



Elasticsearch7.6.0
ElasticSerach 7.6.0
6.x和7.x的区别十分大
1.1 概念
概念:开源的高扩展的分布式全文搜索引擎,可以近乎实时的存储,检索数据。可扩展到上百台服务器,处理PB级别(大数据)的数据。Es是使用java开发的并使用Lucene(也是java开发的工具包)作为核心来实现所有索引和搜索的功能,通过简单的RestfulApi来隐藏Lucene的复杂性,从而简化全文搜索。ElasticSearch已超过Solr称为排名第一的搜索引擎应用。Solr也是基于Java开发的,基于Lucene的搜索引擎。
1.2 使用
维基百科、国外新闻网站、StackOverFlow、Github、电商网商、日志数据分析ELK(ElasticSearch+Logstash+Kibana)
ELK:
Logstash:用于数据收集
ElasticSearch:数据存储分析和搜索
Kibana:用于结果展示
1.3 Es和Solr对比
- Es开箱使用,相比Solr更简单。
- Solr使用Zookeeper进行分布式管理,而Es自身带有分布式协调管理功能。
- Solr支持更多格式数据,如Json、Xml、Csv。而Es只支持Json格式。
- Solr官方提供功能更多,而Es本身更注重核心功能,高级功能多有第三方插件提供,例如图形化界面由Kibana支持
- Solr查询速度更快,但更新索引慢,用于电商查询多的应用,Es建立索引快,查询相比Solr慢。Solr是传统搜索应用的有力解决方案,Es适用于新兴的实时搜索应用。
- Solr比较成熟,社区活跃。Es相对开发维护者较少,更新快,学习成本高。
1.4 安装准备工作
JDK1.8:ES要求的JDK版本最低是1.8
ElasticSearch:7.6.0版本(https://www.elastic.co/cn/downloads/elasticsearch)
Kibana:需要与ES版本保持一致,也是7.6.0版本(https://www.elastic.co/cn/downloads/kibana)
IK分词器:中文分词器,需要与ES版本保持一致,也是7.6.0版本(https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v7.6.0)
ElasticSearch-Head:连接ES的图形化客户端,需要Node.js环境,先安装Node.js(http://nodejs.cn/download/、https://github.com/mobz/elasticsearch-head)
1.5 安装
将上述的安装包,下载后进行解压。




ES运行(单机):elasticsearch-7.6.0\bin\elasticsearch.bat 双击直接执行 http://127.0.0.1:9200
Kibana运行:kibana-7.6.0-windows-x86_64\bin\kibana.bat http://127.0.0.1:5601
ElasticSearch-Head:先进行编译,npm install,安装完成后直接 npm run start运行即可 http://127.0.0.1:9100
IK分词器:直接将IK分词器目录直接copy到ES的plugins下,并改名为目录名为analysis-ik(否则加载不到),ES启动时就会自动加载插件
1.6 启动访问
1.6.1 启动ES、ES-Head
访问ES http://127.0.0.1:9200 出现下面结果,ES启动成功,ES对外API端口是9200,ES集群内部通讯端口为9300

访问ES-Head http://127.0.0.1:9100,发现连接 ES http://127.0.0.1:9200 出现跨域问题

1.6.2 Head工具跨域问题
解决ES-Head连接ES的跨域问题:
配置 elasticsearch-7.6.0\config\elasticsearch.yml 配置文件,添加跨域支持,然后重启ES,即可
# 开启跨域
http.cors.enabled: true
# 所有人访问
http.cors.allow-origin: "*"
连接成功

1.6.3 启动 Kibana

测试IK分词器,能运行成功并且成功分词,就代表IK分词器配置成功
GET _analyze
{
"analyzer": "ik_smart",
"text": "我是中国人"
}
GET _analyze
{
"analyzer": "ik_max_word",
"text": "我是中国人"
}


1.7 分词器
分词器,作用是将一段字符串拆分成一个个的关键字,我们在搜索的时候,会将我们输入的关键字进行分词,会将索引库中的数据进行分词,然后进行一个匹配操作(搜索出匹配度相关的数据),ES相似度匹配的结果与所选择的分词器类别息息相关。ES默认的分词器为standard,是将每个字看做一个词,但显然不符合我们中文的场景,所以需要使用IK分词器,进行词组的划分。
分词器:
- Standard:单字切分法,一个字(对于英文为一个单词)切分成一个词,ES默认内置分词器。
- CJKAnalyzer: 二元切分法, 把相邻的两个字, 作为一个词。
- SmartChineseAnalyzer: 对中文支持较好, 但是扩展性差, 针对扩展词库、停用词均不好处理。
- Whitespace分词器:去除空格,不支持中文,对生成的词汇单元不进行其他标准化处理。
- language分词器:特定语言的分词器,不支持中文。
- IK-analyzer: 在做中文搜索时,最受欢迎的分词器,支持自定义词库。
1.8 IK分词器
1.8.1 IK分词模式
IK分词器有两种分词模式:ik_max_word 和 ik_smart模式。
1、ik_max_word(最细粒度的拆分)
会将文本做最细粒度的拆分,比如会将“中华人民共和国人民大会堂”拆分为“中华人民共和国、中华人民、中华、华人、人民共和国、人民、共和国、大会堂、大会、会堂等词语。
2、ik_smart(粗粒度的拆分)
会做最粗粒度的拆分,但不会重复,比如会将“中华人民共和国人民大会堂”拆分为中华人民共和国、人民大会堂。
1.8.2 自定义分词字典

有时候,ik分词的结果,不符合我们的预期,比如:我是程序猿,预期结果:我、是、程序猿,但是ik分词器将【程序猿】三个字也拆分了,这个时候我们需要自定义扩展字典,并注入到配置文件中。
-
编写自定义词典(在elasticsearch-7.6.0\plugins\analysis-ik\config,下面新建 my.dic文件(名字自定义),并写入【程序猿】字典值到my.dic中)
-
注入到字典配置文件中(elasticsearch-7.6.0\plugins\analysis-ik\config\IKAnalyzer.cfg.xml),并重启ES。
my.dic

1.9 ES的核心概念
ES是面向文档
| 关系型数据库(例:Mysql) | ES | |
|---|---|---|
| 数据库DataBase | 索引Indices | |
| 表Table | 类型types(慢慢弃用,7.0已经过时,8.0就会彻底弃用) | |
| 行rows | 文档documents | |
| 列字段Columns | 字段fields |
ES集群中可以包含多个索引(数据库),每个索引中可以包含多个类型(表),每个类型下又包含多个文档(行),每个行又包含多个字段(列)。
物理设计:

