

Mybatis的Mapper扫描机制:@MapperScan源码(转)
原文:https://blog.csdn.net/qq_42187215/article/details/132650985
作者:Zzzj_1233
来源:CSDN
1. 如何基于包扫描类
首先提出一个问题:如通过给定包名来扫描包中类的信息呢?
方式一:使用Class.forName
首先,通过包名访问目录下的所有class文件。
接下来,将所有class文件的路径转换为类路径格式,例如将 “a/b/c/HelloWorld.class” 转换为 “a.b.c.HelloWorld”。
最后,使用 Class.forName 方法加载 a.b.c.HelloWorld。
方式二:基于字节码库
同样,首先通过包名访问目录下的所有class文件。
然后,通过字节码库读取这些class文件,以获取类信息。
Spring采取的是方式二
并且使用ASM作为字节码库, ( ASM是java字节码类库中性能最高的之一 )
那为什么Spring不采用Class.forName呢
使用Class.forName必定会经历查找 -> 加载 -> 初始化的过程,最终将类加载到JVM中
可是我们指定一个包去扫描,只需要扫描出包含特定注解的类,而并不需要将所有的类都加载到JVM中
2. @MapperScan的用处
在传统的Mybatis开发中
通过SqlSession#getMapper来得到Mapper
然后使用Mapper进行数据库访问
而在Mybatis集成Spring的开发中,只需要给配置类上标注@MappperScan("指定包名")即可将Mapper注入到Spring的容器中
例如:
@SpringBootApplication @MapperScan("com.zzzj.dao") public class Main { public static void main(String[] args) { SpringApplication.run(Main.class, args) } }
2. 概要
@MapperScan和@ComponentScan一样,都是基于ClassPathBeanDefinitionScanner实现的
只不过@MapperScan做了一些额外的处理,将扫描出来的BeanDefinition替换了,来了一手狸猫换太子
如果还不熟悉ClassPathBeanDefinitionScanner
可以查看这篇文章:Spring的Bean扫描机制:ClassPathBeanDefinitionScanner源码
3. 源码追踪
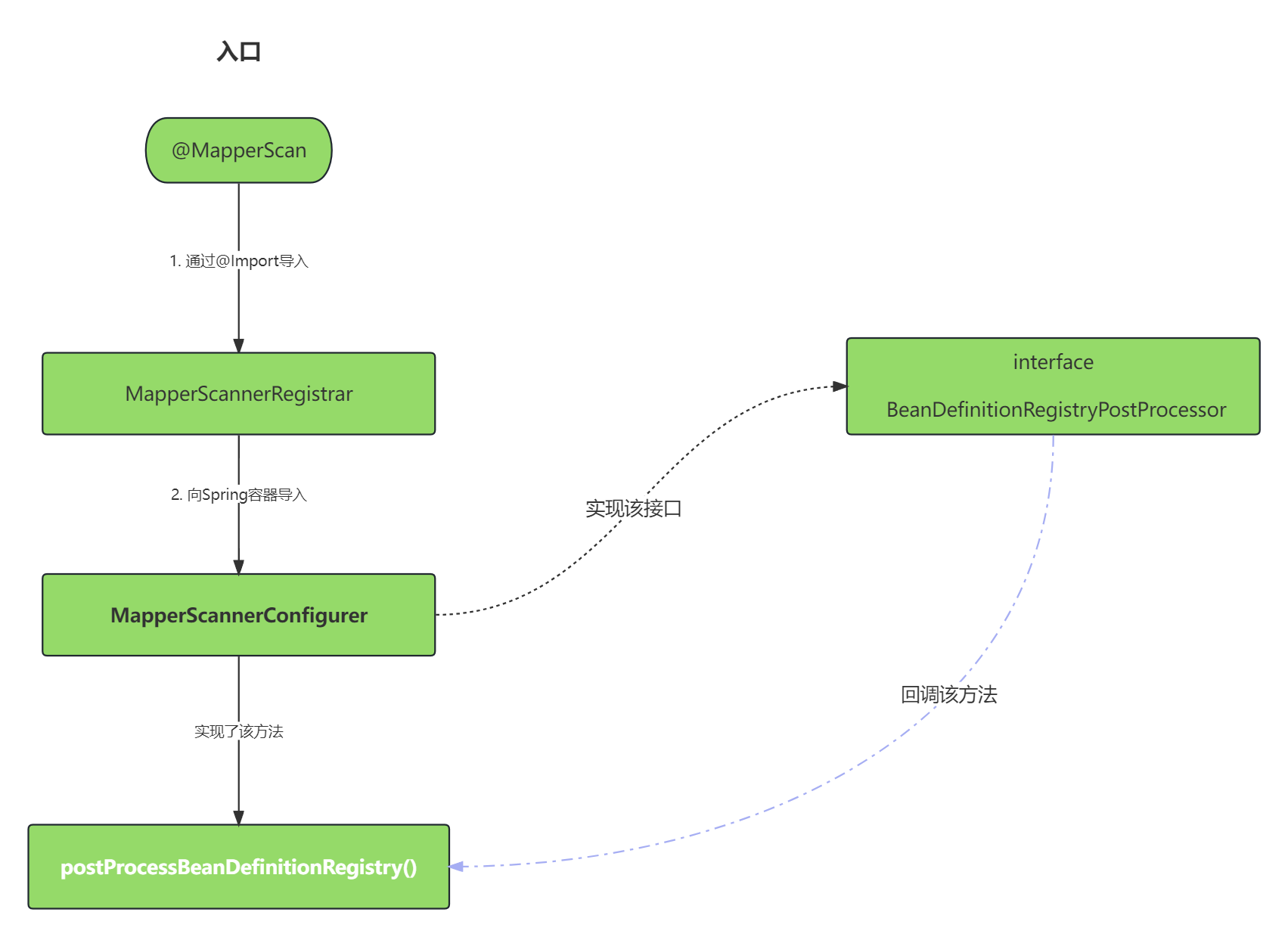
3.1 @Import(MapperScannerRegistrar.class)
@MapperScan注解上使用@Import注解导入了MapperScannerRegistrar
@Import(MapperScannerRegistrar.class) public @interface MapperScan { // ... }
MapperScannerRegistrar向Spring容器中导入了MapperScannerConfigurer
3.2 MapperScannerConfigurer
MapperScannerConfigurer实现了BeanDefinitionRegistryPostProcessor接口,将在BeanDefinitionRegistry被Spring创建好后被回调
回调postProcessBeanDefinitionRegistry方法
此时的流程如下图所示
3.3 postProcessBeanDefinitionRegistry
接下来跟踪MapperScannerConfigurer的postProcessBeanDefinitionRegistry方法
public void postProcessBeanDefinitionRegistry(BeanDefinitionRegistry registry) { // 忽略 if (this.processPropertyPlaceHolders) { processPropertyPlaceHolders(); } // 1. 创建scanner, { ClassPathMapperScanner } 继承了 { ClassPathBeanDefinitionScanner } // { this.