

基本概念
关联分析是一种在大规模数据集中寻找有趣关系的非监督学习算法。这些关系可以有两种形式:频繁项集或者关联规则。频繁项集(frequent item sets)是经常出现在一块的物品的集合,关联规则(association rules)暗示两种物品之间可能存在很强的关系。
下图是一个乒乓球店的交易记录,〇表示顾客购买了商品。其中{底板,胶皮,浇水}就是一个频繁项集;从中可以找到底板->胶皮这样的关联规则:

支持度
怎样有效定义频繁和关联?其中最重要的两个概念是支持度和置信度。
支持度(support)从字面上理解就是支持的程度,一个项集的支持度(support)被定义为数据集中包含该项集的记录所占的比例。上图中{底板}的支持度=(5/6) * 100%。
这个概念其实经常在现实生活中出现,翻译成支持率似乎更好理解,典型的例子就是投票,比如英国脱欧的支持率为51.89%。
用数学去解释就是,设W 中有s%的事务同时支持物品集A和B,s%称为{A,B}的支持度,即:
support({A,B}) = num(A∪B) / W = P(A∩B)
num(A∪B)表示含有物品集{A,B}的事务集的个数,不是数学中的并集。
置信度
置信度(confidence)揭示了A出现时B是否一定出现,如果出现,则出现的概率是多大。如果A->B的置信度是100%,则说明A出现时B一定会出现(返回来不一定)。上图中底板共出现5次,其中4次同时购买了胶皮,底板->胶皮的置信度是80%。
用公式表示是,物品A->B的置信度=物品{A,B}的支持度 / 物品{A}的支持度:
Confidence(A->B) = support({A,B}) / support({A}) = P(B|A)
Apriori原理
假设我们在经营一家商品种类并不多的杂货店,我们对那些经常在一起被购买的商品非常感兴趣。我们只有4种商品:商品0,商品1,商品2和商品3。那么所有可能被一起购买的商品组合都有哪些?这些商品组合可能只有一种商品,比如商品0,也可能包括两种、三种或者所有四种商品。我们并不关心某人买了两件商品0以及四件商品2的情况,我们只关心他购买了一种或多种商品。
下图显示了物品之间所有可能的组合。为了让该图更容易懂,图中使用物品的编号0来取代物品0本身。另外,图中从上往下的第一个集合是Ф,表示空集或不包含任何物品的集合。物品集合之间的连线表明两个或者更多集合可以组合形成一个更大的集合。

前面说过,我们的目标是找到经常在一起购买的物品集合。我们使用集合的支持度来度量其出现的频率。一个集合的支持度是指有多少比例的交易记录包含该集合。如何对一个给定的集合,比如{0,3},来计算其支持度?我们遍历毎条记录并检查该记录包含0和3,如果记录确实同时包含这两项,那么就增加总计数值。在扫描完所有数据之后,使用统计得到的总数除以总的交易记录数,就可以得到支持度。上述过程和结果只是针对单个集合{0,3}。要获得每种可能集合的支持度就需要多次重复上述过程。我们可以数一下上图中的集合数目,会发现即使对于仅有4种物品的集合,也需要遍历数据15次。而随着物品数目的增加遍历次数会急剧增长。对于包含— 物品的数据集共有2N-1种项集组合。事实上,出售10000或更多种物品的商店并不少见。即使只出售100种商品的商店也会有1.26×1030种可能的项集组合。对于现代的计算机而言,需要很长的时间才能完成运算。
为了降低所需的计算时间,研究人员发现一种所谓的Apriori原理。Apriori原理可以帮我们减少可能感兴趣的项集。Apriori原理是说如果某个项集是频繁的,那么它的所有子集也是频繁的。上图给出的例子,这意味着如果{0,1}是频繁的,那么{0}、{1}也一定是频繁的。这个原理直观上并没有什么帮助,但是如果反过来看就有用了,也就是说如果一个项集是非频繁集,那么它的所有超集也是非频繁的,如下所示:

上图中,已知阴影项集{2,3}是非频繁的。利用这个知识,我们就知道项集{0,2,3} ,{1,2,3}以及{0,1,2,3}也是非频繁的。这也就是说,一旦计算出了{2,3}的支持度,知道它是非频繁的之后,就不需要再计算{0,2,3}、{1,2,3}和{0,1,2,3}的支持度,因为我们知道这些集合不会满足我们的要求。使用该原理就可以避免项集数目的指数增长,从而在合理时间内计算出频繁项集。
Apriori算法过程
关联分析的目标包括两项:发现频繁项集和发现关联规则。首先需要找到频繁项集,然后才能获得关联规则。
Apriori算法过程

发现频繁项集的过程如上图所示:
- 由数据集生成候选项集C1(1表示每个候选项仅有一个数据项);再由C1通过支持度过滤,生成频繁项集L1(1表示每个频繁项仅有一个数据项)。
- 将L1的数据项两两拼接成C2。
- 从候选项集C2开始,通过支持度过滤生成L2。L2根据Apriori原理拼接成候选项集C3;C3通过支持度过滤生成L3……直到Lk中仅有一个或没有数据项为止。
下面是一个超市的交易记录:

Apriori算法发现频繁项集的过程如下:

以上转于:https://www.cnblogs.com/bigmonkey/p/7405555.html
FP-Grwoth 算法过程
(1)在每一步产生侯选项目集时循环产生的组合过多,没有排除不应该参与组合的元素;
(2)每次计算项集的支持度时,都对数据集中的全部记录进行了一遍扫描比较,
(1)按以下步骤构造FP-树
原始事务数据库如下:
Tid | Items |
1 | I1,I2,I5 |
2 | I2,I4 |
3 | I2,I3 |
4 | I1,I2,I4 |
5 | I1,I3 |
6 | I2,I3 |
7 | I1,I3 |
8 | I1,I2,I3,I5 |
9 | I1,I2,I3 |
扫描事务数据库得到频繁1-项目集F。
I1 | I2 | I3 | I4 | I5 |
6 | 7 | 6 | 2 | 2 |
定义minsup=20%,即最小支持度为2,重新排列F。
I2 | I1 | I3 | I4 | I5 |
7 | 6 | 6 | 2 | 2 |
重新调整事务数据库。
Tid | Items |
1 | I2, I1,I5 |
2 | I2,I4 |
3 | I2,I3 |
4 | I2, I1,I4 |
5 | I1,I3 |
6 | I2,I3 |
7 | I1,I3 |
8 | I2, I1,I3,I5 |
9 | I2, I1,I3 |
(2)创建根结点和频繁项目表

(3)加入第一个事务(I2,I1,I5)
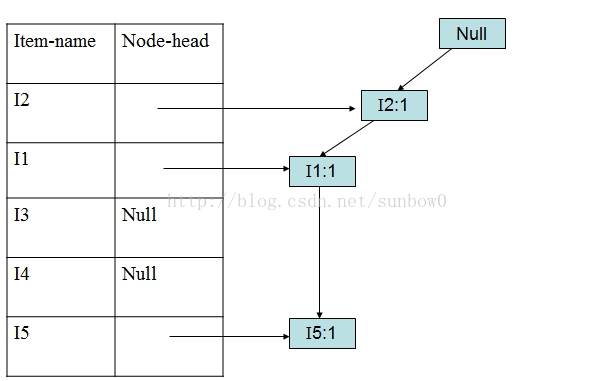
(4)加入第二个事务(I2,I4)

(5)加入第三个事务(I2,I3)