ES在后台把每个索引划分成多个分片,每个分片可以在集群中的的不同服务器间迁移,ES将数据分别存储在每个分片上,分片又存储在不同的节点上,保证了高可用。
一个集群至少有一个节点,而一个节点就是一个ES进程,如果你创建索引,那么索引将会默认有5个分片(primary shard,又称主分片)构成的,每一个主分片会有一个副本(replica shard ,又称复制分片)。
集群(cluster): 由一个或多个节点组成, 并通过集群名称与其他集群进行区分
节点(node): 单个 ElasticSearch 实例. 通常一个节点运行在一个隔离的容器或虚拟机中
索引(index): 在 ES 中, 索引是一组文档的集合
分片(shard): 因为 ES 是个分布式的搜索引擎, 所以索引通常都会分解成不同部分, 而这些分布在不同节点的数据就是分片. ES自动管理和组织分片, 并在必要的时候对分片数据进行再平衡分配, 所以用户基本上不用担心分片的处理细节.主分片数在索引创建时指定,后续不允许修改,除非 Reindex,重建索引。
副本(replica): ES 默认为一个索引创建 5 个主分片(7.0版本以后,默认为1个主分片), 并分别为其创建1个副本分片. 也就是说每个索引都由 5 个主分片组成, 而每个主分片都相应的有一个 copy。对于分布式搜索引擎来说, 分片及副本的分配将是高可用及快速搜索响应的设计核心.主分片与副本都能处理查询请求,它们的唯一区别在于只有主分片才能处理索引请求.副本对搜索性能非常重要,同时用户也可在任何时候添加或删除副本。额外的副本能给带来更大的容量, 更高的呑吐能力及更强的故障恢复能力。主分片可读可写,副本只能读。
逻辑设计:
文档:
ES是面向文档的,索引和搜索数据的最小单位是文档。
- 自我包含,一篇文档同时包含字段和对应的值,也就是同时包含key:value,例如:name:张三。
- 可以是层次性的,一个文档中包含子文档,复杂的逻辑实体就是这么来的。就是一个json对象
- 灵活的数据结构,文档不依赖于预先定义的模式,关系型数据库中需要提前定义字段才能使用,在ES中,对于字段是非常灵活的,有时候可以忽略该字段或者动态的添加一个新的字段。
类型:
类型是文档的逻辑容器,就像关系型数据库一样,表格是行的容器。类型中对于字段的定义称为映射,比如name映射为字符串类型。虽说文档是无模式的,不需要拥有映射中所定义的所有字段,比如新增一个字段,那么ES会自动的将新增的字段加入映射,但是这个字段不确定是什么类型的,ES就会自动判断字段类型,但是可能判断的是错误的,所以最安全的方式是提前定义好所需要的映射,这点跟关系型数据库很像,先定义好字段在使用,避免出现问题。
索引:
索引是映射类型的容器,ES中的索引是一个非常大的文档集合。索引存储了映射类型的字段和其他设置。然后被存储到各个分片上。
2.0 倒排索引(反向索引)
ES使用的是一种称为倒排索引的结构,采用Lucene倒排索引为底层,这种结构适用于全文搜索。实现比关系型数据库更快的过滤方法。有利于ES在不扫描全部文档的情况下,找到哪些关键字存在于哪些文档中。
正排索引:
当用户发起查询时(假设查询为一个关键词),搜索引擎会先扫描索引库中的所有文档,找出所有包含关键词的文档,这种从文档中去查找是否含有关键词的方法叫做正向索引。
正排索引:基于文档建立索引,建立方便,维护简单,检索效率低。扫描文档 --->关键字
倒排索引:
倒排索引:基于字、词建立索引,建立维护复杂,检索效率高。关键字 --> 文档
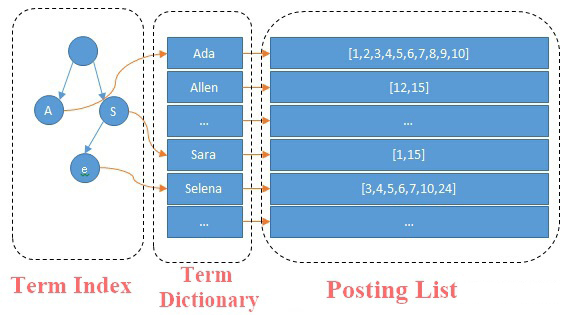
倒排索引的核心分为两部分:
第一部分为单词词典(Term Dictionary),记录所有文档的单词以及单词到倒排列表的关联关系。在实际生产中,单词量会非常大,所以实际会采用 B+ 树和哈希拉链法去存储单词的词典,以满足高性能的插入与查询。
第二部分是倒排列表(Posting List),它记录了单词对应的文档id,倒排列表是由倒排索引(Posting) 组成。,找到文档的id,在去找对应的文档。
倒排索引的使用场景:
搜索引擎,根据关键字,找到所有关联的文章。
2.1 RestfulApi
字段类型:
Text, 字符串类型(可被分词)
Keyword, 字符串类型(不可被分词,是一个整体)
Integer,
Long,
Date,(日期类型,可自定义格式)
Float,
Double,
Boolean,
Object,
Auto, 自动检测类型
Nested, 嵌套类型(Object数据类型的特殊版本)
Ip, IP地址类型(适用于ip段的查询106.94.0.0/16,查询更快)
| 请求方式 | url | 功能 |
|---|---|---|
| PUT | ip:port / 索引名称 / 类型名称 / 文档id | 创建文档(指定id) |
| POST | ip:port / 索引名称 / 类型名称 | 创建文档(随机id) |
| POST | ip:port / 索引名称 / 类型名称 / 文档id / _update | 修改指定文档 |
| DELTE | ip:port/索引名称/类型名称/文档id | 删除指定文档 |
| GET | ip:port/索引名称/类型名称/文档id | 获取指定文档 |
| POST | ip:port/索引名称/类型名称/_search | 查询所有文档 |
可以直接使用kibana测试,类型Type在7.0版本后就开始过时了,8.0彻底废弃,不建议在使用,直接使用默认的 _doc 。
2.1.1 创建索引:

查看ES索引数据存储结果:

2.1.2 创建索引规则:



2.1.3 获取索引信息:
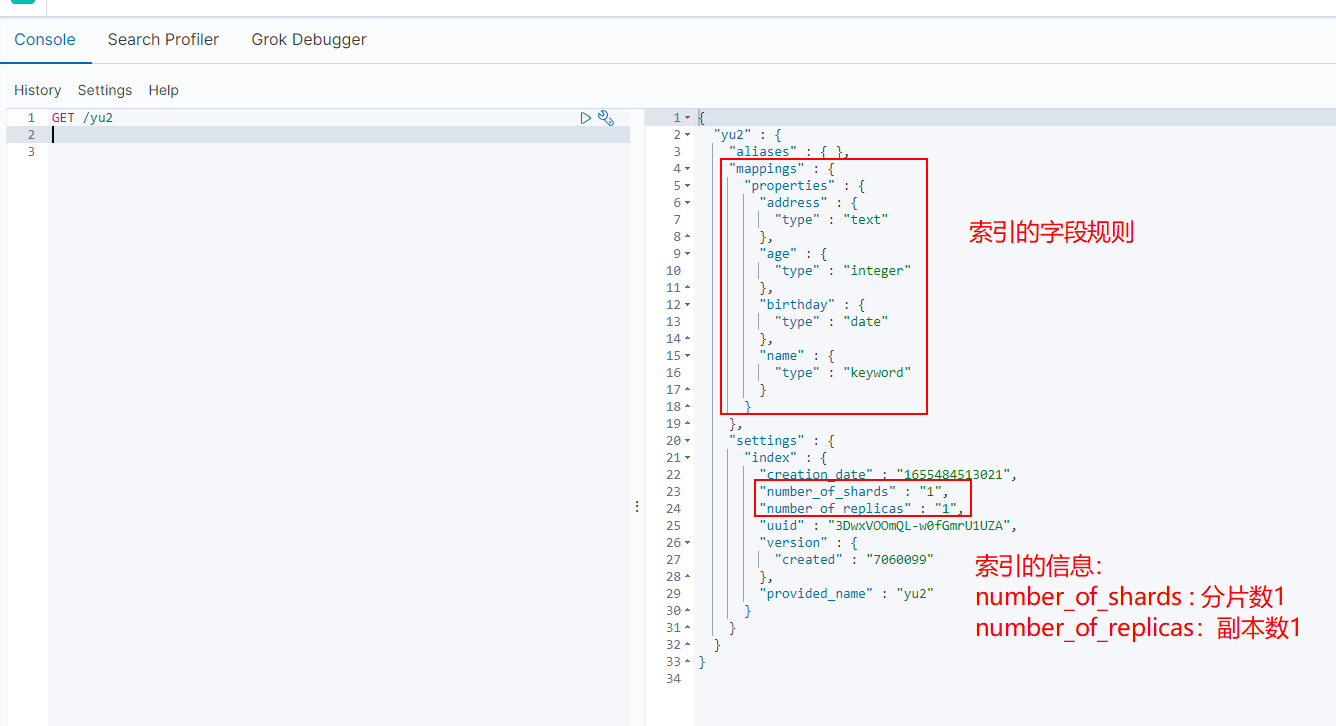
2.1.4 默认索引字段类型:


2.1.5 扩展命令:
GET /_cat/indices?v 查看ES中所有索引的统计信息。

2.1.6 修改索引:
- 使用PUT命令(不推荐使用,全量覆盖,参数中缺少的字段,es会将其更新为空) PUT /索引/类型/id
- 使用POST命令(增量更新,参数中缺少的字段,es不会更新为空) POST/索引/类型/id/_update
PUT更新前:

PUT更新后:


POST更新后:


2.1.7 删除索引:
通过DELETE 命令,可以删除 索引或文档
2.1.8 查询(重点)
原生restful的api针对于入门学习,实际开发中我们并不会这样调用,开发中使用es封装的api

简单查询:
| 根据id获取:GET /索引/类型/文档id |
|---|
| 根据条件获取:GET /索引/类型/_search?q=属性:值 |
复杂查询(_search):
match和term的区别
match会进行分词,对分词进行匹配,对字段进行模糊匹配;
term不会进行分词,它只对字段的分词进行精确匹配;
比如,对于文档中text类型的字段name=张三,match查询条件name:张三能查到,但term不能;
因为张三分词后是张,三;term会到倒排索引中找张三但是无法匹配
再比如name=张三,如果查询条件为name:张,无论是term还是match都会匹配到
match和term都会从倒排索引里面找,重点在于match会将条件进行分词,而term不会对条件分词
_search 查询
GET /索引/类型/_search
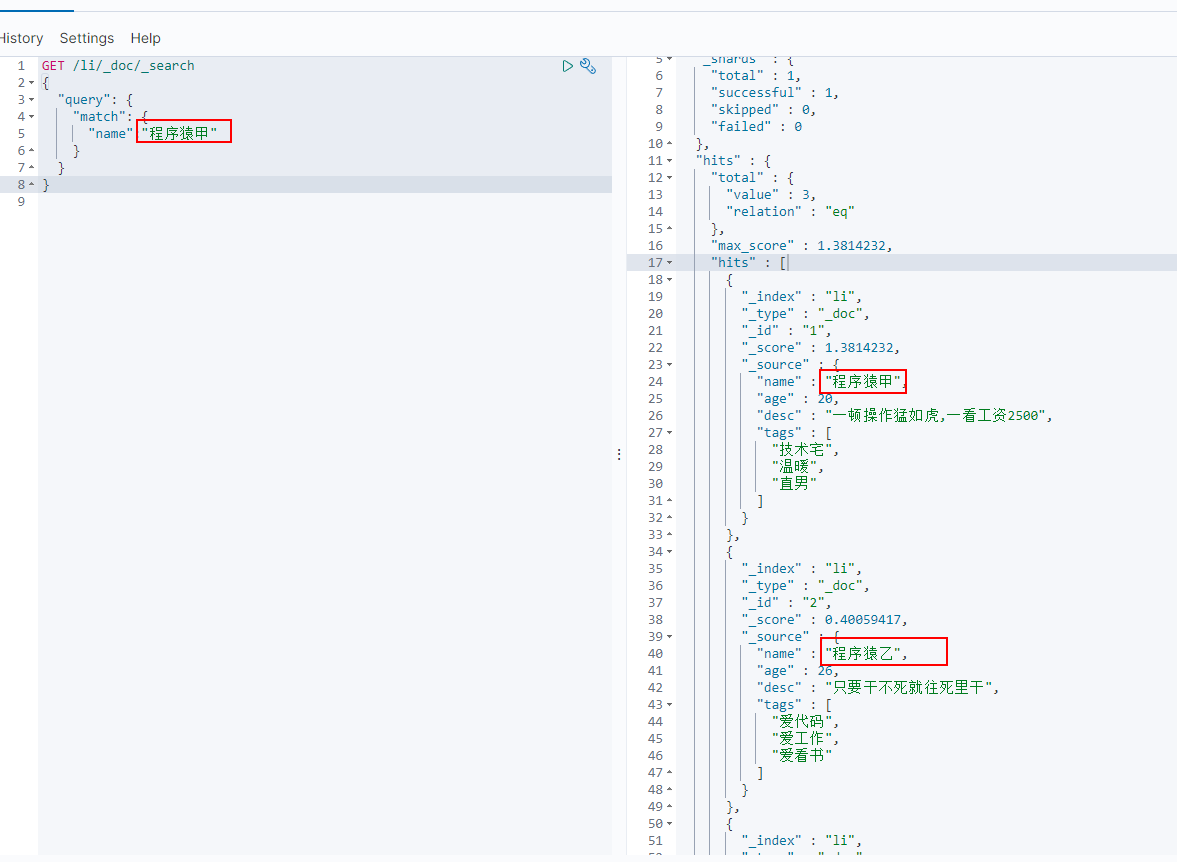
match查询:match查询会将我们的查询的关键字进行分词(分为 程序猿+甲),然后去匹配,但由于我们未设置索引的name字段类型,es默认name为text类型,es对索引的字段name也会进行分词分为 程序猿+甲+乙+丙几种,所以能匹配到包含程序猿的
GET /li/_doc/_search
{
"query": {
"match": {
"name":"程序猿甲"
}
}
}
operator:但我们也可以使用operator 要求搜索的关键字进行分词后,使用and(默认是or 例如上面:程序猿 or 甲)
GET /li/_doc/_search
{
"query": {
"match": {
"name": {
"query": "程序猿甲",
"operator": "and"
}
}
}
}

