
进程管理专题(一)
视频4.进程原理及系统调用
task
Linux 内核把进程叫做任务 (task), 进程的虚拟地址空间可分为用户虚拟地址空间和内
核虚拟地址空间,所有进程共享内核虚拟地址空间--每个进程在用户态有独立的虚拟地址空间,但内核态的地址空间是映射到同一块(高地址部分)
在C语言标准库中和Linux内核进程的概念中,对于进程和线程有点不同,比较如下表:
| C 语言标准库进程 | Linux 内核进程 |
|---|---|
| 包括多个线程的进程 | 线程组 |
| 只有一个线程的进程 | 任务或进程 |
| 线程 | 共享用户虚拟地址空间的进程 |
看完上表后,再来理解下面这句话:
进程有两种特殊的形式:没有用户虚拟地址空间的进程叫内核线程,共享用户虚拟地址空间的进程叫用户线程,共享同一个用户虚拟地址空间的所有用户线程叫线程组
Linux 通过 'ps' 命令用于输出当前系统的进程状态。显示瞬间进程的的状态,并不是动态连续;如果我们想对进程进行实时监控就 'top' 命令。
task_struct
task_struct 结构体在 include\linux\sched.h 中定义
TASK_RUNNING状态
定义: 可运行状态或者可就绪状态,表示进程处于可执行的状态,可能正在执行或等待在就绪队列中。
注意: 在Linux内核中,TASK_RUNNING状态并不严格区分进程是否正在CPU上运行。
TASK_INTERRUPTIBLE状态
定义: 可中断睡眠状态,又称浅睡眠状态。进程进入睡眠状态等待特定条件或资源,条件满足时可被唤醒。
特性: 可通过信号中断睡眠状态,使进程重新进入就绪队列。
TASK_UNINTERRUPTIBLE状态
定义: 不可中断状态,又称深度睡眠状态。进程在睡眠等待时不受信号干扰,不响应任何信号。
查看方式: 可以通过ps命令查看被标记为D状态的进程,即处于不可中断睡眠状态的进程。
__TASK_STOPPED状态
定义: 进程停止运行的状态,通常由于接收到停止信号(如SIGSTOP)。
EXIT_ZOMBIE状态
定义: 僵尸状态,进程已经消亡但在进程表中仍有记录,父进程尚未调用wait()系统调用回收其资源。
注意: 僵尸状态进程占用内核资源,应及时处理以避免资源泄漏。
task_struct中值得注意的: state,pid,tgid,pid_links[PIDTYPE_MAX],real_parent,parent,group_leader,cred,real_cred,comm[TASK_COMM_LEN], prio,static_prio,normal_prio,rt_priority,cpus_ptr,mm,active_mm,fs,files等等等等
进程优先级
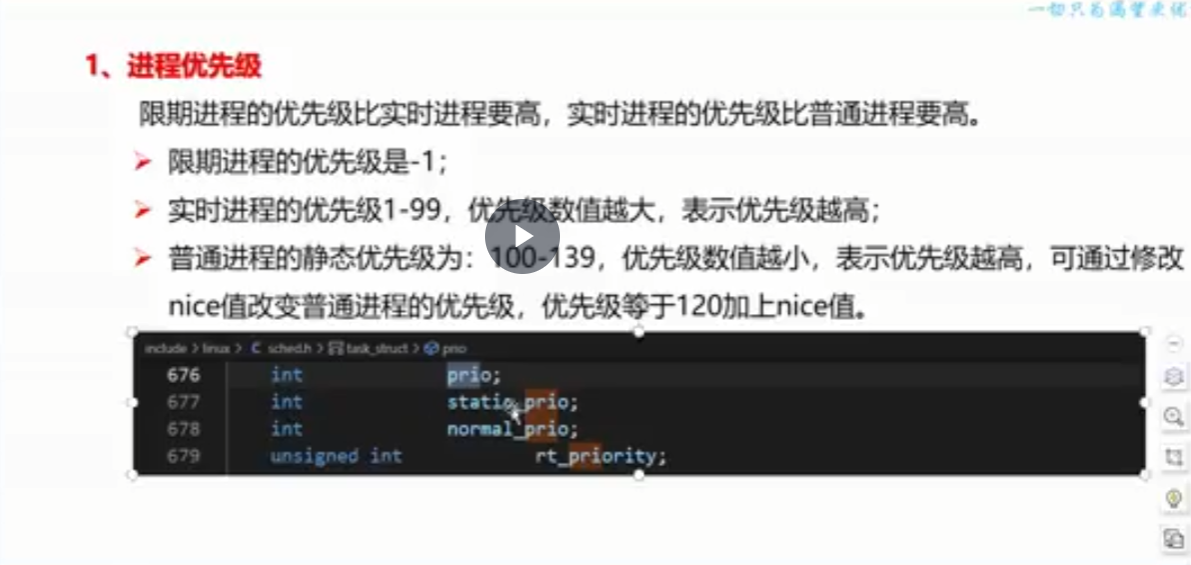
关于 prio,static_prio,normal_prio,rt_priority 的比较与分析见一下博客:
https://blog.csdn.net/shulianghan/article/details/123786549
系统调用
在内核版本为 6.12.54 中的 fork.c 源码中,关于系统调用 fork,vfork等,最终都是调用kernel_clone(&args),具体解析见 《图解Linux内核(基于6.x) (姜亚华) (Z-Library)》--13.3 创建进程
#ifdef __ARCH_WANT_SYS_FORK
SYSCALL_DEFINE0(fork)
{
#ifdef CONFIG_MMU
struct kernel_clone_args args = {
.exit_signal = SIGCHLD,
};
return kernel_clone(&args);
#else
/* can not support in nommu mode */
return -EINVAL;
#endif
}
#endif
#ifdef __ARCH_WANT_SYS_VFORK
SYSCALL_DEFINE0(vfork)
{
struct kernel_clone_args args = {
.flags = CLONE_VFORK | CLONE_VM,
.exit_signal = SIGCHLD,
};
return kernel_clone(&args);
}
#endif
内核线程
内核线程是一种只存在内核态的进程,它不会在用户态运行,多是一些内核中的服务进程
它是独立运行在内核空间的进程,与普通用户进程的区别在于内核线程没有独立的进程地址空间。task_struct 数据结构里面有一个成员指针 mm 设置为 NULL, 说明它只能运行在内核空间
进程退出
