
爬取360动漫热度排行榜并分析
爬取最新手游信息一、主题式网络爬虫设计方案
1.主题式网络爬虫名称: 360动漫热度排行榜爬取并分析
2.主题式网络爬虫爬取的内容与数据特征分析: 内容:爬取360动漫热度排行榜
3.网络爬虫设计方案概述: 登录所要爬取的网址,鼠标移动至所需爬取的资料右击,审查元素,使用get请求和beautifulsoup解析工具进行爬取数据,使用pandas进行数据可视化二、主题页面的结构特征分析
1.主题页面的结构与特征分析:网页:http://www.360kan.com/rank/dongman
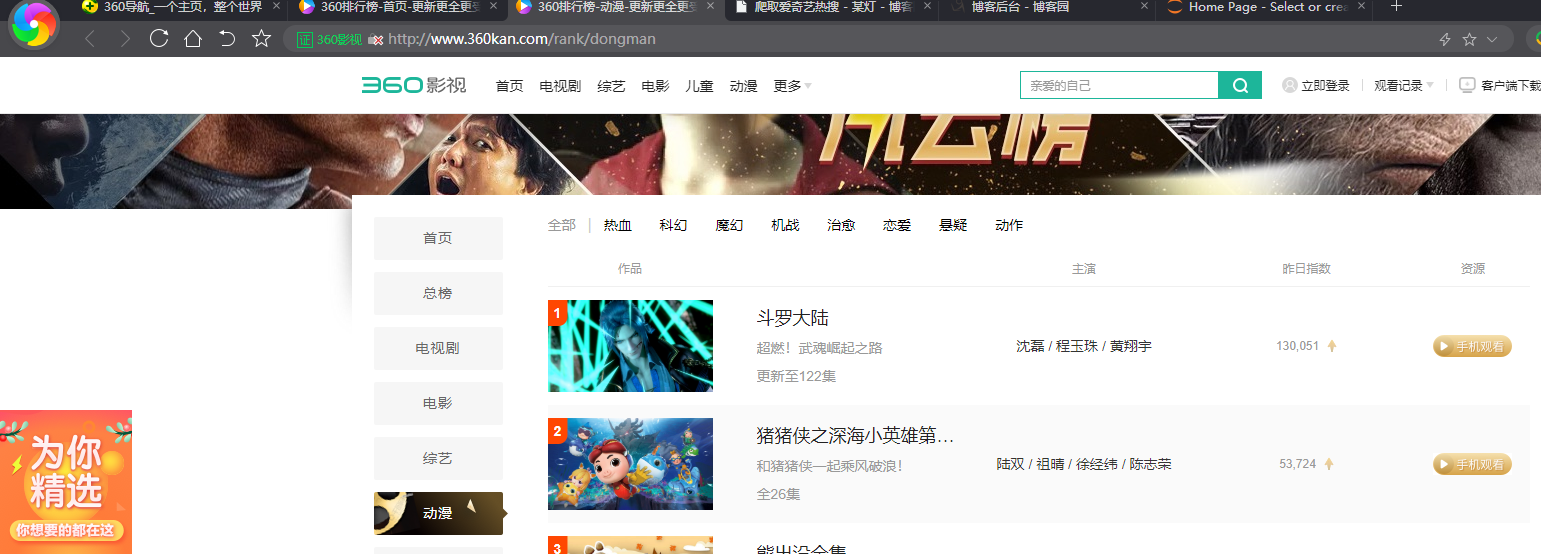
2.结构分析
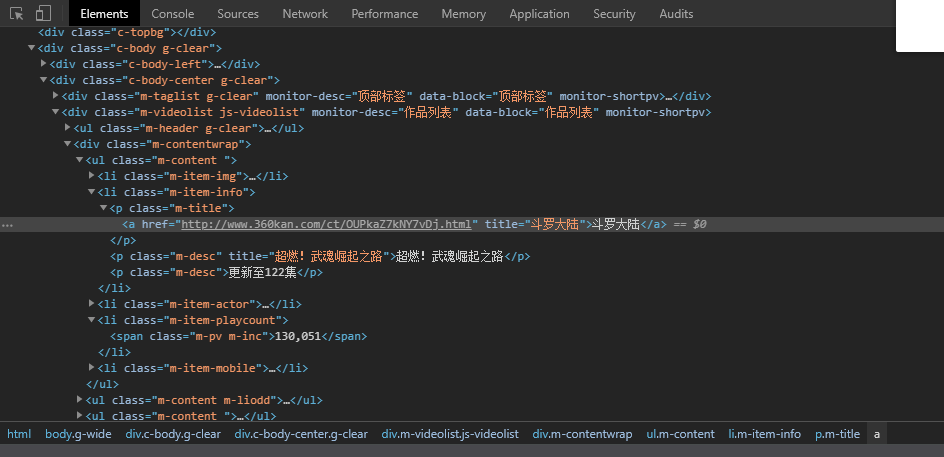
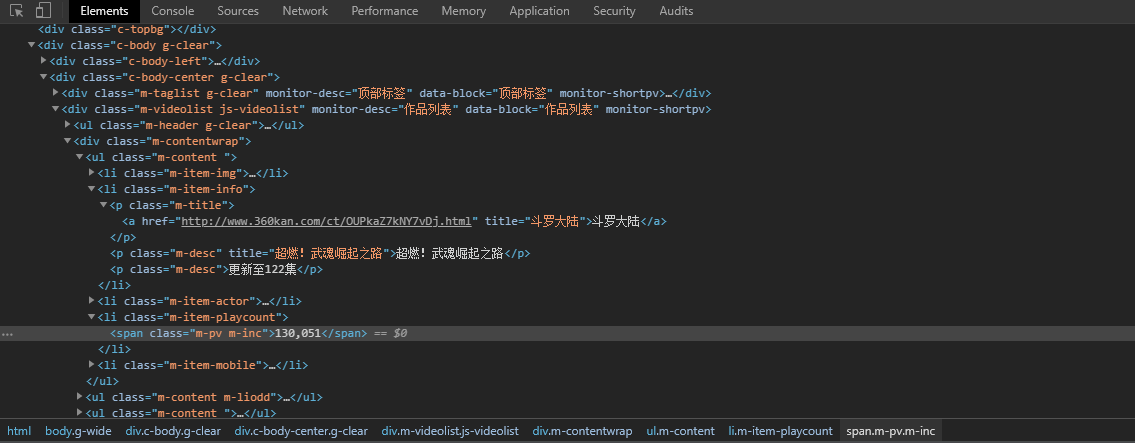
3.利用find_all函数进行遍历查找的方式爬取 三、网络爬虫程序设计1.数据爬取和采集,并保存
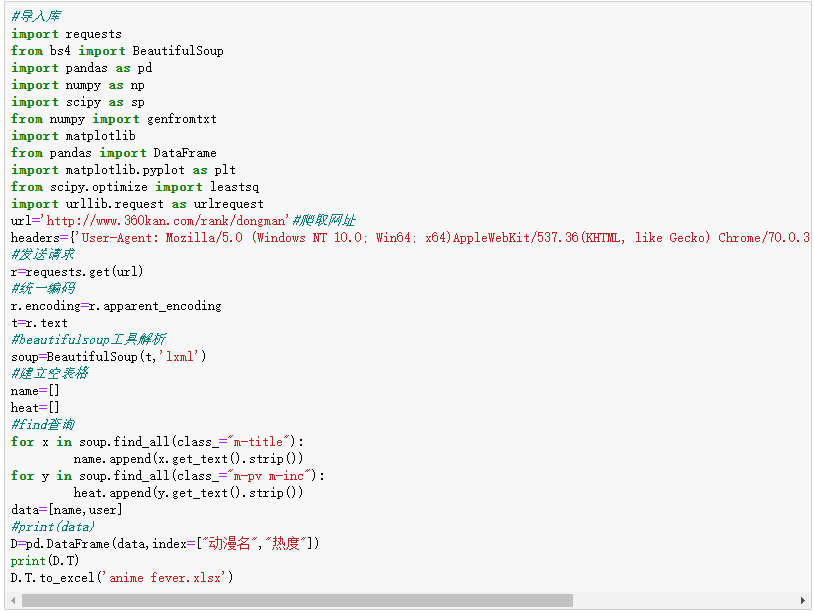

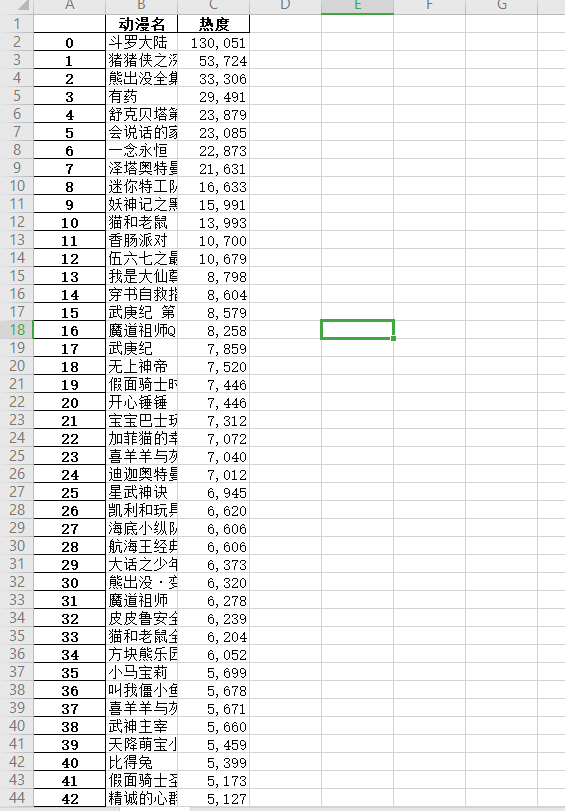
数据清洗


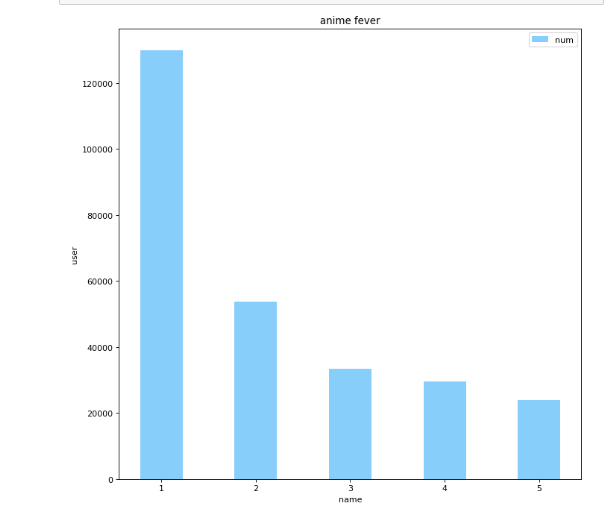
选出热度最高的5部分别用1,2,3,4,5代表

柱形图:
完整代码:
#导入库 import requests from bs4 import BeautifulSoup import pandas as pd import numpy as np import scipy as sp from numpy import genfromtxt import matplotlib from pandas import DataFrame import matplotlib.pyplot as plt from scipy.optimize import leastsq import urllib.request as urlrequest url='http://www.360kan.com/rank/dongman'#搜索网址 headers={'User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36 Edge/18.18363'}#伪装爬虫 