OO第三单元总结
- 实现规格所采取的策略
- 属性部分
最开始的时候是死板地按着规格来“翻译”,规格中数据类型为数组的属性在实现时还真的采用了数组来实现。最后由于数组使用起来实在太过于繁琐,不得不采用Arraylist来实现;当然随着理论课对规格的进一步介绍,对规格的理解越来越灵活,只要具备规格中所描述的特征,如数组的线性即可采用其他很多的数据结构,以使得自己的程序具备良好的性能。 - 方法部分
类似于属性部分,在前两次作业中对方法中规格的翻译显得有点笨拙,例如queryBlockSum中的双重循环,我就老老实实地照着写了两重循环,当然,最后在强测的时候自然惨不忍睹。最后领悟到的是只要满足规格中定义的副作用、后置条件等其期望我们实现的功能和影响,那么可以“不择手段”地去实现。因此最后我会根据我属性的数据结构以及算法的需要来实现方法,必要的话,还可以自己增添函数,比如第三次作业中的findRoot、dijis等函数。 - 总体策略
先易后难。先把属性的规格实现好,再把规格长度较短、对算法要求不高的方法先完成,如此一来在实现的过程中就可以熟悉大多数方法的规格,了解这些方法的功用,为较复杂方法的实现奠定基础。
- 属性部分
- 基于JML规格来设计测试的方法和策略
JML规格为测试的设计提供便利,可以使用JUnit进行方便的单元测试。单元测试构造数据时,根据规格覆盖所有的normal_behavior和exception_behavior分支,在每一个分支中对于每一个后置条件以及副作用使用assert语句进行检查。 - 容器选择和使用的经验
- HashMap 在 一 一 对应的数据结构和查询操作频繁的地方拥有较好的表现。最典型的是第三次作业中的EmojiIdList 和 EmojiHeatList 两个线性并且一 一对应的结构,非常适合用hashMap进行映射。除此之外,在异常类的设计中,由于需要输出对应Id所触发的异常次数,我普遍用到了HashMap来存储Id以及对应的异常触发次数。
- 出现的性能问题
- isCircle
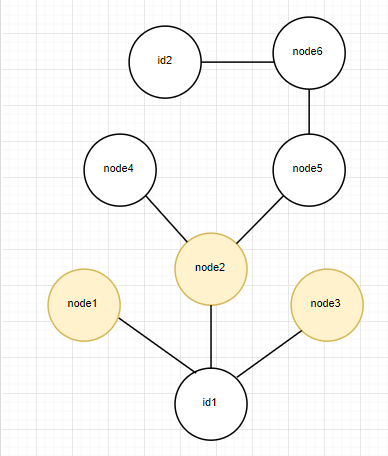
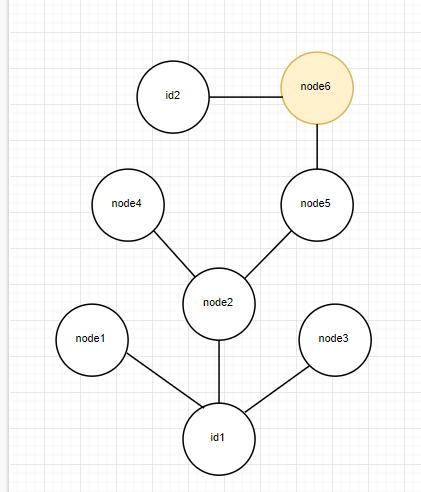
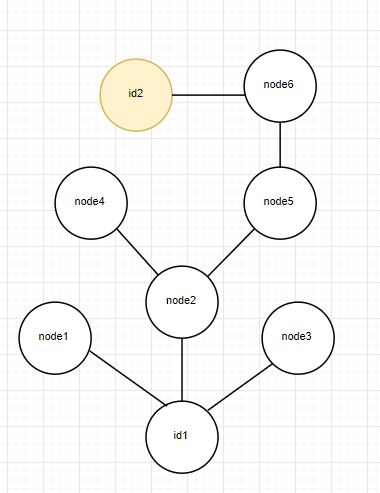
该函数的目的是寻找从id1到id2的通路,有则返回True,否则返回false。我在最初的设计中采取的是递归查找的方法,即从id1开始,不断对它的熟人列表进行递归调用查找函数,直到在某个递归函数中起点的熟人列表中有id2,则停止递归,返回ture,接着一路回溯到最开始的查找函数返回true。若所有熟人列表中的人调用的递归函数均未找到id2,则返回false。为保证在不存在路径时不出现死循环以及减少查找时的性能开销,在函数的参数中一直传递有存储当前已查找节点的列表。对于那些已经调用过递归函数的节点就不再调用函数。算法如图所示
![image]()
![image]()
![image]()
![image]()
在最坏情况下,此算法需要对每一个节点调用一次递归函数,复杂度可达O(n^2).- 优化策略
在资料的查询中,我发现此类通路存在性问题有一种比较典型的算法--并查集算法。该算法的思想为将有直接关联或有间接关联的元素并到一个集合,并给每个这样的集合设定一个标识元素,若两个元素所在集合的标识元素相同,则可快速判断这两个元素在图上存在通路。我的做法如下:
将一个集合的元素用树的结构来表示,在MyNetwork中定义了一个属性fatherMap,用于存储每个节点的父节点,若一个节点的父节点是自身,即它为树的根节点,那么它是该集合的标识元素。- 在addPerson时给新元素单独创建一个集合,并把标识元素设定为自己
- 在addRelation操作时进行判断,若操作的这两个元素的标识元素相同,则不进行额外操作,否则将这两个集合合并,即把一个集合的根节点的父节点设定为另一个集合的根节点。
- 在isCircle函数调用时,只需要判断两个id的根节点是否相同就可以直接判断是否存在通路。
- 上述查找根节点的方法是不断获取其父节点直至其父节点等于自身
- 可以发现,该算法的性能与所构造树的深度直接相关,为了进一步对算法进行优化,我在查找根节点之后将沿途节点的父节点设置为根节点,这样就大大降低了树的深度,对多次查询有极好的优化效果。
1 的图示:
![image]()
2 的图示
![image]()
- 优化策略
- queryBlockSum
该函数的目的是查询社交网络中相互独立的社交块的数量,两个独立的社交块中没有存在关系的元素。最初我采用的是最朴素的双重循环遍历法,本身O(n^2)的遍历复杂度加上isCircle函数的调用,自然是会超时的。最终我采取的方法是维护一个变量来查询任何时刻的块数量。具体做法如下:
在MyNetwork类中定义一个属性blockSum,初始值为0.
