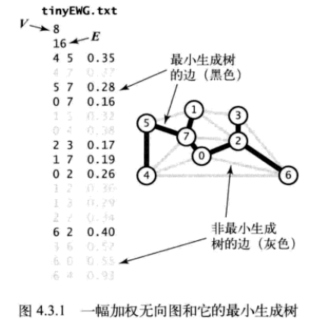
图 - 最小生成树
加权图是一种为每条边关联一个权值或是成本的图模型。这种图能够自然地表示许多应用。在一幅航空图中,边表示航线,权值则可以表示距离或是费用。在这些情形中,最令人感兴趣的自然是将成本最小化。这里用加权无向图模型来解决最小生成树:给定一幅加权无向图,找到它的一棵最小生成树。
图的生成树是它的一棵含有其所有顶点的无环连通子图。一幅加权图的最小生成树(MST)是它的一棵权值(树中所有边的权值之和)最小的生成树。
计算最小生成树的两种经典算法:Prim 算法和 Kruskal 算法。
1.原理
树的两个重要性质:
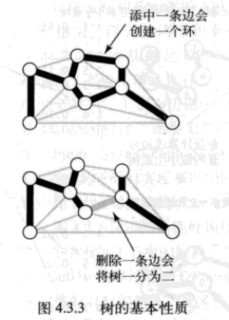
1.用一条边连接树中的任意两个顶点都会产生一个新的环;
2.从树中删除一条边将会得到两棵独立的树。
这两条性质是证明最小生成树的另一条基本性质的基础,而由这条基本性质就能够得到最小生成树的算法。
1.切分定理
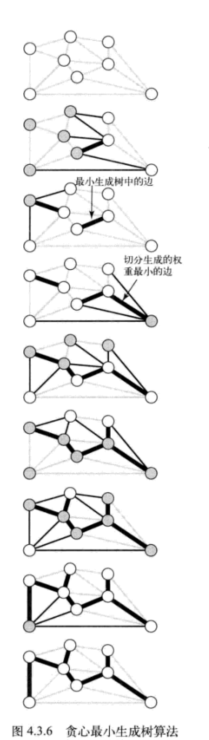
我们称之为切分定理的这条性质将会把加权图中的所有所有顶点分为两个集合,检查横跨两个集合的所有边并识别哪条边应属于图的最小生成树。
通常,我们指定一个顶点集并隐式地认为它地补集为另一个顶点集来指定一个切分。这样,一条横切边就是连接该集合地一个顶点和不在该集合地另一个顶点地一条边。
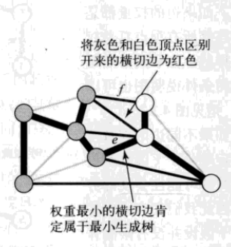
切分定理:在一幅加权图中,给定任意得切分,它的横切边中权重最小者必然属于图的最小生成树。
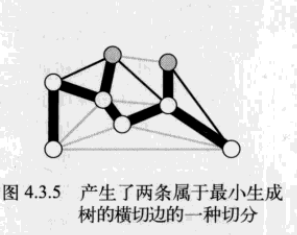
注意,权重最小的横切边并不一定是所有横切边中唯一属于图的最小生成树的边。实际上,许多切分都会产生若干条属于最小生成树的横切边:
2.贪心算法
切分定理是解决最小生成树问题的所有算法的基础。更确切的说,这些算法都是一种贪心算法的特殊情况:使用切分定理找到最小生成树的一条边,不断重复直到找到最小生成树的所有便。这些算法之间的不同之处在于保存切分和判定权重最小的横切边的方式,但它们都是一下性质特殊情况:
最小生成树的贪心算法:下面这种算法会将含有 V 个顶点的任意加权连通图中属于最小生成树的边标记为黑色:初始状态下所有边均为灰色,找到一种切分,它产生的横切边均不为黑色。将它权重最小的横切边标记为黑色。反复,直到标记了 V - 1 条黑色边为止。
2.加权无向图的数据类型

namespace MinimumSpanningTrees { public class Edge:IComparable<Edge> { private int v;//顶点之一 private int w;//另一个顶点 private double weight;//边的权重 public Edge(int v, int w, double weight) { this.v = v; this.w = w; this.weight = weight; } public double Weight() { return weight; } public int Either() { return v; } public int Other(int vertex) { if (vertex == v) return w; else if (vertex == w) return v; else throw new ArgumentException(); } public int