
猿人学内部练习平台12~14题
第12题:静态css字体加密
抓包发现,返回结果数字均为这种格式 ,经对比发现,该串字符串与数字0~9有着一一对应关系,响应匹配即可:
data_set = {
'': '1',
'': '2',
'': '3',
'': '4',
'': '5',
'': '6',
'': '7',
'': '8',
'': '9',
'': '0',
}
第13题:动态css字体加密
抓包后,返回数字格式同上一题,但是不再是固定的映射关系,同时每一次请求都会返回一个图片信息:
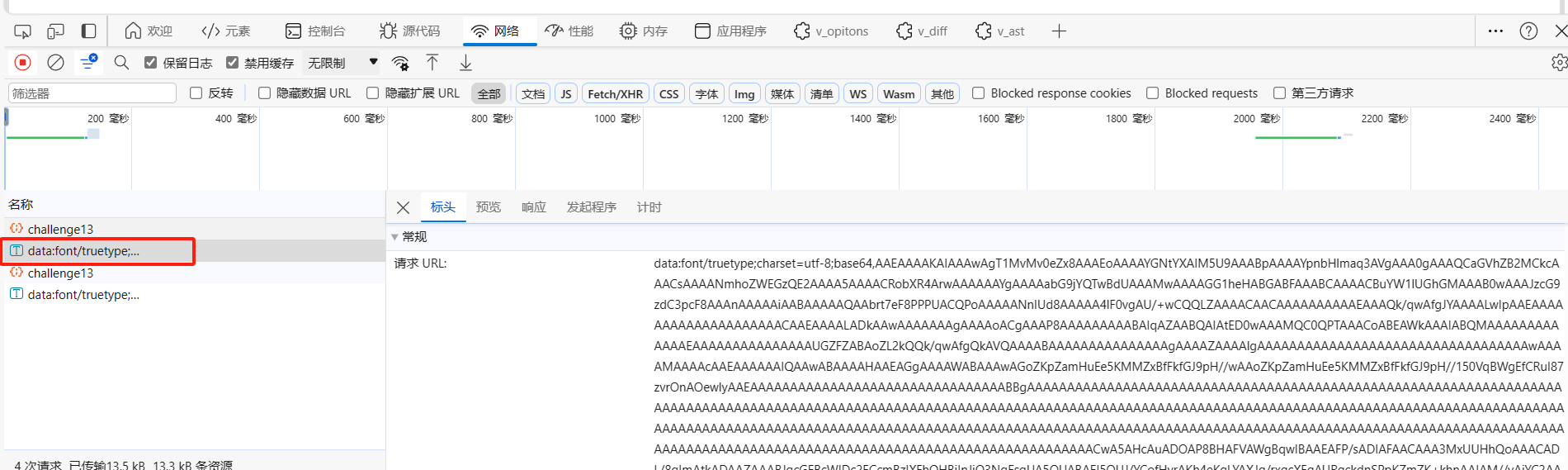
import base64
from fontTools.ttLib import TTFont
base64_data = "AAEAAAAKAIAAAwAgT1MvMhDPaKIAAAEoAAAAYGNtYXBtSs29AAABpAAAAYpnbHlmZprFawAAA0gAAAQCaGVhZB1E6Q4AAACsAAAANmhoZWEGzQE2AAAA5AAAACRobXR4ArwAAAAAAYgAAAAabG9jYQUEBgQAAAMwAAAAGG1heHABGABFAAABCAAAACBuYW1lUGhGMAAAB0wAAAJzcG9zdDftalAAAAnAAAAAiAABAAAAAQAAca9Lel8PPPUACQPoAAAAANnIUd8AAAAA4gpThQAU/+wCQQLZAAAACAACAAAAAAAAAAEAAAQk/qwAfgJYAAAALwIpAAEAAAAAAAAAAAAAAAAAAAACAAEAAAALADkAAwAAAAAAAgAAAAoACgAAAP8AAAAAAAAABAIqAZAABQAIAtED0wAAAMQC0QPTAAACoABEAWkAAAIABQMAAAAAAAAAAAAAEAAAAAAAAAAAAAAAUGZFZABAtUP4FAQk/qwAfgQkAVQAAAABAAAAAAAAAAAAAAAgAAAAZAAAAlgAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAwAAAAMAAAAcAAEAAAAAAIQAAwABAAAAHAAEAGgAAAAWABAAAwAGtUO1lLgmwXXIZ+GD4hnmhOlS+BT//wAAtUO1lLgmwXXIZ+GD4hnmhOlS+BT//0q+SnZH3D6RN54ehB3vGYUWsgfvAAEAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABBgAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAACwBEAGEAdAC3AOUBJgF8AboB6wIBAAEAFP/sADIAFAACAAA3MxUUHhQoAAABADP/8gIlAsoAJAAAEwMzNjc2MzYWFRQGIyInJicjFhcWMzI3NjU0JiMmBwYHIzchNWkmThYqKDNOWmJLQiswBlEHS0JfakhNf2YxKi8eBBgBXALK/nYrFRYBXlZLYCAkRGI5M0FFbHOCARISJO9JAAACABgAAAJBAsoACgAOAAABARUhFTM1MzUjEQczESEBgP6YAWdOdHRRA/7eAsr+Jk6iokMB5Wv+hgAAAQBCAAACFwLKAAYAABMVIQEzATVCAYH+9lcBBwLKS/2BAodDAAABADP/8gImAtgAKwAAASIHBgczNjYXNhcWFAYjIxUzNhYUBwYjJicmJyMWFxYXMjY1NCcmJzY1NCYBM2Y/QgpRB1JIRiclS0g3OktTKy5NQy01A1MJTEBmb4kkIT91fQLYOjpoSE4BASQheEFAAUh/KiwBJCxUeD8zAX1hPyoqEyh4WmgAAAIAMv/yAiYC2QAMABkAAAEmBwYQFxYgNzYQJyYHMhcWFAcGIicmNDc2ASyBQDk5QAEAQjk5Qn9gKh8fKsAqHh4qAtgBcmD+vGBxcWABRGByR2dI+kpmZkr6SGcAAgAz//ICJgLZABsAKAAAASIHBhUUFxYXNjY0JiMiBwYHIyc0NzYXNhczJgM2FxYUBwYHIicmNDYBNnlHQz5CgmmIfWY/MDIbBAEvMFR8GFEeyUktLC0tSEotLV4C2HBrq6NcYAEBi9KDHx44GnpOVAEBe8D+tgEwLZgzMAEzMJZfAAMAKv/yAi4C2AAfACwAOAAAASIHBhUUFxYXFQYHBhUUFjI3NjU0JyYnNTY3NjU0JyYHMhcWFAcGIicmNDc2EzIXFhQHBiImNDc2ASxwPzobHDk4JyqG90VCKic4Nx4bOj9wSywlISinJyImKk1WMCsrL65aLC4C2Do1TjknKhQCDjAzRV90OzlfRTMwDgIUKic5TjU6QychayInJyJrISf+wysngCcqUYAnKwACADP/8gImAtgAHAAoAAABIgYVFBcWMzY2NzMXFAcGIyInIxYzNjc2NTQnJgcyFxYUBiMiJjU0NgEkaYg9P2c/YhsEAS8xU34XUB3HeEhDP0J/Si0sXkVLV1kC2ItqZ0FEAT42GnhQU3q/AW9sqqZaYEUzMJVgXUtOYgAAAQA+AAACGgLYAB0AAAEiBgczNjc2FzIWFRQHBgcGBwYVITUhNjc2NzY0JgE2bIUBUgIqJ0pGTjccVHEqRwHc/okUiG8lRoAC2I94XzAzAUdCRTsdPE4xT2JJSFxMJ0u7cgABAG8AAAFpAsoACQAAAQYGBxU2NxEzEQEpI2YxZUNSAsooPg5SHkT9mgLKAAAAAAASAN4AAQAAAAAAAAAXAAAAAQAAAAAAAQAMABcAAQAAAAAAAgAHACMAAQAAAAAAAwAUACoAAQAAAAAABAAUACoAAQAAAAAABQALAD4AAQAAAAAABgAUACoAAQAAAAAACgArAEkAAQAAAAAACwATAHQAAwABBAkAAAAuAIcAAwABBAkAAQAYALUAAwABBAkAAgAOAM0AAwABBAkAAwAoANsAAwABBAkABAAoANsAAwABBAkABQAWAQMAAwABBAkABgAoANsAAwABBAkACgBWARkAAwABBAkACwAmAW9DcmVhdGVkIGJ5IGZvbnQtY2Fycmllci5QaW5nRmFuZyBTQ1JlZ3VsYXIuUGluZ0ZhbmctU0MtUmVndWxhclZlcnNpb24gMS4wR2VuZXJhdGVkIGJ5IHN2ZzJ0dGYgZnJvbSBGb250ZWxsbyBwcm9qZWN0Lmh0dHA6Ly9mb250ZWxsby5jb20AQwByAGUAYQB0AGUAZAAgAGIAeQAgAGYAbwBuAHQALQBjAGEAcgByAGkAZQByAC4AUABpAG4AZwBGAGEAbgBnACAAUwBDAFIAZQBnAHUAbABhAHIALgBQAGkAbgBnAEYAYQBuAGcALQBTAEMALQBSAGUAZwB1AGwAYQByAFYAZQByAHMAaQBvAG4AIAAxAC4AMABHAGUAbgBlAHIAYQB0AGUAZAAgAGIAeQAgAHMAdgBnADIAdAB0AGYAIABmAHIAbwBtACAARgBvAG4AdABlAGwAbABvACAAcAByAG8AagBlAGMAdAAuAGgAdAB0AHAAOgAvAC8AZgBvAG4AdABlAGwAbABvAC4AYwBvAG0AAAIAAAAAAAAADgAAAAAAAAAAAAAAAAAAAAAAAAAAAAsACwAAAQYBBQEIAQQBCwEHAQkBCgEDAQIHdW5pYjU5NAd1bmllNjg0B3VuaWU5NTIHdW5pYjgyNgd1bmliNTQzB3VuaWMxNzUHdW5pZjgxNAd1bmllMTgzB3VuaWUyMTkHdW5pYzg2Nw=="
font_data = base64.b64decode(base64_data)
# 将字节数据保存为字体文件
with open("font.woff", "wb") as f:
f.write(font_data)
# 使用 fontTools 加载字体文件
font = TTFont("font.woff")
font.saveXML('font.xml')
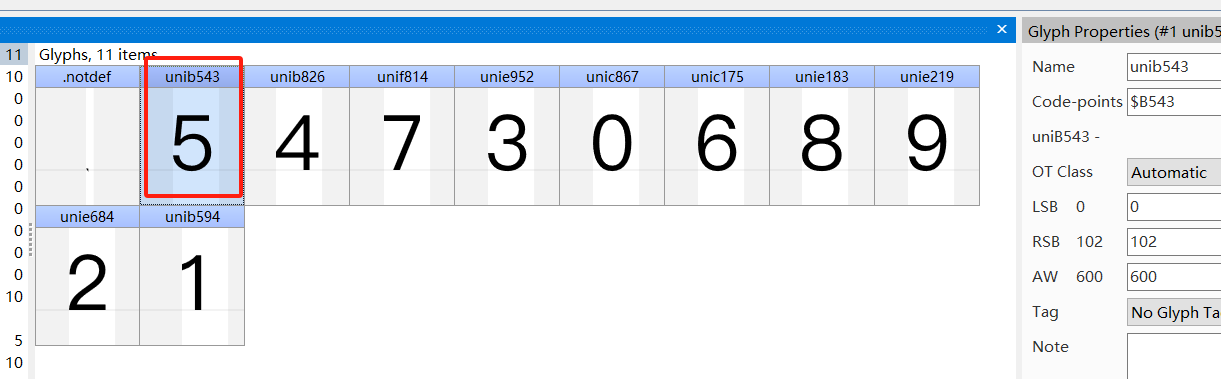
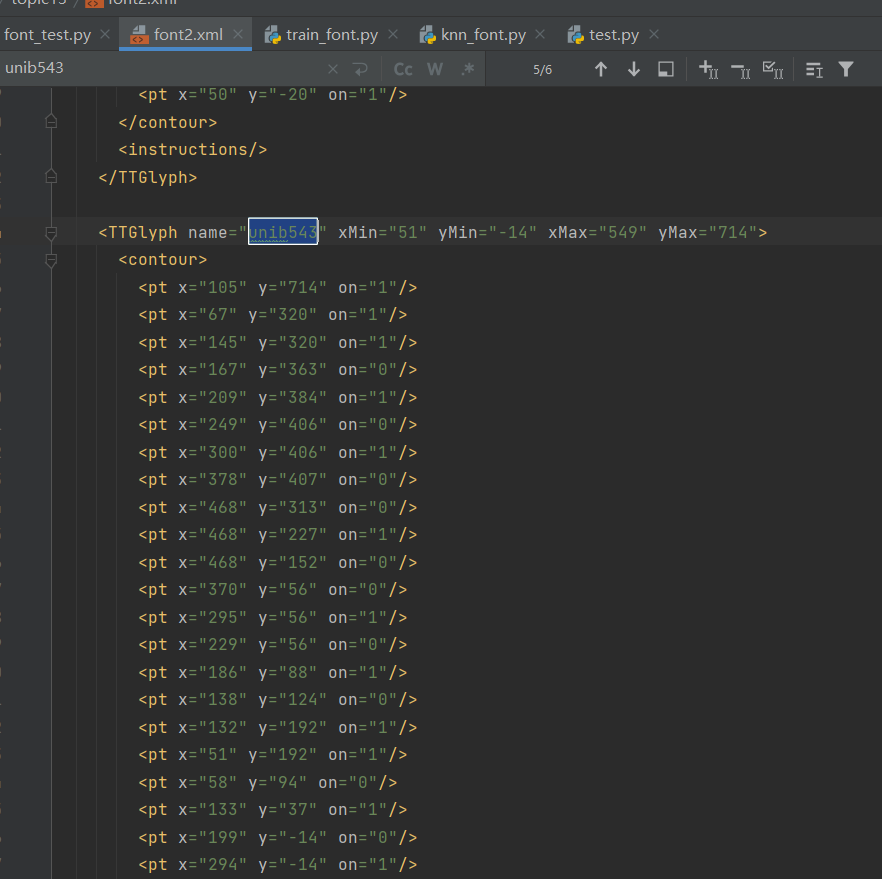
其实就是 woff 字体文件,如果有 fontCreator,可以打开此字体文件查看。如图:5 对应 unib543,在 font.xml 中也可以看到对应轨迹的生成坐标:
接下来可以使用k近邻算法训练还原映射关系,(具体我也不是很懂)根据网上大佬的代码修改后适配本题,具体如下:
先通过上方代码手动保存5份字体文件到本地,然后执行如下代码测试:
font_test.py
