
自动驾驶
自动驾驶开发流程
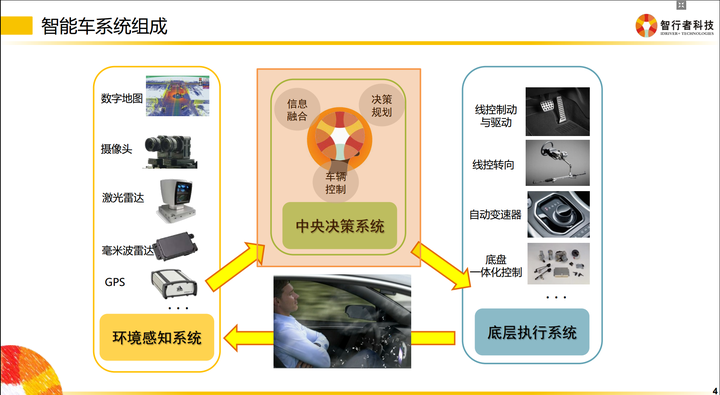
实现一个智能驾驶系统,会有几个层级:
感知层 → 融合层 → 规划层 → 控制层
更具体一点为:
传感器层 → 驱动层 → 信息融合层 → 决策规划层 → 底层控制层
各个层级之间都需要编写代码,去实现信息的转化。
最基本的层级有以下几类:采集及预处理、坐标转换、信息融合
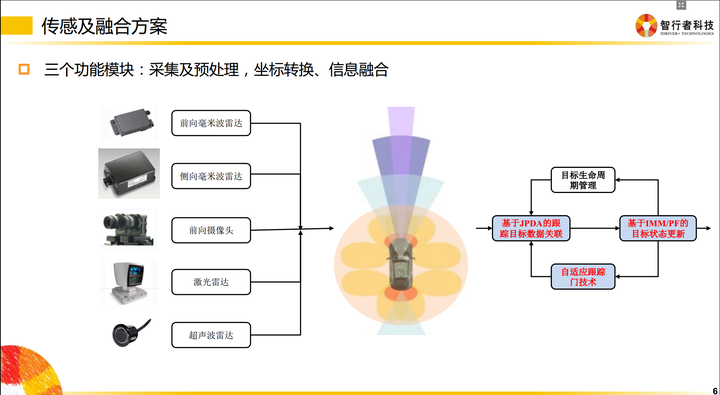
采集
传感器跟我们的PC或者嵌入式模块通信时,会有不同的传输方式。
比如我们采集来自摄像机的图像信息,有的是通过千兆网卡实现的通信,也有的是直接通过视频线进行通信的。再比如某些毫米波雷达是通过CAN总线给下游发送信息的,因此我们必须编写解析CAN信息的代码。
不同的传输介质,需要使用不同的协议去解析这些信息,这就是上文提到的“驱动层”。
通俗地讲就是把传感器采集到的信息全部拿到,并且编码成团队可以使用的数据。
预处理
传感器的信息拿到后会发现不是所有信息都是有用的。
传感器层将数据以一帧一帧、固定频率发送给下游,但下游是无法拿每一帧的数据去进行决策或者融合的。为什么?
因为传感器的状态不是100%有效的,如果仅根据某一帧的信号去判定前方是否有障碍物(有可能是传感器误检了),对下游决策来说是极不负责任的。因此上游需要对信息做预处理,以保证车辆前方的障碍物在时间维度上是一直存在的,而不是一闪而过。
这里就会使用到智能驾驶领域经常使用到的一个算法——卡尔曼滤波。
坐标转换
坐标转换在智能驾驶领域十分重要。
传感器是安装在不同地方的,比如毫米波(上图中紫色区域)是布置在车辆前方的;当车辆前方有一个障碍物,距离这个毫米波雷达有50米,那么我们就认为这个障碍物距离汽车有50米吗?