进程主动终止:从main()函数返回,链接程序会自动添加到exit()系统调用;主动调用exit()系统函数。
进程被动终止:进程收到一个自己不能处理的信号;进程收到 SGKILL 等终止信息
SYSCALL_DEFINE1(exit, int, error_code)
{
do_exit((error_code&0xff)<<8);
}
视频5.调度器及CFS调度器
1.调度:就是按照某种调度的算法设计,从进程的就绪队列当中选取进程分配CPU,主要是协调对CPU等相关资源使用,进程调度的目的是最大限度利用CPU的时间
2.如果调度器支持就绪状态切换到执行状态,同时支持执行状态切换到就绪状态,称调度器为抢占式调度器
3.调度类/调度器类 sched_class 结构体如下:
// kernel/sched/sched.h
struct sched_class {
#ifdef CONFIG_UCLAMP_TASK
int uclamp_enabled;
#endif
void (*enqueue_task) (struct rq *rq, struct task_struct *p, int flags);
bool (*dequeue_task) (struct rq *rq, struct task_struct *p, int flags);
void (*yield_task) (struct rq *rq);
bool (*yield_to_task)(struct rq *rq, struct task_struct *p);
void (*wakeup_preempt)(struct rq *rq, struct task_struct *p, int flags);
int (*balance)(struct rq *rq, struct task_struct *prev, struct rq_flags *rf);
struct task_struct *(*pick_task)(struct rq *rq);
/*
* Optional! When implemented pick_next_task() should be equivalent to:
*
* next = pick_task();
* if (next) {
* put_prev_task(prev);
* set_next_task_first(next);
* }
*/
struct task_struct *(*pick_next_task)(struct rq *rq, struct task_struct *prev);
void (*put_prev_task)(struct rq *rq, struct task_struct *p, struct task_struct *next);
void (*set_next_task)(struct rq *rq, struct task_struct *p, bool first);
#ifdef CONFIG_SMP
int (*select_task_rq)(struct task_struct *p, int task_cpu, int flags);
void (*migrate_task_rq)(struct task_struct *p, int new_cpu);
void (*task_woken)(struct rq *this_rq, struct task_struct *task);
void (*set_cpus_allowed)(struct task_struct *p, struct affinity_context *ctx);
void (*rq_online)(struct rq *rq);
void (*rq_offline)(struct rq *rq);
struct rq *(*find_lock_rq)(struct task_struct *p, struct rq *rq);
#endif
void (*task_tick)(struct rq *rq, struct task_struct *p, int queued);
void (*task_fork)(struct task_struct *p);
void (*task_dead)(struct task_struct *p);
/*
* The switched_from() call is allowed to drop rq->lock, therefore we
* cannot assume the switched_from/switched_to pair is serialized by
* rq->lock. They are however serialized by p->pi_lock.
