
# URL异常检测
(Isolation Forest无监督)这个算法是随机森林的推广。
iTree树构造:随机选一个属性,再随机选该特征的一个值,对样本进行二叉划分,重复以上操作。
iTree构建好了后,就可以对数据进行预测啦,预测的过程就是把测试记录在iTree上走一下,看测试记录落在哪个叶子节点。iTree能有效检测异常的假设是:异常点一般都是非常稀有的,在iTree中会很快被划分到叶子节点,因此可以用叶子节点到根节点的路径h(x)长度来判断一条记录x是否是异常点。
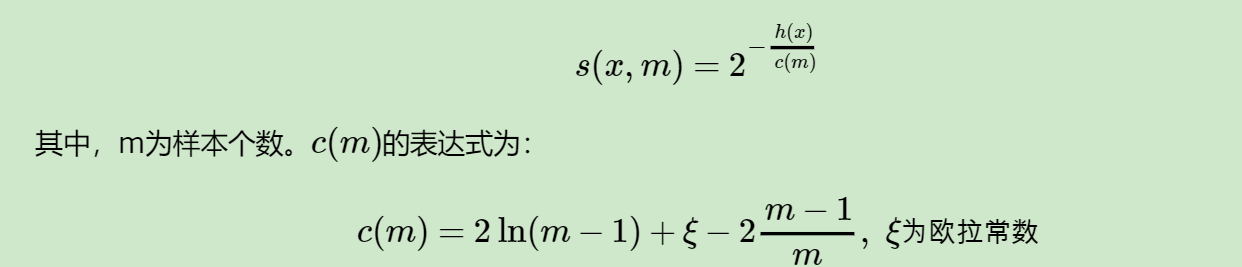
越接近1表示是异常点的可能性高;
越接近0表示是正常点的可能性比较高;
如果大部分的训练样本的s(x,n)都接近于0.5,整个数据没有明显的异常。
Iforest构造:随机采样抽取一部分数据构造每一棵树,保证树的差异性。
与随机森林的区别:
1、随机森林需要采样集样本个数等于训练集个数,IForest也是随机采样,但样本个数小于训练集个数。因为我们的目的是异常点检测,只需要部分的样本我们一般就可以将异常点区别出来了
2、IForest采用随机选择一个划分特征,对划分特征随机选择一个划分阈值,RF划分需要使用信息增益或者信息增益率作为选择属性和阈值的依据。
URL异常检测(IForest)
数据源在这里。
正常请求的数据
/103886/
/rcanimal/
/458010b88d9ce/
/cclogovs/
/using-localization/
/121006_dakotacwpressconf/
恶意请求的数据
/top.php?stuff='uname >q36497765 #
/h21y8w52.nsf?
/ca000001.pl?action=showcart&hop=">&path=acatalog/
/scripts/edit_image.php?dn=1&userfile=/etc/passwd&userfile_name= ;id;
这里就需要有文本向量化的知识,调用sklearn中CountVectorizer
from sklearn.feature_extraction.text import CountVectorizer
vectorizer=CountVectorizer()
corpus=["I come to China to travel",
"This is a car polupar in China",
"I love tea and Apple ",
"The work is to write some papers in science"]
print(vectorizer.fit_transform(corpus))
'''文本的序号,词的序号,词频'''
(0, 16) 1
(0, 3) 1
(0, 15) 2
print(vectorizer.get_feature_names())#I是停用词不统计,打印分割好的词向量
['and', 'apple', 'car', 'china', 'come', 'in', 'is', 'love', 'papers', 'polupar', 'science', 'some', 'tea', 'the', 'this', 'to', 'travel', 'work', 'write']
print(vectorizer.fit_transform(corpus).toarray()) //转换成矩阵打印,四行代表四句话,列上的数字代表出现频率,统计词频后的19维特征做为文本分类的输入
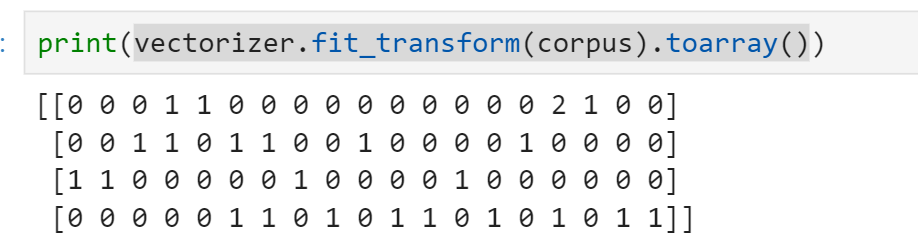
TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。
TF(Term Frequency)词频,某个词在文章中出现的次数或频率。
IDF(inverse document frequency)逆文档频率。一个词语“权重”的度量,一个词越常见,IDF越低。
IDF计算公式:
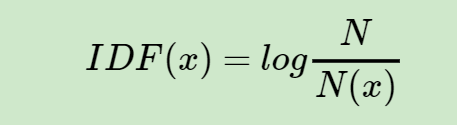
N代表语料库中文本的总数,而N(x)代表语料库中包含词x的文本总数,有对应的词库
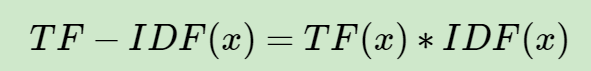
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer
corpus=["I come to China to travel",
"This is a car polupar in China",
"I love tea and Apple ",
"The work is to write some papers in science"]
vectorizer=CountVectorizer()
transformer = TfidfTransformer()
tfidf = transformer.fit_transform(vectorizer.fit_transform(corpus))
print(tfidf)
得到(文本的序号,词的序号,TF-IDF值)
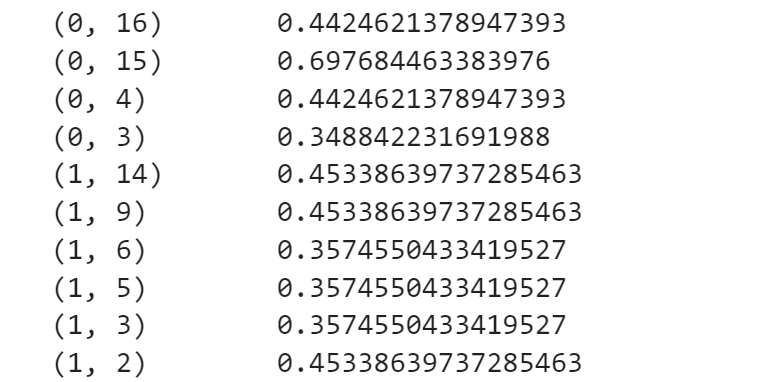
这块知识的相关参考文章:
https://www.cnblogs.com/pinard/p/6693230.html
https://www.cnblogs.com/pinard/p/6693230.html
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.ensemble import IsolationForest
from sklearn.metrics import confusion_matrix
import itertools
from sklearn.metrics import accuracy_score
#data
good_data=pd.read_csv('goodqueries.txt',names=['url'])
good_data['label']=0
data=good_data
data.head()
##feature
vectorizer = TfidfVectorizer(min_df = 0.0, analyzer="char", sublinear_tf=True, ngram_range=(1,3)) #converting data to vectors
X = vectorizer.fit_transform(data['url'].values.astype('U')) #TF-IDF向量化

分为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, data['label'].values, test_size=0.2, random_state=42) #splitting data
print(X_train) #y_test标签都设置为0表示都是正常数据集
clf=IsolationForest()
clf.fit(X_train)
y_pre = clf.predict(X_test)
ny_pre = np.asarray(y_pre)
ny_pre[ny_pre==1] = 0 ##最后输出1为正常,-1为异常 ==>0是正常,1是异常点
ny_pre[ny_pre==-1] = 1
ny_test = np.asarray(y_test) #y_test都是0因为只导入了goodqueries.txt数据集
accuracy_score(ny_test,ny_pre)

URL异常检测(LSTM)
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2019/6/4 9:25
# @Author : afanti
import sys
import os
import json
import pandas as pd
import numpy
import optparse
from keras.callbacks import TensorBoard
from keras.models import Sequential
from keras.layers import LSTM, Dense, Dropout
from keras.layers.embeddings import Embedding
from keras.preprocessing import sequence
from keras.preprocessing.text import Tokenizer
from collections import OrderedDict
from keras.models import load_model
from keras.models import model_from_json
def model():
dataframe = pd.read_csv('goodqueries.txt', names=['url'])
dataframe['label']=0
# dataframe.head()
dataframe1 = pd.read_csv('badqueries.txt', names=['url'])
dataframe1['label']=1
# dataframe1.head()
dataset=pd.concat([dataframe,dataframe1])
dataset=dataset.sample(frac=1).values
X = dataset[:,0]
Y = dataset[:,1]
for i in range(len(X)):
if type(X[i])==float:
X[i]=str(X[i])
tokenizer = Tokenizer(filters='\t\n', char_level=True)
tokenizer.fit_on_texts(X)
X = tokenizer.texts_to_sequences(X) #序列的列表,列表中每个序列对应于一段输入文本
word_dict_file = 'build/word-dictionary.json'
if not os.path.exists(os.path.dirname(word_dict_file)):
os.makedirs(os.path.dirname(word_dict_file))
with open(word_dict_file, 'w',encoding='utf-8') as outfile:
json.dump(tokenizer.word_index, outfile, ensure_ascii=False) #将单词(字符串)映射为它们的排名或者索引
num_words = len(tokenizer.word_index)+1 #174
max_log_length = 100
train_size = int(len(dataset) * .75)
# padding
X_processed = sequence.pad_sequences(X, maxlen=max_log_length)
# 划分样本集
X_train, X_test = X_processed[0:train_size], X_processed[train_size:len(X_processed)]
Y_train, Y_test = Y[0:train_size], Y[train_size:len(Y)]
model = Sequential()
model.add(Embedding(num_words, 32, input_length=max_log_length))
model.add(Dropout(0.5))
model.add(LSTM(64, recurrent_dropout=0.5))
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
model.summary()
model.fit(X_train, Y_train, validation_split=0.25, epochs=3, batch_size=128)
# Evaluate model
score, acc = model.evaluate(X_test, Y_test, verbose=1, batch_size=128)
print("Model Accuracy: {:0.2f}%".format(acc * 100))
# Save model
model.save_weights('securitai-lstm-weights.h5')
model.save('securitai-lstm-model.h5')
with open('securitai-lstm-model.json', 'w') as outfile:
outfile.write(model.to_json())
df_black = pd.read_csv('badqueries.txt', names=['url'], nrows=20000)
df_black['label'] = 1
X_waf = df_black['url'].values.astype('str')
Y_waf = df_black['label'].values.astype('str')
X_sequences = tokenizer.texts_to_sequences(X_waf)
X_processed = sequence.pad_sequences(X_sequences, maxlen=max_log_length)
score, acc = model.evaluate(X_processed, Y_waf, verbose=1, batch_size=128)
print("Model Accuracy: {:0.2f}%".format(acc * 100))
这里用到了keras的Tokenizer分词器
from keras.preprocessing.text import Tokenizer
import keras
tokenizer = Tokenizer(char_level=True)
text = ["/javascript/nets.png", "/javascript/legacy.swf"]
tokenizer.fit_on_texts(text)
# tokenizer.word_counts #[[2, 5]] False
tokenizer.texts_to_sequences(["nets swf"])
tokenizer.word_index
当char_level=True时,会按char-level将字符频度进行统计,如下图a出现次数最多,

输出结果,nets swf输出在上面图查找:
#[[11, 12, 6, 3, 3, 17, 18]] True 语义没了
输入数据做了padding操作,这里补成了128维
# padding
X_processed = sequence.pad_sequences(X, maxlen=max_log_length)

相关Tokenizer操作看这里:
https://blog.csdn.net/wcy23580/article/details/84885734
https://blog.csdn.net/wcy23580/article/details/84957471
训练模型前Embedding层做一次word embedding,单词嵌入是使用密集的矢量表示来表示单词和文档的一类方法。output_dim这是嵌入单词的向量空间的大小,input_dim这是文本数据中词汇的取值可能数这里是173,input_length:输入文档都由1000个字组成,那么input_length就是1000.
