cgroup原理简析:进程调度
本篇来探究下cgroup对cpu的限制机制,前文提到过cgroup也是通过进程调度子系统来达到限制cpu的目的,因此需要了解下进程调度子系统.
因为是介绍cgroup的文章,因此只介绍进程调度中与cgroup密切关联的部分,详细完成的进程调度实现可参考进程调度的相关资料.
本文分为三个部分,首先介绍进程调度中的调度算法,在该基础上引入组调度,最后结合前面文章(cgroup原理简析:vfs文件系统)来说明上层通过echo pid >> tasks, echo n > cpu.shares等操作影响调度器对进程的调度,从而控制进程对cpu的使用,(内核源码版本3.10)
-------------------------------------------------------------
1.进程调度
我们知道linux下的进程会有多种状态,已就绪状态的进程在就绪队列中(struct rq),当cpu需要加载新任务时,调度器会从就绪队列中选择一个最优的进程加载执行.
那么调度器根据规则来选出这个最优的进程呢?这又引出了进程优先级的概念,简单来说,linux将进程分为普通进程和实时进程两个大类,用一个数值范围0-139来表示优先级,值越小优先级越高,其中0-99表示实时进程,100-139(对应用户层nice值-20-19)表示普通进程,实时进程的优先级总是高于普通进程.
不同优先级类型的进程当然要使用不同的调度策略,普通进程使用完全公平调度(cfs),实时进程使用实时调度(rt),这里内核实现上使用了一个类似面向对象的方式,抽象出一个调度类(struct sched_class)声明同一的钩子函数,完全公平调度实例(fair_sched_class)和实时调度实例(rt_sched_class)各自实现这些钩子.
对应的,就绪队列里也就分为两个子队列,一个维护普通进程,称之为cfs队列(cfs_rq),一个维护实时进程,称之为rt队列(rt_rq).
另外,虽然调度器最终调度的对象是进程,但在这里用一个调度实体(struct sched_entity||struct sched_rt_entity)表示一个要被调度的对象.
对于普通的进程调度来说,一个调度实体对象内嵌在task_struct中,对于组调度(cgroup)来说,其内嵌在task_group中.
cfs队列用红黑树组织调度实体,cfs调度算法总是选择最左边的调度实体.
rt队列的结构是类似rt_queue[100][list]这样的结构,这里99对应实时进程的0-99个优先级,二维是链表,也就是根据实时进程的优先级,将进程挂载相应的list上.
rt调度算法总是先选优先级最高的调度实体.
这里先贴出这些概念的struct,图1展示了他们之间的关系.
struct rq { unsigned int nr_running; //就绪进程的总数目 struct load_weight load; //当前队列的总负荷 struct cfs_rq cfs; //完全公平队列 struct rt_rq rt; //实时队列 struct task_struct *curr, *idle, *stop; //curr指向当前正在执行的task, u64 clock; //该队列自身的时钟(实际时间,调度算法还有个虚拟时间的概念) ... };
就绪队列,每个cpu对应一个就绪队列,后面为描述方便,假定系统cpu核数为1.
struct cfs_rq { //删减版 struct load_weight load; //该队列的总权重 unsigned int nr_running, h_nr_running; //该队列中的任务数 u64 min_vruntime; //一个虚拟时间,后面细说 struct rb_root tasks_timeline; //该cfs队列的红黑树,所有的进程用它来组织 struct rb_node *rb_leftmost; //指向红黑树最左边的一个节点,也就是下次将被调度器装载的 struct sched_entity *curr, *next, *last, *skip; //curr指向当前正在执行的进程 struct rq *rq; //自己所属的rq struct task_group *tg; //该cfs队列所属的task_group(task_group是实现cgroup的基础,后面再说) ... };
cfs就绪队列,用红黑树组织,这里有一个虚拟时间(vruntime)的概念,来保证在保证高优先级进程占用更多cpu的前提下,保证所有进程被公平的调度.