*/
void (*switching_to) (struct rq *this_rq, struct task_struct *task);
void (*switched_from)(struct rq *this_rq, struct task_struct *task);
void (*switched_to) (struct rq *this_rq, struct task_struct *task);
void (*reweight_task)(struct rq *this_rq, struct task_struct *task,
const struct load_weight *lw);
void (*prio_changed) (struct rq *this_rq, struct task_struct *task,
int oldprio);
unsigned int (*get_rr_interval)(struct rq *rq,
struct task_struct *task);
void (*update_curr)(struct rq *rq);
#ifdef CONFIG_FAIR_GROUP_SCHED
void (*task_change_group)(struct task_struct *p);
#endif
#ifdef CONFIG_SCHED_CORE
int (*task_is_throttled)(struct task_struct *p, int cpu);
#endif
};
4.调度器类可以分为以下五类
extern const struct sched_class stop_sched_class; //停机调度类
extern const struct sched_class dl_sched_class; //限期调度类
extern const struct sched_class rt_sched_class; //实时调度类
extern const struct sched_class fair_sched_class; //公平调度类
extern const struct sched_class idle_sched_class; //空闲调度类
这五种调度类的优先级从高到低依次为:停机调度类,限期调度类,实时调度类,公平调度类,空闲调度类
- 停机调度类:优先级最高的调度类,停机进程是优先级最高的进程,可以抢占所有其他进程,其他进程不可抢占停机进程
- 限期调度类:最早使用优先算法,使用红黑树把进程按照绝对截止期限从小到大排序,每次调度时选择绝对截止期限最小的进程
- 实时调度类:为每个调度优先级维护一个队列
- 公平调度类:使用完全公平的调度算法,这种算法会引入虚拟运行时间的相关概念--虚拟运行时间=实际运行时间*nice0 对应的权重/进程的权重
- 空闲调度类:每个CPU上有一个空闲线程,即0号线程。空闲调度类优先级别最低,仅当没有其他进程可以调度的时候,才会调度空闲线程
5.进程优先级
// include\linux\sched\prio.h
#define MAX_RT_PRIO 100
#define MAX_DL_PRIO 0
#define MAX_PRIO (MAX_RT_PRIO + NICE_WIDTH)
#define DEFAULT_PRIO (MAX_RT_PRIO + NICE_WIDTH / 2)
【进程分类】
实时进程(Real-Time Process):优先级高,需要立即被执行的进程
普通进程(Normal Process):优先级低,更长执行时间的进程
进程的优先级是用一个0-139的整数直接表示。数字越小,优先级越高,其中优先级0-99留给实时进程,100-139留给普通进程
6.内核调度策略
linux内核提供一些调度策略供用户应用程序来选择调度器,linux内核调度策略部分源码如下:
// include/uapi/linux/sched.h
/*
* Scheduling policies
*/
#define SCHED_NORMAL 0
#define SCHED_FIFO 1
#define SCHED_RR 2
#define SCHED_BATCH 3
/* SCHED_ISO: reserved but not implemented yet */
#define SCHED_IDLE 5
#define SCHED_DEADLINE 6
#define SCHED_EXT 7
/* Can be ORed in to make sure the process is reverted back to SCHED_NORMAL on fork */
#define SCHED_RESET_ON_FORK 0x40000000
- SCHED_NORMAL:普通进程调度策略,使 task 选择 CFS 调度器来调度运行
- SCHED_FIFO:实时进程调度策略,先进先出调度没有时间片,没有更高优先级的状态下,只有等待主动让出 CPU
- SCHED_RR:实时进程调度策略,时间片轮转,进程使用完时间片之后加入优先级对应运行队列当中的尾部,把 CPU 让给同等优先级的其他进程
- SCHED_BATCH:普通进程调度策略,批量处理,使task选择 CFS 调度器来调度运行
- SCHED_IDLE:普通进程调度策略,使 task 以最低优先级选择 CFS 调度器来调度运行
- SCHED_DEADLINE:限期进程调度策略,使 task 选择 Deadline 调度器来调度运行