$propertyName } 来自@MapperScan注解的属性 ClassPathMapperScanner scanner = new ClassPathMapperScanner(registry); scanner.setAddToConfig(this.addToConfig); scanner.setAnnotationClass(this.annotationClass); scanner.setMarkerInterface(this.markerInterface); scanner.setSqlSessionFactory(this.sqlSessionFactory); scanner.setSqlSessionTemplate(this.sqlSessionTemplate); scanner.setSqlSessionFactoryBeanName(this.sqlSessionFactoryBeanName); scanner.setSqlSessionTemplateBeanName(this.sqlSessionTemplateBeanName); scanner.setResourceLoader(this.applicationContext); scanner.setBeanNameGenerator(this.nameGenerator); scanner.setMapperFactoryBeanClass(this.mapperFactoryBeanClass); if (StringUtils.hasText(lazyInitialization)) { scanner.setLazyInitialization(Boolean.valueOf(lazyInitialization)); } if (StringUtils.hasText(defaultScope)) { scanner.setDefaultScope(defaultScope); } scanner.registerFilters(); // 调用scan方法, 扫描包下的类 scanner.scan( StringUtils.tokenizeToStringArray(this.basePackage, ConfigurableApplicationContext.CONFIG_LOCATION_DELIMITERS)); }
3.4 scan
上面有提到,ClassPathMapperScanner继承自ClassPathBeanDefinitionScanner
ClassPathMapperScanner并没有重写scan方法,这里还是调用的ClassPathBeanDefinitionScanner的scan方法
Spring的Bean扫描机制:ClassPathBeanDefinitionScanner源码
在上篇文章中已经追踪过scan方法的具体流程了,就不再赘述
但是
ClassPathMapperScanner重写了ClassPathBeanDefinitionScanner的doScan方法
接下来继续跟追doScan方法
// ClassPathBeanDefinitionScanner 的 scan 方法源码 public int scan(String... basePackages) { int beanCountAtScanStart = this.registry.getBeanDefinitionCount(); doScan(basePackages); if (this.includeAnnotationConfig) { AnnotationConfigUtils.registerAnnotationConfigProcessors(this.registry); } return (this.registry.getBeanDefinitionCount() - beanCountAtScanStart); }
3.5 doScan
注意这里是ClassPathMapperScanner重写的doScan方法
@Override public Set<BeanDefinitionHolder> doScan(String... basePackages) { // 1. 得到super ( ClassPathBeanDefinitionScanner ) 扫描后的 beanDefinition 集合 Set<BeanDefinitionHolder> beanDefinitions = super.doScan(basePackages); if (beanDefinitions.isEmpty()) { LOGGER.warn(() -> "No MyBatis mapper was found in '" + Arrays.toString(basePackages) + "' package. Please check your configuration."); } else { // 2. 对 beanDefinition 集合做额外的处理 processBeanDefinitions(beanDefinitions); } return beanDefinitions; }
为什么ClassPathMapperScanner要对扫描出来的BeanDefinition做额外的处理?