r=requests.get(url)#发送get请求 r.encoding=r.apparent_encoding#统一编码 t=r.text soup=Beautifulsoup(t,'lxml') name=[] heat=[] for y in soup.find_all(class_="m-title"): name.append(y.get_text().strip()) for x in soup.find_all(class_="m-pv m-inc"): heat.append(x.get_text().strip()) data=[title,index] print(data) c=pd.DataFrame(data,index=["动漫名","热度"]) print(c.T) D.T.to_excel("anime fever") #数据清洗 print('\n====各列是否有缺失值情况如下:====') print(df.isnull()) #统计空值情况 print(df.duplicated()) #查找重复值 print(df.isna().head()) #统计缺失值 # 得出结果为False则不为空值 print(df.describe()) #描述数据 #柱形图 plt.figure(figsize=(10,10),dpi=80) #柱子总数 N=5 #包含每个柱子对应值的序列 values=(130051,53724,33306,29491,23879) #包含每个柱子下标的序列 index=np.arange(N) #柱子的宽度 width=0.45 p2=plt.bar(index,values,width,label="num",color="#87CEFA") #设置横轴标签 plt.xlabel('name') #设置纵轴标签 plt.ylabel('user') #添加标题 plt.title('anime fever') #添加纵横轴的刻度 plt.xticks(index,('1','2','3','4','5')) #plt.yticks(np.arange(0,10000,10)) #添加图例 plt.legend(loc="upper right") plt.show() #画一元二次回归方程 chinese=matplotlib.font_manager.FontProperties(fname='C:/Windows/Fonts/simsun.ttc') #调用中文 