

上篇虽然主要讲述简单工厂模式,但其中包含的内容也挺多,涉及到工厂模式和单件模式,所以篇幅比较长.
这篇就来谈谈.Net Framework中简单工厂模式的运用,一切将会变的非常有趣.
一)System.Text.Encoding
第一部份:编码相关知识介绍,如果你只对简单工厂模式的应用感兴趣,那直接跳到第二部份吧.
Encoding为我们提供了各种编码,我们平常可能编码接触的并不是很多,所以我们先来了解一下,说不定下次就用到了.
1.人们怎么跟计算机交流呢?使用二进制,0110001001010110000011101011010......眼花缭乱了没,哈哈.
2.老美在痛苦不堪后,决定使用比较亲切的abcdefg 24个字母与计算机交流. 那字母到0,1是如何转换呢?
ASCII编码来了: 字符a 对应的十进制为97, 对应的十六进制为61, 对应的二进制为 0011 1101 刚好为一个字节
实验一:使用ASCII编码a,b输出十进制
 byte[] b = System.Text.Encoding.ASCII.GetBytes("ab");for (int i = 0; i < b.Length; i++) Response.Write(b[i].ToString() + " ");
byte[] b = System.Text.Encoding.ASCII.GetBytes("ab");for (int i = 0; i < b.Length; i++) Response.Write(b[i].ToString() + " ");输出: 97 98
说明: ToString()输出为十进制, 字符a对应97 字符b对应98
实验二:使用ASCII编码a,b输出十六进制
byte[] b = System.Text.Encoding.ASCII.GetBytes("ab");for (int i = 0; i < b.Length; i++) Response.Write(b[i].ToString("x") + " ");输出:61 62
说明: ToString("x")输出为十六进制, 字符a 对应61 字符b对应62
byte[] b = System.Text.Encoding.ASCII.GetBytes("ab");Response.Write(BitConverter.ToString(b));说明: BitConverter.ToString(byte[]) 输出为十六进制
有兴趣可以查看BitConverter.ToString(byte[])的源码,比较简单,注意一下该方法会在两个字节中间添加一个分隔符
3.中国人不爽了,我要用中文与计算机交流,我可不想使用英文与计算机交流.
GB2312编码来了
实验四:使用Gb2312编码 "小菜" ,输出十进制
byte[] b = System.Text.Encoding.GetEncoding("gb2312").GetBytes("小菜");for (int i = 0; i < b.Length; i++) Response.Write(b[i].ToString() + " ");说明: 输出十进制, '小' 对应208 161 占两个字节 '菜' 对应 178 203 占两个字节
实验五:验证十进制208 161 178 203 可以转换成 "小菜"
string name = System.Text.Encoding.GetEncoding("gb2312").GetString(b);
Response.Write(name);
说明: 看来十进制转换成字符串没问题 注意:前后的编码必须一致都为gb2312才行.
实验六:使用Gb2312编码 "小菜" ,输出十六进制
for (int i = 0; i < b.Length; i++)
Response.Write(b[i].ToString("x") + " ");
说明: 输出为十六进制,'小' 对应d0 a1 '菜' 对应 b2 cb
实验七:验证十六进制d0 a1 b2 cb 可以转换成 "小菜"
string name = System.Text.Encoding.GetEncoding("gb2312").GetString(b);
Response.Write(name);
说明: 看来十六进制转换成字符串没问题
4.日本人,韩国人,希腊人......也不爽了,他们也想使用自己的语言来使用计算机.
于是日语,韩语,希腊语......也需要转换成二进制.
日语使用XXX进行编码,韩语使用XXX进行编码,希腊语使用XXX进行编码......
看来这不是个办法,我们需要统一的编码才行.
UTF-8编码,Unicode编码来了,他们两兄弟志在统一全球的编码.就也是为什么现在JavaScript,Java等许多语言的char都是
使用Unicode编码,都是两个字节,而不在是一个字节,就是以全球化为目的.