日常开发中,基本都是定义一个接口,作为Mapper
例如
public interface UserMapper { User selectById(int id); }
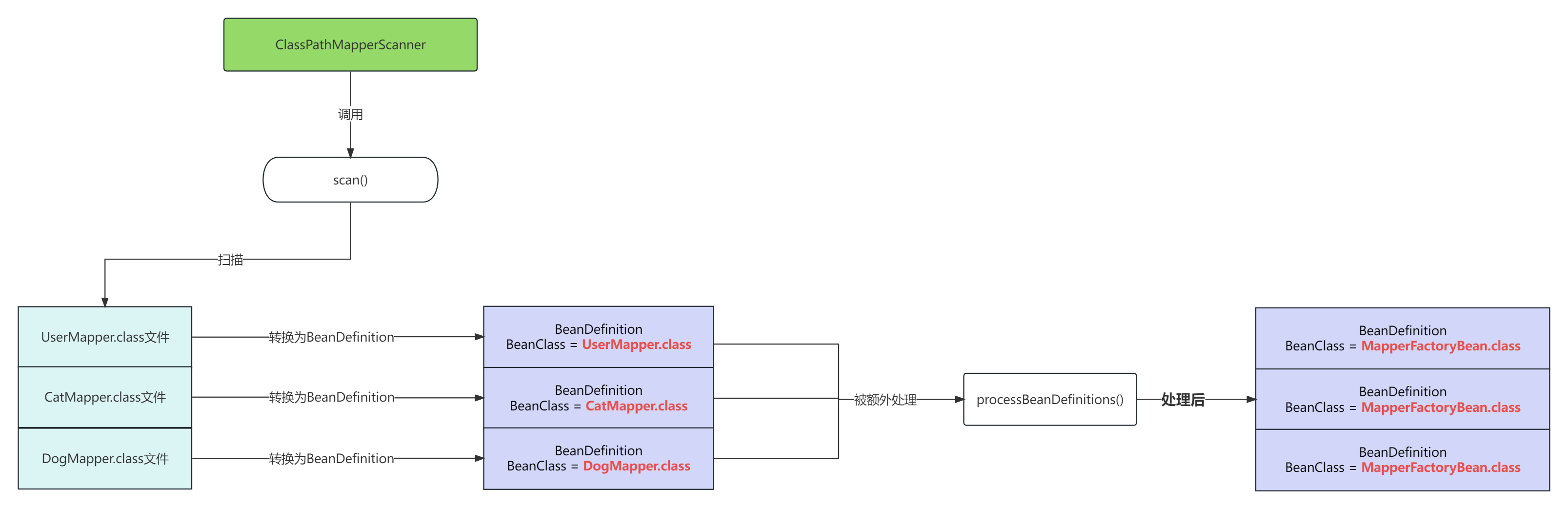
UserMapper被扫描出来后,ClassPathBeanDefinitionScanner为其创建对应的BeanDefinition对象
BeanDefinition对象的BeanClass就是UserMapper.class
而一个接口是无法直接被Spring实例化的,我们需要的是SqlSession.getMapper创建出来的代理对象
ClassPathMapperScanner的额外处理就是修改BeanDefinition的属性,使其最终还是通过SqlSession.getMapper方法创建Mapper对象
====================================================================================================
那么接下来继续追踪processBeanDefinitions方法,看看这个方法究竟做了什么额外处理
3.6 processBeanDefinitions
private void processBeanDefinitions(Set<BeanDefinitionHolder> beanDefinitions) { AbstractBeanDefinition definition; for (BeanDefinitionHolder holder : beanDefinitions) { definition = (AbstractBeanDefinition) holder.getBeanDefinition(); String beanClassName = definition.getBeanClassName(); definition.getConstructorArgumentValues().addGenericArgumentValue(beanClassName); // issue #59 // 注意这里: 修改了BeanClass definition.setBeanClass(this.mapperFactoryBeanClass); definition.getPropertyValues().add("addToConfig", this.addToConfig); definition.setAttribute(FACTORY_BEAN_OBJECT_TYPE, beanClassName); // ... 忽略边缘逻辑代码 } }
在该方法中, 最最核心的一行代码就是
definition.setBeanClass(this.mapperFactoryBeanClass);
mapperFactoryBeanClass属性在ClassPathMapperScanner被定义
public class ClassPathMapperScanner extends ClassPathBeanDefinitionScanner { // .... private Class<? extends MapperFactoryBean> mapperFactoryBeanClass = MapperFactoryBean.class; // .... }
也就是说,ClassPathMapperScanner 将扫描出的BeanDefinition的BeanClass替换为了MapperFactoryBean
3.7 MapperFactoryBean
MapperFactoryBean是一个FactoryBean
我们关注该类的getObject方法
@Override public T getObject() throws Exception { return getSqlSession().getMapper(this.mapperInterface); }
可以看到,兜兜转转,最终还是通过SqlSession.getMapper方法来创建Mapper的
那么该对象的SqlSession和mapperInterface是怎么来的呢?
