,整合了多阶段训练策略。

1.3 Qwen2.5-VL 2025.1 功能强化
在 2 代基础上大幅增强 文档解析(QwenVL HTML)、精确定位(BBox/Points + 稳定 JSON 输出)、长视频(>1h)事件定位、视觉 Agent 等能力;开源有 **3B/7B/72B **等尺寸可选,并提供 AWQ 量化。小结:QWen2.5-VL在很多任务上的表现都小幅度领先GPT-4o,并且模型的NLP能力也保持的很好。同时,QWen2.5-VL将LLM中最新的技术例如RL、COT等都用在了VLM上。
论文:《Qwen2.5-VL Technical Report》
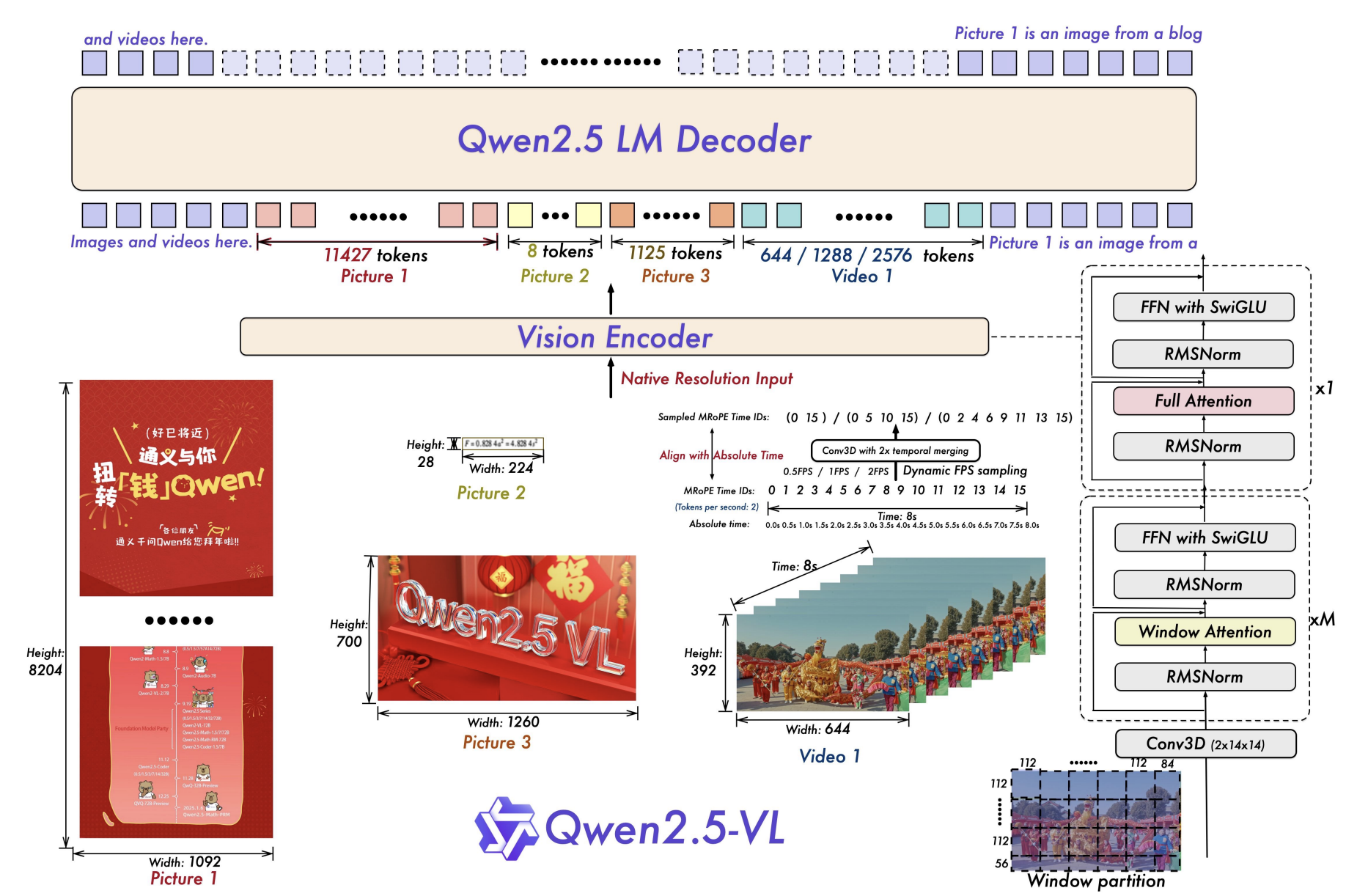
- 视觉编码器进一步升级,采用从头训练的带有窗口注意力的ViT,架构更紧密地与LLM设计原则对齐,如RMSNorm、SwiGLU等。
- 文档解析格式 QwenVL HTML,能够输出带 bbox 的 HTML 结构,适配票据、表单、论文、网页、手机截图等多场景。
- 精确定位与结构化 JSON:支持点/框/属性的稳定 JSON 输出(例如检测头部/手部关键点或机动车头盔状态)。
- 长视频理解:面向 >1 小时视频,新增“事件捕获”能力(按片段定位)。
- 视觉 Agent:直接进行电脑/手机的 GUI 操作(工具调用 + 推理)。
1.4 Qwen3-VL 2025.9 系统跃迁
目前 Qwen 家族最强的视觉-[语言模型],支持 **Dense 与 MoE 架构**,上下文长度 **原生 256K、可拓展到 1M**,视频理解更强,**GUI 级视觉 Agent** 更稳,OCR 扩到 **32 种语言**;适合复杂多模态工作流与视频/长文档检索总结。推出 MoE 与 Dense 系列,已放出 Qwen3-VL-235B-A22B 与 Qwen3-VL-30B-A3B(含 Thinking 版、FP8 版本);README 明确 原生 256K→1M上下文、视觉 Agent/视频/空间三维推理全面升级。
github:https://github.com/QwenLM/Qwen3-VL
模型架构升级:
- 交错式MRoPE:通过强大的位置嵌入,在时间、宽度和高度上实现全频谱分配,增强长时视频推理能力。
- DeepStack:融合多层级的ViT特征,以捕捉细粒度的细节并优化图像与文本的对齐效果。
- 文本-时间戳对齐:超越T-RoPE,实现精确的时间戳锚定事件定位,从而增强视频的时间建模能力。
Qwen3-VL 的目标,是让模型不仅能“看到”图像或视频,更能真正看懂世界、理解事件、做出行动。为此,我们在多个关键能力维度上做了系统性升级,力求让视觉大模型从“感知”走向“认知”,从“识别”迈向“推理与执行”。