统一的编码有什么好处呢?看看Google
使用Google搜索,有时你会看到搜索的内容中出现日语,咦,怎么不是乱码呢?
因为Google使用UTF-8编码:<meta http-equiv=content-type content="text/html; charset=UTF-8">
那百度呢?百度使用gb2312编码:<meta http-equiv="content-type" content="text/html;charset=gb2312">
所以如果有朝一日你在百度的搜索内容中看到日文,你看到的也将是乱码.
那为什么百度不用UTF-8编码呢? :) 我也不知道,你可以问李彦宏. :)
5.那UTF-8与Unicode有什么区别呢?
UTF-8对一个字母将使用一个字节编码.
UTF-8对一个汉字将使用三个字节编码.
Unicode对字母或汉字都使用两个字节编码.
Unicode也就是UTF-16
实验八:使用UTF8与Unicode编码 a,b
Response.Write(BitConverter.ToString(System.Text.Encoding.Unicode.GetBytes("ab")));
输出:61-00-62-00
说明: 'a' 使用UTF-8编码对应61(十六进制) 即二进制0011 1101 为一个字节
'b' 使用UTF-8编码对应62(十六进制) 即二进制0011 1110 为一个字节
'a' 使用Unicode即UTF-16编码对应61 00(十六进制) 即二进制 0011 1101 0000 0000 为两个字节
'b' 使用Unicode即UTF-16编码对应62 00(十六进制) 即二进制 0011 1110 0000 0000 为两个字节
注意了:如果使用
for (int i = 0; i < b.Length; i++)
Response.Write(b[i].ToString("x") + " ");
那怎么办呢?使用String.PadLeft(2,'0').
for (int i = 0; i < b.Length; i++)
Response.Write(b[i].ToString("x").PadLeft(2, '0'));
那我们来看下一个通用的MD5加密算法,它就用到了我们上面的知识.
using System;using System.Security.Cryptography;public class SecurityHelper {
{

 public static string MD5(string str)
public static string MD5(string str) {
{ byte[] b = System.Text.Encoding.Unicode.GetBytes(str); MD5 md5 = new MD5CryptoServiceProvider(); //等价MD5 md5 = MD5.Create() b = md5.ComputeHash(b); string ret = ""; for(int i = 0; i < b.Length; i++) ret += b[i].ToString("x").PadLeft(2,'0'); return ret;
byte[] b = System.Text.Encoding.Unicode.GetBytes(str); MD5 md5 = new MD5CryptoServiceProvider(); //等价MD5 md5 = MD5.Create() b = md5.ComputeHash(b); string ret = ""; for(int i = 0; i < b.Length; i++) ret += b[i].ToString("x").PadLeft(2,'0'); return ret; }
} }
}或者把MD5 md5 = new MD5CryptoServiceProvider(); 换成 SHA1 sha1 = new SHA1CryptoServiceProvider();
MD5与SHA1为抽象类,MD5CryptoServiceProvider继承MD5与SHA1CryptoServiceProvider继承SHA1
但小菜觉得使用SHA1+盐度加密会更帅一点. :)
实验九:使用UTF-8与Unicode编码 "小菜"
Response.Write(BitConverter.ToString(System.Text.Encoding.Unicode.GetBytes("小菜")));
输出:0F-5C-DC-83
说明: '小' 使用UTF-8编码对应 E5 B0 8F (十六进制3个字节)
'菜' 使用UTF-8编码对应 E8 8F 9C (十六进制3个字节)
'小' 使用Unicode编码对应 0F 5C (十六进制2个字节)
'菜' 使用Unicode编码对应 DC 83 (十六进制2个字节)
6.在.Net中,我们可以使用System.Text.Encoding.Default自动获取当前系统当前代码页的编码.
你可以试试:Response.Write(System.Text.Encoding.Default.EncodingName);
输出:简体中文(GB2312).表示系统的当前代码页的编码为简体中文(GB2312).
但小菜并不推荐使用Encoding.Default,在不同编码的计算机中运行的话,编码将出现不一致.