CompareTo([AllowNull] Edge other) { if (this.Weight() < other.Weight()) return -1; else if (this.Weight() > other.Weight()) return 1; else return 0; } public override string ToString() { return string.Format("%d-%d %.2f",v,w,weight); } } }
加权无向图的实现使用了 Edge 对象。

namespace MinimumSpanningTrees { public class EdgeWeightedGraph { private int v;//顶点总数 private int e;//边的总数 private List<Edge>[] adj;//邻接表 public EdgeWeightedGraph(int V) { this.v = V; e = 0; adj = new List<Edge>[V]; for (int _v = 0; _v < V; _v++) { adj[_v] = new List<Edge>(); } } public int V() { return v; } public int E() { return e; } public void AddEdge(Edge edge) { int v = edge.Either(); int w = edge.Other(v); adj[v].Add(edge); adj[w].Add(edge); e++; } public IEnumerable<Edge> Adj(int _v) { return adj[_v]; } } }
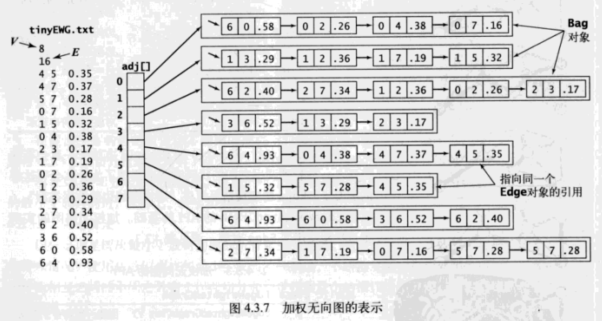
为了整洁,用一对 int 值和一个 double 值表示每个 Edge 对象。实际的数据结构是一个链表,其中每个元素都是一个指向含有这些值的对象的指针。需要注意的是,虽然每个Edge对象都有两个引用,但图中的每条边所对应的 Edge 对象只有一个。
用权重来比较边
Edge 类实现了 IComparable 接口的 CompareTo 方法。一幅加权无向图中的边的自然次序就是按权重排序。
平行边
和无环图的实现一样,这里也允许存在平行边。我们也可以用更复杂的方法来消除平行边,比如保留平行边中权重最小者。
自环
允许存在自环,这对最小生成树算法没有影响,因为最小生成树肯定不会含有自环。
有个 Edge 对象之后用例的代码就可以变得更加干净整洁。这也有小的代价:每个邻接表的结点都是一个都是一个指向 Edge 对象的引用,它们含有一些冗余的信息, v 的邻接链表中的每个结点都会用一个变量保存 v 。使用对象也会带来一些开销。虽然每条边的 Edge 对象都只有一个,但邻接表中还是会含有两个指向同一 Edge 对象的引用。
另一种广泛使用的方案是与 Graph 一样,用两个结点对象表示一条边,每个结点对象都会保存顶点的信息和边的权重。这种方法也是有代价的 -- 需要两个结点,每条边的权重都会被保存两次。
3.最小生成树 API
按照惯例,在 API 中会定义一个接受加权无向图为参数的构造函数并且支持能够为用例返回图的最小生成树和其权重的方法。那么应该如何表示最小生成树?由于图的最小生成树是图的一幅子图并且同时也是一棵树,因此可以有一下选择:
1.一组边的列表;
2.一幅加权无向图;
3.一个以顶点为索引且含有父结点链接的数组。