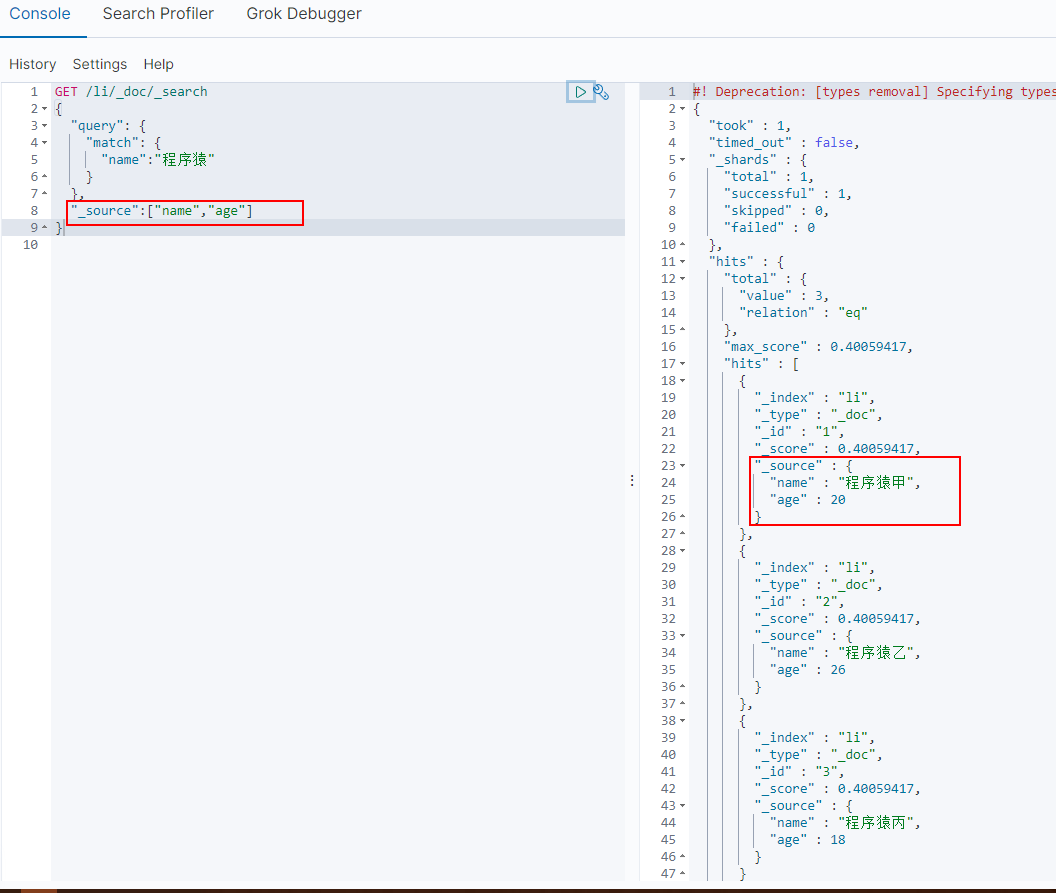
_source 限制返回属性
ES默认是返回文档中的所有字段,我们可以使用_source进行限制字段返回
GET /li/_doc/_search
{
"query": {
"match": {
"name":"程序猿"
}
},
"_source":["name","age"]
}
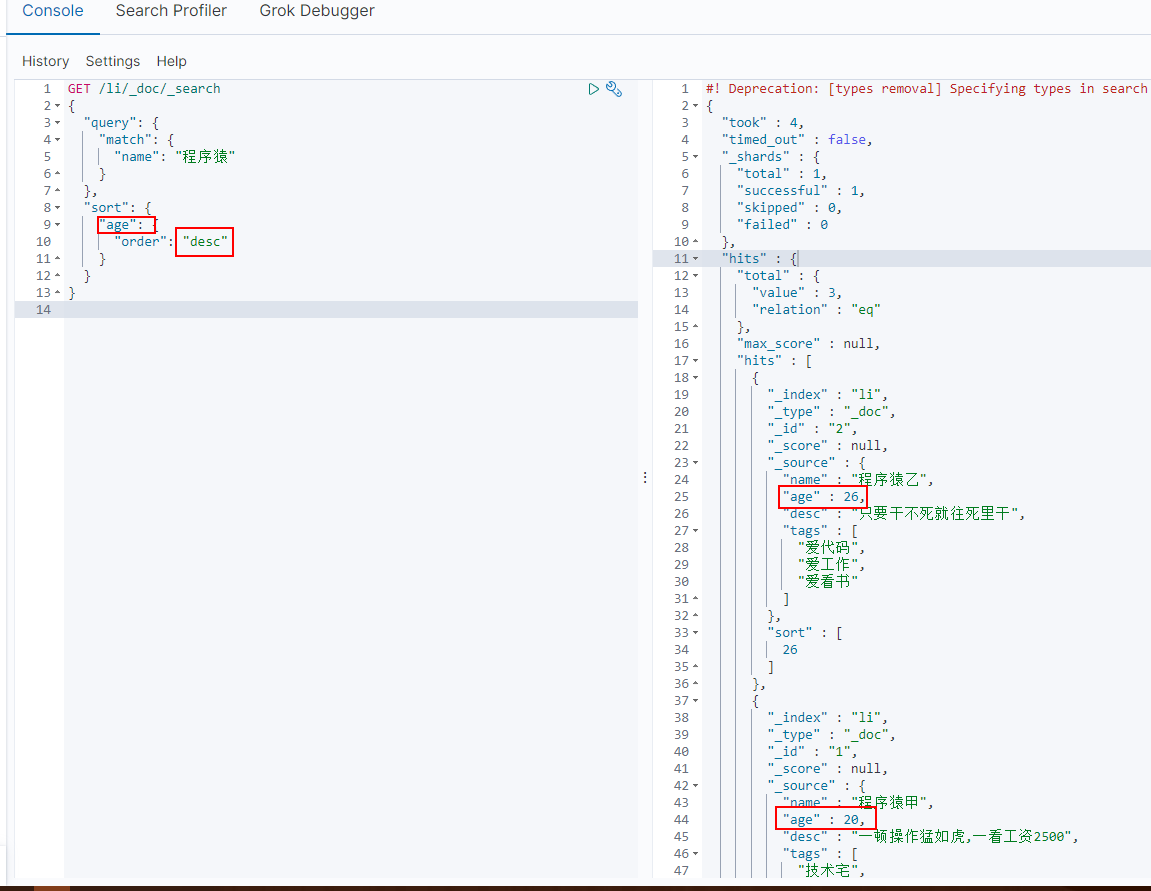
sort 排序
GET /li/_doc/_search
{
"query": {
"match": {
"name": "程序猿"
}
},
"sort": {
"age": {
"order": "desc"
}
}
}
from、size分页
from:开始下标 size:每页查询条数
GET /li/_doc/_search
{
"query": {
"match": {
"name": "程序猿"
}
},
"sort": {
"age": {
"order": "desc"
}
},
"from": 0,
"size": 1
}