关键升级:
- 视觉智能体(Visual Agent):Qwen3-VL 能操作电脑和手机界面、识别 GUI 元素、理解按钮功能、调用工具、执行任务,在 OS World 等 benchmark 上达到世界顶尖水平,能通过调用工具有效提升在细粒度感知任务的表现。
- 纯文本能力媲美顶级语言模型:Qwen3-VL 在预训练早期即混合文本与视觉模态协同训练,文本能力持续强化,最终在纯文本任务上表现与 Qwen3-235B-A22B-2507 纯文本旗舰模型不相上下 —— 是真正“文本根基扎实、多模态全能”的新一代视觉语言模型。
- 视觉 Coding 能力大幅提升:实现图像生成代码以及视频生成代码,例如看到设计图,代码生成 Draw.io/HTML/CSS/JS 代码,真正实现“所见即所得”的视觉编程。
- 空间感知能力大幅提升:2D grounding 从绝对坐标变为相对坐标,支持判断物体方位、视角变化、遮挡关系,能实现 3D grounding,为复杂场景下的空间推理和具身场景打下基础。
- 长上下文支持和长视频理解:全系列模型原生支持 256K token 的上下文长度,并可扩展至 100 万 token。这意味着,无论是几百页的技术文档、整本教材,还是长达两小时的视频,都能完整输入、全程记忆、精准检索,支持视频精确定位到秒级别时刻。
- 多模态思考能力显著增强:Thinking 模型重点优化了 STEM 与数学推理能力。面对专业学科问题,模型能捕捉细节、抽丝剥茧、分析因果、给出有逻辑、有依据的答案,在 MathVision、MMMU、MathVista 等权威评测中达到领先水平。
- 视觉感知与识别能力全面升级:通过优化预训练数据的质量和广度,模型现在能识别更丰富的对象类别——从名人、动漫角色、商品、地标,到动植物等,覆盖日常生活与专业领域的“万物识别”需求。
- OCR 支持更多语言及复杂场景:支持的中英外的语言从 10 种扩展到 32 种,覆盖更多国家和地区;在复杂光线、模糊、倾斜等实拍挑战性场景下表现更稳定;对生僻字、古籍字、专业术语的识别准确率也显著提升;超长文档理解和精细结构还原能力进一步提升。
模型性能
我们从十个维度全面评估了模型的视觉能力,涵盖综合大学题目、数学与科学推理、逻辑谜题、通用视觉问答、主观体验与指令遵循、多语言文本识别与图表文档解析、二维与三维目标定位、多图理解、具身与空间感知、视频理解、智能体任务执行以及代码生成等方面。整体来看,Qwen3-VL-235B-A22B-Instruct 在非推理类模型中多数指标表现最优,显著超越了 Gemini 2.5 Pro 和 GPT-5 等闭源模型,同时刷新了开源多模态模型的最佳成绩,展现了其在复杂视觉任务中的强大泛化能力与综合性能。
