磁盘、mysql、redis、hana 的故事!
我们所接触到的事物,都有他的同类存在。硬件设备的突破,如 cpu,内存条等;数据的管理技术:人工表管理数据,机器卡片物理管理数据,磁盘管理数据,磁盘管理数据等等,有的因为需求增加,现状不满足需求时,就会被动的去更新升级,有的是为了满足需求更大的需求,也有的提前去挖掘需求,还有的是为了学术研究,突破,探索更深层次的事物。
磁盘对于数据存储的重要性
我们知道电脑有硬盘的组成,我们的文件,程序等数据放在硬盘或软盘中,那我们要拿硬盘或软盘中的某个文件的数据时,如在一个文件中搜索 MmoMartin 的字符串,就会涉及到磁盘的寻址(寻址比较好理解,就比如外卖小哥接到外卖单好,带着外卖送到指定地点,这个客户的下单地址就是外卖小哥要找的地址,也就是磁盘的寻址,然后等待对方领外卖,完成送外卖操作。这个操作涉及两个时间段:第一个时间段是外卖小哥送达的时间耗时,第二个时间段是等待客户领外卖的时间耗时。磁盘的寻址的响应时间=寻址时间 + 等待时间,一般情况下磁盘的寻址是ms级别,内存的寻址为ns级别,磁盘的吞吐一般在几百 M,快的可以达到几个 G,想深入了解的可以去搜索下磁盘原理)
回到文件搜索 MmoMartin 的字符串,当你打开一个大小为 10G,百 G 的文本文件时,若你用 txt
文档打开的话,打开很卡(大家应该遇见过吧),因为其中涉及到磁盘的寻址与吞吐,所以慢很正常,打开都困难了何况搜索。为了解决这个问题,有多种方案,如:
将很大的文件拆分成小文件存储。以文件为 100G 为例,若每个文件存储 512M 的话,需要 200
个文件,也就是你需要打开 200 个文件去搜索 MmoMartin 这个字符串,这种方式比起将 100G
堆在一个文件来说,磁盘寻址的响应时间是可以缩短。是不是有点麻烦哦,那有没有更加简便的方法去实现呢?以下以 mysql 为例。
mysql 存储数据
嗯,mysql 数据库是可以让查找数据更加快的。那为啥建立索引可以让他快呢?
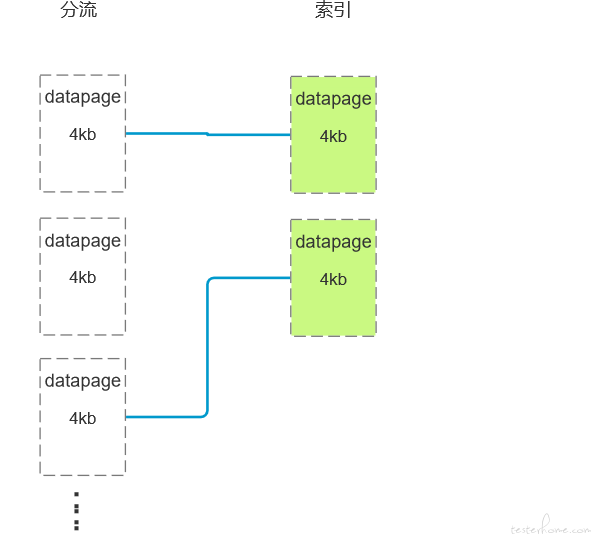
先说快吧,建立索引,可以让数据搜索快,其实,mysql 的底层实现也是将一个表的数据存储在类似盒子的东西里面,mysql 官方称
datapage,我们就叫它盒子,盒子大小为 4KB 或 8KB 或者 16KB 等(默认盒子大小都为
4KB)。首先将表的数据按照切分成盒子这样大小的数据,很多个,然后放进盒子(这个步骤我们叫它--分流),若单单这样操作跟磁盘操作一样,搜索
MmoMartin
还是得遍历啊,对吧,速度也不见长。为了解决让其快,他将对应的列的数据也拿出来,也放到盒子去,该列所处的盒子会记录该数据对应分流的哪个盒子,是不是跟
key-value
很像哦。这样子是不是可以根据所处的索引列的盒子直接拿分流的盒子了,不用一一去遍历(拆)分流的盒子了,直接取出分流的盒子,遍历该盒子的数据就 OK
了。增加、删除、修改需要重新建立新的索引的盒子,会导致索引不起作用,这也就是大家常常说增加、删除、修改会让索引不起作用。这只是建立了类似 key-value,理想情况下,无论分流的数据有多大,只要索引的盒子不被破坏,查询速度也是那样快的。那能不能让 mysql 更加快呢?