bool 多条件组合查询
| 关键字 | 对应mysql中的关键字 |
|---|---|
| must | 等同于mysql中的 and |
| should | 等同于mysql中的 or |
| must_not | 等同于mysql中的 not |
| gt | > |
| lt | < |
| gte | >= |
| lte | <= |
GET /li/_doc/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "程序猿乙"
}
},
{
"match": {
"age": "26"
}
}
]
}
}
}

GET /li/_doc/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"desc": "最美不过程序猿"
}
},
{
"match": {
"age": "26"
}
}
]
}
}
}

GET /li/_doc/_search
{
"query": {
"bool": {
"must_not": [
{
"match": {
"desc": "最美不过程序猿"
}
},
{
"match": {
"age": "26"
}
}
]
}
}
}

GET /li/_doc/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"name": "程序猿"
}
}
],
"filter": {
"range": {
"age": {
"gt": 25
}
}
}
}
}
}

term 精确查询
term是直接去倒排索引进行词条的精确匹配。
构建测试数据:
name为text
desc为keyword

PUT /li2
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"desc": {
"type": "keyword"
}
}
}
}
PUT /li2/_doc/1
{
"name":"程序猿甲",
"desc":"谈一个对象 desc"
}
PUT /li2/_doc/2
{
"name":"程序猿乙",
"desc":"new一个对象 desc"
}
开始查询
GET /li2/_doc/_search
{
"query":{
"term":{
"name":"程"
}
}
}

GET /li2/_doc/_search
{
"query":{
"term":{
"desc":"new一个对象 desc"
}
}
}

tem的多条件精确匹配
GET /li2/_doc/_search
{
"query": {
"bool": {
"must": [
{
"term": {
"name": "甲"
}
},
{
"term": {
"desc": "谈一个对象 desc"
}
}
]
}
}
}

highlight 高亮查询
GET /li2/_doc/_search
{
"query": {
"match":{
"name":"程序"
}
},
"highlight": {
"fields":{
"name":{}
}
}
}

自定义高亮标签
pre_tags:前标签
post_tags:后标签
GET /li2/_doc/_search
{
"query": {
"match":{
"name":"程序"
}
},
"highlight": {
"pre_tags":"<p style='color:red'>",
"post_tags":"</p>",
"fields":{
"name":{}
}
}
}

3. 集成SpringBoot
-
找ElasticSearch官方文档
-
引入官方依赖,找到关键对象RestHighLevelClient
<!--elasticsearch依赖--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-elasticsearch</artifactId> </dependency> -
创建cilent对象 RestHighLevelClient
RestHighLevelClient restClient = new RestHighLevelClient(RestClient.builder(new HttpHost("127.0.0.1", 9200, "http"),new HttpHost("127.0.0.1", 9201, "http")));
3.1 创建项目
创建maven项目,创建module(使用springboot的骨架创建)


3.2 修改ES核心包的版本
我们看到2.2.5的springboot中集成的是es的 6.8.6版本,所以需要修改版本号为我们的es版本,7.6.0,找到es版本的标签,直接在我们的pom文件中进行覆盖