还是在processBeanDefinitions方法中被赋值的
private void processBeanDefinitions(Set<BeanDefinitionHolder> beanDefinitions) { AbstractBeanDefinition definition; for (BeanDefinitionHolder holder : beanDefinitions) { definition = (AbstractBeanDefinition) holder.getBeanDefinition(); String beanClassName = definition.getBeanClassName(); // 1. 通过 { MapperFactoryBean } 的构造方法注入 { mapperInterface } 属性 // beanClassName也就是被扫描的接口全限定名, 例如 "com.zzzj.UserMapper" // 注意: MapperFactoryBean 的构造方法接收一个Class对象, 而不是String对象 ( beanClassName是String类型的 ) // 在Spring调用 { MapperFactoryBean } 构造方法前会进行值的转换 // 将String转换为Class definition.getConstructorArgumentValues().addGenericArgumentValue(beanClassName); definition.setBeanClass(this.mapperFactoryBeanClass); // 2. 这里赋值的 { sqlSessionTemplate } if (StringUtils.hasText(this.sqlSessionTemplateBeanName)) { definition.getPropertyValues().add("sqlSessionTemplate", new RuntimeBeanReference(this.sqlSessionTemplateBeanName)); explicitFactoryUsed = true; } else if (this.sqlSessionTemplate != null) { definition.getPropertyValues().add("sqlSessionTemplate", this.sqlSessionTemplate); explicitFactoryUsed = true; } // ...... } }
4. 总结
- @MapperScan通过@Import注解导入了MapperScannerRegistrar
- MapperScannerRegistrar向容器中注入MapperScannerConfigurer
- MapperScannerConfigurer是一个BeanDefinitionRegistryPostProcessor,将会被Spring容器回调postProcessBeanDefinitionRegistry方法
- 在postProcessBeanDefinitionRegistry方法中创建了ClassPathMapperScanner,并且调用ClassPathMapperScanner的scan方法
- ClassPathMapperScanner重写了父类ClassPathBeanDefinitionScanner的doScan方法,在扫描完Bean获取到BeanDefinition后,在processBeanDefinitions方法对其进行了额外的处理
- processBeanDefinitions方法将所有的BeanDefinition的beanClass属性转换为了MapperFactoryBean
- MapperFactoryBean是一个FactoryBean,将会被Spring回调getObject()方法,并且将方法的返回值注入到容器中
- MapperFactoryBean的getObject()方法通过sqlSession#getMapper方法创建Mapper对象,注入到容器中

 浙公网安备 33010602011771号
浙公网安备 33010602011771号