struct rt_prio_array { //实时队列用这个二位链表组织进程 DECLARE_BITMAP(bitmap, MAX_RT_PRIO+1); struct list_head queue[MAX_RT_PRIO]; // MAX_RT_PRIO=100 上面解释过了 }; struct rt_rq { struct rt_prio_array active; //组织所有就绪进程 unsigned int rt_nr_running; //就绪进程数目 int rt_throttled; //禁止调度标记 u64 rt_time; //当前队列累计运行时间 u64 rt_runtime; //当前队列最大运行时间 unsigned long rt_nr_boosted; struct rq *rq; //所属rq struct task_group *tg; //所属cgroup ... };
实时就绪队列,用二维链表组织.
因为实时进程优先级总是高于普通进程,又不使用完全公平算法,极端情况下实时进程一直占着cpu,普通进程等不到cpu资源.
因此实现用rt_time,rt_runtime用来限制实时进程占用cpu资源,例如rt_time = 100 rt_runtime = 95,这两个变量对应cgroup下的cpu.rt_period_us, cpu.rt_runtime_us.
那么该rq下,所有的实时进程只能占用cpu资源的95%,剩下的%5的资源留给普通进程使用.
struct sched_entity { struct load_weight load; //该调度实体的权重(cfs算法的关键 >> cgroup限制cpu的关键) struct rb_node run_node; //树节点,用于在红黑树上组织排序 u64 exec_start; //调度器上次更新这个实例的时间(实际时间) u64 sum_exec_runtime; //自进程启动起来,运行的总时间(实际时间) u64 vruntime; //该调度实体运行的虚拟时间 u64 prev_sum_exec_runtime; //进程在上次被撤销cpu时,运行的总时间(实际时间) struct sched_entity *parent;//父调度实体 struct cfs_rq *cfs_rq; //自己所属cfs就绪队列 struct cfs_rq *my_q; //子cfs队列,组调度时使用,如果该调度实体代表普通进程,该字段为NULL ... };
普通进程使用完全公平算法来保证队列中的进程都可得到公平的调度机会,同时兼顾高优先级的进程占用更多的cpu资源.
struct sched_rt_entity { struct list_head run_list; //链表节点,用于组织实时进程 struct sched_rt_entity *parent; //父调度实体 struct rt_rq *rt_rq; //自己所属rt就绪队列 struct rt_rq *my_q; //子rt队列,组调度时使用,如果该调度实体代表普通进程,该字段为NULL ... };
实时进程的调度算法是很简单的,优先级高的可实时抢占优先级低的进程,直到进程自己放弃cpu,否则可"一直"运行.(加了引号的一直)
struct sched_class { const struct sched_class *next; //sched_class指针,用于将cfs类 rt类 idle类串起来 // 全是函数指针,不同的类去各自实现,由调度器统一调用, void (*enqueue_task) (struct rq *rq, struct task_struct *p, int flags); void (*dequeue_task) (struct rq *rq, struct task_struct *p, int flags); void (*yield_task) (struct rq *rq); bool (*yield_to_task) (struct rq *rq, struct task_struct *p, bool preempt); void (*check_preempt_curr) (struct rq *rq, struct task_struct *p, int flags); struct task_struct * (*pick_next_task) (struct rq *rq); void (*put_prev_task) (struct rq *rq, struct task_struct *p); void (*set_curr_task) (struct rq *rq); void (*task_tick) (struct rq *rq, struct task_struct *p, int queued); void (*task_fork) (struct task_struct *p); void (*switched_from) (struct rq *this_rq, struct task_struct *task); void (*switched_to) (struct rq *this_rq, struct task_struct *task); void (*prio_changed) (struct rq *this_rq, struct task_struct *task,int oldprio); unsigned int (*get_rr_interval) (struct rq *rq, struct task_struct *task); void (*task_move_group) (struct task_struct *p, int on_rq); };
struct sched_class只是向调度器声明了一组函数,具体的实现是由各个调度类(cfs rt)实现.核心调度器只关心在什么时机调用那个函数指针,不关心具体实现.