进一步优化 mysql 的索引
由于索引列的数据也是放在盒子的,为了在查找索引的盒子的速度再提升,就有了B+ 树的出现了,很多博客也说了为啥 mysql 的索引是 B+ 树的原因,大家可以去看看。mysql 的索引机制如图:
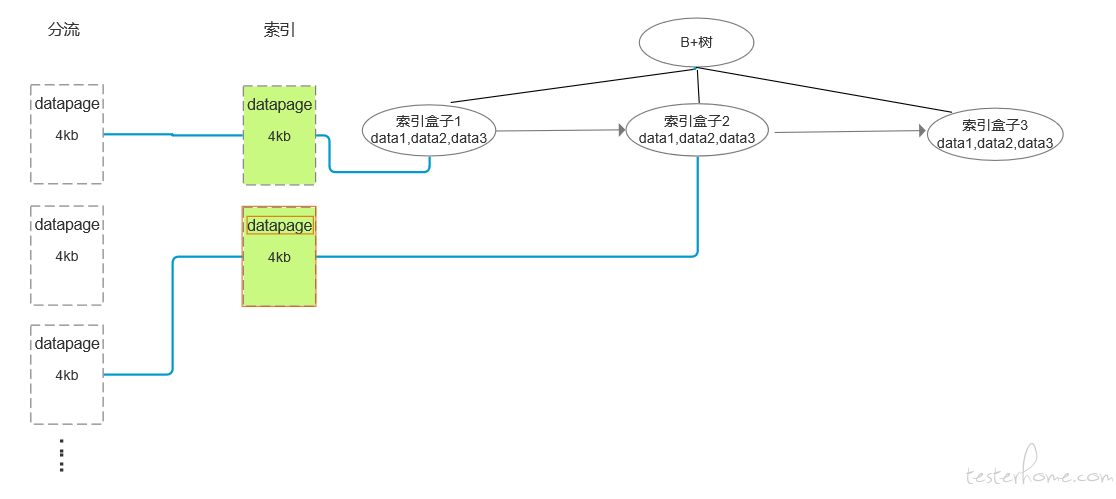
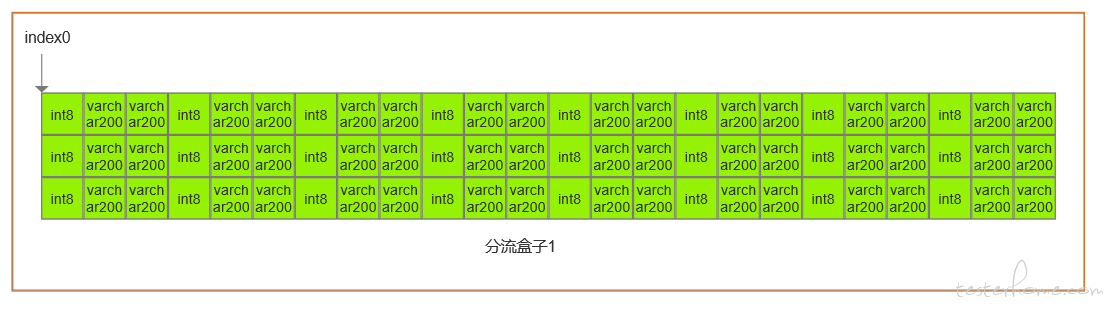
mysql 查找 MmoMartin 字符串,首先通过 B+ 树找到索引的盒子,然后通过盒子直接去找分流的盒子,然后遍历分流盒子的数据,由于 mysql 是行式存储(因为每列都带有数据类型,建表的列时需要指定大小,如下图),按照每列指定的的大小进行偏移就可以将带有 MmoMartin 的该行数据读取,输出,这样就提升了查找的能力,这也是设计数据库时为啥要尽量的设计列字段的大小合适的原因,大的在偏移过程中是需要时间的。若 B+ 树找索引盒子的算法是在内存进行的,我觉得可以提高一个档次了。既然内存辣么牛逼,那有没有直接在内存操作的数据库?嗯 ,答案是有的
我是最贵的数据库--HANA
嗯,确实是存在内存的数据库,为了让数据读写更快以及知道内存的读写时 ns 级别的,有个公司发明了一个数据库,该数据库是直接在内存运行的,那就是 HANA,但是造价相当相当的贵哦,内存最小貌似 2T,数据的操作无需放到硬盘,直接存储在内存,用户可以直接对大量实时业务数据进行查询和分析,而不需要对业务数据进行建模、聚合,被称为 HANA(High-Performance Analytic Appliance) 高性能分析设备,他们的设备一般都是整包出售的,ERP 系统,服务器等,售价自然也就贵了。既然这么贵,很多人用不起啊,那有没有一个工具也是内存读写数据,又便宜的数据存储的工具?嗯,也有。
我开源,我也是使用内存的存储数据的--Redis
由于 mysql 是跟磁盘打交道,速度有时跟不上,hana 是跟内存打交道但是太贵了,用不起,于是有人就发明了 redis 这个工具,也正是 redis 的开源,免费,高并发,速度快,才得以生存。当你的计算部分需要高速运行时,可以交给 redis 操作,这样你的程序可以变得更快。redis 是直接占用内存,计算的操作也是内存,速度也就快了。当并发情况下,请求同一资源时,mysql 需要开启事务,结束事务操作(事务锁,告诉其他人该 shi 坑我占用了,其他人等待),才能保证数据的准确性,但是 redis 不需要,直接在内存操作,没有涉及锁不锁的问题,数据直接更新,下个人拿的数据就是最新的数据,速度上也就快了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号