- SCHED_EXT:扩展进程调度策略,用于支持自定义或实验性的调度器,使 task 可以根据特定需求选择扩展调度器来运行
补充:CFS(Completely Fair Scheduler)是 Linux 内核 2.6.23 之后默认的普通进程调度器,专为 SCHED_NORMAL、SCHED_BATCH、SCHED_IDLE 这类非实时任务设计。它的核心目标是让所有进程尽可能公平地分享 CPU 时间,而不是传统意义上的“时间片”轮转。CFS 是一个“按比例分配 CPU 时间的红黑树调度器”,完全抛弃固定时间片,用虚拟运行时间(vruntime)衡量谁最“欠” CPU,就让谁运行。
补充:其中 stop 调度器和 DLE-task 调度器,仅在内核中使用,用户没有办法进行选择使用
7.CFS调度器类在linux内核源码如下:
// kernel\sched\fair.c
const struct sched_class fair_sched_class;
/**************************************************************
* CFS operations on generic schedulable entities:
*/
/*
* All the scheduling class methods:
*/
DEFINE_SCHED_CLASS(fair) = {
.enqueue_task = enqueue_task_fair,
.dequeue_task = dequeue_task_fair,
.yield_task = yield_task_fair,
.yield_to_task = yield_to_task_fair,
.wakeup_preempt = check_preempt_wakeup_fair,
.pick_task = pick_task_fair,
.pick_next_task = __pick_next_task_fair,
.put_prev_task = put_prev_task_fair,
.set_next_task = set_next_task_fair,
#ifdef CONFIG_SMP
.balance = balance_fair,
.select_task_rq = select_task_rq_fair,
.migrate_task_rq = migrate_task_rq_fair,
.rq_online = rq_online_fair,
.rq_offline = rq_offline_fair,
.task_dead = task_dead_fair,
.set_cpus_allowed = set_cpus_allowed_fair,
#endif
.task_tick = task_tick_fair,
.task_fork = task_fork_fair,
.reweight_task = reweight_task_fair,
.prio_changed = prio_changed_fair,
.switched_from = switched_from_fair,
.switched_to = switched_to_fair,
.get_rr_interval = get_rr_interval_fair,
.update_curr = update_curr_fair,
#ifdef CONFIG_FAIR_GROUP_SCHED
.task_change_group = task_change_group_fair,
#endif
#ifdef CONFIG_SCHED_CORE
.task_is_throttled = task_is_throttled_fair,
#endif
#ifdef CONFIG_UCLAMP_TASK
.uclamp_enabled = 1,
#endif
};
- enqueue_task_fair:当任务进入可运行状态时,用此函数将调度实体存放到红黑树,完成入队操作
- dequeue_task_fair:当任务退出可运行状态时,用此函数将调度实体从红黑树中移除,完成出队操作
8.CFS调度器就绪队列内核源码如下
/* CFS-related fields in a runqueue */
struct cfs_rq {
struct load_weight load;
unsigned int nr_running;
unsigned int h_nr_queued; /* SCHED_{NORMAL,BATCH,IDLE} */
unsigned int h_nr_runnable; /* SCHED_{NORMAL,BATCH,IDLE} */
unsigned int idle_nr_running; /* SCHED_IDLE */
unsigned int idle_h_nr_running; /* SCHED_IDLE */
unsigned int h_nr_delayed;
s64 avg_vruntime;
u64 avg_load;
u64 min_vruntime;
#ifdef CONFIG_SCHED_CORE
unsigned int forceidle_seq;
u64 min_vruntime_fi;
#endif
struct rb_root_cached tasks_timeline;
/*
* 'curr' points to currently running entity on this cfs_rq.
