
存储引擎系列(二):数据库索引底层数据结构 —— B+ 树
索引原理
只要是稍微了解 MySQL 数据库的同学都应该知道,合理设置索引字段可以有效提高数据库的查询性能,数据库索引也是底层的存储引擎维护的,那么为什么设置索引可以提升数据库查询性能?MySQL 数据库底层又是如何维护索引的?要解答这两个问题,我们首先要了解数据库索引的数据结构。
前面我们在《数据结构与算法》中花了两个教程的篇幅简单介绍过数据库索引技术的雏形:
之所以说是雏形,是因为其原理和数据库索引技术很接近,或者说,数据库索引是基于这两个索引技术为基石实现的,事实上也确实如此。
我们直接开门见山,MySQL 数据库索引底层使用的数据结构是 B+ 树,每个索引都对应着一棵 B+ 树,以主键索引为例,对应 B+ 树的叶子结点是按照主键值升序排序,每个叶子节点包含一条完整记录的所有信息,而这些叶子节点之上是数据库记录所在的页码(MySQL 通过数据页管理成千上万条记录,一个数据页包含多条记录,具体条数因单条记录大小而定,或者换句话说,一个数据页的空间是有限的,单条记录占据空间大,则存放条数少,反之存放条数多),而页码之上则是数据页目录索引,如果数据表记录非常多,那么还会继续在数据页目录索引之上再设置范围更广的目录索引的索引,依次类推,对应的 B+ 树结构图如下所示:
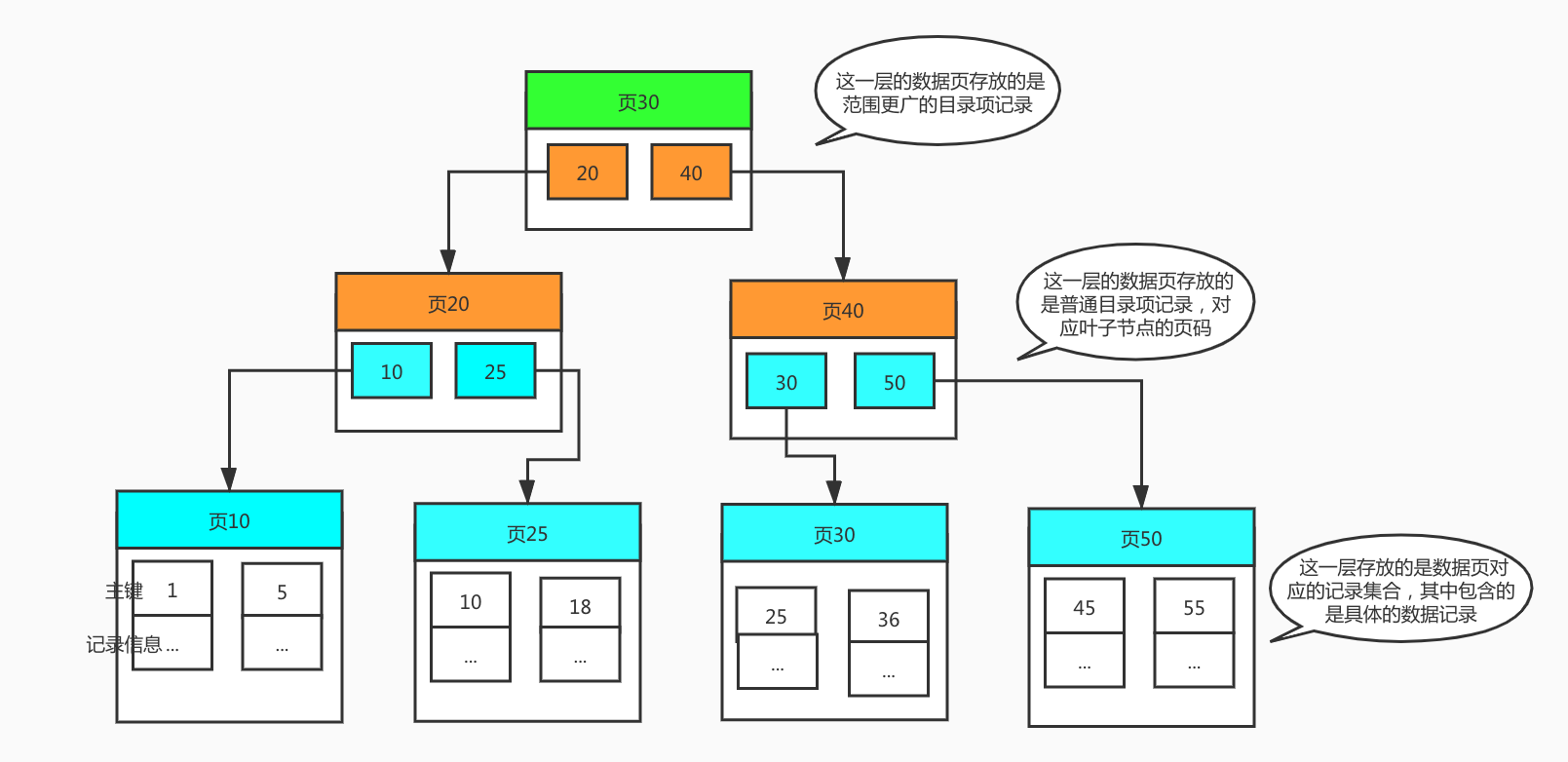
再将它与前面的分块索引示例图进行对比:
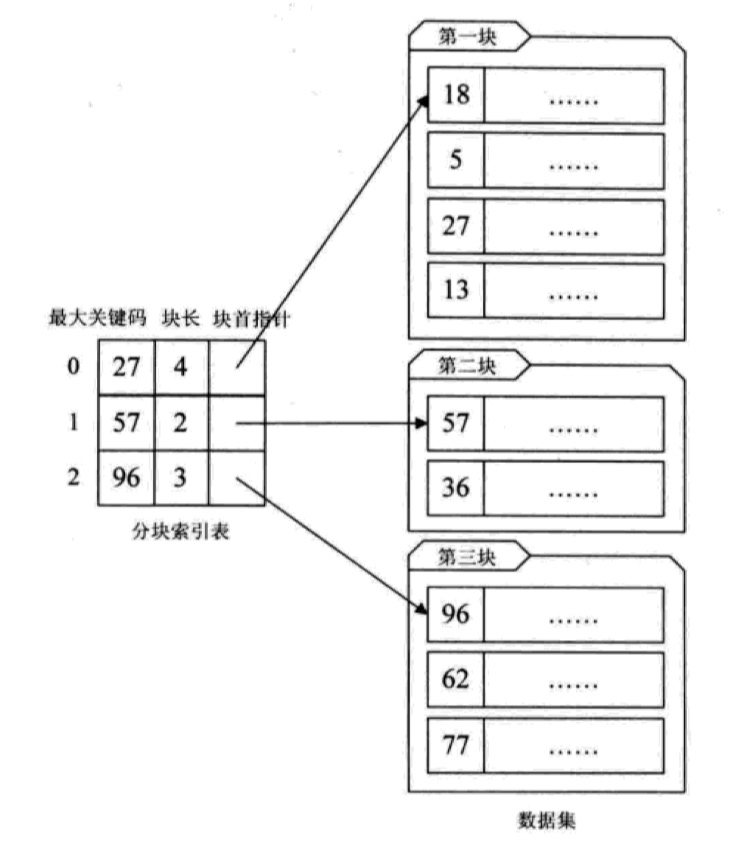
是不是很像?
