一个完整的大作业
获取中国乒乓球协会官方网站(http://www.ctta.cn/)的所有协会动态信息
要求
选一个自己感兴趣的主题。
网络上爬取相关的数据。
进行文本分析,生成词云。
对文本分析结果解释说明。
写一篇完整的博客,附上源代码、数据爬取及分析结果,形成一个可展示的成果。
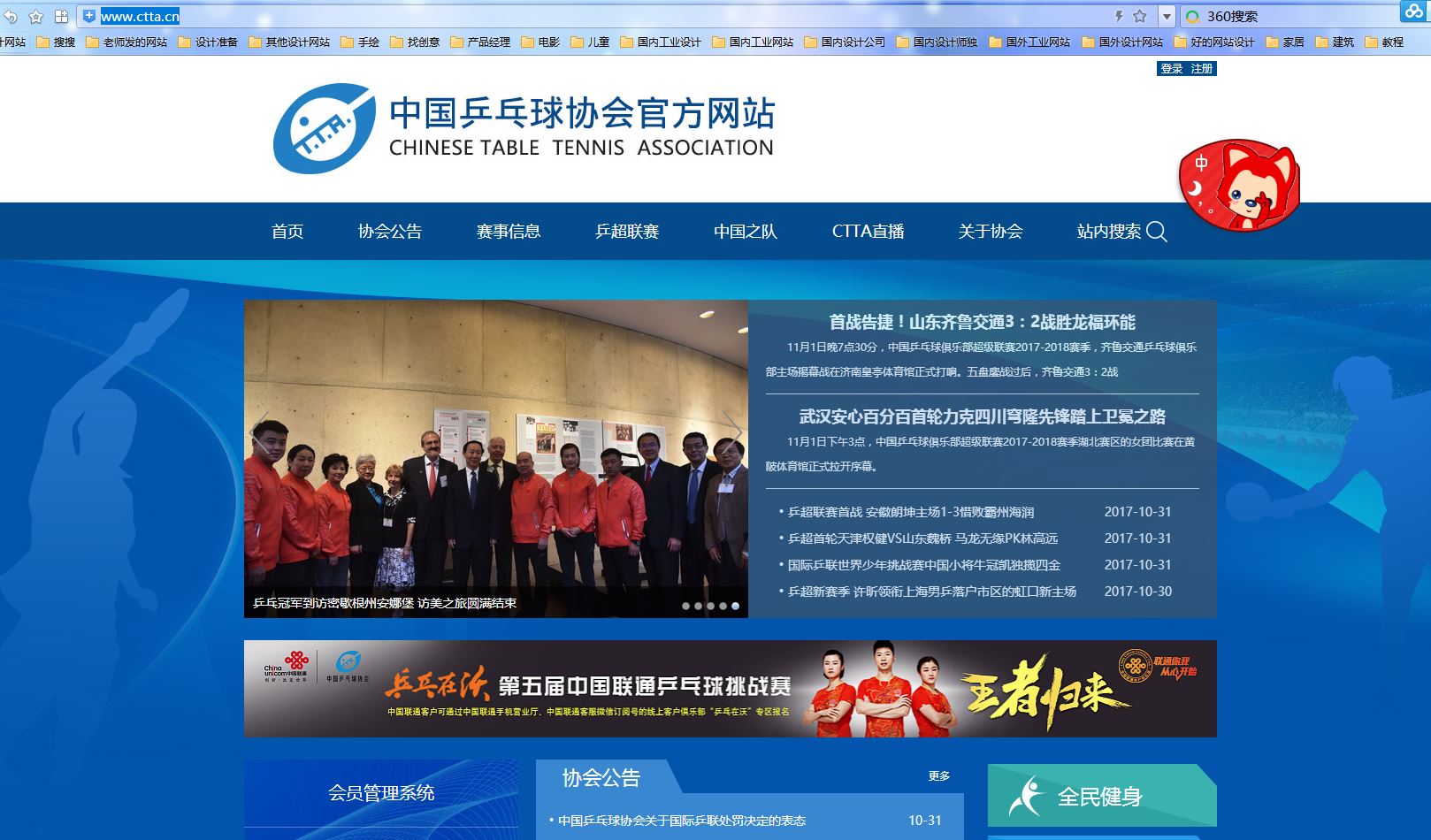
1、首先使用浏览器打开中国乒乓球协会官方网站动态的网页http://www.ctta.cn/,在空白地方点击鼠标右键查看源代码。
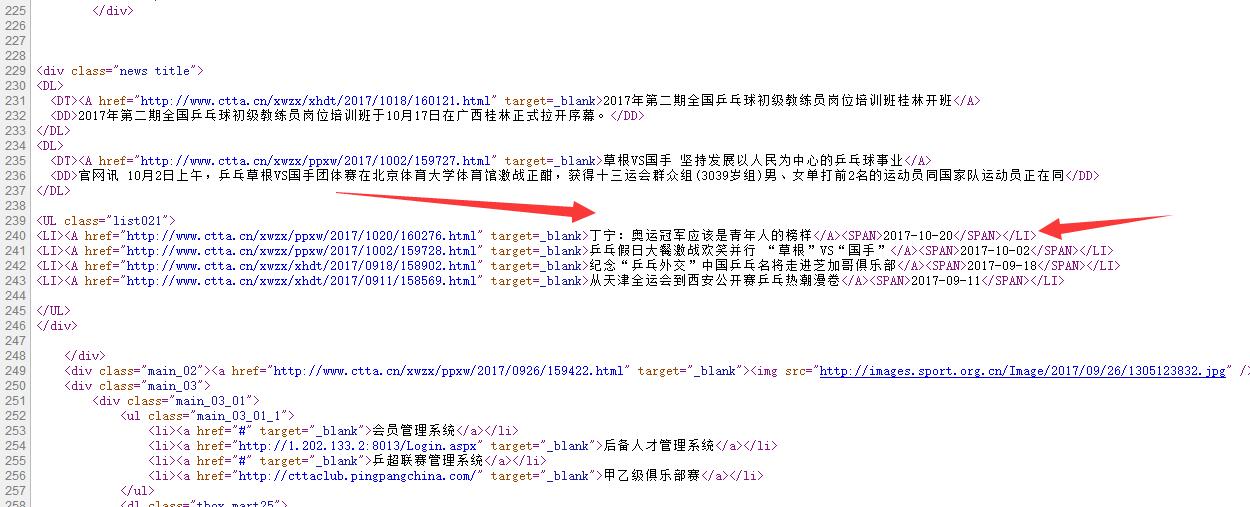
2、测试获取标题、标题链接、及发布时间代码
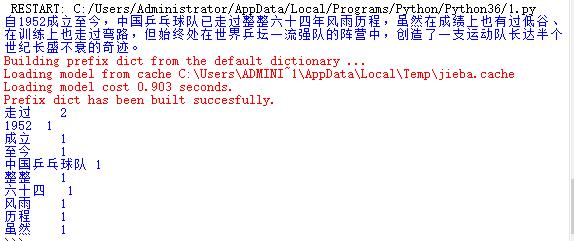
import requests from bs4 import BeautifulSoup from datetime import datetime import re url = 'http://www.ctta.cn/' res = requests.get(url) res.encoding='utf-8' soup=BeautifulSoup(res.text,'html.parser') for news in soup.select('.list021'): if len(news.select('a'))>0: title=news.select('a')[0].text#标题,选取<a>的全部内容,取出list列表第一个元素,选取当中title文本 time=news.select('span')[0].text#时间,选取<span>的全部内容,取出list列表第一个元素,选取当中的非代码文本内容 url=news.select('a')[0]['href']#链接,选取<a>的全部内容,取出list列表第一个元素,选取当中href文本 print("标题:",title,"\t\t\t\t\t\t时间:",time,"\t\t\t\t\t\t\t\t链接:",url)
3、获取标题、标题链接
import requests from bs4 import BeautifulSoup from datetime import datetime import re url = 'http://www.ctta.cn/' res = requests.get(url) res.encoding='utf-8' soup=BeautifulSoup(res.text,'html.parser') for news in soup.select('.pic'): if