from io import BytesIO
from pathlib import Path
import requests
import json
import base64
from fontTools.ttLib import TTFont
from knn_font import Classify
# _woff_path = Path(__file__).absolute().parent/"fonts"/"test.ttf"
_classify = Classify()
def get_map_test():
data = {
'page': '6'
}
response = requests.post(url='https://www.python-spider.com/api/challenge13', data=data, cookies={'sessionid': 你的id})
base64_woff_data = json.loads(response.text)['woff']
font_content = base64.b64decode(base64_woff_data)
with open('./fonts/test.woff', 'wb') as f:
f.write(font_content)
return get_map(font_content)
# 获取映射关系dict
def get_map(font_content):
font = TTFont(BytesIO(font_content))
glyf_order = font.getGlyphOrder()[1:]
info = []
for g in glyf_order:
coors = font['glyf'][g].coordinates
coors = [_ for c in coors for _ in c]
info.append(coors)
map_li = map(lambda x: str(int(x)), _classify.knn_predict(info))
uni_li = map(lambda x: x.replace('uni', '&#x'), glyf_order)
return dict(zip(uni_li, map_li))
if __name__ == '__main__':
print(get_map_test())
train_font.py
from fontTools.ttLib import TTFont
def get_coor_info(font, cli):
glyf_order = font.getGlyphOrder()[1:]
info = list()
for i, g in enumerate(glyf_order):
coors = font['glyf'][g].coordinates
coors = [_ for c in coors for _ in c]
coors.insert(0, cli[i])
info.append(coors)
return info
def get_font_data():
