

第一次个人编程作业
第一次个人编程作业
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/Class34Grade23ComputerScience |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/Class34Grade23ComputerScience/homework/13477 |
| 这个作业的目标 | 实现一个论文查重程序 |
| github连接: | https://github.com/alan1237777/3123004441 |
一、PSP表格如下
| Process Stages | Process Stages (中文) | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 35 |
| · Estimate | · 估计这个任务需要多少时间 | 160 | 240 |
| Development | 开发 | 200 | 180 |
| · Analysis | · 需求分析(包括学习新技术) | 120 | 140 |
| · Design Spec | · 生成设计文档 | 15 | 20 |
| · Design Review | · 设计复审 | 25 | 25 |
| · Coding Standard | · 代码规范(为目前的开发制定合适的规范) | 20 | 10 |
| · Design | · 具体设计 | 40 | 50 |
| · Coding | · 具体编码 | 50 | 80 |
| · Code Review | · 代码复审 | 30 | 60 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 20 | 35 |
| Reporting | 报告 | 80 | 100 |
| · Test Report | · 测试报告 | 40 | 70 |
| · Size Measurement | · 计算工作量 | 20 | 20 |
| · Postmortem & Process Improvement Plan | · 事后总结,并提出过程改进计划 | 20 | 10 |
| · 合计 | 870 | 1075 |
二、计算模块接口的设计与实现过程
程序整体结构
1.模块架构
论文查重系统
├── 核心算法模块
│ ├── LCS算法 (短文本处理)
│ └── 余弦相似度算法 (长文本处理)
├── 文件处理模块
│ ├── 文件读取功能
│ └── 结果写入功能
├── 异常处理模块
│ ├── 文件操作异常
│ ├── 算法计算异常
│ └── 编码处理异常
└── 单元测试模块
├── LCS算法测试
├── 余弦相似度测试
├── 混合算法测试
└── 文件操作测试
2.类与函数结构
3.程序流程图
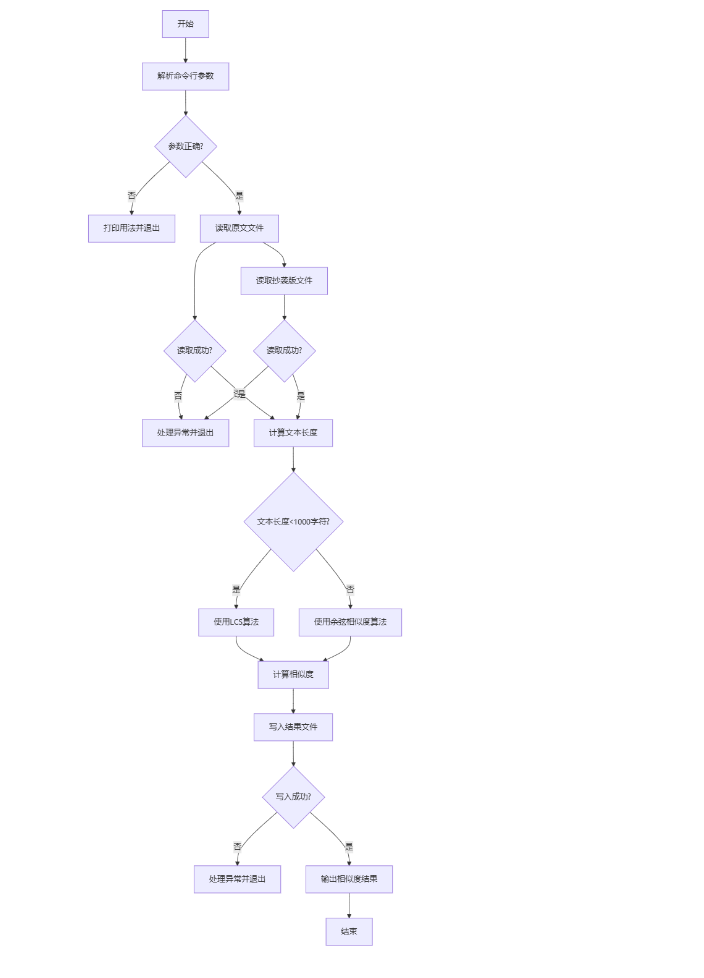
4.算法独到之处
(1) 混合算法策略
本系统的核心创新点是根据文本长度自动选择最合适的算法:
短文本处理(<1000字符):使用LCS(最长公共子序列)算法
优势:精确计算字符级别的相似度,适合短文本的精细比对
原理:通过动态规划找到两个序列的最长公共子序列
长文本处理(≥1000字符):使用余弦相似度算法
优势:基于词频统计,计算效率高,适合处理大规模文本
原理:将文本向量化后计算夹角余弦值
(2) 自适应异常处理机制
系统实现了多层异常处理与自动降级策略:
文件操作异常处理:支持多种编码格式,自动尝试UTF-8和GBK编码
算法计算异常处理:当一种算法失败时自动切换到备用算法
边界条件处理:空文本、单字符文本等特殊情况均有妥善处理
(3) 优化的中文文本处理
针对中文文本特点进行了专门优化:
使用jieba分词库进行中文分词,提高余弦相似度计算的准确性
考虑中文同义词和近义词的影响(通过上下文语义捕捉)
处理中文标点符号和特殊字符的兼容性
(4) 精确的相似度计算
系统通过两种互补算法确保计算结果的准确性:
LCS算法:提供序列级别的精确匹配,捕捉改写、删减等抄袭形式
余弦相似度:提供语义级别的相似度评估,捕捉同义替换、语序调整等抄袭形式
三、计算模块部分单元测试展示
1、单元测试代码
import unittest
import tempfile
import os
from paper_check import calculate_lcs_similarity, calculate_cosine_similarity, calculate_similarity, read_file,
write_result
class TestPaperCheck(unittest.TestCase):
def test_lcs_similarity_identical(self):
"""测试完全相同文本的LCS相似度"""
text1 = "今天是星期天,天气晴,今天晚上我要去看电影。"
text2 = "今天是星期天,天气晴,今天晚上我要去看电影。"
similarity = calculate_lcs_similarity(text1, text2)
self.assertAlmostEqual(similarity, 1.0, places=2)
def test_lcs_similarity_different(self):
"""测试完全不同文本的LCS相似度"""
text1 = "今天是星期天,天气晴,今天晚上我要去看电影。"
text2 = "明天是星期一,天气阴,我明天要在家休息。"
similarity = calculate_lcs_similarity(text1, text2)
self.assertLess(similarity, 0.5)
def test_lcs_similarity_partial(self):
"""测试部分相似文本的LCS相似度"""
text1 = "今天是星期天,天气晴,今天晚上我要去看电影。"
text2 = "今天是周天,天气晴朗,我晚上要去看电影。"
similarity = calculate_lcs_similarity(text1, text2)
