


Java-Spark
wordcount代码:
package cn.itcast.hello; import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaPairRDD; import org.apache.spark.api.java.JavaRDD; import org.apache.spark.api.java.JavaSparkContext; import scala.Tuple2; import java.util.Arrays; import java.util.List; /** * Author itcast * Desc 演示使用Java语言开发SparkCore完成WordCount */ public class JavaSparkDemo01 { public static void main(String[] args) { //0.TODO 准备环境 SparkConf sparkConf = new SparkConf().setAppName("JavaSparkDemo").setMaster("local[*]"); JavaSparkContext jsc = new JavaSparkContext(sparkConf); jsc.setLogLevel("WARN"); //1.TODO 加载数据 JavaRDD<String> fileRDD = jsc.textFile("data/input/words.txt"); //2.TODO 处理数据-WordCount //切割 /* @FunctionalInterface public interface FlatMapFunction<T, R> extends Serializable { Iterator<R> call(T t) throws Exception; } */ //注意:java的函数/lambda表达式的语法: // (参数列表)->{函数体} JavaRDD<String> wordsRDD = fileRDD.flatMap(line -> Arrays.asList(line.split(" ")).iterator()); //每个单词记为1 JavaPairRDD<String, Integer> wordAndOneRDD = wordsRDD.mapToPair(word -> new Tuple2<>(word, 1)); //分组聚合 JavaPairRDD<String, Integer> wordAndCountRDD = wordAndOneRDD.reduceByKey((a, b) -> a + b); //3.TODO 输出结果 List<Tuple2<String, Integer>> result = wordAndCountRDD.collect(); //result.forEach(t-> System.out.println(t)); result.forEach(System.out::println);//方法引用/就是方法转为了函数 //4.TODO 关闭资源 jsc.stop(); } }

words.txt
hello me you her
hello you her
hello her
hello
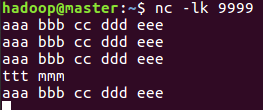
package cn.itcast.hello; import org.apache.spark.SparkConf; import org.apache.spark.streaming.Durations; import org.apache.spark.streaming.api.java.JavaPairDStream; import org.apache.spark.streaming.api.java.JavaReceiverInputDStream; import org.apache.spark.streaming.api.java.JavaStreamingContext; import scala.Tuple2; import java.util.Arrays; /** * Author itcast * Desc 演示使用Java语言开发SparkStreaming完成WordCount */ public class JavaSparkDemo02 { public static void main(String[] args) throws InterruptedException { //0.TODO 准备环境 SparkConf sparkConf = new SparkConf().setAppName("JavaSparkDemo").setMaster("local[*]"); //JavaSparkContext jsc = new JavaSparkContext(sparkConf); //jsc.setLogLevel("WARN"); JavaStreamingContext jssc = new JavaStreamingContext(sparkConf, Durations.seconds(5)); jssc.sparkContext().setLogLevel("WARN"); //1.TODO 加载数据 JavaReceiverInputDStream<String> lines = jssc.socketTextStream("master", 9999); //2.TODO 处理数据-WordCount JavaPairDStream<String, Integer> result = lines.flatMap(line -> Arrays.asList(line.split(" ")).iterator()) .mapToPair(word -> new Tuple2<>(word, 1)) .reduceByKey((a, b) -> a + b); //3.TODO 输出结果 result.print(); //4.TODO 启动并等待停止 jssc.start(); jssc.awaitTermination(); //4.TODO 关闭资源 jssc.stop(); } }