小菜推荐直接使用UTF-8或Unicode编码.
第二部份:System.Text.Encoding中的简单工厂模式(小菜参考了代震军的Factory模式)
我们先来看看System.Text中编码的组织.
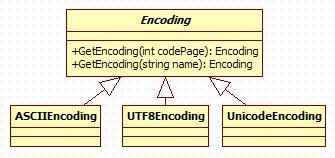
Encoding是抽象类,又是简单工厂.因为它可以使用GetEncoding(codePage)与GetEncoding(name)来创建相应的Encoding类,我们通常会将创建Encoding的逻辑代码独立出来,放入一个简单工厂类中方便管理,.Net Framework的作法是将二者融合.
public abstract class Encoding{ private static Encoding defaultEncoding; //当前系统代码页的编码 private static Encoding asciiEncoding; //ASCII编码 private static Encoding utf8Encoding; //UTF-8编码 private static Encoding unicodeEncoding; //Unicode编码 private static Hashtable encodings; //缓存已经调用过的编码集合 public static Encoding Default { //使用lazy-init get { if (defaultEncoding == null) defaultEncoding = CreateDefaultEncoding();//初始化 return defaultEncoding; } } public static Encoding ASCII { //使用lazy-init get { if (asciiEncoding == null) asciiEncoding = new ASCIIEncoding(); return asciiEncoding; } } public static Encoding Unicode { //使用lazy-init get { if (unicodeEncoding == null) unicodeEncoding = new UnicodeEncoding(false, true); return unicodeEncoding; } } public static Encoding UTF8 { //使用lazy-init get { if (utf8Encoding == null) utf8Encoding = new UTF8Encoding(true); return utf8Encoding; } } //通过编码名称获取Encoding如GetEncoding(gb2312) public static Encoding GetEncoding(String name) { return (GetEncoding(EncodingTable.GetCodePageFromName(name))); } //通过codepage获取Encoding如GetEncoding(936) public static Encoding GetEncoding(int codepage) { if (codepage < 0 || codepage > 65535) { //抛出异常 } Encoding result = null;//我们需要的编码 if (encodings != null) result = (Encoding)encodings[codepage];//看看我们的encodings中是否已经缓存了该编码 if (result == null) { //encodings中未缓存了该编码 lock (InternalSyncObject) { //当encodings还未初始化则初始化,用来缓存已经调用过的编码方式,提高速度. if (encodings == null) encodings = new Hashtable(); //double-check防止另一个线程已经添加了该编码,而当前线程还未添加该编码,会导致encodings中有重复的编码 //不理解的打屁屁,在单件模式那篇中小菜已经强调了. if ((result = (Encoding)encodings[codepage])!=null) return result; //根据codepage取得相应的Encoding switch (codepage) { case CodePageDefault: // 0, default code page result = Encoding.Default; break; case CodePageUnicode: // 1200, Unicode result = Unicode; break; case CodePageBigEndian: // 1201, big endian unicode result = BigEndianUnicode; break; case CodePageWindows1252: // 1252, Windows result = new SBCSCodePageEncoding(codepage); break; case CodePageUTF8: // 65001, UTF8 result = UTF8; break; case CodePageNoOEM: // 1 case CodePageNoMac: // 2 case CodePageNoThread: // 3 case CodePageNoSymbol: // 42 throw new ArgumentException(Environment.GetResourceString( "Argument_CodepageNotSupported", codepage), "codepage"); case CodePageASCII: // 20127 result = ASCII; break; case ISO_8859_1: // 28591 result = Latin1; break; default: { result = GetEncodingCodePage(codepage); if (result == null) result = GetEncodingRare(codepage); );//比较少用的编码 break; } } encodings.Add(codepage, result);//添加入encodings缓存该编码 } } return result; } }我们前面实验过byte[] b = System.Text.Encoding.GetEncoding("gb2312").GetBytes("小菜");这段代码.
调用过程是怎么样呢?
