

提升node.js中使用redis的性能
问题初现
某基于node.js开发的业务系统向外提供了一个dubbo服务,提供向第三方缓存查询、设置多项业务数据并聚合操作结果。在QPS达到800时(两台虚拟机,每台机器4Core8G4node进程),在监控平台上出现了非常多的slow rt警告,平均接口响应达到60+ms,请求报警率达到80%+。
为找到造成该服务吞吐量过低的罪魁祸首,业务人员在请求日志中打点了所有查询缓存的操作,结果显示每个请求查询缓存耗时在50-100ms之间跳动。查询了redis-server的监控数据发现,不存在server端的慢查询,在整个监控区间内服务端处理时间在40us徘徊,因此排除了redis-server的处理能力不足原因;
通过登录内网机器进行不断测试到对应redis server机器的端到端时延发现内部局域网的带宽、时延与抖动足够正常,都不是造成该问题的原因。
因此,错误原因定位到了调用redis client的业务代码以及redis client的I/O性能。
本文中提到的node redis client采用的基于node-redis封装的二方包,因此问题排查也基于node-redis这个模块。
瓶颈在哪
为了在本地模拟线上环境的并发,可以做一个不是很严谨的测试:
async ()=>{
let dd = Date.now()
let arr = []
for(let i=0;i<200;i++){
arr.push(new Promise((res,rej)=>{
let hrtime = process.hrtime();
client.send_command('get',['key'], function(e,r) {
let diff = process.hrtime(hrtime);
let cost = (diff[0] * NS_PER_SEC + diff[1])/1000000;
console.log(`final: ${cost} ms`)
res();
});
}));
}
await Promise.all(arr)
console.log('ops/sec:',200*1000/(Date.now() - dd),Date.now() - dd);
}
会发现每个请求的rt都会比前一个请求来的大
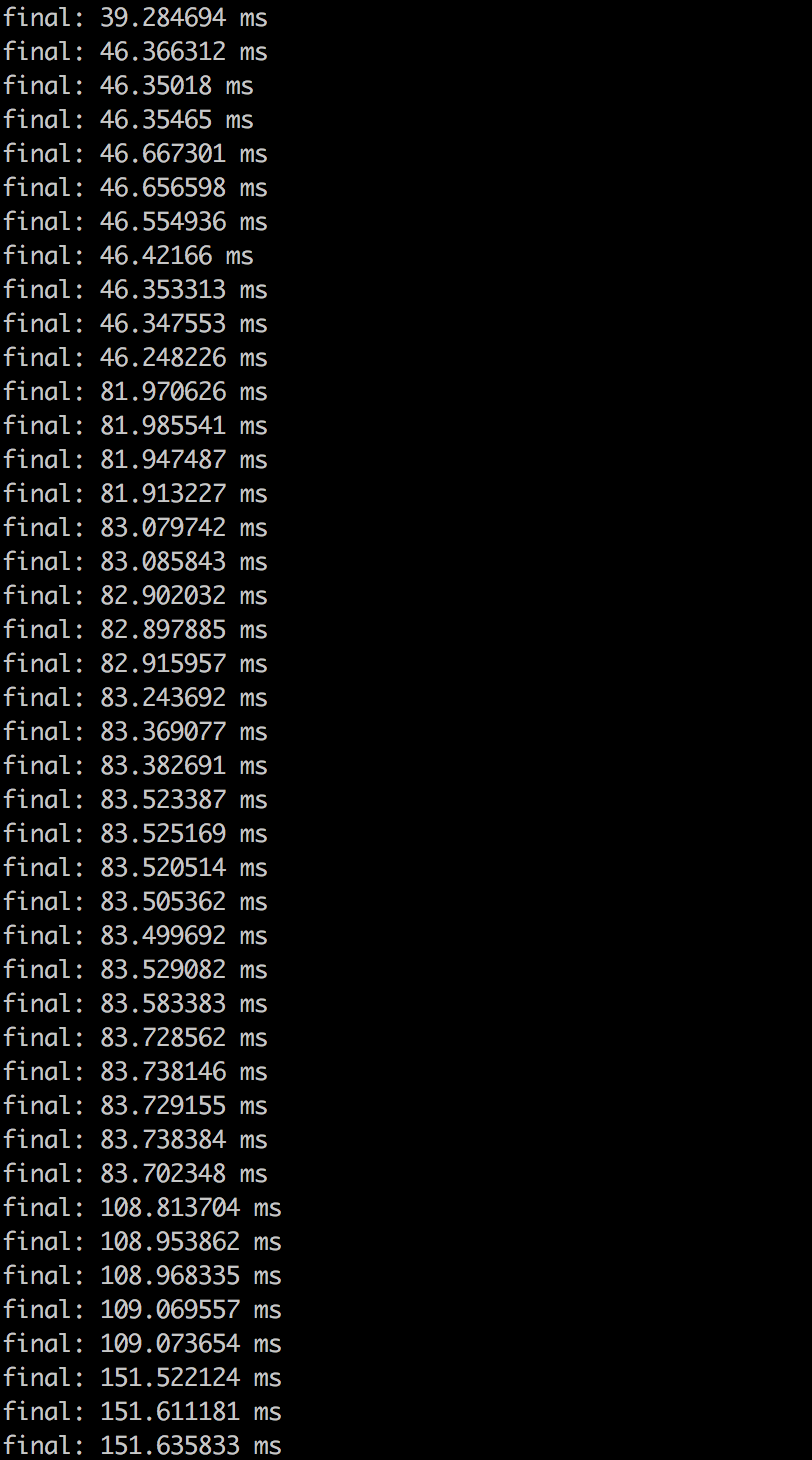