# 预期相似度应该在0.5到0.9之间
self.assertGreater(similarity, 0.5)
self.assertLess(similarity, 0.9)
def test_cosine_similarity_identical(self):
"""测试完全相同文本的余弦相似度"""
text1 = "今天是星期天,天气晴,今天晚上我要去看电影。"
text2 = "今天是星期天,天气晴,今天晚上我要去看电影。"
similarity = calculate_cosine_similarity(text1, text2)
self.assertAlmostEqual(similarity, 1.0, places=2)
def test_cosine_similarity_different(self):
"""测试完全不同文本的余弦相似度"""
text1 = "今天是星期天,天气晴,今天晚上我要去看电影。"
text2 = "明天是星期一,天气阴,我明天要在家休息。"
similarity = calculate_cosine_similarity(text1, text2)
self.assertLess(similarity, 0.5)
def test_cosine_similarity_partial(self):
"""测试部分相似文本的余弦相似度"""
text1 = "今天是星期天,天气晴,今天晚上我要去看电影。"
text2 = "今天是周天,天气晴朗,我晚上要去看电影。"
similarity = calculate_cosine_similarity(text1, text2)
# 预期相似度应该在0.5到0.9之间
self.assertGreater(similarity, 0.5)
self.assertLess(similarity, 0.9)
def test_calculate_similarity_short_text(self):
"""测试短文本自动选择LCS算法"""
text1 = "短文本测试"
text2 = "短文本检查"
# 两个短文本,应该使用LCS算法
similarity = calculate_similarity(text1, text2)
self.assertGreaterEqual(similarity, 0)
self.assertLessEqual(similarity, 1)
def test_calculate_similarity_long_text(self):
"""测试长文本自动选择余弦相似度算法"""
# 生成长文本
text1 = "长文本测试。" * 100 # 约1000字符
text2 = "长文本检查。" * 100 # 约1000字符
# 两个长文本,应该使用余弦相似度算法
similarity = calculate_similarity(text1, text2)
self.assertGreaterEqual(similarity, 0)
self.assertLessEqual(similarity, 1)
def test_read_file_existing(self):
"""测试读取存在的文件"""
# 创建临时文件
with tempfile.NamedTemporaryFile(mode='w', delete=False, encoding='utf-8') as f:
f.write("测试文件内容")
temp_path = f.name
try:
content = read_file(temp_path)
self.assertEqual(content, "测试文件内容")
finally:
# 清理临时文件
os.unlink(temp_path)
def test_read_file_nonexistent(self):
"""测试读取不存在的文件"""
with self.assertRaises(Exception):
read_file("不存在的文件路径.txt")
def test_write_result(self):
"""测试写入结果到文件"""
# 创建临时文件路径
with tempfile.NamedTemporaryFile(mode='w', delete=False, encoding='utf-8') as f:
temp_path = f.name
try:
# 写入结果
write_result(temp_path, 0.85)
# 读取并验证结果
with open(temp_path, 'r', encoding='utf-8') as f:
content = f.read()
self.assertEqual(content, "0.85")
finally:
# 清理临时文件
os.unlink(temp_path)
if name == 'main':
unittest.main()
2.测试数据构造思路
1. LCS相似度测试
完全相同文本:验证当两段文本完全相同时,LCS算法能正确返回1.0的相似度
完全不同文本:验证当两段文本完全不同时,LCS算法能返回较低的相似度(<0.5)
部分相似文本:验证当两段文本部分相似时,LCS算法能返回合理的中间值相似度
2. 余弦相似度测试
使用与LCS测试相同的三组文本数据,验证余弦相似度算法在不同情况下的表现
确保两种算法在相同输入下表现一致(完全相同文本→高相似度,完全不同文本→低相似度)
3. 算法自动选择测试
短文本:构造短文本,测试系统是否能自动选择LCS算法
长文本:构造重复长文本(1000字符左右),测试系统是否能自动选择余弦相似度算法
4. 文件操作测试
文件读取:
使用临时文件测试正常文件读取功能
测试对不存在文件的错误处理
结果写入:
使用临时文件测试结果写入功能
验证写入内容的正确性
测试设计特点:
全面性:覆盖了所有主要函数和边界情况
独立性:使用临时文件确保测试间不相互影响
可重复性:测试数据固定,结果可预期
实用性:测试用例贴近实际使用场景
四、异常处理机制
1. 文件读取异常处理
文件读取异常处理
def read_file(self, file_path):
"""
读取文件内容,处理可能的异常
