hash slot(虚拟桶)
在分布式集群中,如何保证相同请求落到相同的机器上,并且后面的集群机器可以尽可能的均分请求,并且当扩容或down机的情况下能对原有集群影响最小。
round robin算法:是把数据mod后直接映射到真实节点上面,这造成节点个数和数据的紧密关联、后期缺乏灵活扩展。
一致性哈希算法:多增加一层虚拟映射层,数据与虚拟节点映射、虚拟节点与真实节点再映射。
一般都会采用一致性哈希或者hash slot的方法。一致性哈希的ketama算法实现在扩容或down的情况下,需要重新计算节点,这对之前的分配可能会有一些影响。所以可以引入hash slot的方式,即某些hash slot区间对应一台机器,对于扩容或down机情况下,就改变某个hash slot区间就可以了,改动比较小,对之前分配的影响也较小。
虚拟桶是取模和一致性哈希二者的折中办法。
- 采用固定节点数量,来避免取模的不灵活性。
- 采用可配置映射节点,来避免一致性哈希的部分影响。
先来看一下hash slot的基本模型:
记录和物理机之间引入了虚拟桶层,记录通过hash函数映射到虚拟桶,记录和虚拟桶是多对一的关系;第二层是虚拟桶和物理机之间的映射,同样也是多对一的关系,即一个物理机对应多个虚拟桶,这个层关系是通过内存表实现的。对照抽象模型章节,key-partition是通过hash函数实现的,partition-machine是通过内存表来实现的。注:couchbase就是利用的此技术。
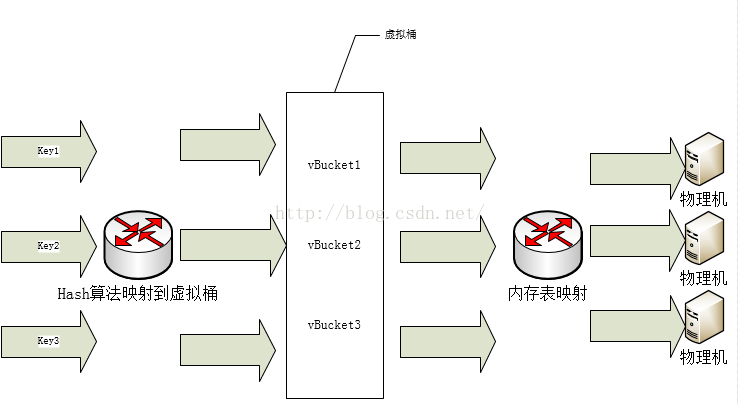
key对虚拟桶层
虚拟桶层采用预设固定数量,比如可以预设N=1024。意味之后这个分布式集群最大扩容到1024个节点,带来的好处就是mod后的值是不变的(非常重要),这保证了第一层映射不受实际节点变化的影响。 关于最大数量,可根据实现需要预先定义好即可。
虚拟桶对实际节点
举个例子,项目刚开始使用时配置节点映射:
Redis Server1对应桶的编号为0到500。
Redis Server2对应桶的编号为500到1024。
缓存数据量增长后需要增加新节点,在加之前需要重新分配节点对应虚拟桶的编号。 比如增加server3并配置对应桶的编号400到600,这时对于key映射虚拟桶层完全无影响。 实际上mod 400到600的真实数据还在另外两台节点上,请求过来后还会发生无法命中的影响。这就要求在增加新节点前,需要在后台把另外二台的400到600编号数据拷贝到新节点上面,完成后再添加配置到映射上面。 因为新来请求会命中到新节点,所以另外2台的400到600编号数据就无用了,需要进行删除。这种做法就能最大限度(100%)的保证动态扩容后,对缓存系统无影响,具体实现细节后续还需深入进行研究。
在redis集群的设计中也是采用的这个思路。
Redis 集群没有并使用传统的一致性哈希来分配数据,而是采用另外一种叫做哈希槽 (hash slot)的方式来分配的。redis cluster 默认分配了 16384 个slot,当我们set一个key 时,会用CRC16算法来取模得到所属的slot,然后将这个key 分到哈希槽区间的节点上,具体算法就是:CRC16(key) % 16384。
所以,我们假设现在有3个节点已经组成了集群,分别是:A, B, C 三个节点,它们可以是一台机器上的三个端口,也可以是三台不同的服务器。那么,采用哈希槽 (hash slot)的方式来分配16384个slot 的话,它们三个节点分别承担的slot 区间是:
- 节点A覆盖0-5460;
- 节点B覆盖5461-10922;
- 节点C覆盖10923-16383.
