

微软的.Net Framework源码到:http://www.cnblogs.com/ghost_boy/archive/2008/07/16/1244229.html 下载.
Mono的.Net Framework源码到:http://go-mono.com/sources-stable/ 下载第一个,现在是mono-1.9.1.tar.bz2.
两个源码质量都很高,反正就是比小菜高.
从System.Collections开始吧,集合对于我们来说太熟悉不过了,我们天天都在用它.
Array,ArrayList,Stack,Queue等等
而且现在小菜热血沸腾,要不等下灭了就不好了.
一)当foreach还未来到这个世界,遍历集合的世界是怎么样的? (挺黑暗的,不信啊,那你接着往下瞧)
 public class Person
public class Person {
{

 private string _name; private int _age; public Person(string name,int age)
private string _name; private int _age; public Person(string name,int age) {
{ _name = name; _age = age;
_name = name; _age = age; } public string Name { get{ return _name; } } public int Age { get{ return _age; } }
} public string Name { get{ return _name; } } public int Age { get{ return _age; } } }static void Main(string[] args){ Array persons = Array.CreateInstance(typeof(Person), 4); persons.SetValue(new Person("小东", 10), 0); persons.SetValue(new Person("小西", 11), 1); persons.SetValue(new Person("小南", 12), 2); persons.SetValue(new Person("小北", 13), 3); for (int i = 0; i < persons.Length; i++) { Console.WriteLine("姓名:" + ((Person)persons.GetValue(i)).Name); Console.WriteLine("年龄:" + ((Person)persons.GetValue(i)).Age); }}
}static void Main(string[] args){ Array persons = Array.CreateInstance(typeof(Person), 4); persons.SetValue(new Person("小东", 10), 0); persons.SetValue(new Person("小西", 11), 1); persons.SetValue(new Person("小南", 12), 2); persons.SetValue(new Person("小北", 13), 3); for (int i = 0; i < persons.Length; i++) { Console.WriteLine("姓名:" + ((Person)persons.GetValue(i)).Name); Console.WriteLine("年龄:" + ((Person)persons.GetValue(i)).Age); }}看看小菜做了些什么,噢,小菜使用Array来存储Person,并且遍历该Array
一些朋友开始不满了,小菜你就让我们看这个啊,这也太简单了吧.( :) 那让我们接着往下看,会有更多惊喜)
static void Main(string[] args){ ArrayList persons = new ArrayList(); persons.Add(new Person("小东",10)); persons.Add(new Person("小西",11)); persons.Add(new Person("小南",12)); persons.Add(new Person("小北",13)); for(int i=0; i<persons.Count; i++) { Console.WriteLine("姓名:" + ((Person)persons[i]).Name); Console.WriteLine("年龄:" + ((Person)persons[i]).Age); }}我们先来看看ArrayList与Array遍历的不同之处吧!
1)Array使用persons.Length来确定长度,ArrayList使用persons.Count来确定长度.
2)Array使用persons.GetValue(i)来取出当前元素,ArrayList使用persons[i]来取出当前元素.
一些朋友开始抱怨代码还是太简单了,那就来个有难度点的Stack(栈)
不知道大家还记不记得这个数组结构中的老大级人物(后进先出)
static void Main(string[] args){ Stack persons = new Stack(); persons.Push(new Person("小东",10)); persons.Push(new Person("小西",11)); persons.Push(new Person("小南",12)); persons.Push(new Person("小北",13)); for(int i=0; i< persons.Count;) { Person p = (Person)persons.Pop(); Console.WriteLine("姓名:" + p.Name); Console.WriteLine("年龄:" + p.Age); } /* //我们还可以使用下面这种方式遍历persons while(persons.Count!=0) { Person p = (Person)persons.Pop(); Console.WriteLine("姓名:" + p.Name); Console.WriteLine("年龄:" + p.Age); } */} 不知道有没有朋友产生疑问?
问题1) for(int i=0; i<persons.Count;)中怎么没有i++啊?
问题2) 将for(int i=0; i<persons.Count;){/*省略*/} 省略中的代码替换成如下代码又会出现什么问题呢?
Console.WriteLine("姓名:" + ((Person)persons.Pop()).Name);
Console.WriteLine("姓名:" + ((Person)persons.Pop()).Name);
输出结果: 姓名:小北 年龄:13 姓名:小西 年龄:11
?奇了怪了怎么小南与小东没有被输出呢
至于为什么,我们来走一遍运行过程吧.
1. i=0; persons.Count=4; p= 小北
2. i=0; persons.Count=3; p= 小南
3. i=0; persons.Count=2; p= 小西
4. i=0; persons.Count=1; p= 小东
Stack中的Pop会返回栈顶元素,并弹出,所以会将count减一,并且数组的索引减一.
所以使用上面的代码,Pop()两次,相当于count减二,数组的索引减二,所以小南和小东不会被输出.