不是的!因为决策控制层做车辆运动规划时,是在车体坐标系下完成的(车体坐标系一般以后轴中心为O点),因此毫米波雷达检测到的50米,转换到自车坐标系下,还需要加上传感器到后轴的距离。最终所有传感器的信息,都是需要转移到自车坐标系下的,这样所有传感器信息才能统一,供规划决策使用。
同理,摄像机一般安装在挡风玻璃下面,拿到的数据也是基于摄像机坐标系的,给下游的数据,同样需要转换到自车坐标系下。
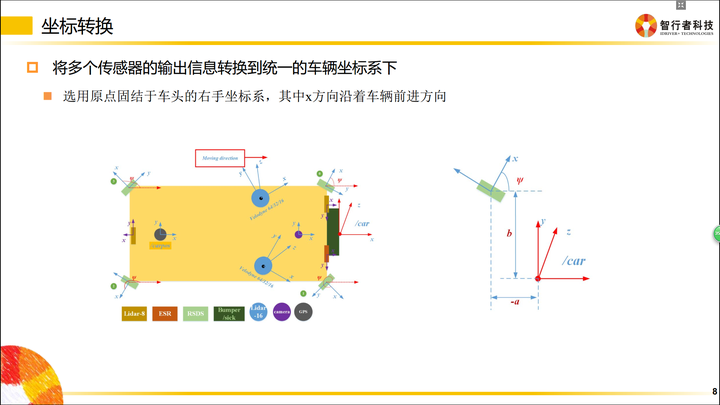
自车坐标系:拿出你的右手,以大拇指 → 食指 → 中指 的顺序开始念 X、Y、Z
然后把手握成如下形状:
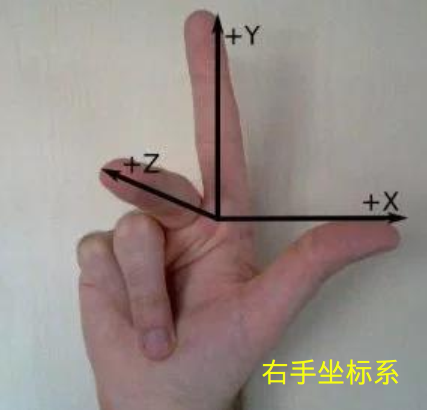
把三个轴的交点(食指根部)放在汽车后轴中心,Z轴指向车顶,X轴指向车辆前进方向。
各个团队可能定义的坐标系方向不一致,只要开发团队内部统一即可。
信息融合
信息融合是指把相同属性的信息进行多合一操作。
比如摄像机检测到了车辆正前方有一个障碍物,毫米波也检测到车辆前方有一个障碍物,激光雷达也检测到前方有一个障碍物,而实际上前方只有一个障碍物,所以我们要做的是把多传感器下这辆车的信息进行一次融合,以此告诉下游,前面有一辆车,而不是三辆车。
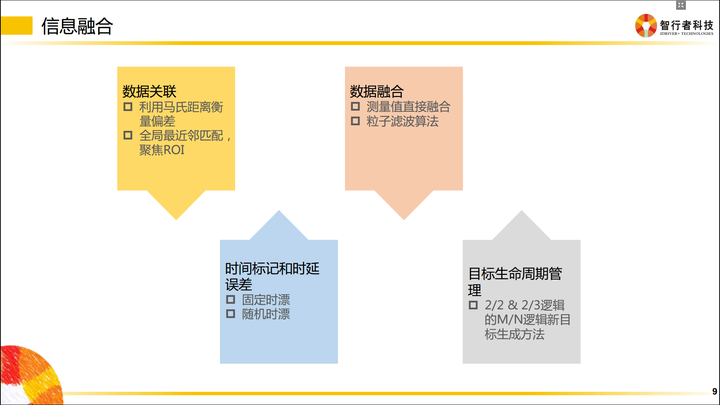
当然,信息融合中还涉及时延的补偿,具体如下:
对于一些大容量数据,确实不能以很高的频率发送(比如10Hz,100ms才发送一次)。这样的数据对高速行驶中的汽车来说,肯定会有偏差。
这些偏差我们算一下:
传感器检测到前方有一个静止障碍物,我100ms之后收到了这个传感器的信息,告诉我这个障碍物离我有30m。如果自车这时正以60KM/h的速度行驶,则这100ms,自车行驶了60 / 3.6 * 0.1 = 1.67m。
所以实际上这个障碍与我的距离为31.67m。
所以面对通信中产生的时延问题,尤其是低频率的信息,一定要考虑时延产生的后果。
时延补偿的另外一个问题:程序处理时,不能保证任何时候都是按固定的频率发送的。
这取决于硬件系统当时的环境,可能温度高了,性能下降,处理速度变慢,10Hz 的发送频率变成了 8Hz。如果我们的程序还是按固定的100ms去计算时延导致的偏差,必定会出现计算错误的情况。
因此我们需要引入时间戳,即在我们发送的信息中加入当前的系统时间,通过两帧数据的时间差来判断接受到的信号到底延时了多久,这种方式比根据频率判断来得更准确。
决策规划
这一层次主要设计的是拿到融合数据后,如何正确做规划。
规划包含纵向控制和横向控制。
纵向控制即速度控制,表现为 什么时候加速,什么时候制动。
横向控制即行为控制,表现为 什么时候换道,什么时候超车等。
个人对这一块不是很了解,不敢妄作评论。
从零开始学习无人驾驶技术 --- 车道检测
前言
个人兴趣爱好,最近在学习一些无人驾驶相关的技术,便萌生了循序渐进的写一系列文章的想法,这是第一篇。文章主要会以Udacity为主线,综合自己在学习过程中搜集的各种材料,取其精华,补其不足,力求通俗易懂,理论明确,实战有效,即作为一个学习总结,potentially又可以帮助对无人驾驶有兴趣但是零基础的朋友们 —— 注意这里的零基础是指未接触过无人驾驶领域,本系列还是需要一些简单的数学和机器学习知识。
因为本文是从零开始的第一篇,这里的车道检测是基础版本,需要满足几个先决条件:(1)无人车保持在同车道的高速路中行驶(2)车道线清晰可见(3)无人车与同车道内前车保持足够远的距离。