更多方面的性能可以查看官方文档。
1.5 Qwen-vl系列内对比:
| 维度 | Qwen2-VL | Qwen2.5-VL | Qwen3-VL |
|---|---|---|---|
| 图像分辨率与Token | NDR 动态分辨率 -> 动态 token | 延续并在定位/文档/多物体识别上强化 | 在 DeepStack 下进一步细粒度对齐 |
| 位置编码 | M-RoPE | M-RoPE + 任务侧适配 | Interleaved-MRoPE + 文本-时间戳对齐 |
| 视频 | 统一范式(图像/视频) | >1h 长视频 + 事件片段定位 | 更强长视频,秒级索引与时间对齐 |
| 文档解析 | 基础能力 | QwenVL HTML 结构化解析 | 解析质量/鲁棒性继续增强 |
| OCR | 强 | 多语种 OCR(票据、表格等结构化提取) | 32 语种,低光/模糊/倾斜更稳 |
| 定位/输出 | 基础 | BBox/Points + 稳定 JSON | 2D 定位更强,并向 3D空间推理扩展 |
| 视觉 Agent | 初步 | 可操作 PC/手机(工具/GUI) | GUI 交互更强(元素/功能理解、任务闭环) |
| 上下文长度 | 轻度长上下文 | 进一步增强(文档/视频工作流) | 原生 256K -> 1M(书本/小时级视频) |
| 尺寸/变体 | 2B/8B/72B | 3B/7B/72B(后有 32B)+ AWQ | Dense & MoE,如 235B-A22B、30B-A3B(含 FP8 版) |
2 GLM-VL系列
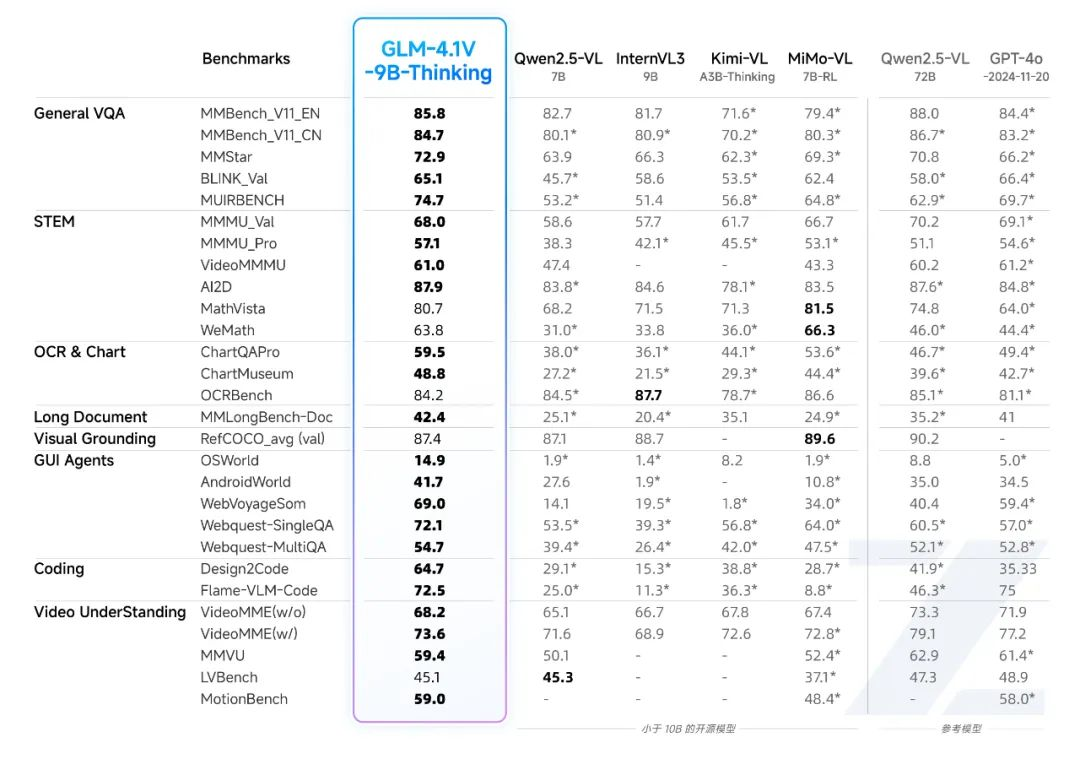
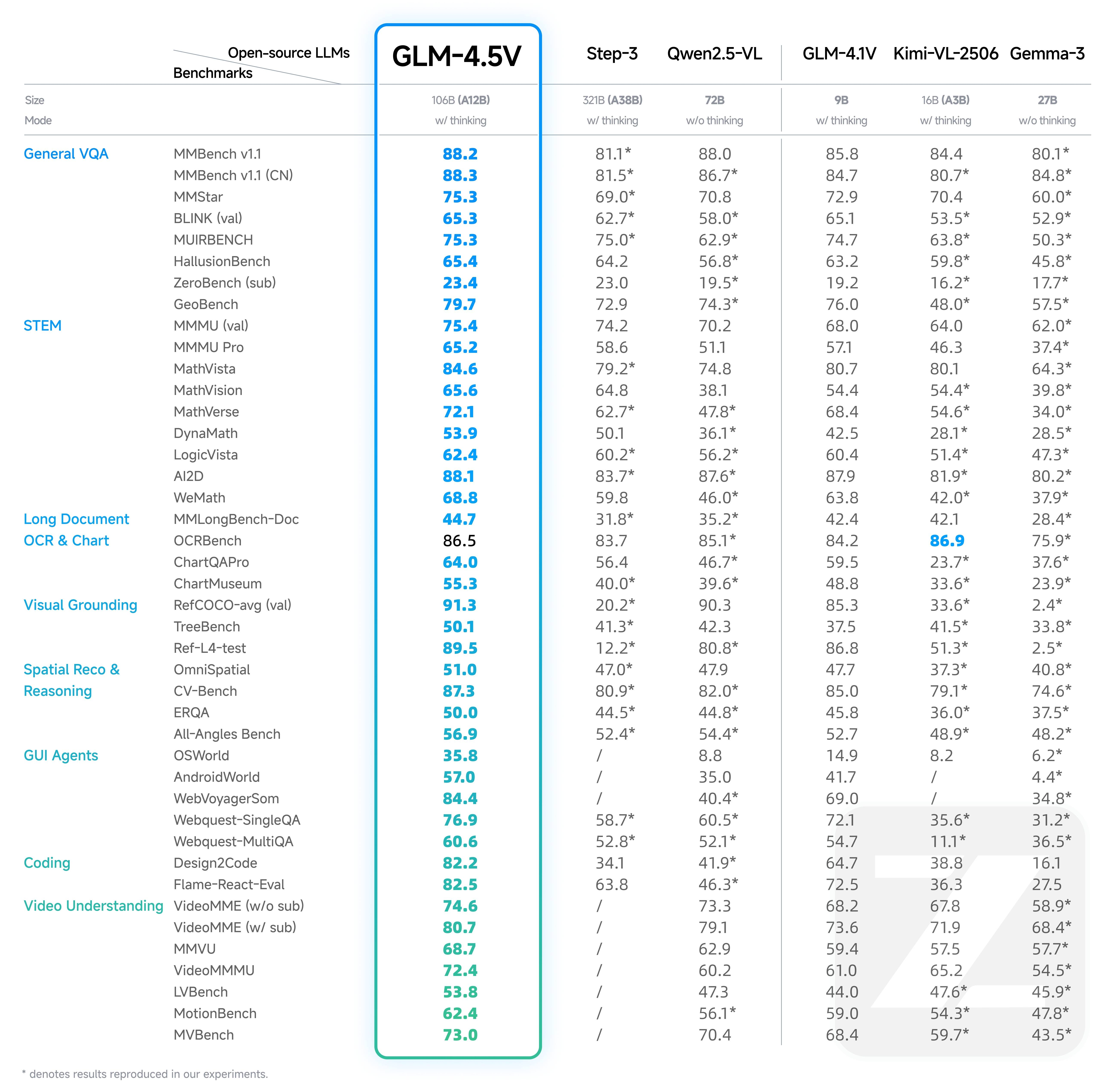
发布GLM-4.1V-9B-Thinking和GLM-4.5V两个模型,其中GLM-4.5V是一个参数量106B,激活12B的MOE结构的模型,且包含thinking和non-thinking两个。其中比较有亮点的是GLM-4.1V-9B-Thinking一个9B的模型在29个Benchmark上超过了Qwen2.5- VL -72B(non-thinking模型)。大模型的发展方向有两个,一个往大的方向发展:不断的探索scaling law。一个是往小的方向发展:参数量比较你小,但是性能比你好。所以GLM-4.1V-9B-Thinking一个9B参数的模型在多个方面超过一个72B的模型,还是很令人吃惊的。