3.3 配置ES客户端对象
| 操作ES的对象 | 类型 | 备注 |
|---|---|---|
| Transport Client | 客户端 | 在ElasticSearch8中将被移除,在spring-data-elasticsearch:4.0版本中被标为过期,不推荐使用 |
| RestHighLevelClient | 客户端 | 高级Restful客户端,灵活度更高,但操作对象需要格式转换。推荐使用 |
| ElasticsearchOperations | 接口 | 直接注入使用,具体使用的客户端要看实现类所配置的客户端,也能使用,但是复杂查询可能比较麻烦 |
| ElasticsearchRepository | 接口 | Spring-data-elasticsearch 提供好的接口,只需要继承 ElasticsearchRepository 接口即可,底层使用的是ElasticsearchOperations 接口的方法(对ElasticsearchOperations接口的再次扩展) |
| ElasticsearchTemplate | 实现类 | 是 ElasticsearchOperations的实现,使用的是 Transport Client,在spring-data-elasticsearch:4.0版本中被标为过期,被ElasticsearchRestTemplate代替,不推荐使用 |
| ElasticsearchRestTemplate | 实现类 | 是 ElasticsearchOperations的实现,使用的是 RestHighLevelClient |
创建RestHighLevelClient 客户端
- 推荐使用这种,这种配置完客户端后就可以同时使用这两个对象 RestHighLevelClient、ElasticsearchRestTemplate
package com.yuening.esapi.config;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.util.StringUtils;
@Configuration
public class ElasticSearchClientConfig {
/**
* es的集群节点配置
* 127.0.0.1:9200,127.0.0.1:9201,127.0.0.1:9202
*/
@Value("${spring.elasticsearch.rest.uris}")
private String uri;
/**
* 创建es的客户端对象
*
* @return
*/
@Bean
public RestHighLevelClient restHighLevelClient() {
//单机版本 & 集群版本 官方文档:
//RestHighLevelClient restClient = new RestHighLevelClient(RestClient.builder(new HttpHost("127.0.0.1", 9200, "http"),new HttpHost("127.0.0.1", 9201, "http")));
if (StringUtils.isEmpty(uri)) {
throw new RuntimeException("elasticsearch uri is unset to properties file");
}
String[] nodes = uri.split(",");
HttpHost[] httpHosts = new HttpHost[nodes.length];
for (int x = 0; x < nodes.length; x++) {
String[] uris = nodes[x].split(":");
HttpHost httpHost = new HttpHost(uris[0], Integer.parseInt(uris[1]), "http");
httpHosts[x] = httpHost;
}
return new RestHighLevelClient(RestClient.builder(httpHosts));
}
}
- 这种配置完客户端后还必须要手动创建 ElasticsearchRestTemplate 才可注入使用 ElasticsearchRestTemplate(否则会报找不到类)
@Configuration
public class ElasticSearchClientConfig2 extends AbstractElasticsearchConfiguration {
/**
* es的集群节点配置
* 127.0.0.1:9200,127.0.0.1:9201,127.0.0.1:9202
*/
@Value("${spring.elasticsearch.rest.uris}")
private String uri;
/**
* 初始化 RestHighLevelClient
* @return
*/
@Override
@Bean
public RestHighLevelClient elasticsearchClient() {
final ClientConfiguration clientConfiguration = ClientConfiguration.builder().connectedTo(uri.split(",")).build();
return RestClients.create(clientConfiguration).rest();
}
/**
* 初始化 ElasticsearchRestTemplate 才能使用
* @return
*/
@Bean
public ElasticsearchRestTemplate elasticsearchRestTemplate() {
return new ElasticsearchRestTemplate(elasticsearchClient());
}
}
3.4 简单测试
这里会使用ElasticsearchRestTemplate、ElasticsearchOperations、RestHighLevelClient
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.client.indices.CreateIndexResponse;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.elasticsearch.core.ElasticsearchOperations;
import org.springframework.data.elasticsearch.core.ElasticsearchRestTemplate;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import java.io.IOException;
@RestController
public class TestController {
@Autowired
private ElasticsearchRestTemplate elasticsearchRestTemplate;
@Autowired
private ElasticsearchOperations elasticsearchOperations;
@Autowired
private RestHighLevelClient restHighLevelClient;
@GetMapping("/test")
public String test(){
boolean test = elasticsearchRestTemplate.createIndex("test");
return String.valueOf(test);
}
@GetMapping("/test2")
public String test2(){
boolean test2 = elasticsearchOperations.createIndex("test2");
return String.valueOf(test2);
}
@GetMapping("/test3")
public String test3() throws IOException {
CreateIndexRequest createIndexRequest = new CreateIndexRequest("test3");
CreateIndexResponse createIndexResponse = restHighLevelClient.indices().create(createIndexRequest, RequestOptions.DEFAULT);
return String.valueOf(createIndexResponse.isAcknowledged());
}
}
3.5 索引API
import org.elasticsearch.action.admin.indices.delete.DeleteIndexRequest;
import org.elasticsearch.action.support.master.AcknowledgedResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.client.indices.CreateIndexResponse;
import org.elasticsearch.client.indices.GetIndexRequest;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.io.IOException;
@SpringBootTest
class EsApiApplicationTests {
@Autowired
RestHighLevelClient restHighLevelClient;
@Test
public void createIndex() throws IOException {
CreateIndexRequest createIndexRequest = new CreateIndexRequest("yu");
//可以设置索引字段规则,也可以不设置,es会自动设置
XContentBuilder xContentBuilder = XContentFactory.jsonBuilder()
.startObject()
.startObject("properties")
.startObject("name").field("type", "keyword").endObject()
.startObject("age").field("type", "integer").endObject()
.startObject("desc").field("type", "text").endObject()
.endObject()
.endObject();
//也可以直接使用DLS语句中的json字符串 例如: createIndexRequest.mapping("",XContentType.JSON);
createIndexRequest.mapping(xContentBuilder);
CreateIndexResponse createIndexResponse = restHighLevelClient.indices().create(createIndexRequest, RequestOptions.DEFAULT);
boolean acknowledged = createIndexResponse.isAcknowledged();
System.out.println("索引创建成功," + acknowledged);
}
@Test
public void existsIndex() throws IOException {
GetIndexRequest getIndexRequest = new GetIndexRequest("yu");
boolean exists = restHighLevelClient.indices().exists(getIndexRequest, RequestOptions.DEFAULT);
System.out.println("索引是否存在,"+exists);
}
@Test
public void deleteIndex() throws IOException {
DeleteIndexRequest deleteIndexRequest = new DeleteIndexRequest("yu");
AcknowledgedResponse delete = restHighLevelClient.indices().delete(deleteIndexRequest, RequestOptions.DEFAULT);
System.out.println("索引删除成功,"+delete.isAcknowledged());
}
}
3.6 文档API CRUD
package com.yuening.esapi;
import com.alibaba.fastjson.JSONObject;
import com.yuening.esapi.domain.Student;
import org.elasticsearch.action.admin.indices.delete.DeleteIndexRequest;
import org.elasticsearch.action.bulk.BulkItemResponse;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.delete.DeleteRequest;
import org.elasticsearch.action.delete.DeleteResponse;
import org.elasticsearch.action.get.GetRequest;
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.action.support.master.AcknowledgedResponse;
import org.elasticsearch.action.update.UpdateRequest;
import org.elasticsearch.action.update.UpdateResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.client.indices.CreateIndexResponse;
import org.elasticsearch.client.indices.GetIndexRequest;
import org.elasticsearch.common.text.Text;
import org.elasticsearch.common.xcontent.XContentBuilder;
import org.elasticsearch.common.xcontent.XContentFactory;
import org.elasticsearch.common.xcontent.XContentType;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.MatchQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.index.query.RangeQueryBuilder;
import org.elasticsearch.index.query.TermQueryBuilder;
import org.elasticsearch.index.query.WildcardQueryBuilder;
import org.elasticsearch.rest.RestStatus;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightField;
import org.elasticsearch.search.sort.SortBuilders;
import org.elasticsearch.search.sort.SortOrder;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
@SpringBootTest
class EsApiApplicationTests {
@Autowired
RestHighLevelClient restHighLevelClient;
@Test
public void createDocument() throws IOException {
// PUT /yu/_doc/1
Student stu = new Student("张三", 18, "张三说我不是李四");
//构建索引请求,参数为索引名称
IndexRequest indexRequest = new IndexRequest("yu");
//设置文档id
indexRequest.id("1");
//将我们的数据放入请求中 json格式
indexRequest.source(JSONObject.toJSONString(stu), XContentType.JSON);
//发起创建索引的请求
IndexResponse index = restHighLevelClient.index(indexRequest, RequestOptions.DEFAULT);
RestStatus status = index.status();
System.out.println("文档创建成功," + status);
}
/**
* 获取文档
*
* @throws IOException
*/
@Test
public void getDocument() throws IOException {
// GET /yu/_doc/1
GetRequest getRequest = new GetRequest("yu", "1");
/**
* {
* "_index":"yu",
* "_type":"_doc",
* "_id":"1",
* "_version":1,
* "_seq_no":0,
* "_primary_term":1,
* "found":true,
* "_source":{
* "age":18,
* "desc":"张三说我不是李四",
* "name":"张三"
* }
* }
*/
GetResponse getResponse = restHighLevelClient.get(getRequest, RequestOptions.DEFAULT);
//获取文档中的_source内容,为string
String sourceAsString = getResponse.getSourceAsString();
Student student = JSONObject.parseObject(sourceAsString, Student.class);