下面我们定义一个词汇表为173的嵌入层(例如从1到173的整数编码的字,包括1到173),一个32维的向量空间,其中将嵌入单词,以及输入文档,每个单词有128个字符
嵌入层自带学习的权重,如果将模型保存到文件中,则将包含嵌入图层的权重。
model = Sequential()
model.add(Embedding(input_dim=num_words, output_dim=32, input_length=max_log_length))
model.add(Dropout(0.5))
model.add(LSTM(64, recurrent_dropout=0.5))
model.add(Dropout(0.5))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
总的来说就是char-level+统计向量化+词嵌入+神经网络LSTM
相关参考在这里:https://juejin.im/entry/5acc23f26fb9a028d1416bb3
URL异常检测(LR)
导入数据
# -*- coding:utf8 -*-
from sklearn.externals import joblib
from sklearn.feature_extraction.text import TfidfVectorizer
import os
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn import metrics
import urllib.parse
from sklearn.pipeline import Pipeline
import matplotlib.pyplot as plt
def loadFile(name):
directory = str(os.getcwd())
filepath = os.path.join(directory, name)
with open(filepath,'r',encoding="utf8") as f:
data = f.readlines()
data = list(set(data))
result = []
for d in data:
d = str(urllib.parse.unquote(d)) #converting url encoded data to simple string
result.append(d)
return result
badQueries = loadFile('badqueries.txt')
validQueries = loadFile('goodqueries.txt')
badQueries = list(set(badQueries))
validQueries = list(set(validQueries))
allQueries = badQueries + validQueries
yBad = [1 for i in range(0, len(badQueries))] #labels, 1 for malicious and 0 for clean
yGood = [0 for i in range(0, len(validQueries))]
y = yBad + yGood
queries = allQueries
划分测试集训练集
X_train, X_test, y_train, y_test = train_test_split(queries, y, test_size=0.2, random_state=42) #splitting data
badCount = len(badQueries) #44532
validCount = len(validQueries) #1265974
Pipeline可以将许多算法模型串联起来,比如将特征提取、归一化、分类组织在一起形成一个典型的机器学习问题工作流。
tfidf TfidfVectorizer类参数analyzer定义特征为词(word)或n-gram字符。
sublinear_tf 应用线性缩放TF,例如,使用1+log(tf)覆盖tf。
ngram_range要提取的n-gram的n-values的下限和上限范围class_weight={0:0.9, 1:0.1},这样类型0的权重为90%,而类型1的权重为10%。
pipe_lr = Pipeline([('tfidf', TfidfVectorizer(min_df = 0.0, analyzer="char", sublinear_tf=True, ngram_range=(1,3))),
('clf', LogisticRegression(class_weight="balanced"))
])
pipe_lr.fit(X_train, y_train)
predicted = pipe_lr.predict(X_test)
predicted=list(predicted)
fpr, tpr, _ = metrics.roc_curve(y_test, (pipe_lr.predict_proba(X_test)[:, 1]))
auc = metrics.auc(fpr, tpr)
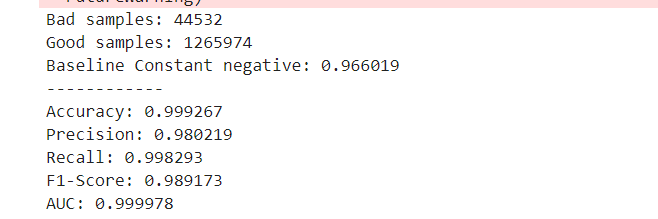
print("Bad samples: %d" % badCount)
print("Good samples: %d" % validCount)
print("Baseline Constant negative: %.6f" % (validCount / (validCount + badCount)))
print("------------")
print("Accuracy: %f" % pipe_lr.score(X_test, y_test)) #checking the accuracy
print("Precision: %f" % metrics.precision_score(y_test, predicted))
print("Recall: %f" % metrics.recall_score(y_test, predicted))
print("F1-Score: %f" % metrics.f1_score(y_test, predicted))
print("AUC: %f" % auc)
joblib.dump(pipe_lr,"lr.pkl")
测试
from urllib.parse import urlparse
from sklearn.externals import joblib
lr=joblib.load("lr.pkl")
def url(url):
try:
parsed_url=urlparse(url)
paths=parsed_url.path+parsed_url.query
result=lr.predict([paths])
if result==[0]:
return False
else:
return True
except Exception as err:
#print(str(err))
pass
result=url('http://br-ofertasimperdiveis.epizy.com/examples/jsp/cal/feedsplitter.php?format=../../../../../../../../../../etc/passwd\x00&debug=1')
result1=url('http://br-ofertasimperdiveis.epizy.com/produto.php?linkcompleto=iphone-6-plus-apple-64gb-cinza')
result2=url('http://br-ofertasimperdiveis.epizy.com/?q=select * from x')

char-level/word-level+n-gram+tfidf一把梭下来,可以解决很多问题了,包括较长文本和短文本,而安全中的很多关键信息都可以看成是长文本和短文本,比如域名请求,恶意代码,恶意文件。
https://www.freebuf.com/articles/network/131279.html
https://github.com/exp-db/AI-Driven-WAF/blob/master/waf.py
https://www.kdnuggets.com/2017/02/machine-learning-driven-firewall.html
N-Gram模型理解
总参考连接:
https://xz.aliyun.com/t/5288#toc-4

 浙公网安备 33010602011771号
浙公网安备 33010602011771号