GLM-4.1V-9B-Thinking成功的关键我觉得有两个:1. 高质量数据的构建(具体数量位置,数据集也没有开源)2. ReinforcementLearning with Curriculum Sampling (RLCS) ,RLCS在训练的过程通过样本的困难程度动态的去采样合适难度的样本(不要太难、也不要太简单,seed-1.5VL中有同样的思想),这个不是超过Qwen-72B的关键,关键其实还是在RL阶段构建的任务是综合的,包含各种任务,在训练方法上即包括RLVF也包含RLHF,并且两者结合。 对于大规模的RL,很容易训练不稳定,智普团队在这篇论文也给出一些发现和洞察,比如针对各个任务设计合适的奖励系统,要不然很容易遇到reward hacking等问题。
参考:GLM-VL系列论文解析
2.1 GLM-4.1V-Thinking 2025.7
由智谱AI与清华大学联合研发,采用Reinforcement Learning with Curriculum Sampling (RLCS)训练框架,通过大规模预训练构建高潜力基础模型,结合监督微调和强化学习,实现跨任务能力提升。在28个公共基准测试中,该模型**(9B参数)**几乎全面超越Qwen2.5-VL-7B,在18项任务上媲美甚至优于更大规模的Qwen2.5-VL-72B,并在长文档理解、STEM推理等任务上与GPT-4o表现相当或更优。论文:GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning
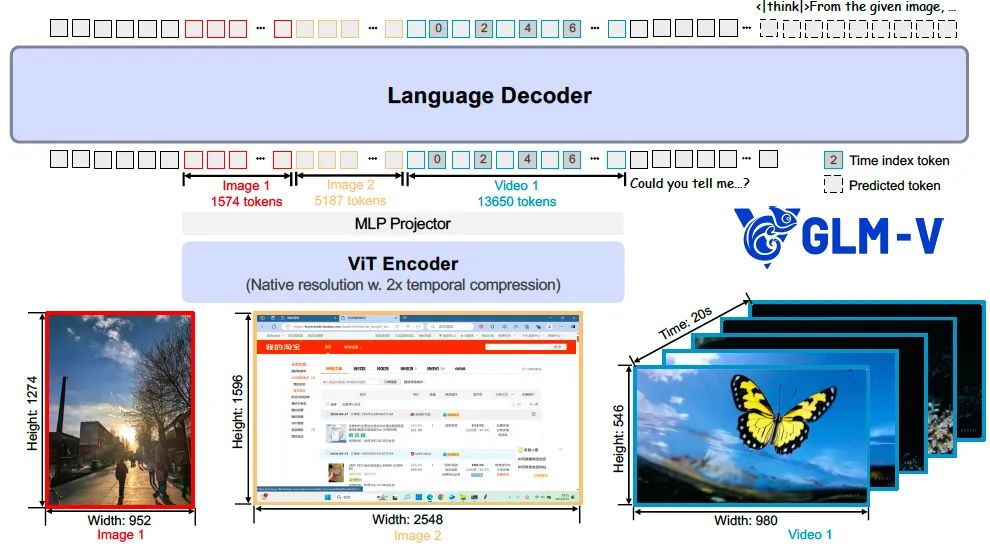
GLM-4.1V-Thinking 模型架构由三个核心模块组成:视觉编码器(ViT Encoder)、多层感知机适配器(MLP Projector)以及语言解码器(Language Decoder)。
我们选用 AIMv2-Huge 作为视觉编码器,GLM 作为语言解码器。在视觉编码器部分,我们将原始的二维卷积替换为三维卷积,从而实现对视频输入在时间维度上的下采样,有效提升了处理效率。对于静态图像输入,则通过复制帧的方式以保持输入格式的一致性。
为进一步增强模型对任意图像分辨率和宽高比的适应能力,我们引入了两项关键改进。
其一,融合二维旋转位置编码(2D-RoPE),使模型能够稳定处理极端宽高比(如超过200:1)和超高分辨率(如4K以上)的图像;
其二,为保留ViT预训练模型的原有能力,我们保留了其可学习的绝对位置嵌入,并通过双三次插值方式在训练过程中动态适配不同分辨率输入。
在语言解码器中,我们对原始的旋转位置编码(RoPE)进行了三维扩展(3D-RoPE)。这一设计显著增强了模型在多模态输入处理中的空间理解能力,同时保持了其在文本生成方面的原始性能。
模型能力:
GLM-4.1V-9B-Thinking 通过有效的混合训练融合了丰富的多模态模型能力,包括但不限于:
- 视频理解 : 能够解析最长两小时的视频内容,通过推理对视频中的时间、人物、事件和逻辑关系进行准确分析;
- 图像问 答 : 对图像中的内容进行深入分析和解答,具备较强的逻辑能力和世界知识;
- 学科 解题 : 支持对数学、物理、生物、化学等学科问题的看图解题,通过推理给出详细的思考过程;
- 文字识 别 : 对图片和视频中的文字和图表内容进行准确抽取和结构化输出;
- 文档解读 : 对金融、政务、教育等领域的文档内容进行准确的原生理解、抽取、提炼和问答;
- Grounding : 识别图片中的特定区域并抽取坐标位置,支持各种需要定位信息的下游任务;
- GUI Agent : 识别网页、电脑屏幕、手机屏幕等交互界面元素,支持点击、滑动等指令执行能力;
- 代码生成 : 能够基于输入的图片文字内容自动编写前端代码,看图写网页。
2.2 GLM-4.5V 2025.8
GLM-4.5V 是智谱新一代基于 MOE 架构的视觉推理模型,以 106B 的总参数量和 12B 激活参数量,在各类基准测试中达到全球同级别开源多模态模型 SOTA,涵盖图像、视频、文档理解及 GUI 任务等常见任务。推荐场景:
- 前端复刻:支持将网页截图或完整浏览录屏输入模型,自动解析布局与交互逻辑,高精度还原页面元素与二级页面结构,生成可交互的 HTML 代码,便于直接使用或二次优化。
- Grounding:可根据文本描述精准定位指定人物或物体,支持按外貌、衣着等多条件组合筛选。适用于安检、质检、内容审核、遥感监测等实业场景,定位精度高。
- GUI Agent:识别并理解屏幕画面,执行点击、滑动等操作指令,精准完成如 PPT 修改、Word 编辑等任务,全程自动化,适用于各类办公场景,为智能体操作任务提供可靠支持。
- 复杂长文档解读:支持对长文档进行深度解析,处理文本、表格、图形等多模态内容,可总结、翻译、提取关键信息,并在原有观点基础上提出新见解,适用于研报分析、科研、教育等专业场景。
- 图像识别和推理:结合强推理能力与丰富世界知识,在无需搜索的情况下推断图像背景信息。支持将图表、曲线等内容转为结构化数据,精确还原内容与布局,适用于无电子版表格的快速数字化处理,避免手动录入的繁琐与错误。
- 视频理解:支持解析长时视频内容,精准识别并推理视频中的时间线、人物关系、事件发展及因果逻辑,适用于安防监控、影视内容分析、舆情事件追踪等领域,实现高效的视频信息抽取与洞察。
- 学科解题:具备图文感知、知识储备与推理能力,能够解决复杂的图文结合题目,适用于 K12 教育场景中的解题和讲解需求。
3 Intern-vl系列