package cn.itcast.hello; import org.apache.spark.sql.Dataset; import org.apache.spark.sql.Encoders; import org.apache.spark.sql.SparkSession; import java.util.Arrays; import static org.apache.spark.sql.functions.col; /** * Author itcast * Desc 演示使用Java语言开发SparkSQL完成WordCount */ public class JavaSparkDemo03 { public static void main(String[] args) { //0.TODO 准备环境 SparkSession spark = SparkSession.builder().appName("JavaSparkDemo").master("local[*]").getOrCreate(); spark.sparkContext().setLogLevel("WARN"); //1.TODO 加载数据 Dataset<String> ds = spark.read().textFile("data/input/words.txt"); //2.TODO 处理数据-WordCount Dataset<String> wordsDS = ds.flatMap((String line) -> Arrays.asList(line.split(" ")).iterator(), Encoders.STRING()); //TODO ====SQL wordsDS.createOrReplaceTempView("t_word"); String sql = "select value, count(*) as counts " + "from t_word " + "group by value " + "order by counts desc"; spark.sql(sql).show(); //TODO ====DSL /*Dataset<Row> temp = wordsDS.groupBy("value") .count(); temp.orderBy(temp.col("count").desc()).show();*/ wordsDS.groupBy("value") .count() //.orderBy($"count".desc()).show(); .orderBy(col("count").desc()).show(); //3.TODO 输出结果 //4.TODO 关闭资源 spark.stop(); } }

package cn.itcast.hello; import org.apache.spark.sql.Dataset; import org.apache.spark.sql.Encoders; import org.apache.spark.sql.Row; import org.apache.spark.sql.SparkSession; import org.apache.spark.sql.streaming.OutputMode; import org.apache.spark.sql.streaming.StreamingQueryException; import java.util.Arrays; import java.util.concurrent.TimeoutException; import static org.apache.spark.sql.functions.col; /** * Author itcast * Desc 演示使用Java语言开发StructuredStreaming完成WordCount */ public class JavaSparkDemo04 { public static void main(String[] args) throws TimeoutException, StreamingQueryException { //0.TODO 准备环境 SparkSession spark = SparkSession.builder().appName("JavaSparkDemo").master("local[*]") .config("spark.sql.shuffle.partitions", "4") .getOrCreate(); spark.sparkContext().setLogLevel("WARN"); //1.TODO 加载数据 Dataset<Row> lines = spark.readStream() .format("socket") .option("host", "master") .option("port", 9999) .load(); //2.TODO 处理数据-WordCount Dataset<String> ds = lines.as(Encoders.STRING()); Dataset<String> wordsDS = ds.flatMap((String line) -> Arrays.asList(line.split(" ")).iterator(), Encoders.STRING()); //TODO ====SQL wordsDS.createOrReplaceTempView("t_word"); String sql = "select value, count(*) as counts " + "from t_word " + "group by value " + "order by counts desc"; Dataset<Row> result1 = spark.sql(sql); //TODO ====DSL Dataset<Row> result2 = wordsDS.groupBy("value") .count() .orderBy(col("count").desc()); //3.TODO 输出结果 result1.writeStream() .format("console") .outputMode(OutputMode.Complete()) .start(); /*.awaitTermination()*/ result2.writeStream() .format("console") .outputMode(OutputMode.Complete()) .start() .awaitTermination(); //4.TODO 关闭资源 spark.stop(); } }


特征列:
|房屋编号mlsNum|城市city|平方英尺|卧室数bedrooms|卫生间数bathrooms|车库garage|年龄age|房屋占地面积acres|
标签列:
房屋价格price
步骤:
0.准备环境
1.加载数据
2.特征处理
3.数据集划分0.8训练集/0.2测试集
4.使用训练集训练线性回归模型
5.使用测试集对模型进行测试
6.计算误差rmse均方误差
7.模型保存(save)方便后续使用(load)
8.关闭资源