图1
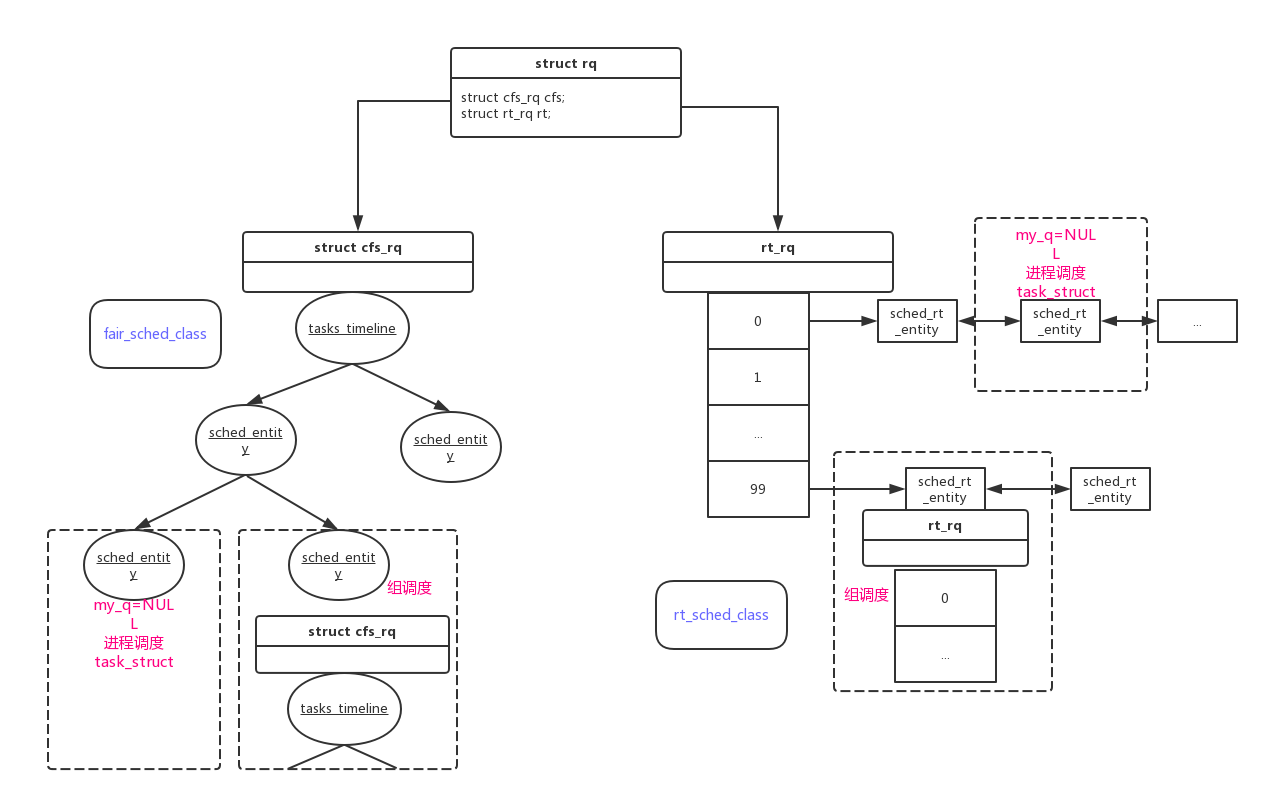
如图1,展示了各个结构之间的关系,注意标注出来的调度组.
为了聚焦,下面讨论时不考虑有新进程入队,或者就绪队列的子机因为等待其他资源(IO)出队等情况,只以周期性调度(系统每个一段时间产生一次tick中断,此时系统有机会更新一些统计变量,同时计算当前进程是否已经运行了足够长时间,需要调度)为例说明调度器的行为.