* It is set to NULL otherwise (i.e when none are currently running).
*/
struct sched_entity *curr;
struct sched_entity *next;
#ifdef CONFIG_SMP
/*
* CFS load tracking
*/
struct sched_avg avg;
#ifndef CONFIG_64BIT
u64 last_update_time_copy;
#endif
struct {
raw_spinlock_t lock ____cacheline_aligned;
int nr;
unsigned long load_avg;
unsigned long util_avg;
unsigned long runnable_avg;
} removed;
#ifdef CONFIG_FAIR_GROUP_SCHED
u64 last_update_tg_load_avg;
unsigned long tg_load_avg_contrib;
long propagate;
long prop_runnable_sum;
/*
* h_load = weight * f(tg)
*
* Where f(tg) is the recursive weight fraction assigned to
* this group.
*/
unsigned long h_load;
u64 last_h_load_update;
struct sched_entity *h_load_next;
#endif /* CONFIG_FAIR_GROUP_SCHED */
#endif /* CONFIG_SMP */
#ifdef CONFIG_FAIR_GROUP_SCHED
struct rq *rq; /* CPU runqueue to which this cfs_rq is attached */
/*
* leaf cfs_rqs are those that hold tasks (lowest schedulable entity in
* a hierarchy). Non-leaf lrqs hold other higher schedulable entities
* (like users, containers etc.)
*
* leaf_cfs_rq_list ties together list of leaf cfs_rq's in a CPU.
* This list is used during load balance.
*/
int on_list;
struct list_head leaf_cfs_rq_list;
struct task_group *tg; /* group that "owns" this runqueue */
/* Locally cached copy of our task_group's idle value */
int idle;
#ifdef CONFIG_CFS_BANDWIDTH
int runtime_enabled;
s64 runtime_remaining;
u64 throttled_pelt_idle;
#ifndef CONFIG_64BIT
u64 throttled_pelt_idle_copy;
#endif
u64 throttled_clock;
u64 throttled_clock_pelt;
u64 throttled_clock_pelt_time;
u64 throttled_clock_self;
u64 throttled_clock_self_time;
int throttled;
int throttle_count;
struct list_head throttled_list;
struct list_head throttled_csd_list;
#endif /* CONFIG_CFS_BANDWIDTH */
#endif /* CONFIG_FAIR_GROUP_SCHED */
};
cfs_rq:跟踪就绪队列信息以及管理就绪态调度实体,并维护一只按照虚拟时间排序的红黑树
视频6.实时调度类及 SMP 和 NUMA
1.Linux进程可分为两大类:实时进程和普通进程。实时进程与普通进程根本不同之处,如果系统中有一个实时进程可执行,那么调度器总是会选择它,除非另有一个优先级更高的实时进程
- SCHED_FIFO:没有时间,在被调度器选择之后,可以运行任意长时间
- SCHED_RR:有时间片,其值在进程运行时会减少
2.实时调度实体 sched_rt_entity 内核源码
// include\linux\sched.h
struct sched_rt_entity {
struct list_head run_list; //专门用于加入到优先级队列当中
unsigned long timeout; //设置时间超时
unsigned long watchdog_stamp; //用于记录jiffies值
unsigned int time_slice; //时间片
unsigned short on_rq;
unsigned short on_list;
struct sched_rt_entity *back; //临时用于从上往下连接RT调度实体使用
#ifdef CONFIG_RT_GROUP_SCHED
struct sched_rt_entity *parent; //指向父RT调度实体
/* rq on which this entity is (to be) queued: */
struct rt_rq *rt_rq;
/* rq "owned" by this entity/group: */
struct rt_rq *my_q; //RT调度实体所拥有的实时运行队列,用于管理子任务
#endif
} __randomize_layout;
3.实时调度类 rt_sched_class 数据结构
DEFINE_SCHED_CLASS(rt) = {