最后一个请求的rt竟然达到了257 ms!虽然在node单进程像示例代码那样并发执行200次get请求是非常少见而且愚蠢的(关于示例代码的优化在在下节讲述),但是针对这个示例必须找到请求delay增加的原因。
为此继续分析,redis client采用的是单连接模式,底层采用的非阻塞网络I/O,socket.recv()在node层面是通过监听socket的data事件完成的,因此先分析redis-client读性能如何:
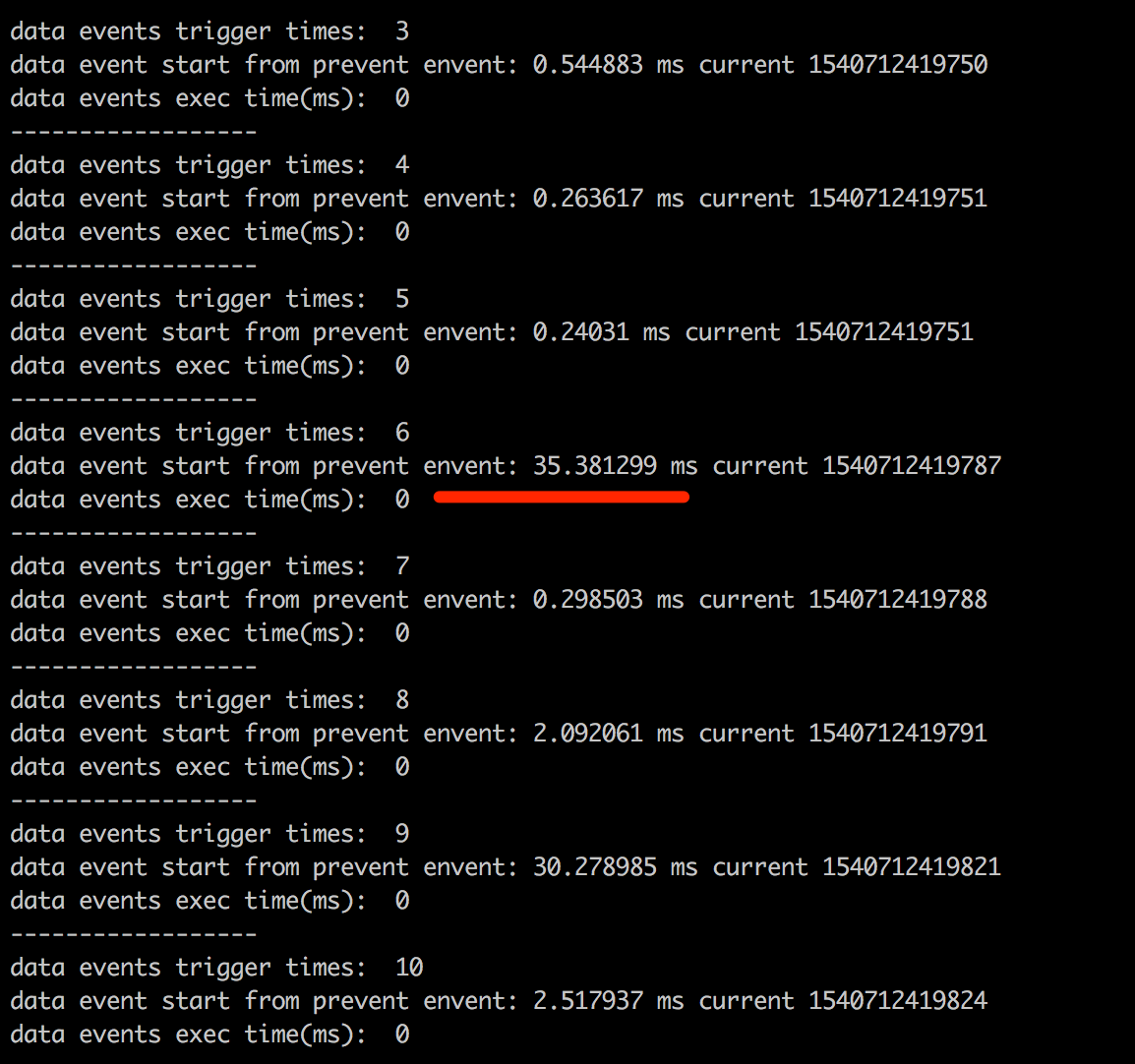
上图每段日志的含义分别表示:
- data events trigger times: socket data事件触发的次数
- data event start from prevent event: data事件距离上次触发的时间间隔
- data events exec time(ms): 本次事件处理函数执行时间
上图只是截取了最初的请求日志,发现当第6次触发data事件时,竟然距离上次触发事件隔了35ms,在随后的请求中会复现这种现象,因此这也就导致了在并发200次查询请求时,每个请求的rt都会随之增大,并且有些响应之间间隔了30ms。