1.System.Text.Encoding.GetEncoding("gb2312")
2.调用return GetEncoding(EncodingTable.GetCodePageFromName("gb2312"))
3.EncodingTable.GetCodePageFromName("gb2312")返回936
也就是gb2312对应的codepage.
不信你可以试试Response.Write(System.Text.Encoding.GetEncoding("gb2312").CodePage);输出936
4.调用GetEncoding(936)会到GetEncodingCodePage(936)中寻找,未找到result==null
5.调用GetEncodingRare(936)去寻找.
private static Encoding GetEncodingRare(int codepage){ Encoding result; switch (codepage) { // 有好多case省略,详见源码 // DuplicateEUCCN为常量51936 EUCCN为常量936,二者被放为是等价的. // 注意现在GB2312已经被称为EUCCN codepage为936 case DuplicateEUCCN: case ISOSimplifiedCN: result = new DBCSCodePageEncoding(codepage, EUCCN); // Just maps to 936 break; // 有好多case详见源码 default: // Not found, already tried codepage table code pages in GetEncoding() throw new NotSupportedException( Environment.GetResourceString("NotSupported_NoCodepageData", codepage)); } return result;}GetEncodingRare中是主要用来放比较少用的编码,也是用来扩展之用.
简单工厂最怕什么? 添加新类型,需要修改switch{}代码.
.Net Framework主要通过GetEncodingRare来扩展.但并不是个好方法,因为还是得修改GetEncodingRare中的switch{}来添加新编码.可能编码已经相对稳定了,添加新编码的可能性比较低了.所以.Net Framework在3.0中也还未改动这部份代码.
那让我们看看Mono中是如何考虑的.
static Encoding GetEncoding (int codePage){ if (codePage < 0 || codePage > 0xffff) throw new ArgumentOutOfRangeException ("codepage", "Valid values are between 0 and 65535, inclusive."); switch (codePage) { case 0: return Default; case ASCIIEncoding.ASCII_CODE_PAGE: return ASCII; case UTF7Encoding.UTF7_CODE_PAGE: return UTF7; case UTF8Encoding.UTF8_CODE_PAGE: return UTF8; case UTF32Encoding.UTF32_CODE_PAGE: return UTF32; case UTF32Encoding.BIG_UTF32_CODE_PAGE: return BigEndianUTF32; case UnicodeEncoding.UNICODE_CODE_PAGE: return Unicode; case UnicodeEncoding.BIG_UNICODE_CODE_PAGE: return BigEndianUnicode; case Latin1Encoding.ISOLATIN_CODE_PAGE: return ISOLatin1; default: break; } // Try to obtain a code page handler from the I18N handler. Encoding enc = (Encoding)(InvokeI18N ("GetEncoding", codePage)); if (enc != null) { enc.is_readonly = true; return enc; } // Build a code page class name. String cpName = "System.Text.CP" + codePage.ToString (); // Look for a code page converter in this assembly. Assembly assembly = Assembly.GetExecutingAssembly (); Type type = assembly.GetType (cpName); if (type != null) { enc = (Encoding)(Activator.CreateInstance (type)); enc.is_readonly = true; return enc; } // Look in any assembly, in case the application // has provided its own code page handler. type = Type.GetType (cpName); if (type != null) { enc = (Encoding)(Activator.CreateInstance (type)); enc.is_readonly = true; return enc; } // We have no idea how to handle this code page. throw new NotSupportedException (String.Format ("CodePage {0} not supported", codePage.ToString ()));}有没有看到String cpName = "System.Text.CP" + codePage.ToString (); 然后通过反射创建该对象.
比如我们添加了一个新编码gb2312 可以创建一个System.Text.CP963 类,那么Encoding.GetEncoding(936)在前面的switch还有InvokeI18N("GetEncoding",codePage);还找不到对应的编码的话,就会使用反射System.Text.CP963 类
所以在.Net中反射用在工厂中很常见,通常都是为了解决新添加类型导致修改switch{}代码的情况.
:) 就到这里,欢迎大家提意见.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号