对于包含索引的字段,如果查询条件命中了索引,则会沿着 B+ 树进行查找,还是以主键索引为例,我们可以根据主键值快速定位记录所在的页码(不难想象 B+ 树是一个巨大的、扁平化的多路树,非叶子节点的数据页结构中存储着该目录项中最小索引值,而叶子节点中的索引值又是升序排列),定位到页码后,就可以在对应的数据页通过二分查找(所有记录已经按照主键做好升序排序)快速定位主键对应记录的位置,对于主键索引,数据记录中包含了该记录的所有信息,所以直接返回就好,所以整个查询过程的时间复杂度基本等同于最后二分查找的时间复杂度,因此性能非常强悍,而如果没有命中索引,就要做全表扫描,对于数据量很大的数据表,自然就是龟速了。
关于数据库索引的不同类型、更新维护和查询细节,我们放到下篇教程详细介绍,这里,学院君想简单给大家介绍下 B+ 树及其由来。
B 树
B+ 树从 B 树衍生而来,它们都属于多路查找树,与二叉树每个节点至多只有两个子节点不同,多路树每个节点的子节点可以多于两个,并且每个节点可以存储多个元素。由于概念里面包含了「查找」二字,所以和二叉查找树一样,多路查找树的节点也是经过排序的。
我们先来看 B 树,B 树一种平衡的多路查找树(可以对比之前数据结构中介绍的平衡二叉树来理解,平衡二叉树是平衡的二叉查找树),也叫 B-树(B-tree 的直译,- 是连字符,不是减号),这种数据结构能够让查找数据、顺序访问、插入数据及删除的动作,都在对数级别的时间复杂度内完成,你可以把平衡二叉树看作是 B 树的特例。
既然平衡二叉树也可以做到对数级别的时间复杂度(O(logn)),那为什么还要引入 B 树呢?
这是因为对于数据库这种大块数据存取,数据记录的容量往往都是 GB 级别的,不可能同时将所有索引和记录信息加载到内存,我们上篇教程也介绍过,MySQL 数据库索引和记录都是存放在磁盘上的,这样一来,当我们查询数据库记录时,势必涉及到磁盘 IO,树的高度越高,磁盘 IO 次数也就越多,众所周知,磁盘 IO 效率很低,为了尽可能减少磁盘 IO,我们需要将平衡二叉树坍塌成 B 树这种多路树(与二叉树相比,可以把多路树想象成是「又胖又矮」的伞状结构),然后将所有索引数据存放到同一个层级的叶子节点,这样,就可以极大减少磁盘 IO,提升查询效率。