在为了各种应用选择这些表示方法时,我们希望尽可能给予最小生成树的实现以最大的灵活性,采用如下 API :

4.Prim 算法
Prim 算法,它的每一步都会为一棵生长中的树添加一条边。一开始这棵树只有一个顶点,然后会向它添加 V-1 条边,每次总是将下一条连接树中的顶点与不在树中的顶点且权重最小的边加入树中。
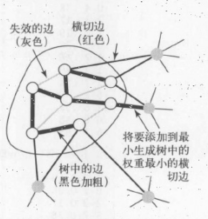
Prim 算法能够得到任意加权连通图的最小生成树。这棵不断生长的树定义了一个切分且不存在树中的横切边。该算法会选择权重最小的横切边并根据贪心算法不断将他们标记。
数据结构
实现 Prim 算法需要一些简单常见的数据结构。具体来说,我们会用一下方法表示树中的顶点,边和横切边:
1.顶点:使用一个由顶点索引的布尔数组 marked[ ] ,如果顶点 v 在树中,那么 marked[v] 的值为 true。
2.边:选择以下两种数据结构之一:一条队列 mst 来保存最小生成树中的边,或者一个由顶点索引的Edge对象的数组 edgeTo[ ] ,其中 edgeTo[ v ] 为将 v 连接到树中的 Edge 对象;
3.横切边:使用一条优先队列 MinPQ<Edge> 来根据权重比较所有边。
有了这些数据结构就可以回答 “哪条边的权重最小” 这个基本问题了。
维护横切边的集合
每当我们向树中添加了一条边后,也向树中添加一个顶点。要维护一个包含所有横切边的集合,就要将连接这个顶点(新加入树)和其他所有不在树中的顶点的边加入优先队列。但还有一点:连接新加入树中的顶点和其他已经在树中的顶点的所有边都要失效(这样的边已经不是横切边了,因为它的两个顶点都在树中)。Prim 算法的即时实现可以将这样的边从优先队列中删掉,先来看一种延时实现,将这些边先留在优先队列中,等到要删除它们的时候再检查边的有效性。
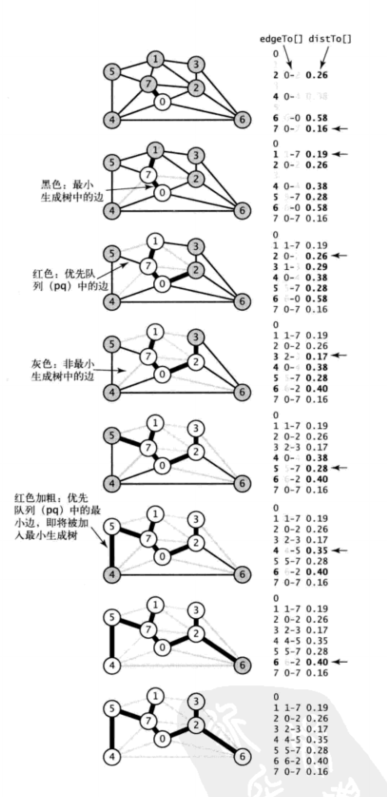
算法构造最小生成树的过程:
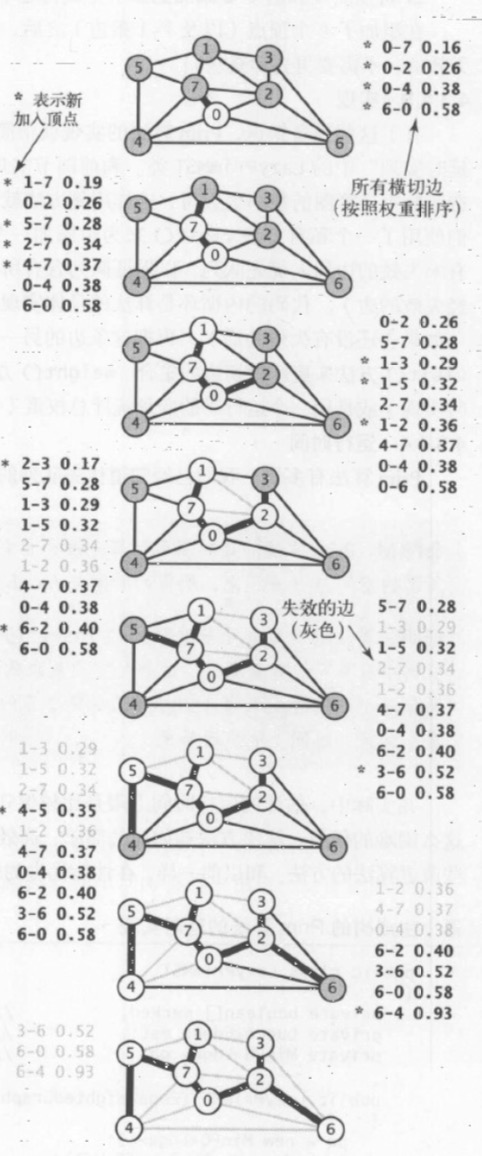
1.将顶点 0 添加到最小生成树,将它的邻接链表中的所有边添加到优先队列中。
2.取权重最小的边 0-7,将顶点 7 和 边 0-7 添加到最小生成树中,将顶点 7 的邻接链表中的所有边添加到优先队列中。
3.将顶点 1 和边 1-7 添加到最小生成树中,将顶点的邻接链表中的所有边添加到优先队列中。
4.将顶点 2 和边 0-2 添加到最小生成树,将边 2-3 和 6-2 添加到优先队列。边 2-7 和 1-2 失效(因为边的两个顶点都在树中,最后删除)。
5.将顶点 3 和边 2-3 添加到最小生成树,将边 3-6 添加到优先队列。边 1-3 失效。
6.将顶点 5 和边 5-7 添加到最小生成树,将边 4-5 添加到优先队列。边 1-5 失效。
7.从优先队列删除失效的边 1-3,1-5 和 2-7 。
8.将顶点 4 和边 4-5 添加到最小生成树中,将边 6-4 添加到优先队列。边 4-7 和 0-4 失效。
9.从优先队列删除失效的边 1-2,4-7 和 0-4 。
10.将顶点 6 和边 6-2 添加到最小生成树中,和顶点 6 相关联的其他边均失效。
在添加了 V 个顶点以及 V-1 条边之后,最小生成树就完成了。优先队列中剩下的边都是无效的,可以不用去检查。
实现