这种将哈希槽分布到不同节点的做法使得用户可以很容易地向集群中添加或者删除节点。 比如说:
- 如果用户将新节点 D 添加到集群中, 那么集群只需要将节点 A 、B 、 C 中的某些槽移动到节点 D 就可以了。
比如我想新增一个
节点D,redis cluster的这种做法是从各个节点的前面各拿取一部分slot到D上。大致就会变成这样:- 节点A覆盖1365-5460
- 节点B覆盖6827-10922
- 节点C覆盖12288-16383
- 节点D覆盖0-1364,5461-6826,10923-12287
- 与此类似, 如果用户要从集群中移除节点 A , 那么集群只需要将节点 A 中的所有哈希槽移动到节点 B 和节点 C , 然后再移除空白(不包含任何哈希槽)的节点 A 就可以了。
因为将一个哈希槽从一个节点移动到另一个节点不会造成节点阻塞, 所以无论是添加新节点还是移除已存在节点, 又或者改变某个节点包含的哈希槽数量, 都不会造成集群下线。
另外,还有一个问题:为什么哈希槽的数量固定为16384?(https://github.com/antirez/redis/issues/2576)
由于使用CRC16算法,该算法可以产生2^16-1=65535个值,可是为什么哈希槽的数量设置成了16384?
Normal heartbeat packets carry the full configuration of a node, that can be replaced in an idempotent way with the old in order to update an old config. This means they contain the slots configuration for a node, in raw form, that uses 2k of space with 16k slots, but would use a prohibitive 8k of space using 65k slots.
At the same time it is unlikely that Redis Cluster would scale to more than 1000 mater nodes because of other design tradeoffs.
So 16k was in the right range to ensure enough slots per master with a max of 1000 maters, but a small enough number to propagate the slot configuration as a raw bitmap easily. Note that in small clusters the bitmap would be hard to compress because when N is small the bitmap would have slots/N bits set that is a large percentage of bits set.
总结一下:
1、redis的一个节点的心跳信息中需要携带该节点的所有配置信息,而16K大小的槽数量所需要耗费的内存为2K,但如果使用65K个槽,这部分空间将达到8K,心跳信息就会很庞大。
2、Redis集群中主节点的数量基本不可能超过1000个。
3、Redis主节点的配置信息中,它所负责的哈希槽是通过一张bitmap的形式来保存的,在传输过程中,会对bitmap进行压缩,但是如果bitmap的填充率slots / N很高的话,bitmap的压缩率就很低,所以N表示节点数,如果节点数很少,而哈希槽数量很多的话,bitmap的压缩率就很低。而16K个槽当主节点为1000的时候,是刚好比较合理的,既保证了每个节点有足够的哈希槽,又可以很好的利用bitmap。
4、选取了16384是因为crc16会输出16bit的结果,可以看作是一个分布在0-2^16-1之间的数,redis的作者测试发现这个数对2^14求模的会将key在0-2^14-1之间分布得很均匀,因此选了这个值。
最后,将redis中计算hash slot的源码贴出来,看一下效果
1 #include <iostream> 2 #include <string.h> 3 #include "crc16.h" 4 5 unsigned int keyHashSlot(char *key, int keylen) { 6 int s, e; /* start-end indexes of { and } */ 7 8 std::cout << "key : " << key << std::endl; 9 10 for (s = 0; s < keylen; s++) 11 if (key[s] == '{') break; 12 13 /* No '{' ? Hash the whole key. This is the base case. */ 14 if (s == keylen) return crc16(key,keylen) & 0x3FFF; 15 16 /* '{' found? Check if we have the corresponding '}'. */ 17 for (e = s+1; e < keylen; e++) 18 if (key[e] == '}') break; 19 20 /* No '}' or nothing betweeen {} ? Hash the whole key. */ 21 if (e == keylen || e == s+1) return crc16(key,keylen) & 0x3FFF; 22 23 /* If we are here there is both a { and a } on its right. Hash 24 * * what is in the middle between { and }. */ 25 return crc16(key+s+1,e-s-1) & 0x3FFF; 26 } 27 28 29 30 int main(int argc, char * argv[]) 31 { 32 if (argc != 2) { 33 std::cout << "usage: ./a.out key" << std::endl; 34 } 35 36 char * key = argv[1]; 37 38 std::cout << keyHashSlot(key, strlen(key)) << std::endl; 39 40 return 0; 41 }
运行结果:
本文参考自:
http://blog.csdn.net/baoxifu/article/details/51344786
http://www.cnblogs.com/mushroom/p/4542772.html
https://www.cnblogs.com/wxd0108/p/5798498.html
http://redisdoc.com/topic/cluster-tutorial.html
https://github.com/antirez/redis/issues/2576
http://blog.onlycatch.com/post/60c42de47e9a
https://www.zhihu.com/question/53927336
posted on 2018-01-05 11:53 LastBattle 阅读(11186) 评论(5) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号