font_1 = TTFont(r'./fonts/1.woff')
cli_1 = [0, 4, 7, 2, 5, 8, 6, 3, 1, 9]
coor_info_1 = get_coor_info(font_1, cli_1)
font_2 = TTFont(r'./fonts/2.woff')
cli_2 = [9, 7, 1, 0, 2, 6, 8, 3, 5, 4]
coor_info_2 = get_coor_info(font_2, cli_2)
font_3 = TTFont(r'./fonts/3.woff')
cli_3 = [4, 7, 0, 8, 6, 2, 1, 5, 3, 9]
coor_info_3 = get_coor_info(font_3, cli_3)
font_4 = TTFont(r'./fonts/4.woff')
cli_4 = [2, 7, 1, 5, 3, 6, 0, 9, 8, 4]
coor_info_4 = get_coor_info(font_4, cli_4)
font_5 = TTFont(r'./fonts/5.woff')
cli_5 = [1, 6, 3, 8, 0, 5, 9, 2, 4, 7]
coor_info_5 = get_coor_info(font_5, cli_5)
infos = coor_info_1 + coor_info_2 + coor_info_3 + coor_info_4 + coor_info_5
return infos
knn_font.py
import numpy as np
import pandas as pd
from train_font import get_font_data
from sklearn.impute import SimpleImputer
from sklearn.neighbors import KNeighborsClassifier
class Classify:
def __init__(self):
self.len = None
self.knn = self.get_knn()
def process_data(self, data):
imputer = SimpleImputer(missing_values=np.nan, strategy='mean')
return pd.DataFrame(imputer.fit_transform(pd.DataFrame(data)))
def get_knn(self):
data = self.process_data(get_font_data())
x_train = data.drop([0], axis=1)
y_train = data[0]
knn = KNeighborsClassifier(n_neighbors=1)
knn.fit(x_train, y_train)
self.len = x_train.shape[1]
return knn
def knn_predict(self, data):
df = pd.DataFrame(data)