plt.rcParams['font.sans-serif']=['Arial Unicode MS'] plt.rcParams['axes.unicode_minus']=False filename="anime fever.xlsx" colnames=["rank","name","hot"] df=pd.read_excel(filename,skiprows=1,names=colnames) X=df.rank Y=df.hot #确定x,y轴 def func(params,x): a,b,c=params return a*x*x+b*x+c def error(params,x,y): #设置误差函数 return func(params,x)-y p0=[1978,0] #主函数 def main(): plt.figure(figsize=(8,6)) #画布尺寸 p0=[1978,300,1] Para=leastsq(error,p0,args=(X,Y)) a,b,c=Para[0] print("a=",a,"b=",b,"c=",c) plt.scatter(X,Y,color="green",label="样本数据",linewidth=2) x=np.linspace(1,25,25) y=a*x*x+b*x+c plt.plot(x,y,color="red",label="拟合曲线",linewidth=2) #画拟合曲线 plt.legend() plt.title("动漫热度") plt.grid() plt.show() main() plt.savefig(fname="C:/动漫热度.jpg",figsize=[1,1])
#保存图像
四、结论(10分)
1.经过对主题数据的分析与可视化, 可以得到哪些结论?
了解到自己对于专业知识学习的不足,对于专业性知识的欠缺,数据可视化使得爬取的数据更加清晰,可以更加清楚的了解到热搜的排名及热度。
2.对本次程序设计任务完成的情况做一个简单的小结。
以后要加强专业的学习,对于Python专业性的知识不足,对于细节知识的匮乏,只有真正自己动手才能够发现自己的不足,哪部分的专业知识缺乏,要求学习的东西有很多,任重而道远,自己以后保持谦虚求学的态度完成今后的学业,加强对于计算机语言的兴趣!