InternVL系列是Shanghai AI Laboratory开源的一系列多模态大模型。InternVL (2023/12)
创新点:
- 大规模视觉编码器(InternViT-6B),解决参数规模不匹配问题。
- 双组件架构与语言中间件(InternViT-6B + QLLaMA)。
- 渐进式对齐策略,包括对比学习和生成学习。
- 越的性能表现,在32个通用视觉-语言基准测试中领先。
InternVL 1.5 (2024/4)
主要创新点:
- 强大的视觉编码器,复用了V1.0中提出的6B大视觉模型。
- 动态高分辨率技术,支持4K分辨率输入。
- 高质量双语数据集,构建了覆盖常见场景和文档图像的中英文高质量数据集。
- 整个模型架构非常简洁,框架允许图像模态和已经编码好词汇表的文本一起输入到InternLM2-Chat-20B。I
InternVL 3.5 (2025/08)
论文:InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
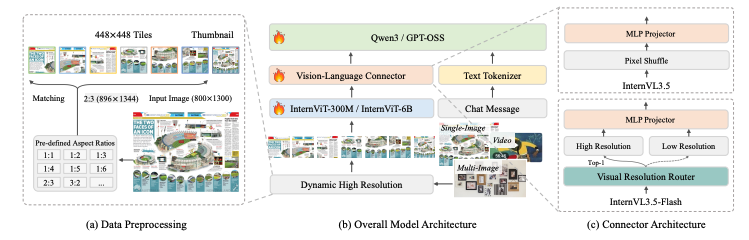
主要创新点:
- 级联强化学习(Cascade RL),结合离线RL和在线RL的两阶段训练策略。
- 视觉分辨率路由器(ViR),动态调整图像token压缩率,提升处理高分辨率图像的效率。
- 解耦视觉-语言部署(DvD),将视觉编码器和语言模型分离到不同的GPU服务器上,并行异步执行。
- 模型规模与能力,提供从1B到241B等多种参数规模的版本,支持GUI交互和具身智能等新型智能体任务。
- 综合性能与影响:InternVL 3.5,尤其是其最大的InternVL3.5-241B-A28B模型,在包括通用多模态理解、复杂推理、纯文本任务以及智能体任务在内的广泛基准测试中,取得了开源模型中的最先进(SOTA)性能。
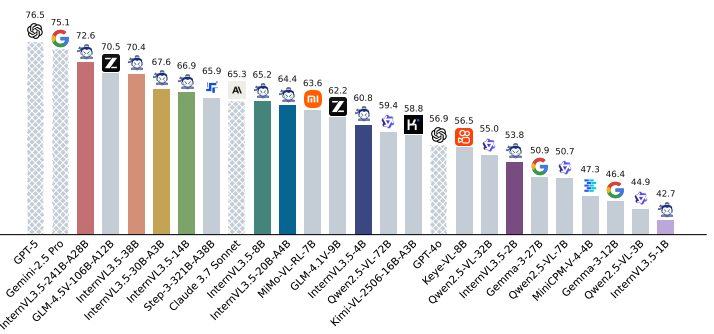
InternVL3.5的主要功能
多模态感知:在图像、视频问答等多模态感知任务中表现出色,241B-A28B 模型以 74.1 的平均得分超越现有开源模型,接近商业模型 GPT-5(74.0)。
多模态推理:在多学科推理基准 MMMU 中获得 77.7 分,较前代提升超 5 个百分点,位列开源榜首。
文本能力:在 AIME、GPQA 及 IFEval 等多个基准中,模型可以取得 85.3 的均分,处于开源领先。
GUI 智能体:强化了 GUI 智能体能力,可实现跨平台自动化操作,例如在 ScreenSpot GUI 定位任务中以 92.9 分超越主流开源模型。
具身空间推理:具备更强的 grounding 能力,可以泛化到全新的复杂具身场景,支持可泛化的长程物体抓取操作。
