RAG 优化方案
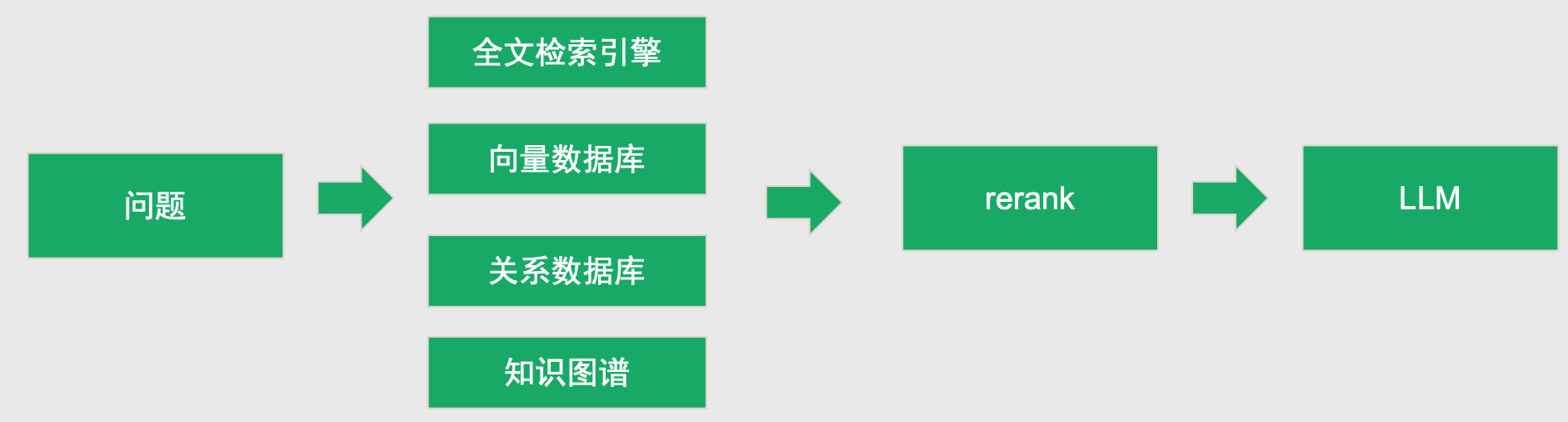
多路召回
定义:在RAG的检索阶段,同时使用多种异构的检索方法(如关键词、向量、语义等),从不同角度挖掘候选文档,形成互补的召回结果。
可以同时使用关键词匹配、向量检索、语义相似度等多种方法,每种方法作为一路召回,最后将结果合并或进一步处理。
- 具体的问题,使用向量数据库或者全文检索引擎。比如什么是LangChain?春节我们公司放假几天?
- 结构化数据,使用向量数据库是搞不定的。使用关系数据库或者全文检索搜索引擎(ES)。如统计有多少活跃用户,查询ID为101的用户情况
- 问题宏观, 跨文档查询:知识图谱
实际落地:
如果问题很单一,使用单一存储即可。
如果问题很复杂,需要多种存储,使用多路召回
rerank算法
在高性能RAG商业知识库案例 52-54有讲一些rerank算法
RAG 表格数据处理优化
需求:智能客服
用户希望大模型能够基于产品信息进行回复和(基于用户画像)推荐
初步方案:
因为是结构化数据,把数据存到关系数据库,或者ES.