package cn.itcast.hello; import org.apache.spark.ml.evaluation.RegressionEvaluator; import org.apache.spark.ml.feature.VectorAssembler; import org.apache.spark.ml.regression.LinearRegression; import org.apache.spark.ml.regression.LinearRegressionModel; import org.apache.spark.sql.Dataset; import org.apache.spark.sql.Row; import org.apache.spark.sql.SparkSession; import org.apache.spark.sql.streaming.StreamingQueryException; import java.io.IOException; import java.util.concurrent.TimeoutException; /** * Author itcast * Desc 演示使用Java语言开发SparkMlLib-线性回归算法-房价预测案例 */ public class JavaSparkDemo05 { public static void main(String[] args) throws TimeoutException, StreamingQueryException, IOException { //0.TODO 准备环境 SparkSession spark = SparkSession.builder().appName("JavaSparkDemo").master("local[*]") .config("spark.sql.shuffle.partitions", "4") .getOrCreate(); spark.sparkContext().setLogLevel("WARN"); //TODO 1.加载数据 Dataset<Row> homeDataDF = spark.read() .format("csv") .option("sep", "|")//指定分隔符 .option("header", "true")//是否有表头 .option("inferSchema", "true")//是否自动推断约束 .load("data/input/homeprice.data"); homeDataDF.printSchema(); homeDataDF.show(); /* root |-- mlsNum: integer (nullable = true) |-- city: string (nullable = true) |-- sqFt: double (nullable = true) |-- bedrooms: integer (nullable = true) |-- bathrooms: integer (nullable = true) |-- garage: integer (nullable = true) |-- age: integer (nullable = true) |-- acres: double (nullable = true) |-- price: double (nullable = true) //|房屋编号|城市|平方英尺|卧室数|卫生间数|车库|年龄|房屋占地面积|房屋价格 +-------+------------+-------+--------+---------+------+---+-----+---------+ | mlsNum| city| sqFt|bedrooms|bathrooms|garage|age|acres| price| +-------+------------+-------+--------+---------+------+---+-----+---------+ |4424109|Apple Valley| 1634.0| 2| 2| 2| 33| 0.04| 119900.0| |4404211| Rosemount|13837.0| 4| 6| 4| 17|14.46|3500000.0| |4339082| Burnsville| 9040.0| 4| 6| 8| 12| 0.74|2690000.0| */ //TODO 2.特征处理 //特征选择 Dataset<Row> featuredDF = homeDataDF.select("sqFt", "age", "acres", "price"); //特征向量化 Dataset<Row> vectorDF = new VectorAssembler() .setInputCols(new String[]{"sqFt", "age", "acres"})//指定要对哪些特征做向量化 .setOutputCol("features")//向量化之后的特征列列名 .transform(featuredDF); vectorDF.printSchema(); vectorDF.show(); /* root |-- sqFt: double (nullable = true) |-- age: integer (nullable = true) |-- acres: double (nullable = true) |-- price: double (nullable = true) |-- features: vector (nullable = true) +-------+---+-----+---------+--------------------+ | sqFt|age|acres| price| features| +-------+---+-----+---------+--------------------+ | 1634.0| 33| 0.04| 119900.0| [1634.0,33.0,0.04]| |13837.0| 17|14.46|3500000.0|[13837.0,17.0,14.46]| | 9040.0| 12| 0.74|2690000.0| [9040.0,12.0,0.74]| */ //TODO 3.数据集划分0.8训练集/0.2测试集 Dataset<Row>[] arr = vectorDF.randomSplit(new double[]{0.8, 0.2}, 100); Dataset<Row> trainSet = arr[0]; Dataset<Row> testSet = arr[1]; //TODO 4.构建线性回归模型并使用训练集训练 LinearRegressionModel model = new LinearRegression() .setFeaturesCol("features")//设置特征列(应该设置向量化之后的) .setLabelCol("price")//设置标签列(数据中已经标记好的原本的价格) .setPredictionCol("predict_price")//设置预测列(后续做预测时预测的价格) .setMaxIter(10)//最大迭代次数 .fit(trainSet);//使用训练集进行训练 //TODO 5.