tessaract ocr简介
Tesseract的历史
Tesseract是一个开源的OCR引擎,惠普公司的布里斯托尔实验室在1984-1994年开发完成。起初作为惠普的平板扫描仪的文字识别引擎。Tesseract在1995年UNLV OCR字符识别准确性测试中拔得头筹,受到广泛关注。后来HP放弃了OCR市场。在1994年以后,Tesseract的开发就停止了。
在2005年,HP将Tesseract贡献给开源社区。美国内华达州信息技术研究所获得该源码,同时,Google开始对Tesseract进行功能扩展及优化。目前,Tesseract作为开源项目发布在Google Project上,重获新生。Tesseract的最新版本是3.02,它支持60种以上的语言,提供一个引擎和一个命令行工具,官方下载地址:谷震平的传送门。
Tesseract架构解析
Tesseract引擎功能强大,概括地可以分为两部分:
图片布局分析
字符分割和识别
图片布局分析,是字符识别的准备工作。工作内容:通过一种混合的基于制表位检测的页面布局分析方法,将图像的表格、文本、图片等内容进行区分。
字符分割和识别是整个Tesseract的设计目标,工作内容最为复杂。首先是字符切割,Tesseract采用两步走战略:
利用字符间的间隔进行粗略的切分,得到大部分的字符,同时也有粘连字符或者错误切分的字符。这里会进行第一次字符识别,通过字符区域类型判定,根据判定结果对比字符库识别字符。
根据识别出来的字符,进行粘连字符的分割,同时把错误分割的字符合并,完成字符的精细切分。
当然,还有另一种说法—-细致地可以分为四个部分:
- 分析连通区域
- 找到块区域
- 找文本行和单词
- 得出(识别)文本