我们使用一个私有方法 Visit()来为树添加一个顶点,将它标记为“已访问”并将与它关联的所有未失效的边加入优先队列,以保证队列含有所有连接树顶点和非树顶点的边(也可能含有一些已失效的边)。代码的内循环是算法的具体实现:从优先队列中取出一条边并将它添加到树中(如果没有失效),再把这条边的另一个顶点也添加到树中,然后用新顶点作为参数调用 Visit 方法来更新横切边的集合。 Weight 方法可以遍历树的所有边并得到权重之和。
namespace MinimumSpanningTrees { public class LazyPrimMST { private bool[] marked;//最小生成树的顶点 private Queue<Edge> mst;//最小生成树的边 private MinPQ<Edge> pq;//横切边(包括失效的边) public LazyPrimMST(EdgeWeightedGraph G) { pq = new MinPQ<Edge>(); marked = new bool[G.V()]; mst = new Queue<Edge>(); Visit(G,0); while (!pq.Count > 0) { Edge e = pq.Dequeue(); int v = e.Either(); int w = e.Other(v); if (marked[v] && marked[w]) continue; pq.Enqueue(e); if (!marked[v]) Visit(G,v); if (!marked[w]) Visit(G,w); } } private void Visit(EdgeWeightedGraph G, int v) { marked[v] = true; foreach (Edge e in G.Adj(v)) { if (!marked[e.Other(v)]) pq.Enqueue(e); } } public IEnumerable<Edge> Edges() { return mst; } public double Weight() { return mst.Sum(o=>o.Weight()); } } }
性能
Prim 算法的延时实现计算一幅含有 V 个顶点和 E 条边的连通加权无向图的最小生成树所需的空间和 E 成正比,所需的时间与 ElogE成正比(最坏情况)。算法的瓶颈在于优先队列的删除和添加方法中比较边的权重的次数。优先队列最多可能含有 E 条边,这就是空间需求的上限。在最坏情况下,一次插入成本为 ~lgE ,删除最小元素的成本为 ~2lgE 。因为最多只能插入 E 条边,删除 E 次最小元素,时间上限显而易见。
5. Prim 算法的即时实现
要改进 LazyPrimMST ,可以尝试从优先队列中删除失效的边,这样优先队列就只有树顶点和非树顶点之间的横切边,但还可以删除更多的边。关键在于,我们感兴趣的只是连接树顶点和非树顶点中权重最小的边。当我们将顶点 v 添加到树中,对于每个非树顶点 w 产生的变化只可能使得 w 到最小生成树的距离更近。简而言之,我们不需要在优先队列中保存所有从 w 到树顶点的边 —— 而只需保存其中权重最小的那条。在将 v 添加到树中后检查是否需要更新这条权重最小的边(因为 v-w 的权重可能更小)。我们只需遍历 v 的邻接链表就可以完成这个任务。换句话说,我们只会在优先队列中保存每个非树顶点 w 的一条边:将它与树中顶点连起来的权重最小的那条边。将 w 和树的顶点连接起来的其他权重较大的边迟早都会失效,所以没必要在优先队列中保存他们。
算法类 PrimMST 将 LazyPrimMST 类中 marked[ ] 和 mst[ ] 替换为两个顶点索引的数组 edgeTo[ ] 和 distTo[ ] :