data = pd.concat([df, pd.DataFrame(np.zeros(
(df.shape[0], self.len - df.shape[1])), columns=range(df.shape[1], self.len))])
data = self.process_data(data)
y_predict = self.knn.predict(data)
return y_predict
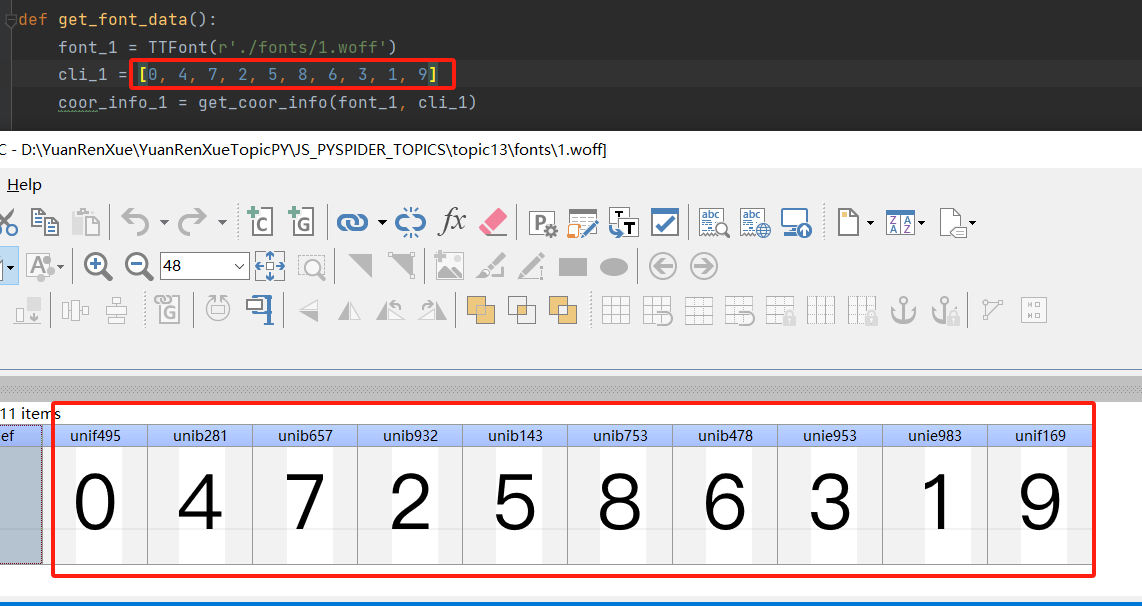
train_font中的get_font_data方法下的数组根据实际情况填写,如我的1.woff, 经FontCreator查看,如下:
项目目录如下:
然后运行 font_test.py,可以成功获取映射关系:

接下来就可以通过 font_test 的 get_map 方法获取正确的映射了。最终的参考代码如下:
topic13_.py
import requests
import json
import base64
import time
from font_test import get_map
url = 'https://www.python-spider.com/api/challenge13'
cookies = {
'sessionid': 你的id
}
total_num = 0
i = 1
while i < 101:
data = {
'page': str(i)
}
response = requests.post(url, cookies=cookies, data=data)
print('第 {} 页'.format(i))
print(response.status_code, response.text)
if response.status_code == 200 and json.loads(response.text)['state'] == 'success':
base64_woff_data = json.loads(response.text)['woff']
font_content = base64.b64decode(base64_woff_data)
result_dict = get_map(font_content)
data_list = json.loads(response.text)['data']
for data in data_list:
value_list = data['value'].split(' ')
num_ = ''
for value in value_list:
if value:
num_ += result_dict[value]
# print(num_)
total_num += int(num_)
# print(total_num)
i += 1
else:
time.sleep(1)
print(total_num)
第14题:js_fuck核心代码加密
抓包分析发现,需逆向uc参数,根据调用堆栈很容易找到uc的位置:
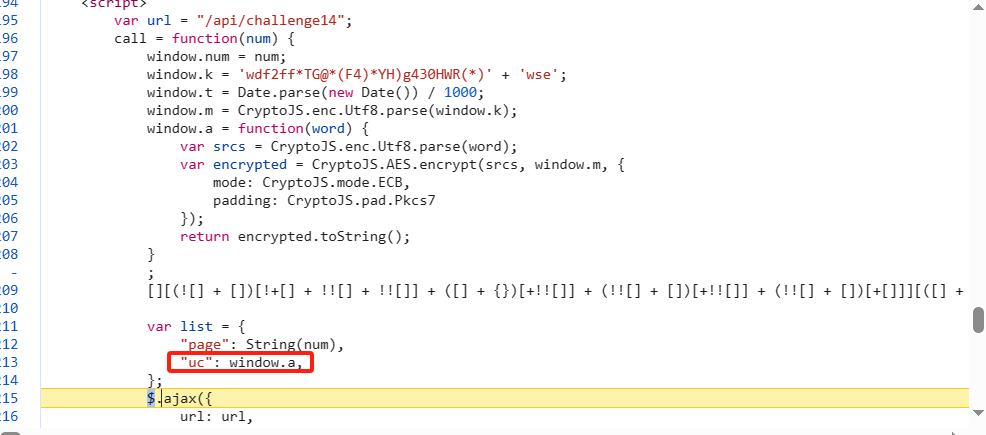
可以看到uc = window.a,但是上方多了一行由若干括号、感叹号和加号构成的内容,此为js_fuck加密,可通过 v_jstools插件的解混淆功能处理(插件地址:https://github.com/cilame/v_jstools)
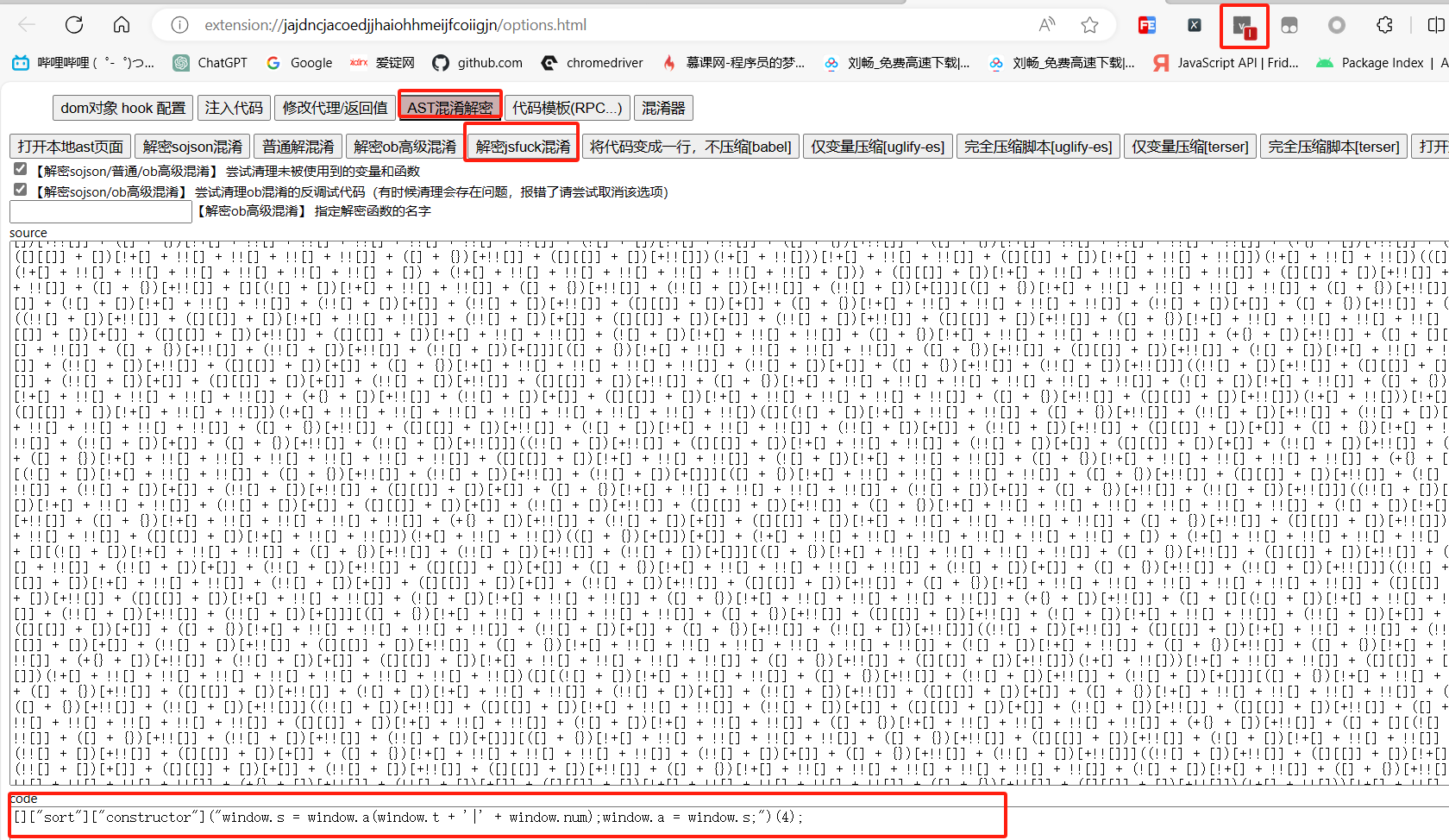
如果不使用插件,可以将代码复制到本地,然后通过控制台打印一步步替换,最终也能得到结果。
可以看到,window.a 是 window.t + '|' + window.num 经AES_ECB加密后得到的,即 uc值,最终参考代码:
import requests
import urllib3
import time
import json
import base64
from Crypto.Cipher import AES
urllib3.disable_warnings()
def aes_encode(data, key):
while len(data) % 16 != 0: # 补足字符串长度为16的倍数
data += (16 - len(data) % 16) * chr(16 - len(data) % 16)
data = str.encode(data)
aes = AES.new(str.encode(key), AES.MODE_ECB) # 初始化加密器
return str(base64.encodebytes(aes.encrypt(data)), encoding='utf8').replace('\n', '') # 加密
key = 'wdf2ff*TG@*(F4)*YH)g430HWR(*)wse'
url = 'https://www.python-spider.com/api/challenge14'
cookies = {
'sessionid': 你的id
}
session = requests.Session()
total_num = 0
page = 1
while page < 101:
uc = aes_encode(str(int(time.time())) + '|' + str(page), key)
# print(uc)
data = {
'page': page,
'uc': uc
}
response = session.post(url, cookies=cookies, data=data)
print('第 {} 页'.format(page))
print(response.status_code, response.text)
data_list = json.loads(response.text)['data']
for data in data_list:
total_num += int(data['value'])
time.sleep(0.5)
page += 1
print(total_num)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号