从表象看造成问题在于redis-server发送的响应不是一个数据块,而是多个数据块导致触发socket的data事件过多,而且data事件抖动过大导致响应之间存在30ms的突变(data事件是无法同时触发两次的,每次data事件处理函数执行完后才能继续触发下一个data事件);当然也有可能和socket写入(即发送req)有关,如缓存请求等。为了继续探查,监控与socket写入相关的接口 _write(),记录每次写入socket的数据时距离上一次写入的间隔:
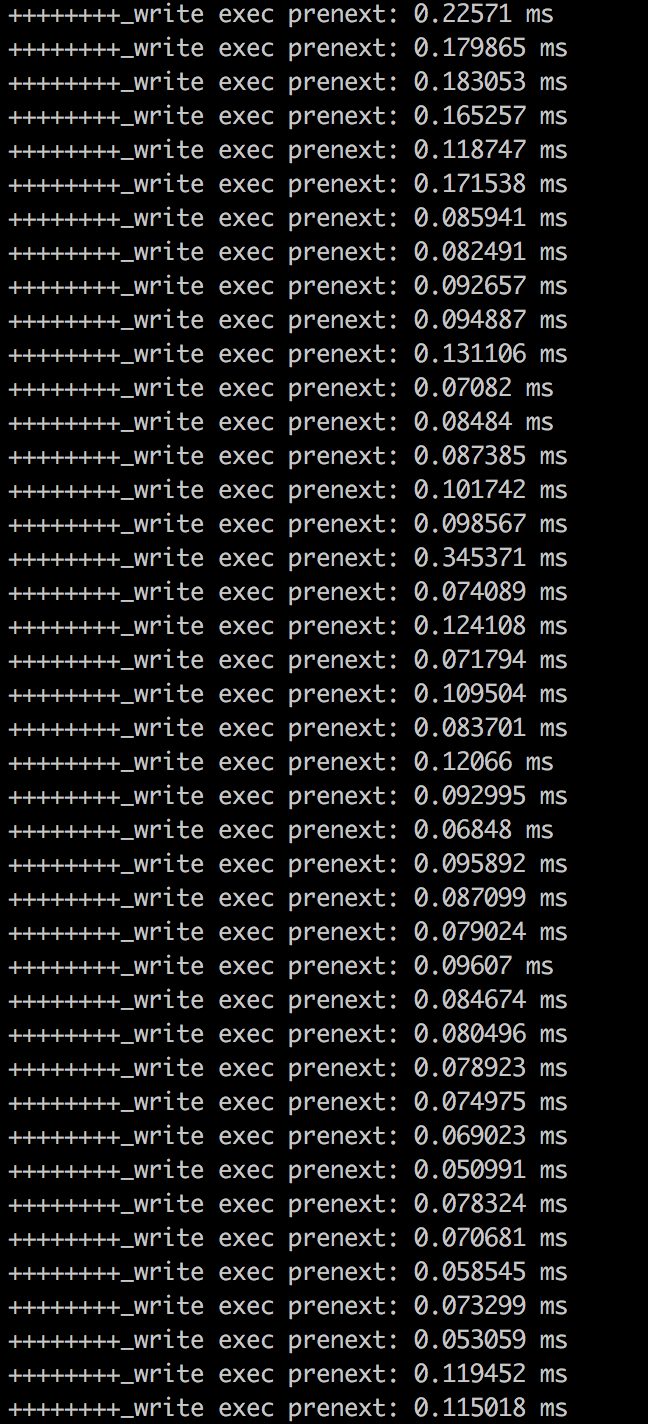
可见,在使用redis-client发送请求时,write方法也不是瓶颈。
采用同样方法,对socket的push()(该方法触发socket的data事件)进行监控,发现socket的数据到达间隔抖动非常大:
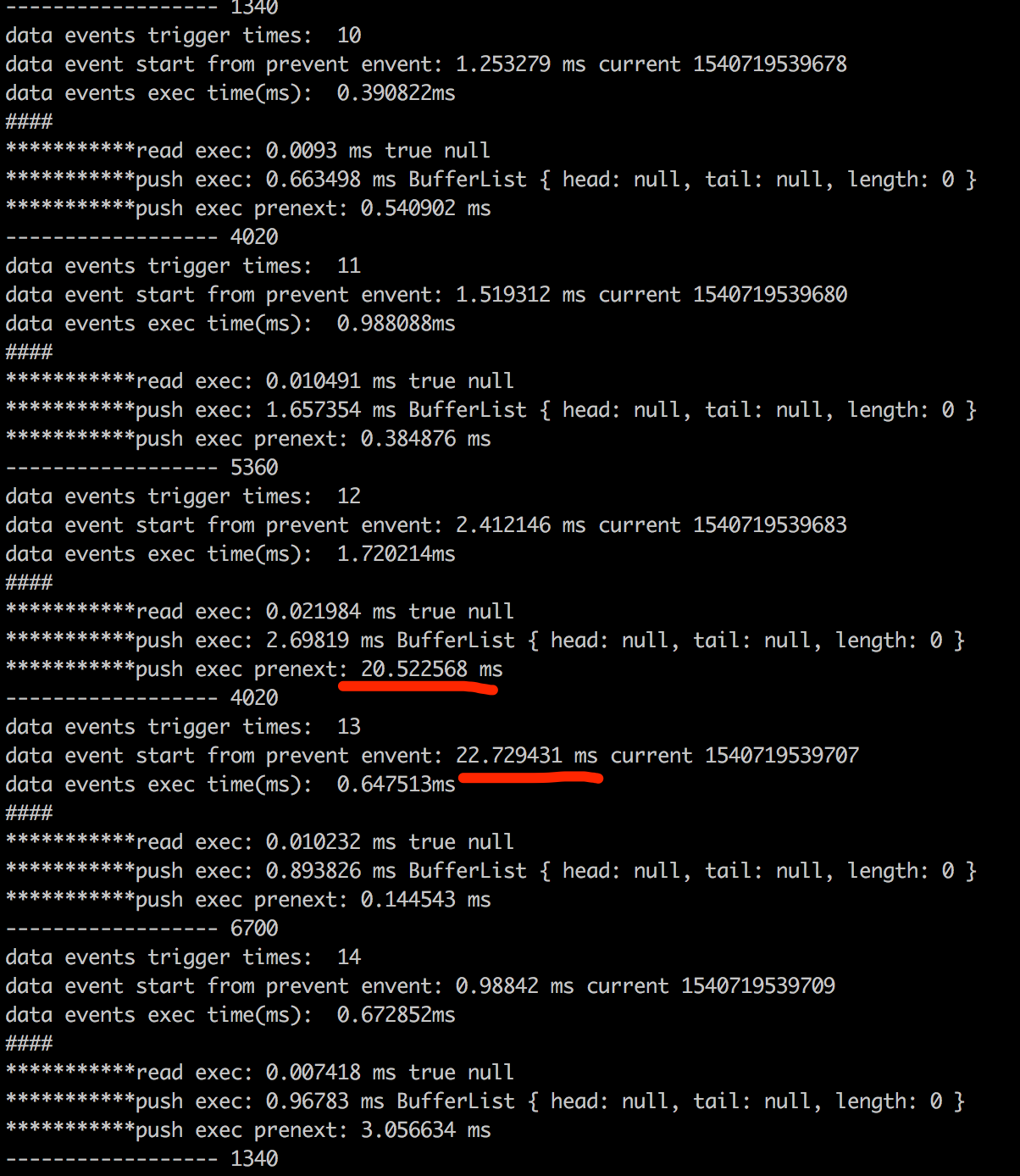
因此,造成redis-client并发请求下响应rt抖动较大的情况与单连接下响应数据到达本地的时刻有关,具体可能与底层libuv的缓存策略有关(笔者并未再往下探查)。
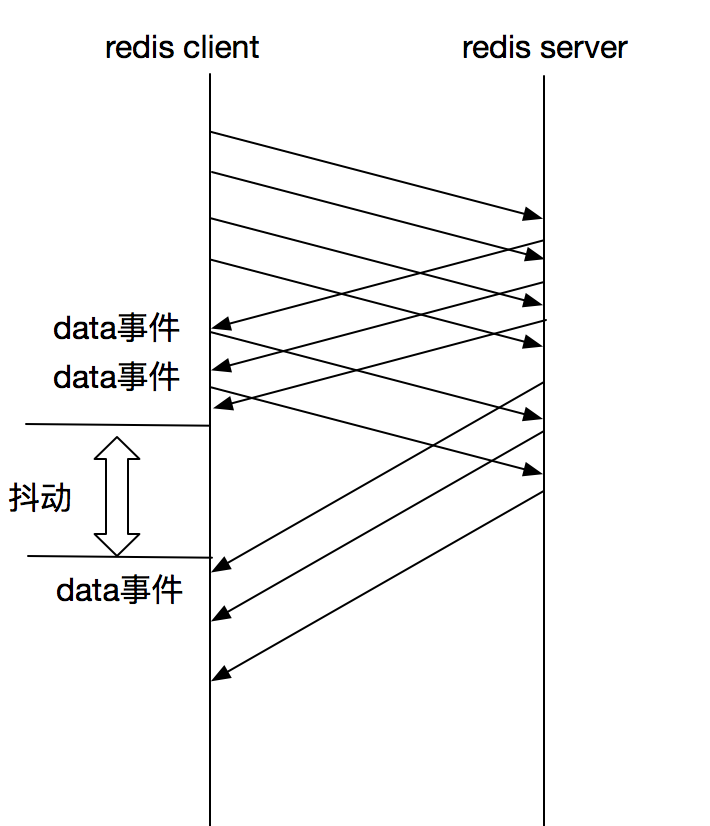