矢量图形处理:在 SGP-Bench 以 70.7 分刷新开源纪录,能够有效应用于网页图形生成与工程图纸解析等专业场景。
4 Kimi-VL系列
Kimi-VL系列是由Moonshot AI(月之暗面)开发的开源视觉语言模型,专注于多模态理解和推理能力。发布时间:• Kimi-VL:2025年4月11日正式发布。
• Kimi-VL-Thinking:与Kimi-VL同时发布,作为支持长思考推理能力的版本。
代码和模型发布的地址:https://github.com/MoonshotAI/Kimi-VL
Kimi-VL的架构由三个主要部分组成:原生分辨率视觉编码器(MoonViT)、MLP投影器和MoE语言模型,
- 视觉编码器(MoonViT):能够原生处理不同分辨率的图像,无需复杂的子图像分割和拼接操作。
- MLP投影器:用于将视觉特征投影到语言模型的嵌入空间。
- MoE语言模型:基于Moonlight模型,具有高效的参数激活机制,支持长链推理(CoT)。
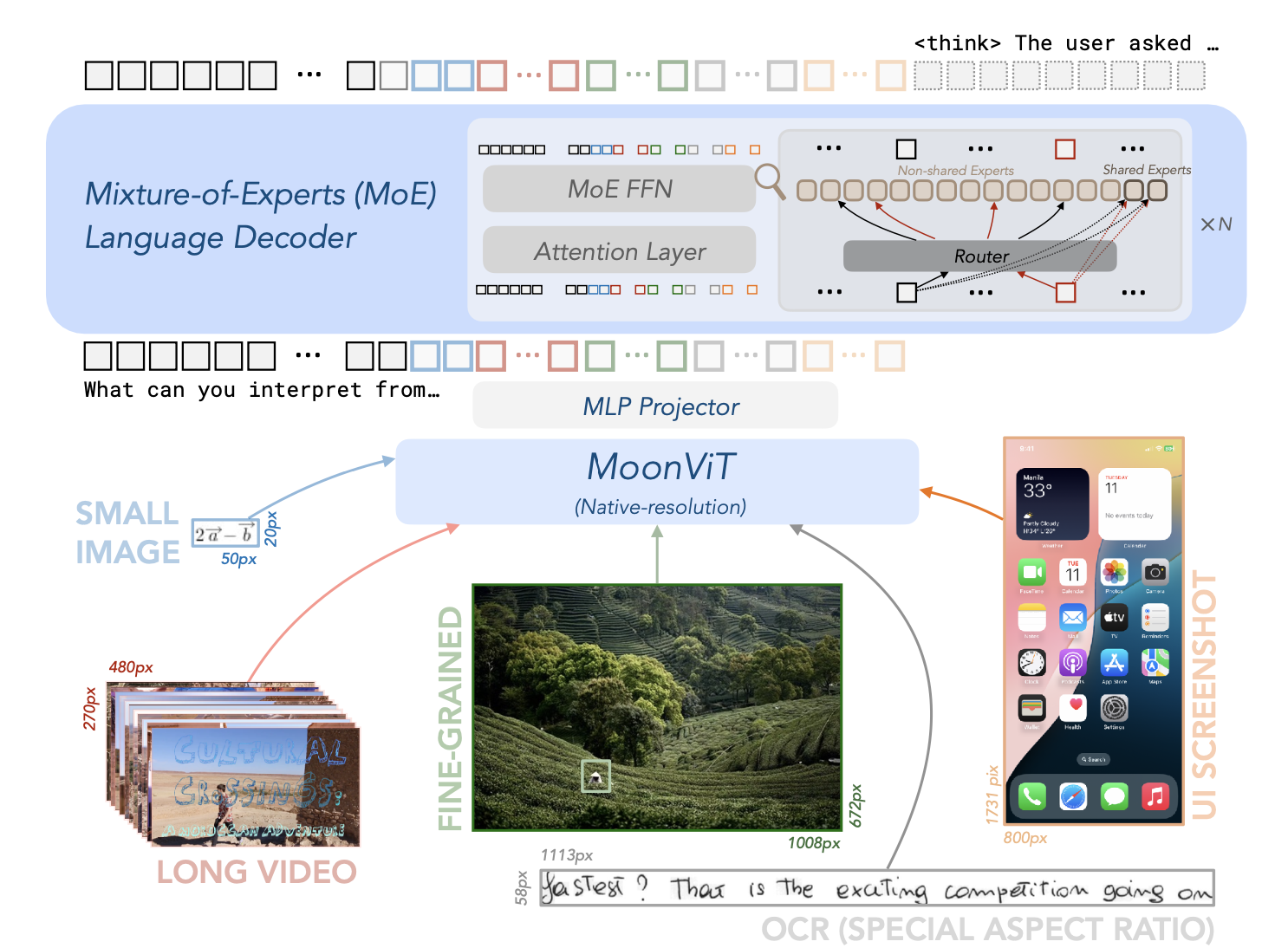
作为一个高效的模型,Kimi-VL能够稳健地处理多种任务(细粒度感知、数学、大学水平的问题、OCR、代理等),这些任务覆盖了广泛的输入形式(单图像、多图像、视频、长文档等)。与现有的10B级密集型视觉语言模型(VLMs)和DeepSeek-VL2(A4.5B)的简要比较:
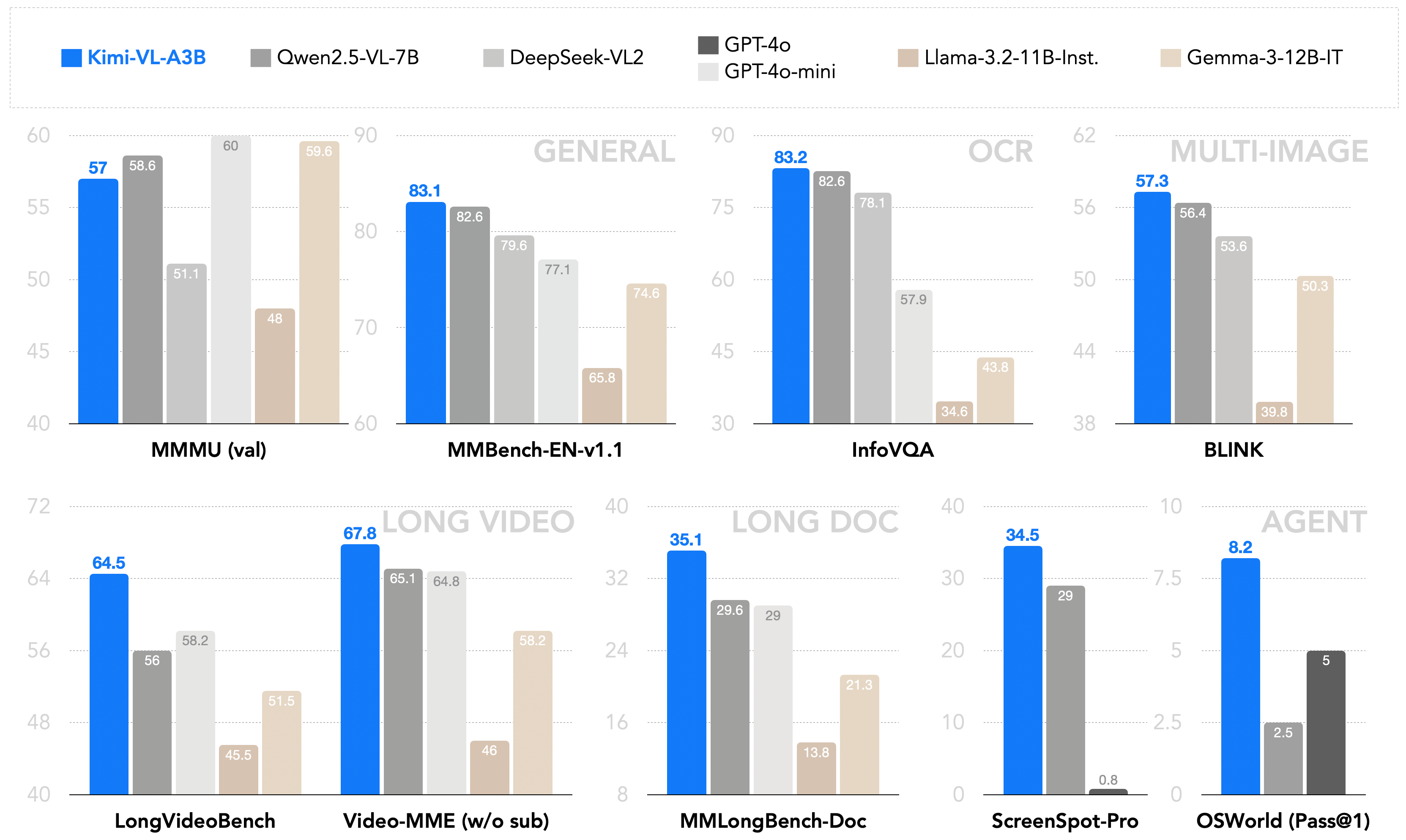
凭借有效的长思考能力,Kimi-VL-A3B-Thinking(2504版本)能够在MathVision基准测试中达到与30B/70B前沿开源视觉语言模型(VLMs)相当的性能:
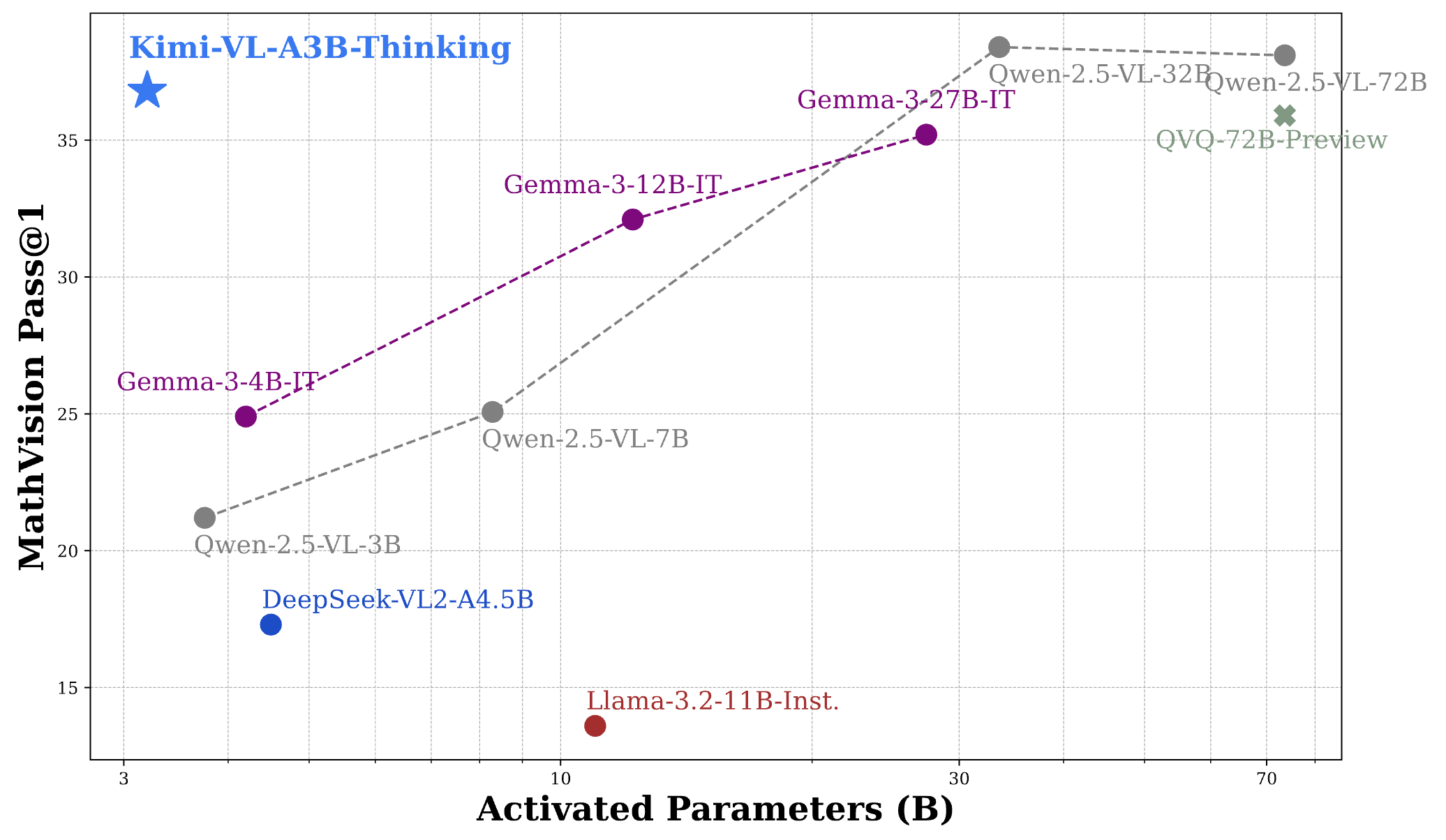
对于常见的通用多模态感知和理解、OCR、长视频和长文档、视频感知以及操作系统代理(OS-agent)的使用,我们推荐使用Kimi-VL-A3B-Instruct进行高效的推理;同时,我们的新思考版本Kimi-VL-A3B-Thinking-2506在实现更好的多模态推理技能的同时,也具有出色的多模态感知、长视频和长文档以及操作系统代理定位能力。
| Model | #Total Params | #Activated Params | Context Length |
|---|---|---|---|
| Kimi-VL-A3B-Thinking-2506 | 16B | 3B | 128K |
| Kimi-VL-A3B-Instruct | 16B | 3B | 128K |