我们知道实时进程是会抢占普通进程的,所以当有实时进程进入就绪队列时,普通进程很快就会被撤销cpu,让给实时进程,因此实时进程和普通进程的抢占都是在实时进程入队时实时触发的,所以周期性调度不用考虑这种情况.
那么情况就变简单了,周期调度只需调用当前task的sched_class.task_tick就可以了,如果task是实时进程,相当于调用实时进程的调度类的task_tick实现,当task是普通进程时同理.
------cfs调度算法
完全公平调度算法的主要好处是它可以保证高优先级的进程占用更多的cpu时间,当时又能保证所有进程公平的得到调度机会.
上面也提到了虚拟时间的概念(vruntime),高优先级的进程得到了更多的cpu时间(实际时间runtime),但从虚拟时间(vruntime)的维度来说,各个进程跑的vruntime是一样长的.
怎么理解?待我举个不是很形象的栗子:
我们把A B C三个进程比为三个老奶奶,把调度器视为一个红领巾,红领巾的目标是同时把三个老奶奶一起扶到马路对面(完全公平嘛).
cfs调度算法跟上面红领巾的例子是类似的,可以把红领巾扶老奶奶走过的路程想象为vruntime,一个周期后,他对ABC都是公平的,扶她们走的路程都一样(vruntime时长),我们假设A奶奶腿脚极其不变(A优先级高),那么虽然扶A和扶BC走过的路程一样长,但是因为A慢呀,所以明显扶A要花更长的时间(实际时间).
所以cfs调度算法的秘密就是,优先级高的进程vruntime增长的慢,ABC三个进程可能都跑了10vruntime,但是BC花了10个runtime,而A(优先级高)缺花了20runtime.
怎么实现呢?
runtime = period * (se->load.weight / cfs_rq->load.weight) 公式1
period为一个调度周期,这里不关注它如何计算,se->load.weight越大,该调度实体在一个调度周期内获得的实际时间越长.
vruntime = runtime * (orig_load_value / se->load.weight) 公式2
将orig_load_value是个常量(1024),显而易见,进程的优先级越高(se->load.weight越大),在runtime相同时其vruntime变化的越慢.
我们将公式1带入公式2可得公式3:
vruntime = period * orig_load_value / cfs_rq->load.weight 公式3
由此可见,进程的vruntime和优先级没有关系,这样就达到了按照优先级分配实际时间,相同的vruntime体现公平.
上面cfs_rq.min_vruntime总是保存当前cfs队列各个调度实体中最小的vruntime(不是太严谨,不影响).
而红黑树各个sched_entity排序的key为(sched_entity->vruntime - cfs_rq.min_vruntime),这样优先级越高,相同实际时间的sched_entity->vruntime越小.
对应红黑树的key越小,越靠近红黑树左侧,cfs调度算法就是选取红黑树最左侧的sched_entity给cpu装载.
从头撸代码,当tick中断发生时,核心调度器调用cfs的task_tick函数task_tick_fair:
static void task_tick_fair(struct rq *rq, struct task_struct *curr, int queued) { struct cfs_rq *cfs_rq; struct sched_entity *se = &curr->se; for_each_sched_entity(se) { //组调度 cfs_rq = cfs_rq_of(se); entity_tick(cfs_rq, se, queued); //在entity_tick中更新cfs队列,当前调度实体时间相关的统计,并判断是否需要调度 } .... } static void entity_tick(struct cfs_rq *cfs_rq, struct sched_entity *curr, int queued) { ... update_curr(cfs_rq); // 更新调度实体,cfs队列统计信息 if (cfs_rq->nr_running > 1) check_preempt_tick(cfs_rq, curr); // 判断是否需要调度 ... }
entity_tick函数主要的操作就是两部分,首先调用update_curr()去更新sched_entity cfs的runtimevruntime等信息.