使用测试集对模型进行测试/预测 Dataset<Row> testResult = model.transform(testSet); testResult.show(false); //TODO 6.计算误差rmse均方误差 double rmse = new RegressionEvaluator()//创建误差评估器 .setMetricName("rmse") //设置要计算的误差名称,均方根误差 (sum((y-y')^2)/n)^0.5 .setLabelCol("price")//设置真实值是哪一列 .setPredictionCol("predict_price")//设置预测值是哪一列 .evaluate(testResult);//对数据中的真实值和预测值进行误差计算 System.out.println("rmse为:" + rmse); //TODO 7.模型保存(save)方便后续使用(load) //model.save("path"); //LinearRegressionModel lmodel = LinearRegressionModel.load("path"); //TODO 8.关闭资源 spark.stop(); } }
结果:
root |-- mlsNum: integer (nullable = true) |-- city: string (nullable = true) |-- sqFt: double (nullable = true) |-- bedrooms: integer (nullable = true) |-- bathrooms: integer (nullable = true) |-- garage: integer (nullable = true) |-- age: integer (nullable = true) |-- acres: double (nullable = true) |-- price: double (nullable = true) +-------+------------+-------+--------+---------+------+---+-----+---------+ | mlsNum| city| sqFt|bedrooms|bathrooms|garage|age|acres| price| +-------+------------+-------+--------+---------+------+---+-----+---------+ |4424109|Apple Valley| 1634.0| 2| 2| 2| 33| 0.04| 119900.0| |4404211| Rosemount|13837.0| 4| 6| 4| 17|14.46|3500000.0| |4339082| Burnsville| 9040.0| 4| 6| 8| 12| 0.74|2690000.0| |4362154| Lakeville| 6114.0| 7| 5| 12| 25|14.83|1649000.0| |4388419| Lakeville| 6546.0| 5| 5| 11| 38| 5.28|1575000.0| |4188305| Rosemount| 1246.0| 4| 1| 2|143|56.28|1295000.0| |4350149| Eagan| 8699.0| 5| 6| 7| 28| 2.62|1195000.0| |4409729| Rosemount| 6190.0| 7| 7| 7| 22|4.128|1195000.0| |4408821| Lakeville| 5032.0| 5| 5| 3| 9| 1.1|1125000.0| |4342395| Lakeville| 4412.0| 4| 5| 4| 9|0.924|1100000.0| |4361031| Lakeville| 5451.0| 5| 5| 2| 22|23.83| 975000.0| |4424555|Apple Valley| 8539.0| 5| 6| 6| 20|2.399| 975000.0| |4416412| Rosemount| 4910.0| 5| 4| 3| 29| 7.99| 799000.0| |4420237|Apple Valley| 5000.0| 4| 4| 3| 14| 0.77| 796000.0| |4392412| Eagan| 7000.0| 4| 5| 3| 21| 1.65| 789900.0| |4432729| Rosemount| 6300.0| 5| 5| 3| 22|4.724| 789000.0| |4349895| Lakeville| 5001.0| 4| 4| 6| 13| 2.62| 778500.0| |4376726| Burnsville| 5138.0| 4| 5| 3| 24| 1.83| 749900.0| |4429738| Lakeville| 4379.0| 4| 4| 8| 6| 0.7| 749900.0| |4429711| Lakeville| 4944.0| 4| 5| 3| 9|0.724| 724900.0| +-------+------------+-------+--------+---------+------+---+-----+---------+ only showing top 20 rows root |-- sqFt: double (nullable = true) |-- age: integer (nullable = true) |-- acres: double (nullable = true) |-- price: double (nullable = true) |-- features: vector (nullable = true) +-------+---+-----+---------+--------------------+ | sqFt|age|acres| price| features| +-------+---+-----+---------+--------------------+ | 1634.0| 33| 0.04| 119900.0| [1634.0,33.0,0.04]| |13837.0| 17|14.46|3500000.0|[13837.0,17.0,14.46]| | 9040.0| 12| 0.74|2690000.0| [9040.0,12.0,0.74]| | 6114.0| 25|14.83|1649000.0| [6114.0,25.0,14.83]| | 6546.0| 38| 5.28|1575000.0| [6546.0,38.0,5.28]| | 1246.0|143|56.28|1295000.0|[1246.0,143.0,56.28]| | 8699.0| 