len(news.select('a'))>0: title=news.select('a')[1].text#标题,选取<a>的全部内容,取出list列表第一个元素,选取当中title文本 url=news.select('a')[0]['href']#链接,选取<a>的全部内容,取出list列表第一个元素,选取当中href文本 print("标题:",title,"\t\t\t\t\t\t\t\t链接:",url)

4、取其中一条信息详情
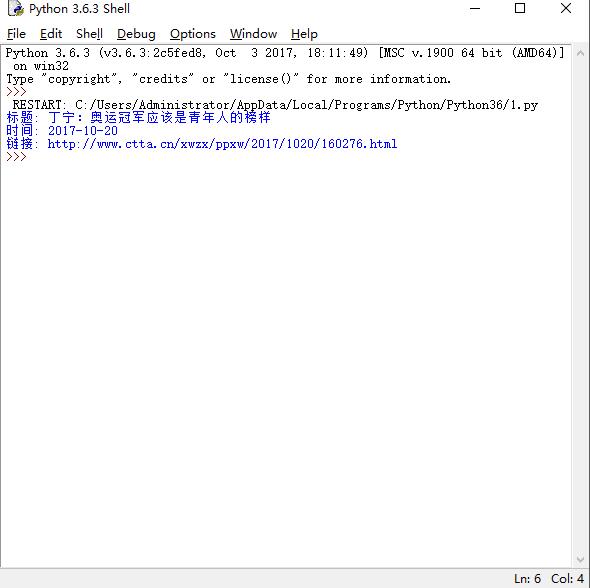
import requests from bs4 import BeautifulSoup import re aopaurl='http://www.ctta.cn/xwzx/ppxw/2017/1020/160276.html' res=requests.get(aopaurl) res.encoding='utf-8' soupn =BeautifulSoup(res.text,'html.parser') text=soupn.select('.content')[0].text print(text)

5、生成词云
import requests import jieba from bs4 import BeautifulSoup import re url = 'http://www.ctta.cn/' res = requests.get(url) res.encoding='utf-8' soup=BeautifulSoup(res.text,'html.parser') for news in soup.select('.main_05_01'): if len(news.select('h4'))>0: p=news.select('h4')[0].text print(p) break words = jieba.lcut(p) ls = [] counts = {} for word in words: ls.append(word) if len(word) == 1: continue else: counts[word] = counts.get(word,0)+1 items = list(counts.items()) items.sort(key = lambda x:x[1], reverse = True) for i in range(10): word , count = items[i] print ("{:<5}{:>2}".format(word,count))