.enqueue_task = enqueue_task_rt, //将一个task存放到就绪队列或者尾部
.dequeue_task = dequeue_task_rt, //将一个task从就绪队列的末尾
.yield_task = yield_task_rt, //主动放弃执行
.wakeup_preempt = wakeup_preempt_rt,
.pick_task = pick_task_rt, //核心调度器选择就绪队列当中的那个哪个任务将要被调度, prev 是将要被调度出的任务,返回值是将要被调度的任务
.put_prev_task = put_prev_task_rt, //当一个任务将要被调出出时执行
.set_next_task = set_next_task_rt,
#ifdef CONFIG_SMP
.balance = balance_rt,
.select_task_rq = select_task_rq_rt,
.set_cpus_allowed = set_cpus_allowed_common,
.rq_online = rq_online_rt,
.rq_offline = rq_offline_rt,
.task_woken = task_woken_rt,
.switched_from = switched_from_rt,
.find_lock_rq = find_lock_lowest_rq,
#endif
.task_tick = task_tick_rt,
.get_rr_interval = get_rr_interval_rt,
.prio_changed = prio_changed_rt,
.switched_to = switched_to_rt,
.update_curr = update_curr_rt,
#ifdef CONFIG_SCHED_CORE
.task_is_throttled = task_is_throttled_rt,
#endif
#ifdef CONFIG_UCLAMP_TASK
.uclamp_enabled = 1,
#endif
};
其中宏 DEFINE_SCHED_CLASS(name) 展开如下:
#define DEFINE_SCHED_CLASS(name) \
const struct sched_class name##_sched_class \
__aligned(__alignof__(struct sched_class)) \
__section("__" #name "_sched_class")
A:实时调度类操作核心函数 enqueue_task_rt -> 插入进程:
/*
* Adding/removing a task to/from a priority array:
*/
//更新调度信息,将调度实体插入到相应优先级队列的末尾
static void
enqueue_task_rt(struct rq *rq, struct task_struct *p, int flags)
{
struct sched_rt_entity *rt_se = &p->rt;
if (flags & ENQUEUE_WAKEUP)
rt_se->timeout = 0;
check_schedstat_required();
update_stats_wait_start_rt(rt_rq_of_se(rt_se), rt_se);
enqueue_rt_entity(rt_se, flags);
if (!task_current(rq, p) && p->nr_cpus_allowed > 1)
enqueue_pushable_task(rq, p);
}
B:实时调度类操作核心函数 pick_next_rt_entity -> 选择进程,实时调度类会选择最高优先级的实时进程来运行:
static struct sched_rt_entity *pick_next_rt_entity(struct rt_rq *rt_rq)
{
struct rt_prio_array *array = &rt_rq->active;
struct sched_rt_entity *next = NULL;
struct list_head *queue;
int idx;
//首先找到一个可用的实体
idx = sched_find_first_bit(array->bitmap);
BUG_ON(idx >= MAX_RT_PRIO);
//从链表组中找到对应的链表
queue = array->queue + idx;
if (SCHED_WARN_ON(list_empty(queue)))
return NULL;
next = list_entry(queue->next, struct sched_rt_entity, run_list);
return next; //返回找到的运行实体
}
C:实时调度类操作核心函数 dequeue_task_rt -> 删除进程:
static bool dequeue_task_rt(struct rq *rq, struct task_struct *p, int flags)
{
struct sched_rt_entity *rt_se = &p->rt;
update_curr_rt(rq); //更新调度数据信息等
dequeue_rt_entity(rt_se, flags); //将rt_se从运行队列中删除,然后添加到队列尾部
dequeue_pushable_task(rq, p);
return true;
}
5.SMP服务器CPU利用率最好的情况下是2至4个CPU
6.从应用层系统架构,目前商用服务器大体分为三类:SMP,NUMA,MPP
- NUMA优势:一台物理服务器内部继承多个CPU,使系统具有较高事务处理能力。NUMA架构适合OLTP事务处理环境
- SMP优势:当前使用的OTLP程序当中,用户访问

 浙公网安备 33010602011771号
浙公网安备 33010602011771号