所以,B 树常被应用在数据库和文件系统这种外部存储的索引实现上。
对于 B 树而言,我们将任意节点最大的孩子数(叶子节点数)称之为 B 树的阶,假设这个数目是 m,则将该 B 树称为 m 阶 B 树,假设我们将英文字母构建成 B 树如下:
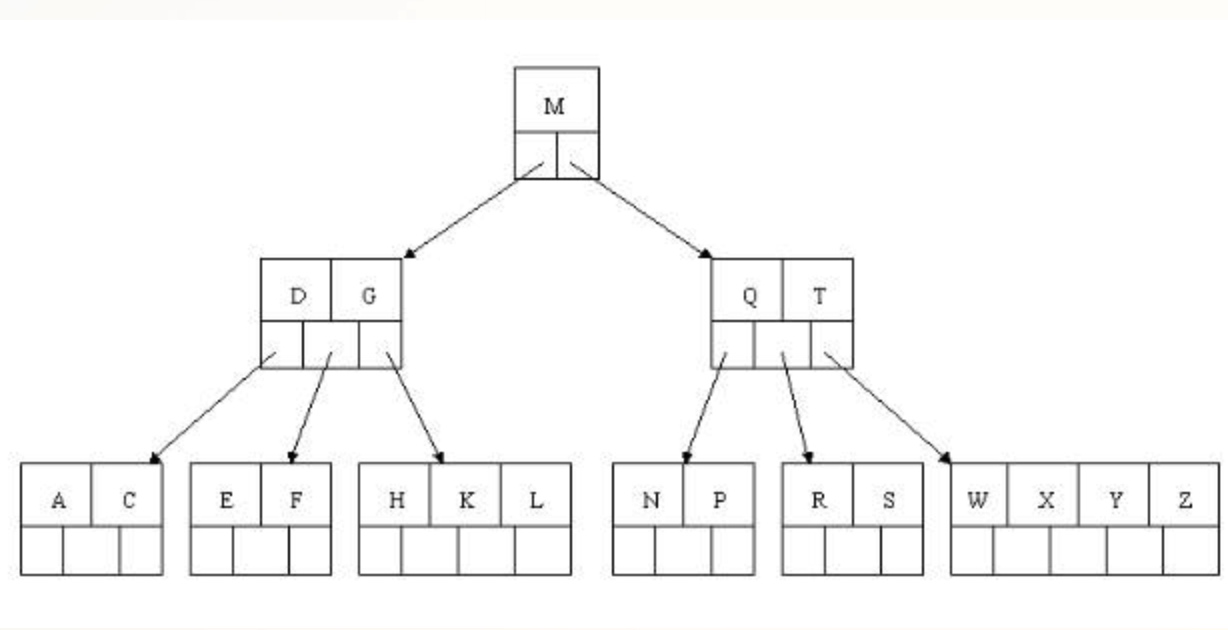
由于最大的孩子数是 3,所以可以将其称为 3 阶 B 树。
对于一个 m 阶 B 树,具备以下特点:
- 如果根节点不是叶子节点,则至少有两棵子树;
- 所有叶子节点都位于同一层级;
- 每个中间节点都包含
k-1个元素和k个孩子,其中 m/2 ≥ k ≤ m; - 每个叶子节点都包含
k-1个元素,其中 m/2 ≥ k ≤ m; - 每个节点中存放的元素都是按照从小到大升序排序。
关于 B 树的查询、插入、删除细节这里就不详细展开了,和平衡二叉树一样,插入和删除节点、元素时,B 树会进行自平衡。我们日常使用的非关系型数据库 MongoDB 就是使用 B 树来存储索引数据的。
而 MySQL 数据库索引实现使用的是 B+ 树,那么 B+ 树与 B 树有什么区别呢?
B+ 树
B+ 树是 B 树的一种变形,B+ 树的结构与 B 树类似,B+ 树包含两种类型的结点:内部节点(也称索引节点)和叶子节点。根结点既可以是内部节点,也可以是叶子节点。
B+ 树与 B 树最大的不同是内部节点不保存数据,只用于索引,所有数据记录都保存在叶子节点中。
注意对于 MySQL 数据库而言,这里的索引不是数据库索引,而是数据页的索引,数据库索引和数据都是作为数据记录存储在叶子节点的。虽然 MySQL 的索引和数据最终是持久化到磁盘中的,但是存储引擎具体处理数据的时候还是在和内存打交道,因此,要把磁盘中的数据加载到内存中,由于磁盘 IO 很慢,所以不可能一条一条的加载数据库记录,为此,MySQL 引入了数据页的概念:将一张表的数据记录划分成若干个数据页,然后以页为单位在磁盘和内存之间进行数据交换(不管是写入还是读取,都是以页为单位,以 InnoDB 为例,一个数据页的大小默认是 16 KB,即每次都是一次性从磁盘读取 16 KB 大小的数据,写入亦然)。
我们看一个简单的示例图,下面是一个存储 MySQL 索引数据的 B+ 树,非叶子节点中存放的是数据页目录索引,叶子节点存放的才是真正的索引数据:
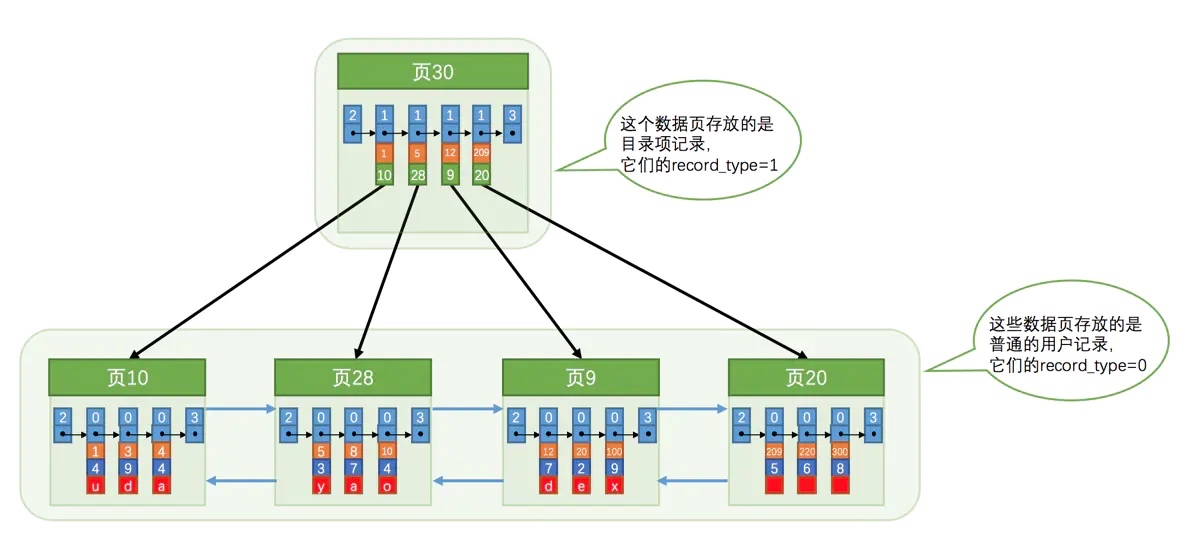
虽然所有的节点对应的都是数据页结构,但是 MySQL 底层会通过一个 record_type 来标识不同的数据页类型,值为 0 表示这个数据页存放的是普通的数据记录(包含数据表索引和数据),值为 1 表示这个数据页存放的是数据页目录索引,在这些数据页节点中不包含数据记录。
B+ 树这么设计的原因是为了简化查询和维护逻辑,避免在不同节点之间来回访问,另外,这种设计也方便进行带有范围的区间查询,比如我要查找 id 在 100 和 1000 之间的所有记录,只需要定位到 id=100 和 id=1000 的两条记录位置,然后把中间的所有记录返回即可(B+ 树本身按照主键索引进行升序排序了,如果 id 是主键的话)。
另外,对于 MySQL 底层的 B+ 树而言,每个节点对应一个数据页结构,对于非叶子节点由于不包含用户记录,只存放数据页索引,所以可以存放非常大的索引范围,这也进一步优化了 B+ 树的查询,减少磁盘 IO(树的高度越低,磁盘 IO 次数越少),而对于叶子节点而言,每个数据页中存放的记录都以索引字段为标识进行升序排序,这样,一旦通过索引定位到数据记录所在的数据页,就可以在数据页内部通过二分查找快速找到对应的数据记录,效率非常高。
假设每个数据页索引存放了 1000 个数据页,每个叶子节点的数据页中包含了 100 条记录,那么对于一个层高为 2 的 B+ 树,可以存放 10 万条记录,如果层高是 3 的话,则可以存放 1 亿条记录,而层高为 4 的话,可以存放 1000 亿条记录,相当惊人!即便是这么多条记录,如果查询语句命中索引的话,也只需要经历至多 4 次磁盘 IO,然后再通过一个时间几乎可以忽略的二分查找返回查询结果,这就是 MySQL 数据库选择 B+ 树作为底层索引数据结构的原因。
下篇教程,我们就以 InnoDB 存储引擎为例,深入底层探究 MySQL 底层插入数据记录时是如何维护不同索引对应的 B+ 树的,以及进行数据查询时,底层又是如何通过 B+ 树查询返回结果的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号