关联规则挖掘 Apriori
原创转载请注明出处:https://www.cnblogs.com/agilestyle/p/12987224.html
关联规则挖掘
关联规则挖掘可以让我们从数据集中发现项与项(item 与 item)之间的关系,它在我们的生活中有很多应用场景,“购物篮分析”就是一个常见的场景,这个场景可以从消费者交易记录中发掘商品与商品之间的关联关系,进而通过商品捆绑销售或者相关推荐的方式带来更多的销售量。所以说,关联规则挖掘是个非常有用的技术。
概念引入
举一个超市购物的例子,下面是几名客户购买的商品列表:
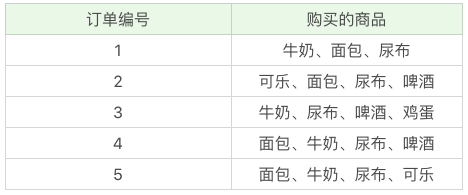
支持度
支持度是个百分比,它指的是某个商品组合出现的次数与总次数之间的比例。支持度越高,代表这个组合出现的频率越大。
e.g.
“牛奶”出现了 4 次,那么这 5 笔订单中“牛奶”的支持度就是 4/5=0.8。
“牛奶 + 面包”出现了 3 次,那么这 5 笔订单中“牛奶 + 面包”的支持度就是 3/5=0.6。
置信度
置信度是个条件概念,就是说在 A 发生的情况下,B 发生的概率是多少。它指的就是当你购买了商品 A,会有多大的概率购买商品 B。
e.g.
置信度(牛奶→啤酒) = 2/4 = 0.5,代表如果你购买了牛奶,有多大的概率会购买啤酒?在 4 次购买了牛奶的情况下,有 2 次购买了啤酒,所以置信度 (牛奶→啤酒) = 0.5
置信度(啤酒→牛奶) = 2/3 = 0.67,代表如果你购买了啤酒,有多大的概率会购买牛奶?在 3 次购买啤酒的情况下,有 2 次购买了牛奶,所以置信度 (啤酒→牛奶) = 0.67
提升度
提升度代表的是“商品 A 的出现,对商品 B 的出现概率提升的”程度。
e.g.
如果我们单纯看置信度 (可乐→尿布)=1,也就是说可乐出现的时候,用户都会购买尿布,那么当用户购买可乐的时候,我们就需要推荐尿布么?实际上,就算用户不购买可乐,也会直接购买尿布的,所以用户是否购买可乐,对尿布的提升作用并不大。
可以用下面的公式来计算商品 A 对商品 B 的提升度:
提升度 (A→B) = 置信度 (A→B) / 支持度 (B)
这个公式是用来衡量 A 出现的情况下,是否会对 B 出现的概率有所提升。
所以提升度有三种可能:
- 提升度 (A→B)>1:代表有提升;
- 提升度 (A→B)=1:代表有没有提升,也没有下降;
- 提升度 (A→B)<1:代表有下降。
Apriori 算法的工作原理
首先把上面案例中的商品用 ID 来代表,牛奶、面包、尿布、可乐、啤酒、鸡蛋的商品 ID 分别设置为 1-6,上面的数据表可以变为:
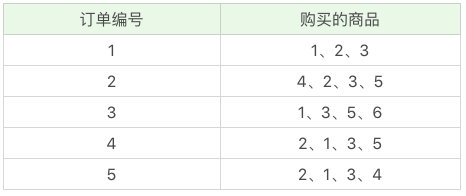
Apriori 算法其实就是查找频繁项集 (frequent itemset) 的过程。
项集:英文叫做 itemset,它可以是单个的商品,也可以是商品的组合。
频繁项集就是支持度大于等于最小支持度 (Min Support) 阈值的项集,所以小于最小值支持度的项目就是非频繁项集,而大于等于最小支持度的项集就是频繁项集。
