

2023数据采集与融合技术作业一
作业①
1.大学排名爬取
要求
用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020 )的数据,屏幕打印爬取的大学排名信息。
| 排名 | 学校名称 | 省市 | 学校类型 | 总分 |
|---|---|---|---|---|
| 1 | 清华大学 | 北京 | 综合 | 852.5 |
| 2...... |
代码
点击查看代码
import requests
from bs4 import BeautifulSoup
import re
# 目标网页:上海软科中国大学排名
url = "http://www.shanghairanking.cn/rankings/bcur/2020"
# 设置请求头,模拟浏览器访问
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/85.0.4183.121 Safari/537.36"
}
# 发送请求,编码为utf-8
response = requests.get(url, headers=headers)
response.encoding = "utf-8"
# 使用 BeautifulSoup 解析网页内容,指定解析器为 html.parser
soup = BeautifulSoup(response.text, "html.parser")
# 选择表格中的所有行(tr),tbody 表示表格主体
rows = soup.select("tbody tr")
# 打印表头
print(f"{'排名':<5}{'学校名称':<15}{'省市':<10}{'学校类型':<10}{'总分':<10}")
# 遍历每一行数据,获取当前行中的所有单元格,确保这一行至少有 5 列数据(排名、学校、地区、类型、分数)
for row in rows:
cols = row.find_all("td")
if len(cols) >= 5:
# 提取排名,去掉多余空格
rank = cols[0].get_text(strip=True)
# 学校名称可能在 <a><span> 标签中,如果存在 span 标签,直接取文本,否则直接取 td 的文本,并用正则去掉非中文字符
span = cols[1].select_one("a span")
if span:
name = span.get_text(strip=True)
else:
raw_name = cols[1].get_text(strip=True)
name = re.sub(r"[^\u4e00-\u9fff]", "", raw_name)
# 去掉学校名称中的“ 双一流 ”字样
# 去掉“ 双一流 ”以及可能存在的空格
name = re.sub(r"\s*双一流\s*", "", name)
# 提取省市、学校类型、总分
province = cols[2].get_text(strip=True)
category = cols[3].get_text(strip=True)
score = cols[4].get_text(strip=True)
# 格式化输出每一行数据
print(f"{rank:<5}{name:<15}{province:<10}{category:<10}{score:<10}")
实验结果

2.心得体会
这段代码通过 requests 获取网页内容,用 BeautifulSoup 解析表格数据,再通过ccs选择器获取表格中的数据行,逐行提取需要的字段,最后用格式化输出整齐展示排名结果。在其中学会了运用find方法寻找tbody,同时结果发现学校名称有时包含额外的标签或“ 双一流 ”字样,我在事后运用re.sub将其去除,以达到格式要求。
作业②
1.商品价格爬取实验
要求
用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
| 序号 | 价格 | 商品名 |
|---|---|---|
| 1 | 65.00 | xxx |
| 2...... |
代码
点击查看代码
import requests
import re
import random
# 设置请求的URL,搜索书包
url = "http://search.dangdang.com/?key=%CA%E9%B0%FC&act=input"
try:
# 发送请求,获取编码
r = requests.get(url)
r.encoding = r.apparent_encoding
except:
print("fail")
# 获取网页的HTML源码
html = r.text
# 使用正则表达式提取商品列表所在的<ul>标签块
m = re.search('<ul class="bigimg cloth_shoplist".*?</ul>', html, re.S)
if not m:
print("没找到商品")
# 将匹配到的<ul>部分HTML提取出来
html = m.group()
# 在<ul>中查找所有<li>标签
lis = re.findall("<li.*?</li>", html, re.S)
random.shuffle(lis)
i = 1
for li in lis:
# 提取价格信息和商品名称
p = re.search('<span class="price_n">¥(.*?)</span>', li)
t = re.search('title="(.*?)"', li)
if p and t:
price = "¥" + p.group(1)
name = t.group(1)
print(f"{i}. {name} —— {price}")
i += 1
实验结果

2.心得体会
在写代码时我原本想用淘宝和京东来进行爬取,结果却都被反爬导致没有结果,最后没有办法在查询网络后选择了当当网并成功爬取。这段代码中我选取了通过 requests 库向当当网发送搜索请求,获取“书包”的搜索结果页面源码,然后利用正则表达式提取商品列表ul中li的每个标签,从中解析出商品的价格和名称,并以“序号 商品 价格”的表格形式打印出来。
作业③
1.福大网页图片下载
要求
爬取一个给定网页(https://news.fzu.edu.cn/yxfd.htm)或者自选网页的所有JPEG、JPG或PNG格式图片文件,将自选网页内的所有JPEG、JPG或PNG格式文件保存在一个文件夹中
代码
点击查看代码
import re
import urllib.request
import os
# 要爬取的网页列表,共6页
pages = [
"https://news.fzu.edu.cn/yxfd.htm",
"https://news.fzu.edu.cn/yxfd/1.htm",
"https://news.fzu.edu.cn/yxfd/2.htm",
"https://news.fzu.edu.cn/yxfd/3.htm",
"https://news.fzu.edu.cn/yxfd/4.htm",
"https://news.fzu.edu.cn/yxfd/5.htm",
]
# 用来存储所有图片链接
allpics = []
# 遍历每个网页
for p in pages:
print("正在爬:", p)
# 构造请求
req = urllib.request.Request(p, headers={"User-Agent":"Mozilla/5.0"})
# 打开网页
res = urllib.request.urlopen(req)
# 读取网页内容
html = res.read().decode("utf-8","ignore")
# 使用正则表达式匹配所有 jpg 图片链接
pat = re.compile(r'src="([^"]+?\.jpg)"', re.IGNORECASE)
links = pat.findall(html)
print("找到", len(links), "张")
# 提取网页的域名部分
domain = re.match(r"(https?://[^/]+)", p).group(1)
newlinks = []
for l in links:
# 如果是完整的 http 链接,直接使用
if l.startswith("http"):
newlinks.append(l)
# 如果是以 / 开头的相对路径,加上域名
elif l.startswith("/"):
newlinks.append(domain + l)
# 否则认为是相对路径,加上当前页面所在目录
else:
newlinks.append(p.rsplit("/",1)[0] + "/" + l)
# 将处理好的链接加入总列表
allpics += newlinks
# 去重,避免重复下载相同图片
allpics = list(set(allpics))
print("总共", len(allpics), "张, 开始下载...")
# 下载图片并保存到 image 文件夹
i = 1
for u in allpics:
try:
fname = "image/img_" + str(i) + ".jpg"
# 下载图片
urllib.request.urlretrieve(u, fname)
print("ok:", fname)
i += 1
except:
# 如果下载失败,打印失败的链接
print("fail:", u)
结果