接着再调用check_preempt_tick()函数检查该cfs是否需要重新调度,看下这两个函数.
static void update_curr(struct cfs_rq *cfs_rq) { struct sched_entity *curr = cfs_rq->curr; u64 now = rq_of(cfs_rq)->clock_task; // 获取当前时间,这里是实际时间 unsigned long delta_exec; if (unlikely(!curr)) return; delta_exec = (unsigned long)(now - curr->exec_start); // 计算自上个周期到当前时间的差值,也就是该调度实体的增量runtime if (!delta_exec) return; __update_curr(cfs_rq, curr, delta_exec); //真正的更新函数 curr->exec_start = now; // exec_start更新成now,用于下次计算 ... account_cfs_rq_runtime(cfs_rq, delta_exec); //和cpu.cfs_quota_us cpu.cfs_period_us相关 } static inline void __update_curr(struct cfs_rq *cfs_rq, struct sched_entity *curr,unsigned long delta_exec) { unsigned long delta_exec_weighted; curr->sum_exec_runtime += delta_exec; //sum_exec_runtime保存该调度实体累计的运行时间runtime delta_exec_weighted = calc_delta_fair(delta_exec, curr); //用runtime(delta_exec)根据公式2算出vruntime(delta_exec_weighted) curr->vruntime += delta_exec_weighted; //累加vruntime update_min_vruntime(cfs_rq); //更新该cfs的min_vruntime }
这几行代码还是比较清晰的,根据runtime 公式2算出vruntime,然后累加该sched_entity的vruntime.
因为该sched_entity的vruntime增加了,所以之前保存的cfs_rq->min_vruntime可能失效了,update_min_vruntime()函数负责检查并更新.
同理,该sched_entity的vruntime也许不是该cfs红黑树中最小的了,因此上面调用了check_preempt_tick()简单是否需要重新调度.
看下check_preempt_tick():
static void check_preempt_tick(struct cfs_rq *cfs_rq, struct sched_entity *curr) { unsigned long ideal_runtime, delta_exec; struct sched_entity *se; s64 delta; ideal_runtime = sched_slice(cfs_rq, curr); //根据该sched_entity的权重以及公式1计算出期在本调度周期最大可运行的runtime delta_exec = curr->sum_exec_runtime - curr->prev_sum_exec_runtime; //该周期已经运行的runtime if (delta_exec > ideal_runtime) { // 超过了,则调用resched_task设置重新调度标记,(cgroup中的cpu.cfs_quota_us, cpu.cfs_period_us) resched_task(rq_of(cfs_rq)->curr); return; } if (delta_exec < sysctl_sched_min_granularity) return; se = __pick_first_entity(cfs_rq); // 选取当前红黑树最左端的sched_entity delta = curr->vruntime - se->vruntime; // 两个sched_entity的vruntime比较 if (delta < 0) return; if (delta > ideal_runtime) //这里是个BUG,vruntime不能和runtime比啊,改为 if (delta > calc_delta_fair(ideal_runtime, curr)) resched_task(rq_of(cfs_rq)->curr); }
check_preempt_tick也是比较清晰的,首先该sched_entity占用cpu的实际时间不能超过根据其权值算出的份额.
其次,如果红黑树最左侧的sched_entity的vruntime更小(delta > ideal_runtime *(orig_load_value / se->load.weight)参见公式2),那么发起调度.
这里不直接判断delta > 0,应该是为了防止频繁调度吧,cfs调度算法结束.