假设这个例子随机指定最小支持度是 50%,也就是 0.5。
Apriori 算法是如何运算的:
首先,我们先计算单个商品的支持度,也就是得到 K=1 项的支持度: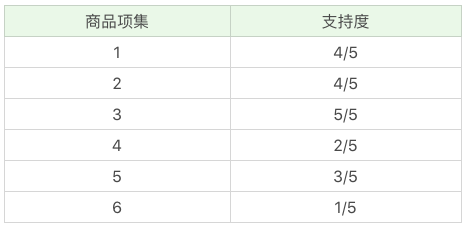
因为最小支持度是 0.5,所以你能看到商品 4、6 是不符合最小支持度的,不属于频繁项集,于是经过筛选商品的频繁项集就变成:
在这个基础上,我们将商品两两组合,得到 k=2 项的支持度: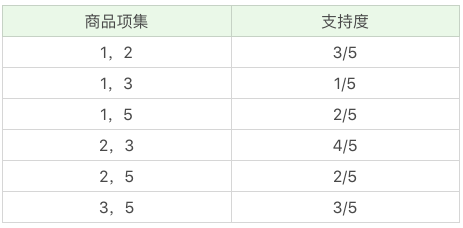
我们再筛掉小于最小值支持度的商品组合,可以得到: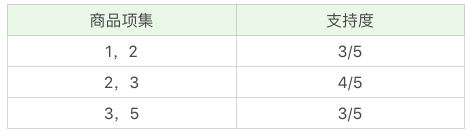
我们再将商品进行 K=3 项的商品组合,可以得到: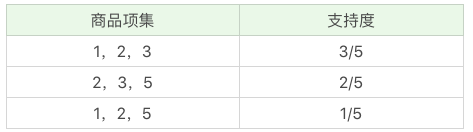
再筛掉小于最小值支持度的商品组合,可以得到:
通过上面这个过程,我们可以得到 K=3 项的频繁项集{1,2,3},也就是{牛奶、面包、尿布}的组合。
到这里,我们模拟了一遍整个 Apriori 算法的流程,总结下 Apriori 算法的递归流程:
- K=1,计算 K 项集的支持度;
- 筛选掉小于最小支持度的项集;
- 如果项集为空,则对应 K-1 项集的结果为最终结果,否则 K=K+1,重复 1-3 步。
Apriori 的改进算法:FP-Growth 算法
刚完成了 Apriori 算法的模拟,可以看到 Apriori 在计算的过程中有以下几个缺点:
- 可能产生大量的候选集。因为采用排列组合的方式,把可能的项集都组合出来了;
- 每次计算都需要重新扫描数据集,来计算每个项集的支持度。
所以 Apriori 算法会浪费很多计算空间和计算时间,为此人们提出了 FP-Growth 算法,它的特点是:
- 创建了一棵 FP 树来存储频繁项集。在创建前对不满足最小支持度的项进行删除,减少了存储空间。
- 整个生成过程只遍历数据集 2 次,大大减少了计算量。
所以在实际工作中,我们常用 FP-Growth 来做频繁项集的挖掘,下面简述下 FP-Growth 的原理。
创建项头表
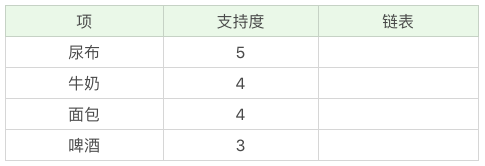
创建项头表的作用是为 FP 构建及频繁项集挖掘提供索引。
这一步的流程是先扫描一遍数据集,对于满足最小支持度的单个项(K=1 项集)按照支持度从高到低进行排序,这个过程中删除了不满足最小支持度的项。
项头表包括了项目、支持度,以及该项在 FP 树中的链表。初始的时候链表为空。
将数据集按照【尿布-牛奶-面包-啤酒】进行排序
- 尿布 牛奶 面包
- 尿布 面包 啤酒
- 尿布 牛奶 啤酒
- 尿布 牛奶 面包 啤酒
- 尿布 牛奶 面包
构造FP树
1)遍历第1条数据,得到
尿布1 |牛奶1 |面包1
2)遍历第2条数据,得到
尿布2 |面包1 |啤酒1
|牛奶1 |面包1
3)遍历第3条数据,得到
尿布3 |面包1 |啤酒1
|牛奶2 |面包1
|啤酒1
4)遍历第4条数据,得到
尿布4 |面包1 |啤酒1
|牛奶3 |面包2 |啤酒1
|啤酒1
5)遍历第5条数据,得到