TLDR (or the take-away)
一个基础版的车道检测步骤主要分为以下几点:
- Gray Scale Transformation
- Gaussian Smoothing
- Canny Edge Detection
- ROI (Region of Interest) Based Edge Filtering
- Hough Transformation
- Lane Extrapolation
代码:Github链接
最后的效果如下视频所示,其中红线表示自动检测到的车道。
从图片开始谈起
无人车往往配备有数个camera,常见的情况是有一个camera固定在车的前方,用来perceive前方道路情况,生成视频。计算机对该视频进行分析,综合其他sensor的信息,对车辆行为进行指导。视频是由图片组成,如果能够成功检测图片上的车道,那我们就几乎解决了车道检测问题。下面是一张车辆行驶过程中的图片,让我们动手吧!
import matplotlib.image as mplimg
img = mplimg.imread('lane.jpg')

Gray Scale Transformation
这个变换比较简单,是将RGB图片转换成灰度图片,用来作为Canny Edge Detection的输入。
import cv2
gray = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
# Note that if you use cv2.imread() to read image, the image will
# be in format BGR.

Gaussian Smoothing
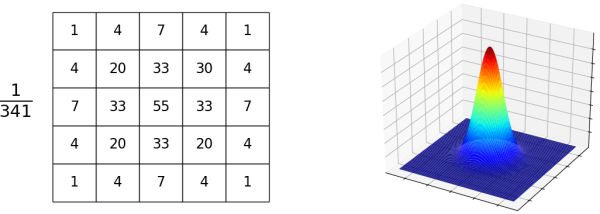
Gaussian Smoothing是对图片apply一个Gaussian Filter,可以起到模糊图片和消除噪声的效果。其基本原理是重新计算图片中每个点的值,计算时取该点及其附近点的加权平均,权重符合高斯分布。下图左侧展示了一个kernel_size = 5的Gaussian Filter,55是高斯分布的中心点,341是网格中所有值的和。假设网格矩阵为,图片为,新图片为,则:
Gaussian Filter是一种低通过滤器,能够抑制图片中的高频部分,而让低频部分顺利通过。那什么是图片的高频部分呢?下图给出了一个比较极端的例子。爱好摄影的朋友们都知道相机ISO适当时能够得到右侧图片,画质细腻;如果ISO过大,就会导致产生左侧图片,画质差,噪点多。这些噪点就是图片中的高频部分,表示了像素值剧烈升高或降低。

介绍完了Gaussian Filter,现在可以将其应用到我们的灰度图片上:
blur_ksize = 5 # Gaussian blur kernel size
blur_gray = cv2.GaussianBlur(gray, (blur_ksize, blur_ksize), 0, 0)

Canny Edge Detection
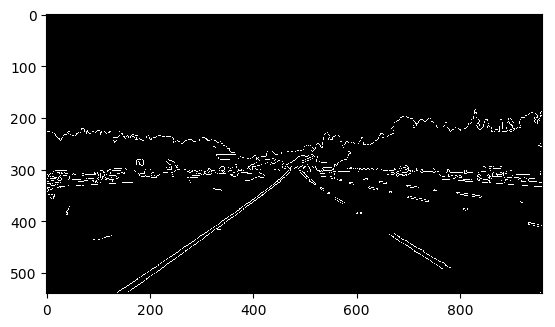