------实时调度算法,
实时调度算法原理上没啥好说的,直接看代码吧.
static void task_tick_rt(struct rq *rq, struct task_struct *p, int queued) { struct sched_rt_entity *rt_se = &p->rt; update_curr_rt(rq); // 更新runtime统计,并判断实时进程占用份额达到限制的话,设置调度标记 if (p->policy != SCHED_RR) // 如果不是SCHED_RR调度策略,直接返回 return; if (--p->rt.time_slice) // 每次tick中断-1 return; p->rt.time_slice = sched_rr_timeslice; // p->rt.time_slice 自减为0,该调度了,给起重新赋值后放入队列末尾 for_each_sched_rt_entity(rt_se) { if (rt_se->run_list.prev != rt_se->run_list.next) { requeue_task_rt(rq, p, 0); // 挂到对列尾, set_tsk_need_resched(p); // 设置调度标记 return; } } } static void update_curr_rt(struct rq *rq) { struct task_struct *curr = rq->curr; struct sched_rt_entity *rt_se = &curr->rt; struct rt_rq *rt_rq = rt_rq_of_se(rt_se); u64 delta_exec; delta_exec = rq->clock_task - curr->se.exec_start; //增量runtime curr->se.sum_exec_runtime += delta_exec; //task_struct累加 curr->se.exec_start = rq->clock_task; //置为当前时间,用以下次计算差值 for_each_sched_rt_entity(rt_se) { rt_rq = rt_rq_of_se(rt_se); if (sched_rt_runtime(rt_rq) != RUNTIME_INF) { //组调度? rt_rq->rt_time += delta_exec; // 当前rt_rq的rt_time累加 if (sched_rt_runtime_exceeded(rt_rq)) //该rt_rq运行时间是否超出限制 resched_task(curr); //是就调度, } } }
sched_rt_runtime_exceeded里的判断涉及到了用户层通过cgroup限制实时进程的cpu份额(cpu.rt_period_us, cpu.rt_runtime_us).看下:
static int sched_rt_runtime_exceeded(struct rt_rq *rt_rq) { u64 runtime = sched_rt_runtime(rt_rq); if (rt_rq->rt_throttled) return rt_rq_throttled(rt_rq); if (runtime >= sched_rt_period(rt_rq)) return 0; balance_runtime(rt_rq); //去其他核上借点时间,不深究了,(cpu.rt_runtime_us / cpu.rt_period_us * cpus才是真正的最大份额) runtime = sched_rt_runtime(rt_rq); //获取本周期最大执行时间 if (runtime == RUNTIME_INF) return 0; if (rt_rq->rt_time > runtime) { //当前运行时间已经超出,需要让出cpu struct rt_bandwidth *rt_b = sched_rt_bandwidth(rt_rq); /* * Don't actually throttle groups that have no runtime assigned * but accrue some time due to boosting. */ if (likely(rt_b->rt_runtime)) { rt_rq->rt_throttled = 1; //设置该rt_throttled为1,当新的周期开始时,rt_throttled重新被置0 } else { rt_rq->rt_time = 0; } if (rt_rq_throttled(rt_rq)) { sched_rt_rq_dequeue(rt_rq); //将该rt_rq --> task_group(后面说) --> sched_rt_entity出队 return 1; } } return 0; }
到此实时调度也结束了,下面看下组调度.
-------------------------------------------------------------
2.组调度
上面讨论时一直用调度实体来表示进程的,这是因为,一个调度实体可能对应一个task_struct,也可能对应一个task_group,看下struct:
struct task_struct { int on_rq; int prio, static_prio, normal_prio; unsigned int rt_priority; const struct sched_class *sched_class; //调度类 struct sched_entity se; // cfs调度实体 struct sched_rt_entity rt; //rt调度实体 struct task_group *sched_task_group; ... } struct task_group { struct cgroup_subsys_state css; struct sched_entity **se; //cfs调度实体 struct cfs_rq **cfs_rq; //子cfs队列 unsigned long shares; // atomic_t load_weight; // struct sched_rt_entity **rt_se; // rt调度实体 struct rt_rq **rt_rq; //子rt队列 struct rt_bandwidth rt_bandwidth; //存储cpu.rt_period_us, cpu.rt_runtime_us struct cfs_bandwidth cfs_bandwidth; //存储cpu.cfs_quota_us, cpu.cfs_period_us };
可见task_group和task_struct中都内嵌了调度实体,与后者不同的是,task_group并不是最终的运行单位,它只是代表本group中的所有task在上层分配总的cpu资源,
图2展示了task_group和其他几个结构的关系.