1.如果顶点 v 不在树中但至少含有一条边和树相连,那么 edgeTo[v] 是将 v 和树连接的最短边,distTo[v] 为这条边的权重。
2.所有这类顶点 v 都保存在一条索引优先队列中,索引 v 关联的值是 edgeTo[v] 的边的权重。
这些性质的关键在于优先队列中的最小键即是权重最小的横切边的权重,而和它相关联的顶点 v 就是下一个将被添加到树中的顶点。marked[ ] 数组已经没有必要了,因为判断条件 !marked[w] 等价于 distTo[w] 是无穷的(且 edgeTo[w] 为 null)。要维护这些数据结构,PrimMST 会从优先队列中取出一条边并检查它的邻接链表中的每条边 v-w 。如果 w 已经被标记过,那这条边就已经失效了;如果 w 不在优先队列中或者 v-w 的权重小于目前已知的最小值 edgeTo[w],代码会更新数组,将 v-w 作为将 w 和树连接的最佳选择。
namespace MinimumSpanningTrees { public class PrimMST { private Edge[] edgeTo;//距离树最近的边 private double[] distTo;//distTo[w]=edgeTo[w].weight() private bool[] marked;//如果 v 在树中则为 true public IndexMinPQ<double> pq;//有效的横切边 public PrimMST(EdgeWeightedGraph G) { edgeTo = new Edge[G.V()]; distTo = new double[G.V()]; marked = new bool[G.V()]; for (int v = 0; v < G.V(); v++) { distTo[v] = Double.MaxValue; } pq = new IndexMinPQ<double>(G.V()); distTo[0] = 0.0; pq.Insert(0,0.0); //用顶点 0 和权重 0 初始化 pq while (pq.Count > 0) { Visit(G,pq.DelMin());//将最近的顶点添加到树中 } } private void Visit(EdgeWeightedGraph G, int v) { //将顶点 v 添加到树中,更新数据 marked[v] = true; foreach (Edge e in G.Adj(v)) { int w = e.Other(v); if (marked[w]) continue; if (e.Weight() < distTo[w]) { edgeTo[w] = e; distTo[w] = e.Weight(); if (pq.Contains(w)) pq.Change(w, distTo[w]); else pq.Insert(w,distTo[w]); } } } } }
Prim 算法的即时实现计算一幅含有 V 个顶点和 E 条边的连通加权无向图的最小生成树所需的空间和 V 成正比,所需的时间与 ElogV成正比(最坏情况)。
6.Kruskal 算法
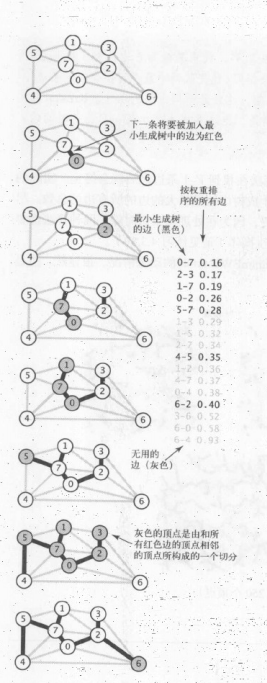
第二种生成最小生成树的主要思想是按照边的权重顺序(从小到大)处理它们,将边加入最小生成树中,加入的边不会与已经加入的边构成环,直到树中含有 V-1 条边为止。这些边逐渐由一片森林合共成一棵树。
为什么 Kruskal 算法能够计算任意加权连通图的最小生成树?