System.out.println("文档获取成功," + JSONObject.toJSONString(student));
//获取文档中的_source内容为map
Map<String, Object> sourceAsMap = getResponse.getSourceAsMap();
System.out.println("文档获取成功," + JSONObject.toJSONString(sourceAsMap));
}
/**
* 更新文档
*
* @throws IOException
*/
@Test
public void updateDocument() throws IOException {
UpdateRequest updateRequest = new UpdateRequest("yu", "1");
Student stu = new Student();
stu.setDesc("我说你就是李四啊啊啊啊");
// POST /yu/_doc/1/_update {"doc":{"desc":"我说你就是李四啊啊啊啊"}}
updateRequest.doc(JSONObject.toJSONString(stu), XContentType.JSON);
/**
* {
* "fragment":false,
* "id":"1",
* "index":"yu",
* "primaryTerm":1,
* "result":"UPDATED",
* "seqNo":2,
* "shardId":{
* "fragment":true,
* "id":-1,
* "index":{
* "fragment":false,
* "name":"yu",
* "uUID":"_na_"
* },
* "indexName":"yu"
* },
* "shardInfo":{
* "failed":0,
* "failures":[
*
* ],
* "fragment":false,
* "successful":1,
* "total":2
* },
* "type":"_doc",
* "version":3
* }
*/
UpdateResponse update = restHighLevelClient.update(updateRequest, RequestOptions.DEFAULT);
System.out.println("更新文档成功," + JSONObject.toJSONString(update));
}
/**
* 删除文档
*
* @throws IOException
*/
@Test
public void deleteDocument() throws IOException {
DeleteRequest deleteRequest = new DeleteRequest("yu", "1");
DeleteResponse delete = restHighLevelClient.delete(deleteRequest, RequestOptions.DEFAULT);
RestStatus status = delete.status();
System.out.println("删除文档成功," + status);
}
/**
* 批量操作文档 新增、更新、删除
*/
@Test
public void bulkOperateDocument() throws IOException {
//批处理请求
BulkRequest bulkRequest = new BulkRequest();
List<Student> studentList = new ArrayList<>();
Student stu1 = new Student("李四", 1, "我是李四");
Student stu2 = new Student("李四2", 2, "我是李四2");
Student stu3 = new Student("李四3", 3, "我是李四3");
Student stu4 = new Student("李天奎1", 4, "我是李天奎1我也是李天奎");
Student stu5 = new Student("李天奎2", 5, "我是李天奎2我也是李天奎");
Student stu6 = new Student("李天奎3", 6, "我是李天奎3");
studentList.add(stu1);
studentList.add(stu2);
studentList.add(stu3);
studentList.add(stu4);
studentList.add(stu5);
studentList.add(stu6);
studentList.forEach(p -> {
//也可以创建批量更新、批量删除
//UpdateRequest updateRequest = new UpdateRequest("yu","1");
//DeleteRequest deleteRequest = new DeleteRequest("yu","1");
IndexRequest indexRequest = new IndexRequest("yu");
//indexRequest.id(); 可不设置id,es会默认生成一个字符串id
//将我们需要批量处理的数据 放入source中
indexRequest.source(JSONObject.toJSONString(p), XContentType.JSON);
//将请求添加到 批处理请求中
bulkRequest.add(indexRequest);
});
BulkResponse bulk = restHighLevelClient.bulk(bulkRequest, RequestOptions.DEFAULT);
boolean b = bulk.hasFailures();//是否有失败
BulkItemResponse[] items = bulk.getItems();//获取此次批处理执行的结果集合
System.out.println("批量插入文档成功,是否全部成功:" + !b + "," + JSONObject.toJSONString(items[0]));
}
/**
* 搜索文档
*
* @throws IOException
*/
@Test
public void searchDocument() throws IOException {
//构建搜索请求
SearchRequest searchRequest = new SearchRequest("yu");
//构建搜索条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("name", "李");
searchSourceBuilder.query(termQueryBuilder);
searchRequest.source(searchSourceBuilder);
//发起请求
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
SearchHits hits = searchResponse.getHits();
System.out.println("查询文档成功:" + JSONObject.toJSONString(hits));
}
/**
* 搜索文档 Query && Filter Query
*
* Query:查询结果会计算文档得分,并根据文档得分进行返回
* Filter Query:过滤查询,用在大数据量中筛选出查询的相关结果,不会计算文档得分
* 而且ES对filter query进行优化,对于经常使用的filter query的查询结果进行缓存,方便下次查询
*
* 注意:es中一旦同时使用了 query和filter query,es会先执行filter query再去执行query(类似于mysql的where条件过滤),可以提高查询效率
*
* @throws IOException
*/
@Test
public void searchQueryAndFilterQueryDocument() throws IOException {
//构建搜索请求
SearchRequest searchRequest = new SearchRequest("yu");
//构建搜索条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("name", "李天奎3");
//同时使用 query和filter query
searchSourceBuilder.query(termQueryBuilder).postFilter(QueryBuilders.termQuery("age",6));
searchRequest.source(searchSourceBuilder);
//发起请求
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
SearchHits hits = searchResponse.getHits();
System.out.println("查询文档成功:" + JSONObject.toJSONString(hits));
}
/**
* 搜索文档bool查询
*
* @throws IOException
*/
@Test
public void searchBoolDocument() throws IOException {
//构建搜索请求
SearchRequest searchRequest = new SearchRequest("yu");
//构建搜索条件
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//构建排序条件
searchSourceBuilder.sort(SortBuilders.fieldSort("age").order(SortOrder.DESC));
//构建match查询条件
MatchQueryBuilder nameMatchQueryBuilder = QueryBuilders.matchQuery("name", "李");
//构建range范围查询条件
RangeQueryBuilder ageRangeQueryBuilder = QueryBuilders.rangeQuery("age").from(3).to(6);
//构建通配符条件
WildcardQueryBuilder wildcardQueryBuilder = QueryBuilders.wildcardQuery("desc", "*奎*");
//构建bool查询条件
BoolQueryBuilder queryBuilder = QueryBuilders.boolQuery().must(nameMatchQueryBuilder).must(ageRangeQueryBuilder).must(wildcardQueryBuilder);
searchSourceBuilder.query(queryBuilder);
searchRequest.source(searchSourceBuilder);
//发起请求
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
//获取返回值,以及总记录数
SearchHits hits = searchResponse.getHits();
long value = searchResponse.getHits().getTotalHits().value;
System.out.println("bool查询文档成功,总记录数:" + value + ",详细结果:" + JSONObject.toJSONString(hits));
}
/**
* 分页查询文档
*
* @throws IOException
*/
@Test
public void searchPageDocument() throws IOException {
//构建搜索请求
SearchRequest searchRequest = new SearchRequest("yu");
//构建SearchSourceBuilder
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//构建分页查询 下标0开始-查5条
searchSourceBuilder.from(0).size(5);
//fetchSource可以指定只返回的字段,也可以指定需要排除的字段,第一个参数为:包含的字段数组 第二个参数为:需要排除的字段数组
searchSourceBuilder.fetchSource(new String[]{"name","desc"},new String[]{});
//构建通配符条件
WildcardQueryBuilder wildcardQueryBuilder = QueryBuilders.wildcardQuery("desc", "*奎*");
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery().must(wildcardQueryBuilder);
searchSourceBuilder.query(boolQueryBuilder);
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
//获取返回值,以及总记录数
SearchHits hits = searchResponse.getHits();
long value = searchResponse.getHits().getTotalHits().value;
System.out.println("分页查询文档成功,总记录数:" + value + ",详细结果:" + JSONObject.toJSONString(hits));
}
/**
* 高亮查询文档
*
* @throws IOException
*/
@Test
public void searchHighlightDocument() throws IOException {
//构建搜索请求
SearchRequest searchRequest = new SearchRequest("yu");
//构建SearchSourceBuilder
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//构建HighlightBuilder高亮
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.field("desc");
highlightBuilder.preTags("<span style='color:red'>");
highlightBuilder.postTags("</span>");
//多个字段高亮的时候设置为false,否则只会高亮一个字段
highlightBuilder.requireFieldMatch(false);
//构建查询条件 desc中含有奎的,name中含有李的
WildcardQueryBuilder wildcardQueryBuilder = QueryBuilders.wildcardQuery("desc", "*奎*");
WildcardQueryBuilder wildcardQueryBuilder2 = QueryBuilders.wildcardQuery("name", "*李*");
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery().should(wildcardQueryBuilder).should(wildcardQueryBuilder2);
searchSourceBuilder.highlighter(highlightBuilder).query(boolQueryBuilder);
searchRequest.source(searchSourceBuilder);
List<Map<String, Object>> mapList = new ArrayList<>();
//执行搜索请求
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
//解析高亮,返回结果中并不是直接把_source中的字段desc加上了高亮标签,而是单独返回了高亮的字段,需要我们自行进行替换
SearchHits hits = searchResponse.getHits();
for (SearchHit hit : hits.getHits()) {
//获取高亮的字段
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
//获取_source map
Map<String, Object> sourceAsMap = hit.getSourceAsMap();
//获取高亮字段desc
HighlightField descHighlightField = highlightFields.get("desc");
//判断是不是为空,不然你匹配的第一个结果没有高亮内容,那么就会报空指针异常
if (null != descHighlightField) {
//获取高亮字段的文本内容(是个数组)
Text[] texts = descHighlightField.getFragments();
StringBuilder textStr = new StringBuilder();
for (Text text : texts) {
textStr.append(text);
}
//替换掉_source中的desc字段内容
sourceAsMap.put("desc", textStr);
mapList.add(sourceAsMap);
}
}
System.out.println(JSONObject.toJSONString(mapList));
}
}
3.7 聚合查询
聚合:英文为Aggregation,简称Aggs ,聚合查询是es除了搜索功能外提供的针对es数据做数据统计分析的功能。聚合有助于根据搜索查询提供聚合数据。聚合查询是数据库中重要的功能特征。它是基于查询条件来对数据进行分桶、计算的方法。有点类似于sql中的group by再加一下函数方法的操作。
注意:text类型的字段是不支持聚合的(text是支持分词的,无法聚合统计)
es中的聚合,例如:terms分组、max、min、avg、sum
kibana的语法:
3.7.1 字段分组统计
size:如何不设置为0,会默认返回hits集合,默认返回前10条数据,而我们只需要聚合结果即可,设置为0即可
age_group:自定义的聚合的名字,一般以 字段+聚合函数类型,此处是按照age分组,所以命名为age_group
GET /yu/_doc/_search
{
"query":{
"match_all":{}
},
"size":0,
"aggs":{
"age_group":{
"terms":{
"field":"age"
}
}
}
}