图2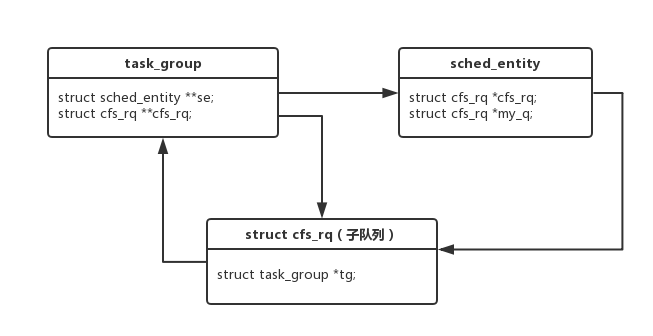
结合图1来看,调度算法在选到一个entity时,如果对应的是一个group,那么就在该cgroup的子rq中再次选择,知道选中一个真的进程,结合代码吧:
static void task_tick_fair(struct rq *rq, struct task_struct *curr, int queued) { struct cfs_rq *cfs_rq; struct sched_entity *se = &curr->se; for_each_sched_entity(se) { //组调度 cfs_rq = cfs_rq_of(se); entity_tick(cfs_rq, se, queued); //在entity_tick中更新cfs队列,当前调度实体时间相关的统计,并判断是否需要调度 } .... } #define for_each_sched_entity(se) \ for (; se; se = se->parent)
这是上面的代码,展开for_each_sched_entity宏
更新统计信息时是循环的,如果该调度实体是普通进程,那么se->parent为NULL,如果是某个group下的进程,那么循环向上更新父group.
static struct task_struct *pick_next_task_fair(struct rq *rq) { struct task_struct *p; struct cfs_rq *cfs_rq = &rq->cfs; struct sched_entity *se; if (!cfs_rq->nr_running) return NULL; do { //循环处理 se = pick_next_entity(cfs_rq); set_next_entity(cfs_rq, se); cfs_rq = group_cfs_rq(se); } while (cfs_rq); p = task_of(se); if (hrtick_enabled(rq)) hrtick_start_fair(rq, p); return p; }
调度器选择下一个装载的进程时,pick_next_entity选出最左边的sched_entity,如果对应的是一个group,那么就从该cgroup的 sub cfs_rq继续选,知道选到一个进程,
实时组调度也是类似的,有区别的是,实时group的权重,是该group下权重最大的进程的权重,因为实时进程优先级高的抢占优先级低的呀.
下面结合下前面文章(cgroup原理简析:vfs文件系统)来说下通过echo cgroup的控制文件是如何限制该cgroup下的进程的吧.
-------------------------------------------------------------
eg: echo 2048 >> cpu.shares
vfs调用过成上篇文章说过了,不再重复,直接到cpu_shares_write_u64,cpu_shares_write_u64只是包装,实际工作的是sched_group_set_shares()函数.