John F. Canny在1986年发明了Canny Edge Detection技术,其基本原理是对图片中各个点求gradient,gradient较大的地方往往是edge。Canny Edge Detection精妙的地方在于它有两个参数:low_threshold和high_threshold。算法先比较gradient与这两个threshold的关系,如果gradient > high_threshold,就承认这是一个edge point;如果gradient < low_threshold,就断定这不是edge point;对于其他的点,如果与edge point相连接,那么这个点被认为也是edge point,否则不是。
canny_lthreshold = 50 # Canny edge detection low threshold
canny_hthreshold = 150 # Canny edge detection high threshold
edges = cv2.Canny(blur_gray, low_threshold, high_threshold)
ROI Based Edge Filtering
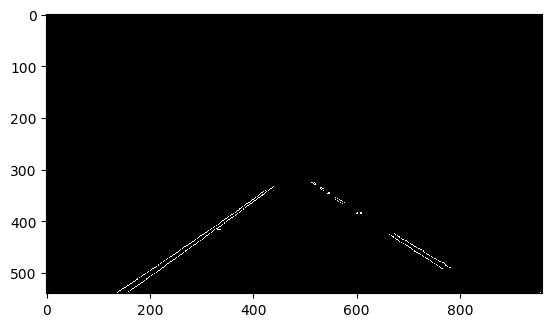
Woohoo! It's awesome! 经过了Canny Edge Detection,我们发现物体的轮廓都被检测到了!但是似乎东西有点儿太多了… 没关系,还有一个重要的条件没有用:camera相对于车是固定的,而无人车相对于车道的左右位置也是基本固定的,所以车道在camera视频中基本保持在一个固定区域内!据此我们可以画出一个大概的Region of Interest (ROI),过滤掉ROI之外的edges。
def roi_mask(img, vertices):
mask = np.zeros_like(img)
mask_color = 255
cv2.fillPoly(mask, vertices, mask_color)
masked_img = cv2.bitwise_and(img, mask)
return masked_img
roi_vtx = np.array([[(0, img.shape[0]), (460, 325),
(520, 325), (img.shape[1], img.shape[0])]])
roi_edges = roi_mask(edges, roi_vtx)
Hough Transformation
目前看起来我们似乎已经得到了车道线了呢,然而…并没有! 因为最终目标是得到exactly两条直线!而目前现在图中不仅有多条线,还有一些点状和块状区域,Hough Transformation的目的就是找到图中的线。
下图中左侧是image space,中间和右侧是Hough space。先看左侧和中间的图(右侧图见本节备注),image space中的一个点对应Hough space的一条线;image space中的两个点()对应Hough space的两条相交线,且交点对应的线必经过image space的这两个点。
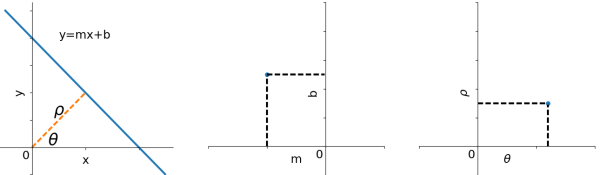
那么,如果Hough space中有多条线相交于一点,则在image space中对应的那些点应位于同一条线上,例如:
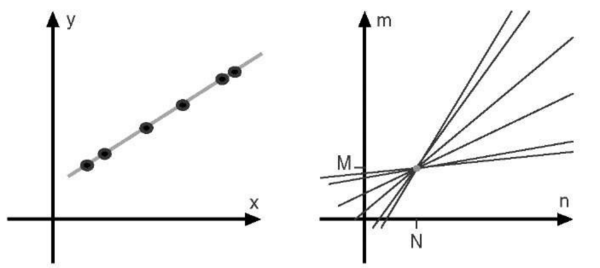
在实际操作中,我们往往将Hough space划分为网格状,如果经过一个格子的线的数目大于某threshold,我们认为这个经过这个格子的线在原image space对应的点应在同一条线上。具备了这些知识,我们可以用Hough Transformation来找线啦!