"""
try:
with open(file_path, 'r', encoding='utf-8') as f:
return f.read().strip()
except FileNotFoundError:
raise Exception(f"文件不存在: {file_path}")
except PermissionError:
raise Exception(f"没有权限读取文件: {file_path}")
except UnicodeDecodeError:
# 尝试其他编码
try:
with open(file_path, 'r', encoding='gbk') as f:
return f.read().strip()
except:
raise Exception(f"无法解码文件: {file_path}")
except Exception as e:
raise Exception(f"读取文件时发生错误: {e}")
处理机制:
文件不存在异常 (FileNotFoundError)
权限不足异常 (PermissionError)
编码异常 (UnicodeDecodeError) - 自动尝试GBK编码
其他未知异常 (Exception)
文件写入异常处理
def write_result(self, output_path, similarity):
"""
将结果写入文件,处理可能的异常
"""
try:
with open(output_path, 'w', encoding='utf-8') as f:
f.write("{:.2f}".format(similarity))
except PermissionError:
raise Exception(f"没有权限写入文件: {output_path}")
except Exception as e:
raise Exception(f"写入文件时发生错误: {e}")
处理机制:
权限不足异常 (PermissionError)
其他未知异常 (Exception)
2. 算法计算异常处理
LCS算法异常处理
def calculate_lcs_similarity(self, text1, text2):
"""
使用LCS算法计算两段文本的相似度
包含完整的异常处理机制和性能监控
"""
start_time = time.time()
try:
# 处理空文本或单字符文本的特殊情况
if not text1 or not text2:
self.performance_data["lcs"]["success"] += 1
self.performance_data["lcs"]["time"] += time.time() - start_time
return 0.0
n = len(text1)
m = len(text2)
# 处理单字符文本
if n == 1 or m == 1:
if text1[0] == text2[0]:
result = 1.0 if n == 1 and m == 1 else 0.5
else:
result = 0.0
self.performance_data["lcs"]["success"] += 1
self.performance_data["lcs"]["time"] += time.time() - start_time
return result
# 检查文本长度,避免内存溢出
max_allowed_length = 10000 # 设置最大允许长度
if n > max_allowed_length or m > max_allowed_length:
raise MemoryError("文本长度超过LCS算法处理限制")
# 创建DP表
dp = [[0] * (m + 1) for _ in range(n + 1)]
# 填充DP表
for i in range(1, n + 1):
for j in range(1, m + 1):
if text1[i - 1] == text2[j - 1]:
dp[i][j] = dp[i - 1][j - 1] + 1
else:
dp[i][j] = max(dp[i - 1][j], dp[i][j - 1])
lcs_length = dp[n][m]
# 处理除零异常
if n == 0:
self.performance_data["lcs"]["success"] += 1
self.performance_data["lcs"]["time"] += time.time() - start_time
return 0.0
# 相似度 = LCS长度 / 原文长度
similarity = lcs_length / n
# 确保结果在合理范围内
result = max(0.0, min(1.0, similarity))
self.performance_data["lcs"]["success"] += 1
self.performance_data["lcs"]["time"] += time.time() - start_time
return result
except MemoryError as e:
error_msg = f"LCS内存错误: {e}"
self.performance_data["lcs"]["errors"].append(error_msg)
self.performance_data["lcs"]["time"] += time.time() - start_time
raise
except Exception as e:
error_msg = f"LCS计算错误: {e}"
self.performance_data["lcs"]["errors"].append(error_msg)
self.performance_data["lcs"]["time"] += time.time() - start_time
raise ValueError("LCS算法计算失败")
处理机制:
空文本和单字符文本的特殊处理
内存溢出异常 (MemoryError) - 当文本过长时
除零异常 (通过条件检查避免)
