【笔记】数据结构、算法7
邻接矩阵适用于稠密图(边数接近于顶点数的平方),邻接表适用于稀疏图(边数远小于顶点数的平方)。 √
邻接矩阵取决于点,因此用于稠密图,邻接表用于稀疏图,稠密图用邻接表表示的话会占用很多空间,而邻接矩阵的空间是固定的都是n²,所以用矩阵表示稠密图。
用邻接矩阵法存储一个图时,在不考虑压缩存储的情况下,所占用的存储空间大小只与图中结点个数有关,而与图的边数无关,这样的说法正确吗? 正确
邻接矩阵取决于点数,只要点数确定,那么矩阵大小确定,里面的值不会影响存储空间大小。
对于双向循环链表,在p指针所指的结点之后插入s指针所指结点的操作应为()
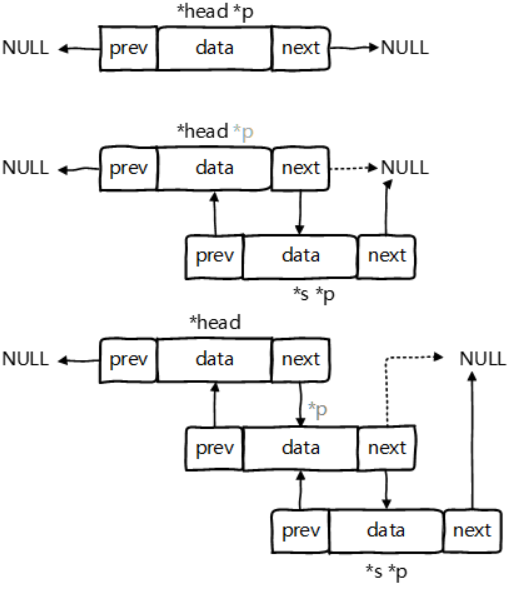
图片来源:https://www.cnblogs.com/hughdong/p/6785391.html
双向链表的插入顺序:先搞定插入节点的前驱和后继,在搞定后结点的前驱,最后搞定前结点的后继。
以下哪个不是分配在栈上的?函数内动态申请的对象
栈:由编译器自动分配释放,存放函数的参数值,局部变量的值等,内存的分配是连续的,类似于平时我们所说的栈,如果还不清楚,那么就把它想成数组,它的内存分配是连续分配的,即,所分配的内存是在一块连续的内存区域内.当我们声明变量时,那么编译器会自动接着当前栈区的结尾来分配内存.
简单类型变量储存在栈中,而对象的内容储存在堆中,只是指向对象的内存地址储存在栈中。
用选择排序方法对线性表(17,9,20,21,1,7,4,11,5)进行升序排序时,第3趟排序的结果是( )
选择排序法升序,每一次选出未比较的序列中最小值,与前面的元素互换位置;记得是互换!!
第一次:1 9 20 21 17 4 11 5
第二次:1 4 20 21 17 9 11 5
第三次:1 4 5 21 17 9 11 20
若以{4,7,8,10,12}作为叶子节点的权值构造哈弗曼树,则其带权路径长度是() 又是哈夫曼!!
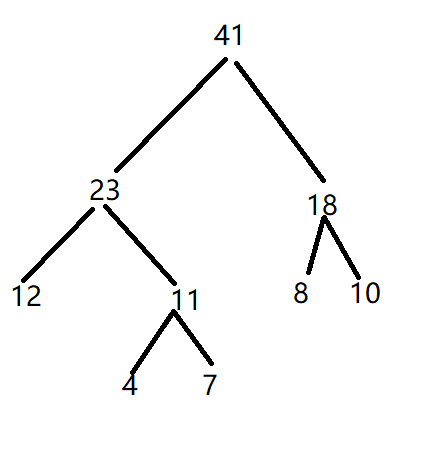
计算就不写了!!
对n(n大于等于2)个权值均不相同的字符构成哈夫曼树,关于该树的叙述中,正确的是()
树中一定没有度为1的结点。
!!这个是正确的,当时脑子一热觉得错???
总结:循环队列的相关条件和公式:顺时针存储
1.队空条件:rearfront
2.队满条件:(rear+1) %QueueSIzefront,其中QueueSize为循环队列的最大长度
3.计算队列长度:(rear-front+QueueSize)%QueueSize
4.入队:(rear+1)%QueueSize
5.出队:(front+1)%QueueSize

 浙公网安备 33010602011771号
浙公网安备 33010602011771号