28| 2.62|1195000.0| [8699.0,28.0,2.62]| | 6190.0| 22|4.128|1195000.0| [6190.0,22.0,4.128]| | 5032.0| 9| 1.1|1125000.0| [5032.0,9.0,1.1]| | 4412.0| 9|0.924|1100000.0| [4412.0,9.0,0.924]| | 5451.0| 22|23.83| 975000.0| [5451.0,22.0,23.83]| | 8539.0| 20|2.399| 975000.0| [8539.0,20.0,2.399]| | 4910.0| 29| 7.99| 799000.0| [4910.0,29.0,7.99]| | 5000.0| 14| 0.77| 796000.0| [5000.0,14.0,0.77]| | 7000.0| 21| 1.65| 789900.0| [7000.0,21.0,1.65]| | 6300.0| 22|4.724| 789000.0| [6300.0,22.0,4.724]| | 5001.0| 13| 2.62| 778500.0| [5001.0,13.0,2.62]| | 5138.0| 24| 1.83| 749900.0| [5138.0,24.0,1.83]| | 4379.0| 6| 0.7| 749900.0| [4379.0,6.0,0.7]| | 4944.0| 9|0.724| 724900.0| [4944.0,9.0,0.724]| +-------+---+-----+---------+--------------------+ only showing top 20 rows 21/03/22 17:07:18 WARN Instrumentation: [56c49327] regParam is zero, which might cause numerical instability and overfitting. 21/03/22 17:07:18 WARN BLAS: Failed to load implementation from: com.github.fommil.netlib.NativeSystemBLAS 21/03/22 17:07:18 WARN BLAS: Failed to load implementation from: com.github.fommil.netlib.NativeRefBLAS 21/03/22 17:07:18 WARN LAPACK: Failed to load implementation from: com.github.fommil.netlib.NativeSystemLAPACK 21/03/22 17:07:18 WARN LAPACK: Failed to load implementation from: com.github.fommil.netlib.NativeRefLAPACK +------+---+-----+--------+-------------------+-------------------+ |sqFt |age|acres|price |features |predict_price | +------+---+-----+--------+-------------------+-------------------+ |851.0 |8 |0.01 |90000.0 |[851.0,8.0,0.01] |66591.15920164142 | |921.0 |43 |0.35 |138500.0|[921.0,43.0,0.35] |33052.91814224735 | |950.0 |73 |0.249|137500.0|[950.0,73.0,0.249] |-10072.945366103137| |1012.0|33 |0.01 |69900.0 |[1012.0,33.0,0.01] |52882.097934101475 | |1048.0|30 |0.01 |104900.0|[1048.0,30.0,0.01] |62662.67324717087 | |1057.0|32 |0.01 |102900.0|[1057.0,32.0,0.01] |60995.34651481066 | |1089.0|32 |0.01 |127500.0|[1089.0,32.0,0.01] |65701.34099693046 | |1091.0|98 |0.12 |73000.0 |[1091.0,98.0,0.12] |-29951.262079218992| |1104.0|41 |0.04 |84900.0 |[1104.0,41.0,0.04] |55198.981091219306 | |1107.0|11 |0.01 |133900.0|[1107.0,11.0,0.01] |99752.7835379153 | |1125.0|46 |0.302|154900.0|[1125.0,46.0,0.302]|57366.181856518015 | |1128.0|32 |0.051|129900.0|[1128.0,32.0,0.051]|72462.72808724108 | |1175.0|17 |0.01 |117000.0|[1175.0,17.0,0.01] |100780.35877105064 | |1200.0|36 |0.01 |60000.0 |[1200.0,36.0,0.01] |76043.48399587075 | |1202.0|39 |0.01 |125000.0|[1202.0,39.0,0.01] |71851.27713031859 | |1237.0|18 |0.01 |134900.0|[1237.0,18.0,0.01] |108402.77923992957 | |1274.0|13 |0.01 |120000.0|[1274.0,13.0,0.01] |121321.30456102165 | |1300.0|0 |0.01 |248900.0|[1300.0,0.0,0.01] |144585.69500071075 | |1312.0|16 |0.01 |90000.0 |[1312.0,16.0,0.01] |122423.34148785431 | |1360.0|30 |0.104|99900.0 |[1360.0,30.0,0.104]|110898.31197543285 | +------+---+-----+--------+-------------------+-------------------+ only showing top 20 rows rmse为:65078.804057320325

 浙公网安备 33010602011771号
浙公网安备 33010602011771号