以此类推加入第5、6、7、8、9个事务。
(6)加入第九个事务(I2,I1,I3)
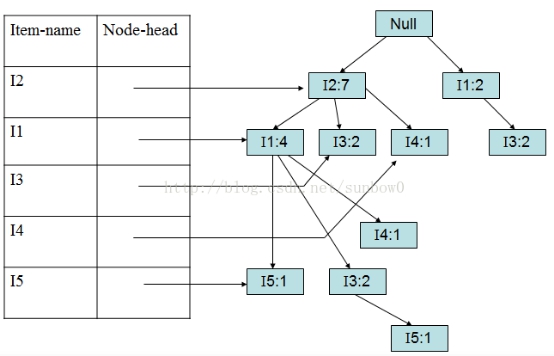
1.1.4 FP-Growth算法演示—FP-树挖掘
FP-树建好后,就可以进行频繁项集的挖掘,挖掘算法称为FpGrowth(Frequent Pattern Growth)算法,挖掘从表头header的最后一个项开始,以此类推。本文以I5、I3为例进行挖掘。
(1)挖掘I5:
对于I5,得到条件模式基:<(I2,I1:1)>、<I2,I1,I3:1>
构造条件FP-tree:
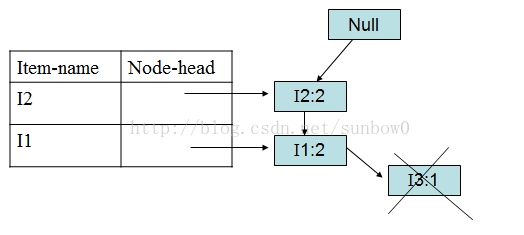
得到I5频繁项集:{{I2,I5:2},{I1,I5:2},{I2,I1,I5:2}}
I4、I1的挖掘与I5类似,条件FP-树都是单路径。
(1)挖掘I3:
I5的情况是比较简单的,因为I5对应的条件FP-树是单路径的,I3稍微复杂一点。I3的条件模式基是(I2 I1:2), (I2:2), (I1:2),生成的条件FP-树如下图:

I3的条件FP-树仍然是一个多路径树,首先把模式后缀I3和条件FP-树中的项头表中的每一项取并集,得到一组模式{I2 I3:4, I1 I3:4},但是这一组模式不是后缀为I3的所有模式。还需要递归调用FP-growth,模式后缀为{I1,I3},{I1,I3}的条件模式基为{I2:2},其生成的条件FP-树如下图所示。
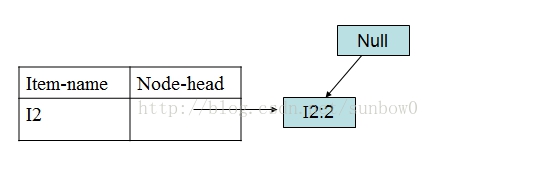
在FP_growth中把I2和模式后缀{I1,I3}取并得到模式{I1 I2 I3:2}。
理论上还应该计算一下模式后缀为{I2,I3}的模式集,但是{I2,I3}的条件模式基为空,递归调用结束。最终模式后缀I3的支持度>2的所有模式为:{ I2 I3:4, I1 I3:4, I1 I2 I3:2}。
转于: https://blog.csdn.net/sunbow0/article/details/45602415
运行Spark fp-growth demo如下:
pom.xml中加载mllib依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.11</artifactId>
<version>2.3.0</version>
</dependency>
官网提供的代码如下:
package cn.xdf.userprofile.ML
import org.apache.spark.sql.SparkSession
import org.apache.spark.ml.fpm.FPGrowth
object FPGrowthDemo {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder
.appName("FPGrowthDemo").master("local")
.config("spark.sql.warehouse.dir", "C:\\study\\sparktest")
.getOrCreate()
//val spark = getSparkSession("FPGrowthDemo")
import spark.implicits._
val dataset = spark.createDataset(Seq(
"1 2 5",
"1 2 3 5",
"1 2 ")
).map(t => t.split(" ")).toDF("items")
val fpgroth=new FPGrowth().setItemsCol("items").setMinSupport(0.5).setMinConfidence(0.6)
val model=fpgroth.fit(dataset)
// Display frequent itemsets.
model.freqItemsets.show()
// Display generated association rules.
model.associationRules.show()
// transform examines the input items against all the association rules and summarize the
// consequents as prediction
model.transform(dataset).show()
// $example off$
spark.stop()
}
}
运行结果如下:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号