
3、K均值(K-means)算法——非监督、聚类
1、K均值(K-means)算法
K均值算法,是一种广泛使用的非监督聚类算法。该算法通过比较样本之间的相似性,将较为相似的样本划分到同一个类别中。由于K均值算法简单、易于实现的特点而得到广泛应用。
K均值算法的缺点: K值是用户给定的,在进行数据处理前,K值未知,不同的K值得到的结果也不一样;对初始簇中心敏感;不适合发现非凸形状的簇或者大小差别较大的簇;特殊值对模型的影响比较大。
K均值算法的优点: 容易理解,聚类效果不错;处理大数据集的时候,该算法可以保证较好的伸缩性;当簇近似高斯分布的时候,效果非常不错。
2、相似性度量
在K均值算法中,通过某种相似性度量的方法,将较为相似的个体划分到同一个类别中。对于不同的应用场景,有着不同的相似性度量的方法。为了度量样本X和样本Y之间的相似性,一般定义一个距离函数$d\left( {X,Y} \right)$来表示。
假设有两个点,分别为点P和点Q,其对应的坐标分别为:
$P = \left( {{x_1}{\rm{,}}{x_2}{\rm{,}} \cdots {\rm{,}}{x_n}} \right) \in {R^n}$
$Q = \left( {{y_1}{\rm{,}}{y_2}{\rm{,}} \cdots {\rm{,}}{y_n}} \right) \in {R^n}$
通常使用的距离函数有:
(1)闵可夫斯基距离
点P和点Q之间的闵可夫斯基距离可以定义为:
$d\left( {P{\rm{,}}Q} \right) = {\left( {\sum\limits_{i = 1}^n {{{\left( {{x_i} - {y_i}} \right)}^p}} } \right)^{\frac{1}{p}}}$
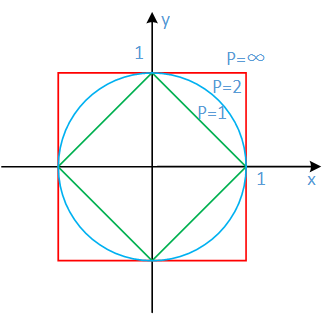
(2)曼哈顿距离
点P和点Q之间的曼哈顿距离可以定义为:
$d\left( {P{\rm{,}}Q} \right) = \sum\limits_{i = 1}^n {\left| {{x_i} - {y_i}} \right|} $
(3)欧式距离
点P和点Q之间的曼哈顿距离可以定义为:
$ d\left( {P{\rm{,}}Q} \right) = \sqrt {\sum\limits_{i = 1}^n {{{\left( {{x_i} - {y_i}} \right)}^2}} } $
在K均值算法中,选用欧式距离作为相似度的度量。
3、K均值算法原理
对于K均值算法,假设有m个样本$\left\{ {{X^{\left( 1 \right)}}{\rm{,}}{X^{\left( 2 \right)}}{\rm{,}} \cdots {\rm{,}}{X^{\left( m \right)}}} \right\}$,其中随机初始化k个聚类中心,通过每个样本与k个聚类中心之间的相似度,确定每个样本所属的类别,再通过每个类别中的样本重新计算每个类的聚类中心,重复这样的过程,直到聚类中心不再改变,最终确定每个样本所属的类别以及每个类的聚类中心。
K均值算法步骤:
- 初始化常数k,并随机初始化k个聚类中心;
- 重复计算以下过程,直到聚类中心不再改变;
- 计算每个样本与每个聚类中心之间的相似度,将样本划分到最相似的类别中;
- 计算划分到每个类别中的所有样本特征的均值,并将该均值作为每个类新的聚类中心。
- 输出最终的聚类中心以及每个样本所属的类别。
4、K均值算法Python实践


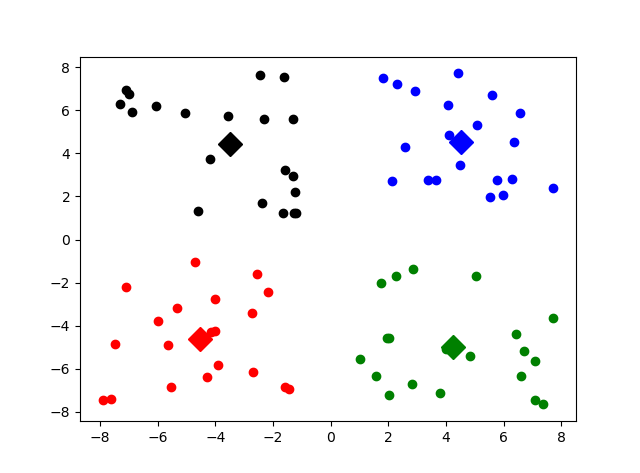
# coding:UTF-8 ''' Date:20160923 @author: zhaozhiyong ''' import numpy as np import matplotlib.pyplot as plt def load_data(file_path): '''导入数据 input: file_path(string):文件的存储位置 output: data(mat):数据 ''' f = open(file_path) data = [] for line in f.readlines(): row = [] # 记录每一行 lines = line.strip().split("\t") for x in lines: row.append(float(x)) # 将文本中的特征转换成浮点数 data.append(row) f.close() return np.mat(data) def distance(vecA, vecB): '''计算vecA与vecB之间的欧式距离的平方 input: vecA(mat)A点坐标 vecB(mat)B点坐标 output: dist[0, 0](float)A点与B点距离的平方 ''' dist = (vecA - vecB) * (vecA - vecB).T return dist[0, 0] def randCent(data, k): '''随机初始化聚类中心 input: data(mat):训练数据 k(int):类别个数 output: centroids(mat):聚类中心 ''' n = np.shape(data)[1] # 属性的个数 centroids = np.mat(np.zeros((k, n))) # 初始化k个聚类中心 for j in range(n): # 初始化聚类中心每一维的坐标 minJ = np.min(data[:, j]) rangeJ = np.max(data[:, j]) - minJ # 在最大值和最小值之间随机初始化 centroids[:, j] = minJ * np.mat(np.ones((k , 1))) \ + np.random.rand(k, 1) * rangeJ #计算公式:c = min + rand(0,1)*(max-min) return centroids def kmeans(data, k, centroids): '''根据KMeans算法求解聚类中心 input: data(mat):训练数据 k(int):类别个数 centroids(mat):随机初始化的聚类中心 output: centroids(mat):训练完成的聚类中心 subCenter(mat):每一个样本所属的类别(二维:类别、最小距离) ''' m, n = np.shape(data) # m:样本的个数,n:特征的维度 subCenter = np.mat(np.zeros((m, 2))) # 初始化每一个样本所属的类别 change = True # 判断是否需要重新计算聚类中心 while change == True: change = False # 重置 for i in range(m): minDist = np.inf # 设置样本与聚类中心之间的最小的距离,初始值为正无穷 minIndex = 0 # 所属的类别 for j in range(k): # 计算i和每个聚类中心之间的距离 dist = distance(data[i, ], centroids[j, ]) if dist < minDist: minDist = dist minIndex = j # 停止条件,判断是否需要改变 if (subCenter[i, 0] != minIndex): # 需要改变 change = True subCenter[i, ] = np.mat([minIndex, minDist]) # 重新计算聚类中心 for j in range(k): sum_all = np.mat(np.zeros((1, n))) r = 0 # 每个类别中的样本的个数 for i in range(m): if subCenter[i, 0] == j: # 计算第j个类别 sum_all += data[i, ] r += 1 for z in range(n): try: centroids[j, z] = sum_all[0, z] / r except: print (" r is zero") return centroids, subCenter def save_result(file_name, source): '''保存source中的结果到file_name文件中 input: file_name(string):文件名 source(mat):需要保存的数据 output: ''' m, n = np.shape(source) f = open(file_name, "w") for i in range(m): tmp = [] for j in range(n): tmp.append(str(source[i, j])) f.write("\t".join(tmp) + "\n") f.close() #作图 def show(dataSet, k, Centroids, clusterAssment): numSamples, dim = dataSet.shape mark = ['or', 'ob', 'og', 'ok', '^r', '+r', 'sr', 'dr', '<r', 'pr'] #作样本点 for i in range(numSamples): markIndex = int(clusterAssment[i, 0]) plt.plot(dataSet[i, 0], dataSet[i, 1], mark[markIndex]) mark = ['Dr', 'Db', 'Dg', 'Dk', '^b', '+b', 'sb', 'db', '<b', 'pb'] #作聚类中心 for i in range(k): plt.plot(Centroids[i, 0], Centroids[i, 1], mark[i], markersize = 12) plt.show() if __name__ == "__main__": k = 4 # 聚类中心的个数 file_path = "data.txt" # 1、导入数据 print ("---------- 1.load data ------------") data = load_data(file_path) # 2、随机初始化k个聚类中心 print ("---------- 2.random center ------------") centroids = randCent(data, k) # 3、聚类计算 print ("---------- 3.kmeans ------------") myCentroids,subCenter = kmeans(data, k, centroids) # 4、保存所属的类别文件 print ("---------- 4.save subCenter ------------") save_result("sub", subCenter) # 5、保存聚类中心 print ("---------- 5.save centroids ------------") save_result("center", myCentroids) #作图 show(data, k, myCentroids,subCenter)
参考文献
[1] 赵志勇. Python机器学习算法[M]. 北京:电子工业出版社,2017.
[2] 李航. 统计学习方法[M]. 北京:清华大学出版社,2012.
[3] 周志华. 机器学习[M]. 北京:清华大学出版社,2016.
附录
数据集下载:
链接:https://pan.baidu.com/s/1X5-mITS7SCRHqmtpYYtRnA
提取码:wrqp

 浙公网安备 33010602011771号
浙公网安备 33010602011771号