在一个node实例中通过一个单连接与redis server通信,在高并发下会出现排队等待响应的情况,并且有可能会出现响应rt雪崩效应(如上文demo所示),因此需要尽可能减少或缓存客户端的请求数量,进行批量发送。
调优
1. pipeline(涉及到写模式及时序)
2. script
对于pipeline方式,redis server是默认支持的。通俗点说,pipeline可以合并一系列请求一次发送,并将这些请求对应的结果一次性拿到。因此这种方式可以有效减少响应次数,从而减少socket触发data事件的次数,尽可能快的拿到响应体。
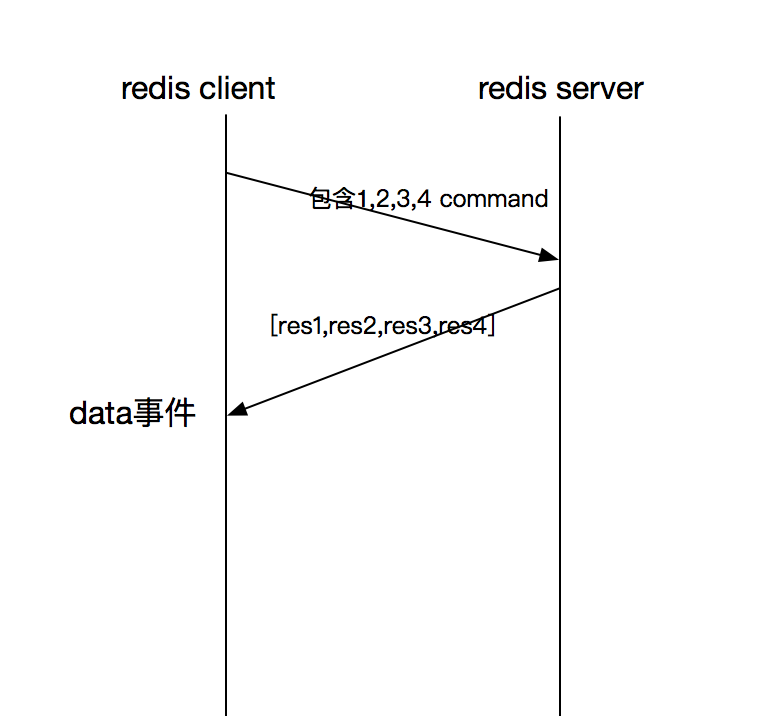
需要强调的是,在node中,是通过底层socket的_writev实现一次发送多条redis命令的,_writev又叫做聚合写,它支持将不同缓冲区的多条数据通过一次系统调用写入目标流,因此性能上比每次写单个缓冲区的单个数据来的好得多。在node的Writeable对象中,有cork和uncork方法,通过这两个方法可以在node write stream中缓存多条数据,通过_writev一次性发送。
关于 _writev的数据结构
redis在拿到数据后,根据resp协议解析出命令集合缓存在队列中,直到收到exec命令,开始批量执行命令集,并将所有命令执行的结果转换为数组返回给redis client。这样就可以通过一次写、一次读实现高性能I/O。
async ()=>{
let dd = Date.now()
let batch = await client.batch();
for(let i=0;i<200;i++){
batch.get('vdWeex_com.koudai.weidian.buyer_1');
}
let rt = await batch.exec();
process.exit();
}
而对于script方法,则是由redis client传入script命令,在server端执行script逻辑,批量执行命令,并返回结果。同样是一次写、一次读。
收获
1. node socket默认采用writev 集合写
2. 无依赖批量请求采用pipeline
3. eval script解决有依赖批量请求
4. redis高性能体现在服务端处理能力,但瓶颈往往出现在客户端,因此增强客户端I/O能力与并发并行多客户端才是高并发解决方案

 浙公网安备 33010602011771号
浙公网安备 33010602011771号