问题 =>分析参数 (LLM) =>检索结构化(生成SQL 从数据库查询) =>数据生成回复 (LLM)
缺点:链路太长。需要2次LLM调用,慢且浪费资源
最终方案
1 把原始表格整理成QA对。
2 存储到ES和向量数据库
3 用户的问题来后,通过搜索ES和向量数据库做多路召回,效率很快
RAG embedding 不准的问题(严格来说不是embedding的问题)
-
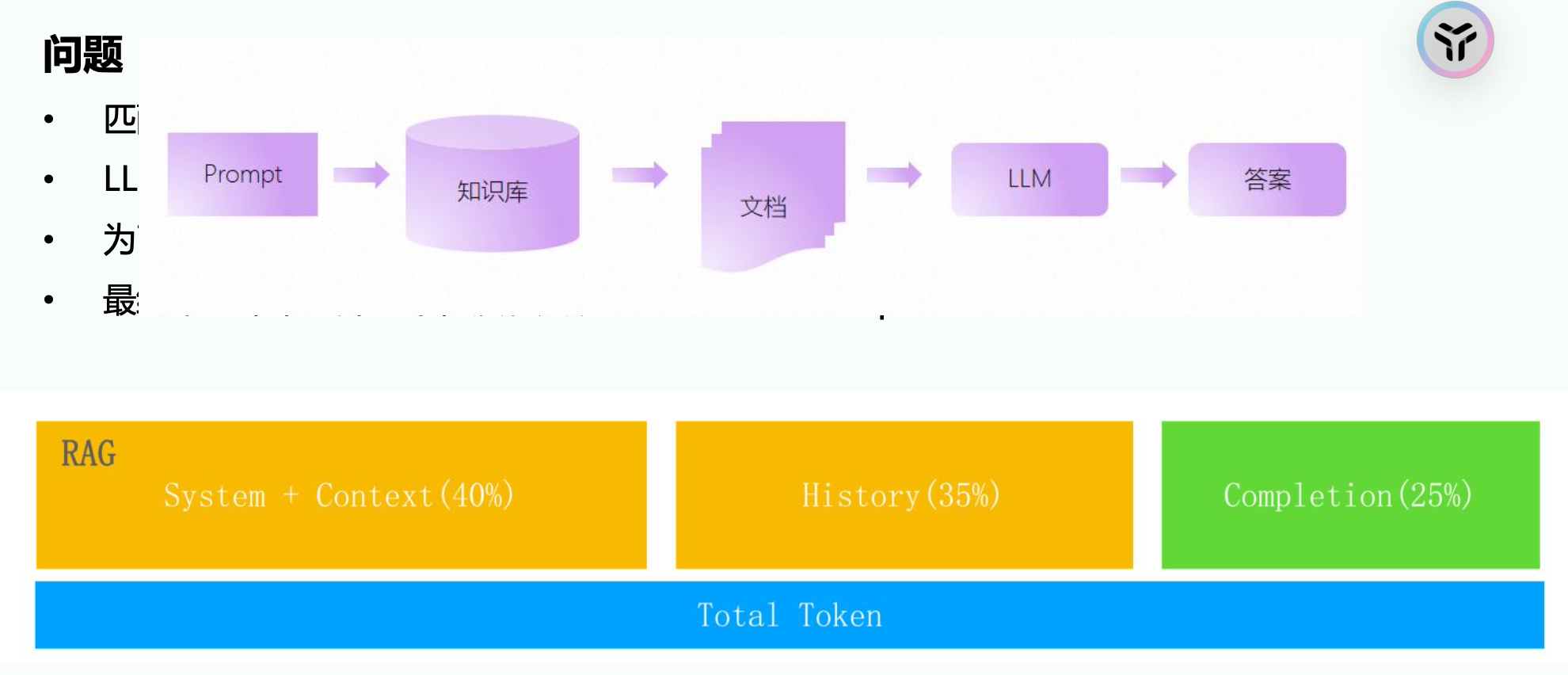
Token窗口不足导致 有意义的知识被丢弃(没进入大模型的提示词)。做法 1 减少历史消息的空间,记录最近5次,把更多空间给Sytem context, 2 增加总token带宽。比如32k升级为64k(费钱)
![]()
-
数据太多,针对性差,干扰太多,
对策:设计意图分类器。将知识
- 如果比较好区分,通过提示词和背景知识
- 如果不好区分,通过训练的小模型
RAG性能优化之幻 觉问题
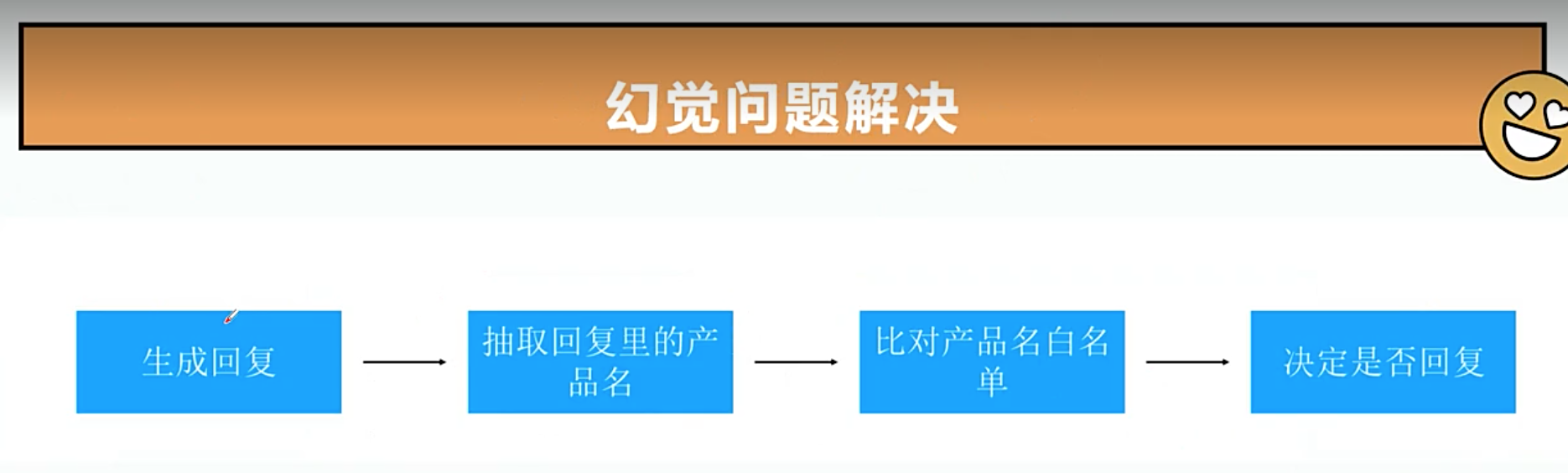
现象: 大模型自行编造产品,比如回复不存在的产品。