| Kimi-VL-A3B-Thinking (deprecated) | 16B | 3B | 128K |
5 DeepSeek-VL系列
DeepSeek-VL发布时间:2024年3月
版本:1.3B和7B参数规模,共4个版本(包括基础版和对话版)
DeepSeek-VL2 2024年12月
https://github.com/deepseek-ai/DeepSeek-VL2
论文标题:DeepSeek-VL2: Mixture-of-Experts Vision-Language Models for Advanced Multimodal Understanding
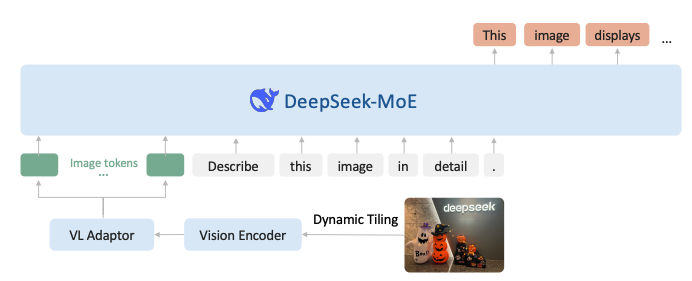
DeepSeek-VL2 在 DeepSeek-VL 基础上做了两个主要升级。
- 视觉组件结合了 Dynamic Tiling 视觉编码策略,旨在处理具有不同纵横比的高分辨率图像。
- 语言组件利用具有多头潜在注意力机制的DeepSeek MoE模型,该机制将键值缓存压缩成潜在向量,以实现高效推理和高吞吐量。
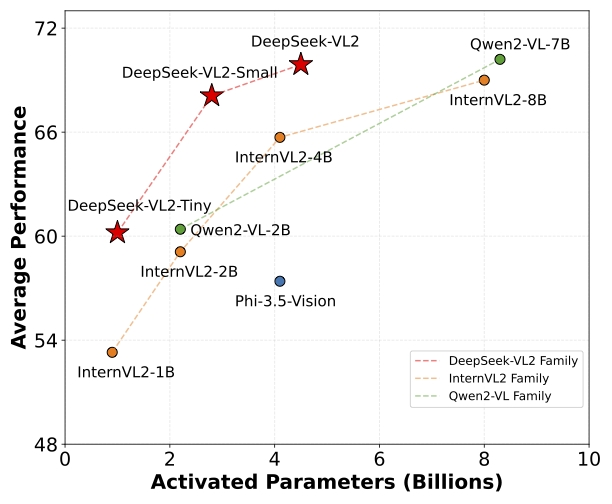
在改进的视觉语言数据集上进行训练,在各种任务中展示了优越的能力,包括 VQA、OCR、文档/表格/图表理解和视觉定位(Visual grounding)等。DeepSeek-VL2系列有三个模型:DeepSeek-VL2-Tiny、DeepSeek-VL2-Small和DeepSeek-VL2,分别具有10亿、28亿和45亿个激活参数。
参考:
1,Qwen3-VL 全面解析:从 Qwen2-VL → Qwen2.5-VL → Qwen3-VL 的三代进化。
2,Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
3,Qwen2-VL: Enhancing Vision-Language Model’s Perception of the World at Any Resolution
4,Qwen2.5-VL Technical Report
5,https://github.com/QwenLM/Qwen3-VL
6,GLM-4.1V-Thinking: Towards Versatile Multimodal Reasoning with Scalable Reinforcement Learning
7,InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency

 浙公网安备 33010602011771号
浙公网安备 33010602011771号