- 进行addPerson操作时对blockSum进行加一操作。
- 进行addRelation操作时,判断操作的两个id,调用isCircle函数,若为True则不发生变化,否则对blockSum进行减一操作。
- 调用queryBlockSum函数的时候直接返回blockSum的值.
优化之后使查询效率降为了O(1),对查询密集的场景有极大的效率提升效果。
- 寻找最短路径算法
在第11次作业中我使用的是比较传统的迪杰斯特拉算法,因此在强测中ctle了一个点。在和同学交流之后,发现他们普遍使用的是堆优化的迪杰斯特拉算法,不过笔者目前还没有去实现这种优化算法。
- isCircle
- 作业架构分析
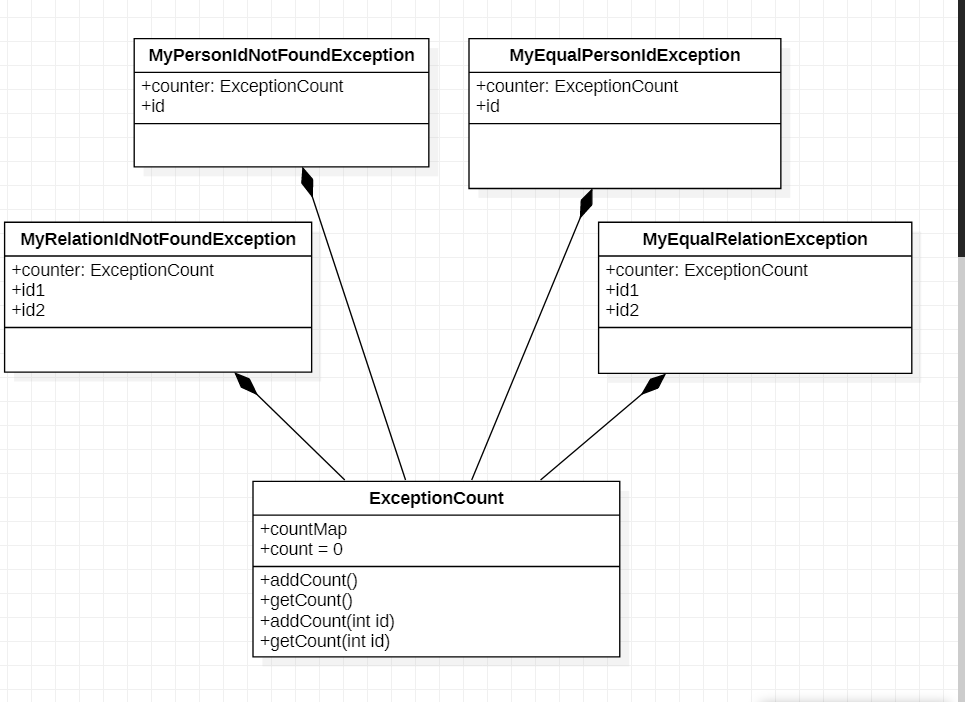
本单元作业的架构基本都是按照规格以及接口来设计的,除此之外,为了算法实现自己也设计了一些函数如findFatherRoot、disji等,不过在审视自己异常类的实现时发现异常类重复的代码过多,因为所有的异常类都需要统计总的异常触发次数以及每个id触发异常的次数。在研讨课上有一位同学分享了他异常类的设计,巧妙地使用组合的方式进行了代码复用。他设计了一个计数器类,与每一个异常类进行组合,间洁有力地优化了作业架构。示意图如下:
![image]()
- 心得体会
在本单元的学习中,我掌握了JML的基本撰写规则和一些规格的具体实现技巧。在实验课填充规格和作业阅读规格的训练中,我熟悉了JML的规则。在作业规格的具体实现中,我学会了灵活地实现规格,兼顾功能和性能的要求,打破了自己原先对规格的一些刻板印象。综上,本单元的作业虽然比较简单,但对未来的软件开发或设计类工作非常有用,好好对待可以学到很多东西。



 浙公网安备 33010602011771号
浙公网安备 33010602011771号