RAG模型部署
RAG涉及三种模型。1 LLM 2 embedding 3 rerank
Ollama 擅长大模型,不擅长管理embedding,rerank
Xinference/LocalAi 对大模型管理不如Ollama,擅长管理embedding,rerank
FastChat 用的比较多
缓存一致性
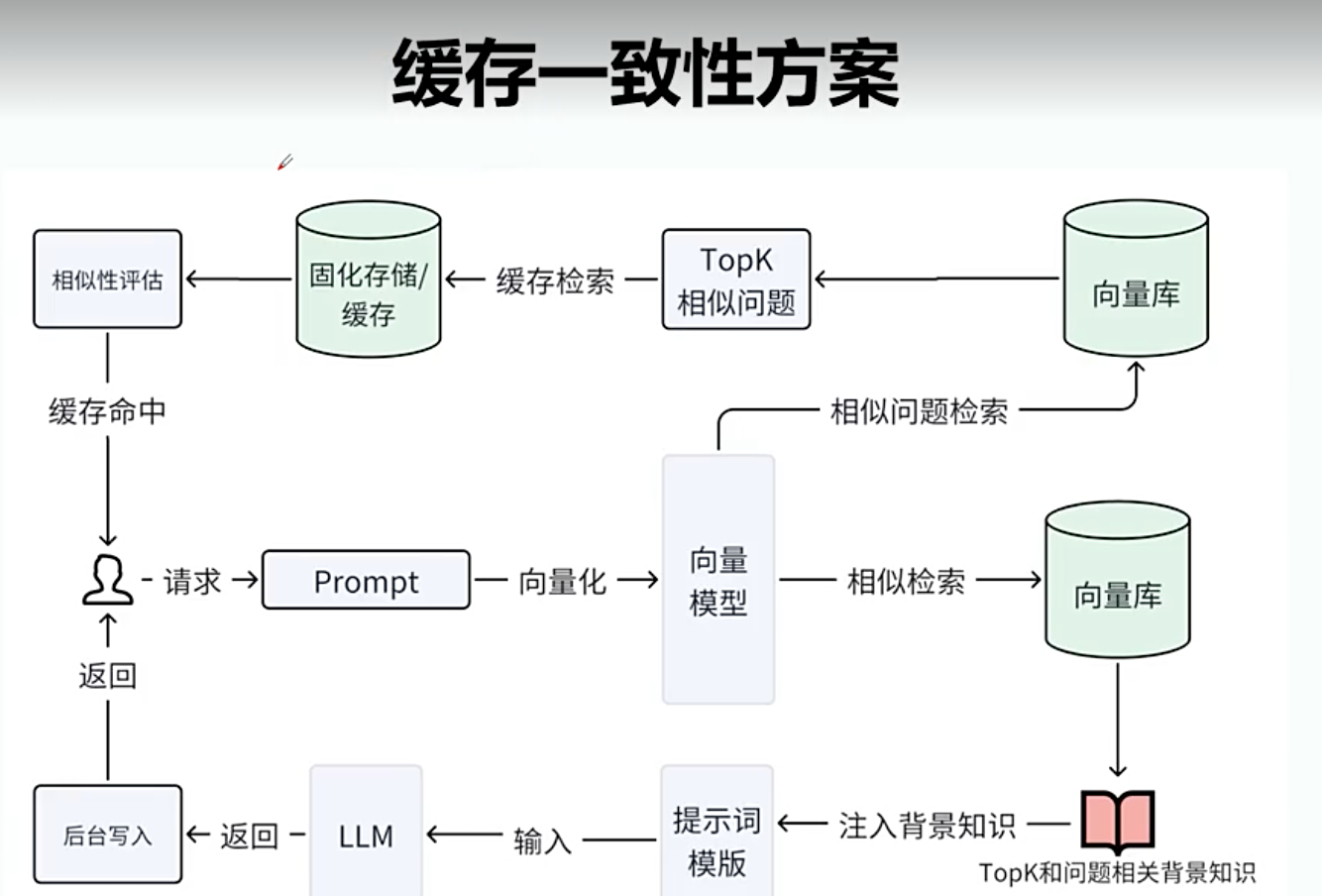
用户问的问题多做缓存化处理。1 问题先存在向量数据库,2 然后问题和答案存在Redis。
第二个问题去向量数据库查找相似的key,找到后去缓存查找返回给用户。
Redis和向量数据库的一致性解决:如果缓存向量数据库找不到(原因是写向量缓存成功,写redis失败),走向量知识库库查询返回给客户,再后再走一次缓存流程。
缓存失效方案: 1 知识库文档发生变化,把缓存向量的问题和 Redis的问题和答案失效掉 2 自动淘汰方案,用的最少得淘汰
有落地的开源方案:gtpcache

 浙公网安备 33010602011771号
浙公网安备 33010602011771号