# Hough transform parameters
rho = 1
theta = np.pi / 180
threshold = 15
min_line_length = 40
max_line_gap = 20
def draw_lines(img, lines, color=[255, 0, 0], thickness=2):
for line in lines:
for x1, y1, x2, y2 in line:
cv2.line(img, (x1, y1), (x2, y2), color, thickness)
def hough_lines(img, rho, theta, threshold,
min_line_len, max_line_gap):
lines = cv2.HoughLinesP(img, rho, theta, threshold, np.array([]),
minLineLength=min_line_len,
maxLineGap=max_line_gap)
line_img = np.zeros((img.shape[0], img.shape[1], 3), dtype=np.uint8)
draw_lines(line_img, lines)
return line_img
line_img = hough_lines(roi_edges, rho, theta, threshold,
min_line_length, max_line_gap)
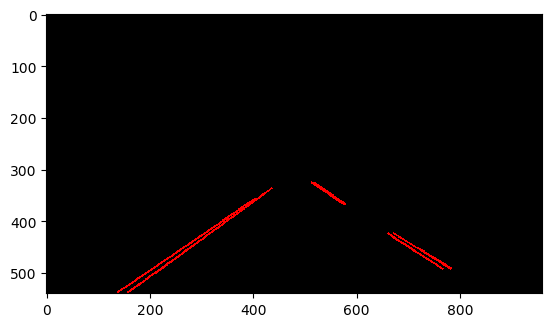
备注:如果image space中两个点,则其形成的直线斜率无限大,无法用中间的图表示,可以采用右侧的极坐标表示方式。
Lane Extrapolation
Almost there! 现在我们要根据得到的线计算出左车道和右车道,一种可以采用的步骤是:
- 根据斜率正负划分某条线属于左车道或右车道
- 分别对左右车道线移除outlier:迭代计算各条线的斜率与斜率均值的差,逐一移除差值过大的线
- 分别对左右车道线的顶点集合做linear regression,得到最终车道。
因为这部分代码有点儿多,就不贴在这里了,请参见我的Github代码。结果如下:
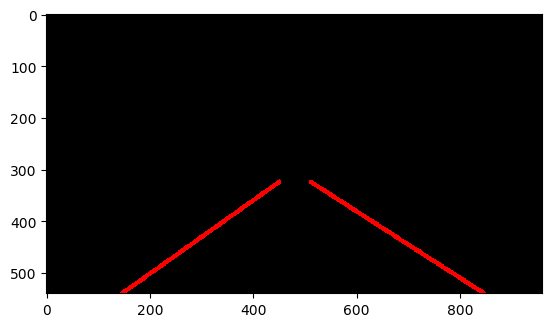
最最后,我们将结果和原图叠加:
cv2.addWeighted(img, 0.8, line_img, 1, 0)

图片任务完成!
回到视频上
现在我们将前面的代码打个包放到叫process_an_image的函数中,然后
from moviepy.editor import VideoFileClip
output = 'video_1_sol.mp4'
clip = VideoFileClip("video_1.mp4")
out_clip = clip.fl_image(process_an_image)
out_clip.write_videofile(output, audio=False)
将代码应用到三个不同的video上,看看结果!
注意:对于不同的情况,有些参数可能需要调节,第三个视频的处理需要一些额外的操作,会在我的Github代码中有具体描述。
参考资料


 浙公网安备 33010602011771号
浙公网安备 33010602011771号