如果下一条将被加入最小生成树中的边不会和已有的边构成环,那么它就跨越了由所有和树顶点相邻的顶点组合的合集以及它们的补集所构成的一个切分。因为加入的边不会形成环,它是目前已知的唯一一条横切边且是按照权重顺序选择的边,所以它必然是权重最小的横切边。因此,该算法能够连续选择权重最小的横切边,和贪心算法一致。
Prim 算法是一条边一条边地来构造最小生成树,每一步都为一棵树添加一条边。 Kruskal 算法构造最小生成树地时候也是一条边一条边地构造,但不同的是它寻找的边会连接一片森林中的两棵树。我们从一片由 V 棵单顶点的树构成的森林开始并不断将两棵树合并(用可以找到的最短边)直到只剩下一棵树,它就是最小生成树。
实现
我们将会使用一条优先队列来将边按照权重排序,用一个 union-find 数据结构来识别会形成环的边,以及一条队列来保存最小生成树的所有边。
public class KruskalMST { private Queue<Edge> mst; public KruskalMST(EdgeWeightedGraph G) { mst = new Queue<Edge>();//最小生成树的边 MinPQ<Edge> pq = new MinPQ<Edge>(G.Edges);//所有边 UF uf = new UF(G.V()); while (!pq.IsEmpty() && mst.Count < G.V() - 1) { Edge e = pq.DelMin();//从 pq 得到权重最小的边和它的顶点 int v = e.Either(), w = e.Other(v); if (uf.Connected(v, w))//忽略失效的边 continue; uf.Union(v,w);//合并分量 mst.Enqueue(e);//将边添加到最小生成树中 } } }
Kruskal 算法的计算一幅含有 V 个顶点和 E 条边的连通加权无向图的最小生成树所需的空间和 E 成正比,所需的时间和 ElogE 成正比(最坏情况)。
算法的实现在构造函数中使用所有边初始化优先队列,成本最多为 E 次比较(请见 union-find)。优先队列构造完成后,其余的部分和 Prim 算法完全相同。优先队列中最多可能含有 E 条边,即所需空间的上限。每次操作的成本最多为 2lgE 次比较,这就是时间上限的由来。 Kruskal 算法最多还会进行 E 次 Connected() 和 V 次 Union()操作,但这些成本相比 ElogE 的总时间的增长数量级可以忽略不计。
与 Prim 算法一样,这个估计是比较保守的,因为算法在找到 V-1 条边之后就会终止。实际成本应该与 E+E0 logE 成正比,其中 E0 是权重小于最小生成树中权重最大的边的所有边的总数。尽管拥有这个优势,Kruskal 算法一般还是比 Prim 算法要慢,因为在处理每条边时,两种方法都要完成优先队列操作之外,它还需要进行一次 Connect() 操作。



 浙公网安备 33010602011771号
浙公网安备 33010602011771号