int sched_group_set_shares(struct task_group *tg, unsigned long shares) { .... tg->shares = shares; //将shares赋值到tg->shares for_each_possible_cpu(i) { //一个cgroup在每个cpu上都有一个调度实体, struct rq *rq = cpu_rq(i); struct sched_entity *se; se = tg->se[i]; for_each_sched_entity(se) update_cfs_shares(group_cfs_rq(se)); } ... return 0; } 进到update_cfs_shares()函数: static void update_cfs_shares(struct cfs_rq *cfs_rq) { struct task_group *tg; struct sched_entity *se; long shares; tg = cfs_rq->tg; se = tg->se[cpu_of(rq_of(cfs_rq))]; if (!se || throttled_hierarchy(cfs_rq)) return; #ifndef CONFIG_SMP if (likely(se->load.weight == tg->shares)) return; #endif shares = calc_cfs_shares(cfs_rq, tg); //可以理解为shares = tg->share reweight_entity(cfs_rq_of(se), se, shares); //设置该task_group对应的sched_entity的load.weight } 一些简单的判断,最终调用reweight_entity设置weight, static void reweight_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, unsigned long weight) { ... update_load_set(&se->load, weight); ... } static inline void update_load_set(struct load_weight *lw, unsigned long w) { lw->weight = w; lw->inv_weight = 0; }
echo 2048 >> cpu.shares就是设置cgroup->task_group->sched_entity.load.weight对应的值.
结合公式1,改变了weight就最终影响到了该sched_entity占cpu的实际时间.
注意该sched_entity不是某个进程的,而是task_group(cgroup)的,所以最终结果是:该cgroup下的进程占用cpu之和等于该sched_entity.load.weight结合公式1算出来的cpu时间.
eg: echo 1000000 >> cpu.rt_period_us echo 950000 >> cpu.rt_period_us
这里以实时进程看下,cpu.cfs_quota_us cpu.cfs_period_us也是类似,不再看了.
vfs-->cpu_rt_period_write_uint,这个函数封装sched_group_set_rt_period()函数.
static int sched_group_set_rt_period(struct task_group *tg, long rt_period_us) { u64 rt_runtime, rt_period; rt_period = (u64)rt_period_us * NSEC_PER_USEC; //计算新的period rt_runtime = tg->rt_bandwidth.rt_runtime; //原有的quota if (rt_period == 0) return -EINVAL; return tg_set_rt_bandwidth(tg, rt_period, rt_runtime); //设置 } vfs-->cpu_rt_runtime_write,这个函数封装sched_group_set_rt_runtime()函数, static int sched_group_set_rt_runtime(struct task_group *tg, long rt_runtime_us) { u64 rt_runtime, rt_period; rt_period = ktime_to_ns(tg->rt_bandwidth.rt_period); //原有的period rt_runtime = (u64)rt_runtime_us * NSEC_PER_USEC; //新的quota if (rt_runtime_us < 0) rt_runtime = RUNTIME_INF; return tg_set_rt_bandwidth(tg, rt_period, rt_runtime); //设置 } 可见设置cpu.rt_period_us,cpu.rt_period_us时,都是除了新设的值,再取另外一个原有的值,一起调用tg_set_rt_bandwidth设置. static int tg_set_rt_bandwidth(struct task_group *tg, u64 rt_period, u64 rt_runtime) { ... tg->rt_bandwidth.rt_period = ns_to_ktime(rt_period); //设置,将quota period存到task_group里 tg->rt_bandwidth.rt_runtime = rt_runtime; for_each_possible_cpu(i) { struct rt_rq *rt_rq = tg->rt_rq[i]; raw_spin_lock(&rt_rq->rt_runtime_lock); rt_rq->rt_runtime = rt_runtime; //同步设置每个rt_rq->rt_runtime raw_spin_unlock(&rt_rq->rt_runtime_lock); } raw_spin_unlock_irq(&tg->rt_bandwidth.rt_runtime_lock); unlock: read_unlock(&tasklist_lock); mutex_unlock(&rt_constraints_mutex); return err; }
结合上面说的实时调度算法,设置了rt_rq->rt_runtime相当于设置了实时进程在每个周期占用的cpu的最大比例.
-------------------------------------------------------------
eg: echo pid >> tasks
这个操作分为两部。首先改变进程所属的cgroup,之前已经说过了.其次调用各个子系统的attach钩子函数,这里相当于改变进程所在的运行队列。
简单来说就是改变几个指针的值。让进程与原先的就绪队列断开。跑在cgroup的就绪队列中。
如有错误,请指正。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号