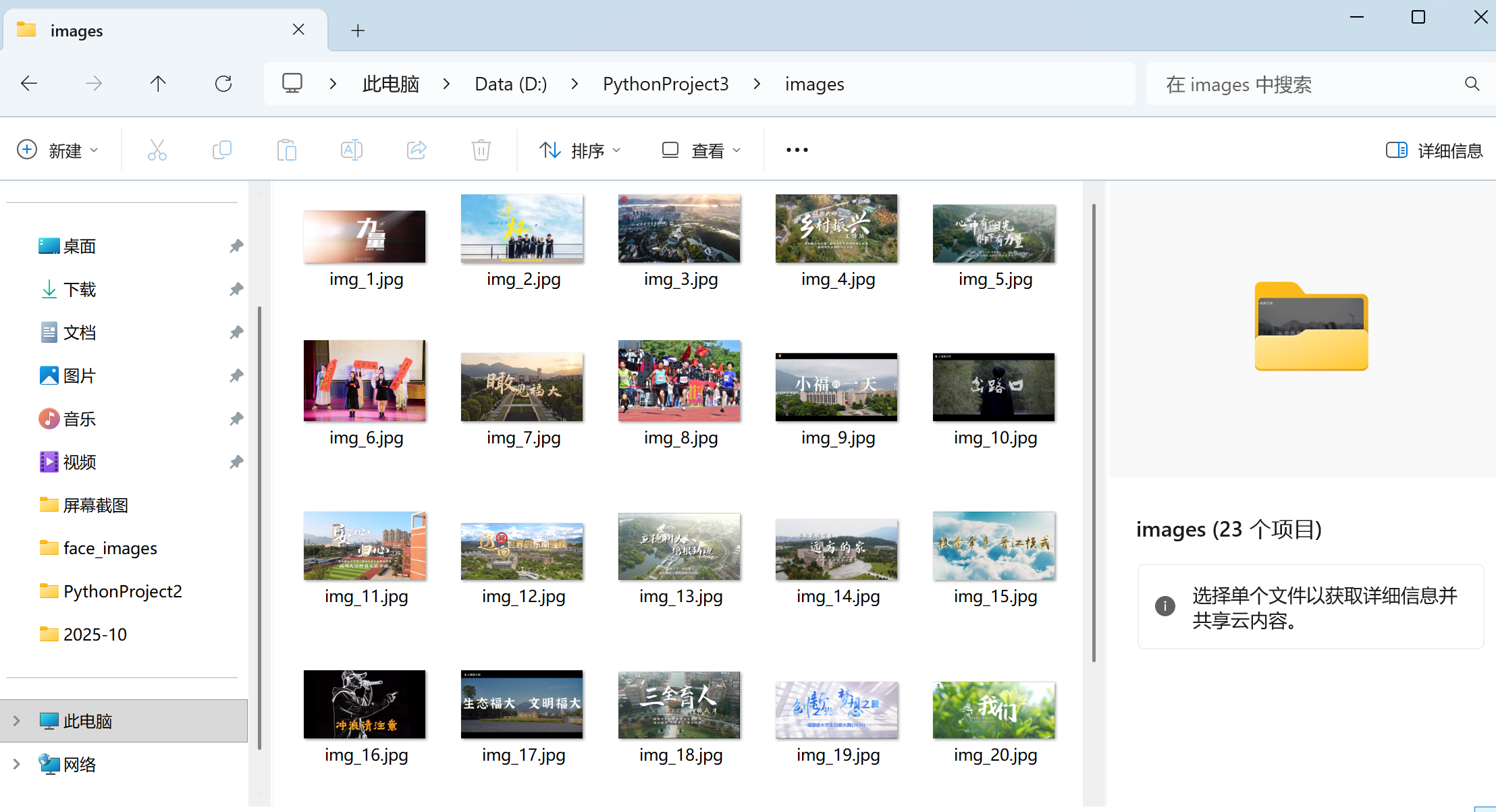
2.心得体会
在爬取图片时遇到了下载多张图片的问题,通过set进行去重后解决,同时爬取图片的链接不是标准的url,要加http。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号