尿布5 |面包1 |啤酒1
|牛奶4 |面包3 |啤酒1
|啤酒1
寻找条件模式基
“条件模式基”,它指的是以要挖掘的节点为叶子节点,自底向上求出 FP 子树,然后将 FP 子树的祖先节点设置为叶子节点之和。
以“啤酒”的节点为例,从 FP 树中可以得到一棵 FP 子树,将祖先节点的支持度记为叶子节点之和
1)以‘啤酒’为节点的链条有3条
- 尿布1 |面包1 |啤酒1
- 尿布1 |牛奶1 |面包1 |啤酒1
- 尿布1 |牛奶1 |啤酒1
2)FP子树
尿布3 |面包1 |啤酒1
|牛奶2 |面包1 |啤酒1
|啤酒1
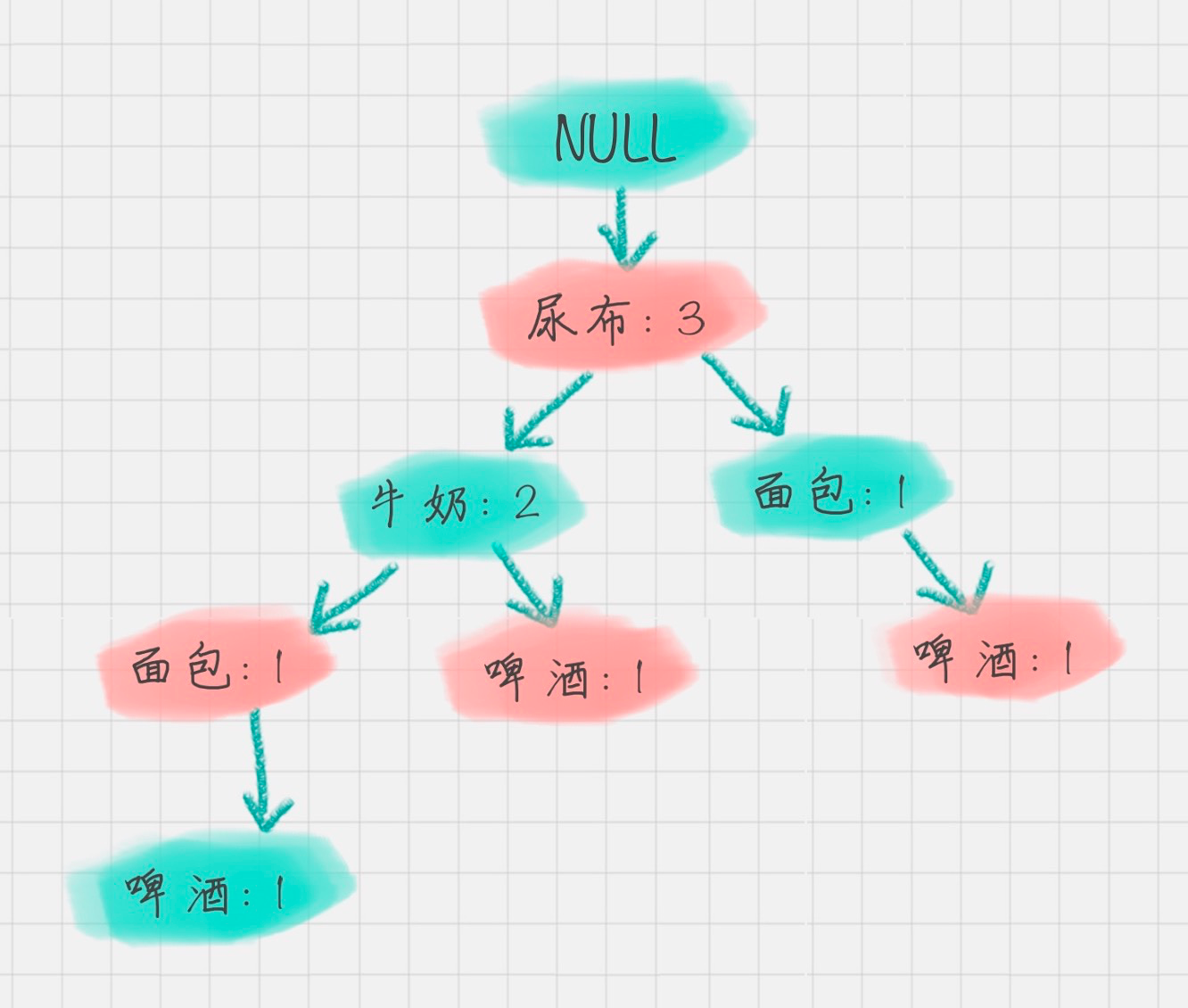
3)“啤酒”的条件模式基是取以‘啤酒’为节点的链条,取‘啤酒’往前的内容,即
- 尿布1 |面包1
- 尿布1 |牛奶1 |面包1
- 尿布1 |牛奶1
使用 efficient-apriori 进行关联规则挖掘
Apriori 虽然是十大算法之一,不过在 sklearn 工具包中并没有它,也没有 FP-Growth 算法。这里可以使用 efficient-apriori 进行关联规则挖掘。
from efficient_apriori import apriori data = [('牛奶', '面包', '尿布'), ('可乐', '面包', '尿布', '啤酒'), ('牛奶', '尿布', '啤酒', '鸡蛋'), ('面包', '牛奶', '尿布', '啤酒'), ('面包', '牛奶', '尿布', '可乐')] item_sets, rules = apriori(data, min_support=0.5, min_confidence=1) print(item_sets) print(rules)
Note:
- data 是要提供的数据集,它是一个 list 数组类型。
- min_support 参数为最小支持度,在 efficient-apriori 工具包中用 0 到 1 的数值代表百分比,比如 0.5 代表最小支持度为 50%。
- min_confidence 是最小置信度,数值也代表百分比,比如 1 代表 100%。
Console Output
{1: {('面包',): 4, ('尿布',): 5, ('牛奶',): 4, ('啤酒',): 3}, 2: {('尿布', '牛奶'): 4, ('尿布', '面包'): 4, ('牛奶', '面包'): 3, ('啤酒', '尿布'): 3}, 3: {('尿布', '牛奶', '面包'): 3}}
[{牛奶} -> {尿布}, {面包} -> {尿布}, {啤酒} -> {尿布}, {牛奶, 面包} -> {尿布}]
Reference
https://time.geekbang.org/column/article/82628
https://time.geekbang.org/column/article/82943
https://pypi.org/project/efficient-apriori/

 浙公网安备 33010602011771号
浙公网安备 33010602011771号