3.7.2 最大值&最小值
GET /yu/_doc/_search
{
"query":{
"match_all":{}
},
"size":0,
"aggs":{
"age_max":{
"max":{
"field":"age"
}
}
}
}

GET /yu/_doc/_search
{
"query":{
"match_all":{}
},
"size":0,
"aggs":{
"age_min":{
"min":{
"field":"age"
}
}
}
}

3.7.3 平均值
GET /yu/_doc/_search
{
"query":{
"match_all":{}
},
"size":0,
"aggs":{
"age_avg":{
"avg":{
"field":"age"
}
}
}
}

3.7.4 求和
GET /yu/_doc/_search
{
"query":{
"match_all":{}
},
"size":0,
"aggs":{
"age_sum":{
"sum":{
"field":"age"
}
}
}
}

RestHighLevel的写法:
/**
* 聚合分组统计查询
* 例如:查询各年龄段的人数
*
* @throws IOException
*/
@Test
public void searchAggsDocument() throws IOException {
//构建搜索请求
SearchRequest searchRequest = new SearchRequest("yu");
//构建SearchSourceBuilder
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//构建查询,size默认为0 && 构建聚合
searchSourceBuilder.query(QueryBuilders.matchAllQuery())
.size(0)
.aggregation(AggregationBuilders.terms("age_group").field("age"))
//.aggregation(AggregationBuilders.terms("name_group").field("name"))
;
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
Aggregations aggregations = searchResponse.getAggregations();
//获取聚合统计分组的结果,因为年龄是int类型,使用ParsedLongTerms接收
ParsedLongTerms parsedLongTerms = aggregations.get("age_group");
//如果是name字段,那就用ParsedStringTerms类接收
//ParsedStringTerms parsedStringTerms = aggregations.get("name_group");
List<? extends Terms.Bucket> buckets = parsedLongTerms.getBuckets();
buckets.forEach(p -> {
System.out.println("age:" + p.getKey() + ",count:" + p.getDocCount());
});
}
/**
* 聚合Max、Min、Sum、Avg查询
*
* @throws IOException
*/
@Test
public void searchAggsMaxMinSumAvgDocument() throws IOException {
//构建搜索请求
SearchRequest searchRequest = new SearchRequest("yu");
//构建SearchSourceBuilder
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//构建查询,size默认为0 && 构建聚合
searchSourceBuilder.query(QueryBuilders.matchAllQuery())
.size(0)
.aggregation(AggregationBuilders.max("age_max").field("age")) //设置max聚合查询
.aggregation(AggregationBuilders.min("age_min").field("age")) //设置min聚合查询
.aggregation(AggregationBuilders.sum("age_sum").field("age")) //设置sum聚合查询
.aggregation(AggregationBuilders.avg("age_avg").field("age")) //设置avg聚合查询
;
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
Aggregations aggregations = searchResponse.getAggregations();
ParsedMax parsedMax = aggregations.get("age_max");
ParsedMin parsedMin = aggregations.get("age_min");
ParsedSum parsedSum = aggregations.get("age_sum");
ParsedAvg parsedAvg = aggregations.get("age_avg");
System.out.println("age_max:"+parsedMax.getValue());
System.out.println("age_min:"+parsedMin.getValue());
System.out.println("age_sum:"+parsedSum.getValue());
System.out.println("age_avg:"+parsedAvg.getValue());
}
总结
以上就是ES的入门级简单总结,学无止境,继续努力!!!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号