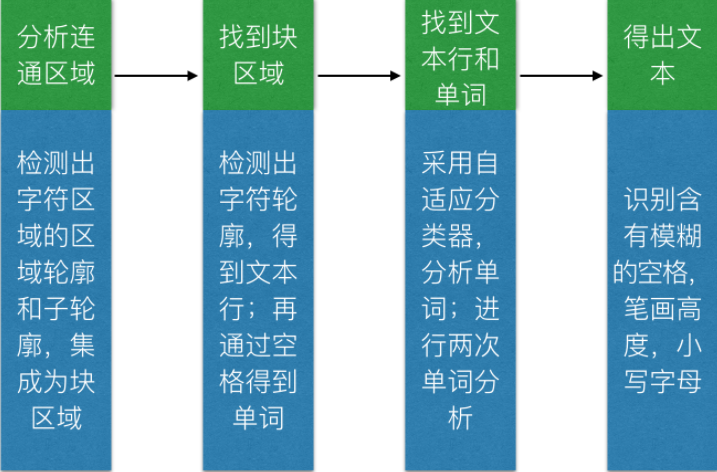
图 Tesseract主要四个部分(仅代表谷震平个人观点,请勿抄袭)
举个详细的例子:
PS:此例也是Ray Smith的文章(Adapting the Tesseract Open Source OCR Engine for Multilingual OCR)中给出的,具有代表性。
不想贴文字,直接上图:
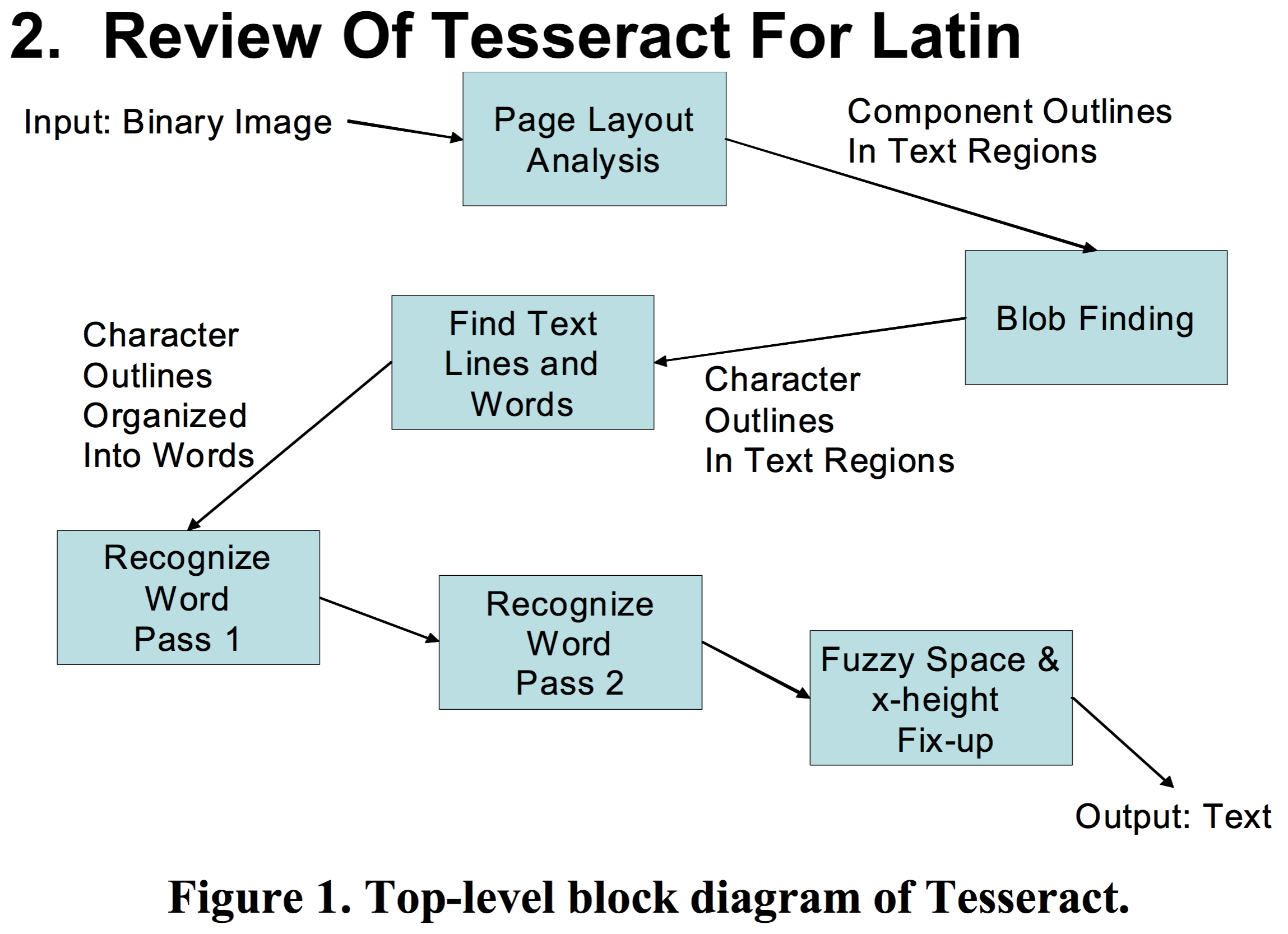
Tesseract的架构并不是我这三言两语能讲清楚地,欢迎留言补充纠正!谢谢合作!
Tesseract实现原理
原理这块相当复杂,这篇blog只谈TessBaseAPI相关的东西。后续系列再撰文补充。
TessBaseAPI是Tesseract引擎的一个核心类,关于这个类的源代码请戳这里:谷震平的传送门。我们来理解下这个类函数的运作机制,借此联想下Tesseract引擎的实现原理。机制如下:
- 调用Init()方法,即对引擎初始化
- 调用setImage()方法,设置图形流的信息
- 通过getUTF8Text()方法获得text信息
- 调用recognizedText类,判断text的正确性,然后输出。这里,会调用自有的trim()方法和length()方法做一些相应的处理。
---------------------
作者:谷震平
来源:CSDN
原文:https://blog.csdn.net/guzhenping/article/details/51019010
版权声明:本文为博主原创文章,转载请附上博文链接!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号