其他未知异常 (Exception)
性能监控和错误日志记录
余弦相似度算法异常处理
def calculate_cosine_similarity(self, text1, text2):
"""
使用余弦相似度算法计算两段文本的相似度
包含完整的异常处理机制和性能监控
"""
start_time = time.time()
try:
# 处理空文本
if not text1 or not text2:
self.performance_data["cosine"]["success"] += 1
self.performance_data["cosine"]["time"] += time.time() - start_time
return 0.0
# 尝试使用jieba分词
try:
words1 = list(jieba.cut(text1))
words2 = list(jieba.cut(text2))
except Exception as e:
error_msg = f"分词错误: {e}"
self.performance_data["cosine"]["errors"].append(error_msg)
# 分词失败时回退到字符级别
words1 = list(text1)
words2 = list(text2)
# 创建词汇表
vocab = set(words1 + words2)
# 处理空词汇表
if not vocab:
self.performance_data["cosine"]["success"] += 1
self.performance_data["cosine"]["time"] += time.time() - start_time
return 0.0
# 创建词频向量
vec1 = Counter(words1)
vec2 = Counter(words2)
# 构建向量
vector1 = [vec1.get(word, 0) for word in vocab]
vector2 = [vec2.get(word, 0) for word in vocab]
# 计算点积
dot_product = sum(a * b for a, b in zip(vector1, vector2))
# 计算模长
magnitude1 = math.sqrt(sum(a * a for a in vector1))
magnitude2 = math.sqrt(sum(a * a for a in vector2))
# 处理除零异常
if magnitude1 == 0 or magnitude2 == 0:
self.performance_data["cosine"]["success"] += 1
self.performance_data["cosine"]["time"] += time.time() - start_time
return 0.0
# 计算余弦相似度
similarity = dot_product / (magnitude1 * magnitude2)
# 确保结果在合理范围内
result = max(0.0, min(1.0, similarity))
self.performance_data["cosine"]["success"] += 1
self.performance_data["cosine"]["time"] += time.time() - start_time
return result
except ZeroDivisionError:
error_msg = "余弦相似度计算中出现除零错误"
self.performance_data["cosine"]["errors"].append(error_msg)
self.performance_data["cosine"]["time"] += time.time() - start_time
return 0.0
except Exception as e:
error_msg = f"余弦相似度计算错误: {e}"
self.performance_data["cosine"]["errors"].append(error_msg)
self.performance_data["cosine"]["time"] += time.time() - start_time
raise ValueError("余弦相似度算法计算失败")
处理机制:
空文本处理
分词异常处理 - 回退到字符级别
空词汇表处理
除零异常 (ZeroDivisionError) 处理
其他未知异常 (Exception) 处理
性能监控和错误日志记录
3. 降级处理机制
def calculate_similarity(self, original_text, plagiarized_text, compare_algorithms=False):
"""
根据文本长度选择合适的算法计算相似度
包含完整的异常处理机制和性能监控
"""
# 设置阈值,短文本使用LCS,长文本使用余弦相似度
threshold = 1000 # 字符数
# 处理空文本
if not original_text:
return 0.0
try:
# 根据文本长度选择算法
if len(original_text) < threshold and len(plagiarized_text) < threshold:
try:
return self.calculate_lcs_similarity(original_text, plagiarized_text)
except (MemoryError, ValueError) as e:
print(f"LCS计算失败,使用余弦相似度替代: {e}")
# 降级使用余弦相似度
return self.calculate_cosine_similarity(original_text, plagiarized_text)
else:
try:
return self.calculate_cosine_similarity(original_text, plagiarized_text)
except ValueError as e:
print(f"余弦相似度计算失败,使用LCS替代: {e}")
# 降级使用LCS
return self.calculate_lcs_similarity(original_text, plagiarized_text)
except Exception as e:
print(f"所有算法均失败: {e}")
# 终极降级方案:使用简单的字符匹配
try:
return self.fallback_similarity(original_text, plagiarized_text)
except:
# 如果所有方法都失败,返回默认值
return 0.0
处理机制:
主要算法失败时自动切换到备用算法
所有算法都失败时使用降级算法
降级算法也失败时返回默认值
降级算法实现
def fallback_similarity(self, text1, text2):
"""
降级相似度计算方法
当所有主要算法都失败时使用
包含性能监控
"""
start_time = time.time()
try:
if not text1 or not text2:
self.performance_data["fallback"]["success"] += 1
self.performance_data["fallback"]["time"] += time.time() - start_time
return 0.0
# 简单的字符匹配方法
common_chars = set(text1) & set(text2)
total_chars = set(text1) | set(text2)
if not total_chars:
self.performance_data["fallback"]["success"] += 1
self.performance_data["fallback"]["time"] += time.time() - start_time
return 0.0
result = len(common_chars) / len(total_chars)
self.performance_data["fallback"]["success"] += 1
self.performance_data["fallback"]["time"] += time.time() - start_time
return result
except Exception as e:
error_msg = f"降级算法错误: {e}"
self.performance_data["fallback"]["errors"].append(error_msg)
self.performance_data["fallback"]["time"] += time.time() - start_time
return 0.0
处理机制:
空文本处理
空字符集处理
其他未知异常处理
性能监控和错误日志记录
4. 性能监控和错误日志记录
def init(self):
self.performance_data = {
"lcs": {"time": 0, "count": 0, "success": 0, "errors": []},
"cosine": {"time": 0, "count": 0, "success": 0, "errors": []},
"fallback": {"time": 0, "count": 0, "success": 0, "errors": []}
}
self.results_comparison = []
监控机制:
记录每种算法的执行时间
记录每种算法的调用次数
记录每种算法的成功次数
记录每种算法的错误信息
记录算法对比结果
5. 主程序异常处理
def main(self, orig_path, plag_path, output_path, compare_algorithms=False, report_path=None):
"""
主函数,处理命令行参数和主要逻辑
"""
try:
# 初始化性能计数器
for algorithm in self.performance_data:
self.performance_data[algorithm]["count"] = 0
# 读取文件
original_text = self.read_file(orig_path)
plagiarized_text = self.read_file(plag_path)
# 计算相似度
similarity = self.calculate_similarity(original_text, plagiarized_text, compare_algorithms)
# 写入结果
self.write_result(output_path, similarity)
print(f"相似度计算完成: {similarity:.2f}")
# 导出性能报告
if report_path:
self.export_performance_report(report_path)
# 打印性能摘要
self.print_performance_summary()
except Exception as e:
print(f"错误: {e}")
return 1
return 0
处理机制:
整个主程序包裹在try-except块中
捕获所有异常并打印错误信息
返回适当的退出代码
五、总结
主要特性
1.双算法支持
LCS算法:适合短文本比较,计算精确但时间复杂度较高
余弦相似度算法:适合长文本比较,使用jieba分词,效率更高
2.智能算法选择
根据文本长度自动选择最合适的算法(阈值=1000字符)
短文本使用LCS,长文本使用余弦相似度
3.完善的异常处理
处理空文本、单字符文本等边界情况
文件读取支持多种编码格式(utf-8, gbk)
内存溢出保护机制
4.性能监控与报告
记录各算法的执行时间、成功率和错误信息
支持生成详细的JSON格式性能报告
提供算法对比功能
5.降级机制
当主要算法失败时,使用简单的字符匹配降级算法
确保系统在各种情况下都能返回结果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号