我们通过Stack中的关键源码来加深下理解.
public class Stack{ private object[] contents; private int current = -1; private int count; private int capacity; const int default_capacity = 16; public Stack () { contents = new object[default_capacity]; capacity = default_capacity; } //压入元素 public virtual void Push(Object o) { if (capacity == count) { Resize(capacity * 2);//容量已满,重设大小,扩大一倍 } count++; current++; contents[current] = o; } //返回栈顶元素,并弹出 public virtual object Pop() { if (current == -1) { throw new InvalidOperationException(); } else { object ret = contents[current]; contents [current] = null; count--; current--; if (count <= (capacity/4) && count > 16) { //弹出元素后,元素个数少于容量的4分之1,重设容量,容量缩小一倍 Resize(capacity/2); } return ret; } } //重设容量 private void Resize(int ncapacity) { ncapacity = Math.Max (ncapacity, 16); object[] ncontents = new object[ncapacity]; Array.Copy(contents, ncontents, count); capacity = ncapacity; contents = ncontents; }}看来我们遇到麻烦了,如果我们不理解Stack这个数据结构,那么对它的遍历操作我们将无法实现.
我们的设计一直提倡针对接口编程,而现在我们却在针对实现编程,看来挺失败的.
具体的数据结构将在很大程度上影响我们的实现.
如果你明白了这一句话那么小菜就没有必要在举例: 队列Queue,哈希表HashTable等等了,小菜也轻松了. :)
二)foreach将我们脱离了苦海.(那么是谁让foreach脱离了苦海呢?)
Iterator模式让foreach脱离苦海.
接下来就让我们进入迭代模式(Iterator模式),这个都快被大家遗忘的模式.
我们先来看看foreach的实现吧!
static void Main(string[] args){ //persons可以是上面的Array,ArrayList,Stack的任何一种 foreach (Person p in persons) { Console.WriteLine("姓名:" + p.Name); Console.WriteLine("姓名:" + p.Age); }}确实简单,我们无需知道遍历集合的任何比较细节.
我们无需知道遍历集合的任何实现.
那foreach是怎么做到的呢?
我们来看看foreach被翻译成什么(代码已简化)
IEnumerator enumerator = persons.GetEnumerator();//persons可以是上面的Array,ArrayList,Stack的任何一种try{ while(enumerator.MoveNext()) { Person name = (Person)enumerator.Current; Console.WriteLine("姓名:" + p.Name); Console.WriteLine("年龄:" + p.Age); }}finally{ if(enumerator) { ((IDisposable)enumerator).Dispose(); }}这时我们将用到一个最重要的设计原则: 对象的职责划分
对象集合的职责是存储对象,遍历对象集合的行为是不属于集合的职责.
所以我们可以将遍历对象集合的行为独立出来成为接口:IEnumerator
对象集合遍历的操作不外乎:1.判断是否还有下一个元素 MoveNext() 2.取出当前元素 Current
那么我们就来定义一个接口吧:IEnumerator(称为枚举器,名称不同罢了,功能是相同的,和java中的接口Iterator迭代器一样)
public interface IEnumerator{ object Current { get; } bool MoveNext();}从Array开始吧.
public abstract class Array : IEnumerable{ private Array()//私有构造函数,无法被实例化 { } public IEnumerator GetEnumerator() { int lowerBound = GetLowerBound(0); //获取第一维的索引下限 if (Rank == 1 && lowerBound == 0) //如果是一维,并且第一维的索引下限为0 return new SZArrayEnumerator(this); else return new ArrayEnumerator(this, lowerBound, Length); } private sealed class SZArrayEnumerator : IEnumerator { private Array _array; private int _index; private int _endIndex; //索引终点 internal SZArrayEnumerator(Array array) { _array = array; _index = -1; _endIndex = array.Length; } public bool MoveNext() { if (_index < _endIndex) { _index++; return (_index < _endIndex); } return false; } public Object Current { get { if (_index < 0) throw new InvalidOperationException("还没开始")); if (_index >= _endIndex) throw new InvalidOperationException("已经到头了"); return _array.GetValue(_index); } } }}
这里说下:return new SZArrayEnumerator(this)表示遍历的数组为一维的时候使用它.
return new ArrayEnumerator(this,lowerBound,Length);表示遍历的数组为多维的时候使用它.
lowerBound: 为第一维的下限
Lenght: 为所有维数中元素的总数
遍历多维的实现也很有趣,主要使用两个函数一个属性:
1.array.GetUpperBound(i) i维的上限 2.array.GetLowerBound(i) i维的下限 3.array.Rank 有几维
如果你对具体实现感兴趣,那就打开你手中的.Net Framework中的Array.cs源码吧.
按这样说,那ArrayList也应该有类似的实现.那就让我们来看看ArrayList的源码,来验证这个想法.
public class ArrayList{ public virtual IEnumerator GetEnumerator() { return new ArrayListEnumeratorSimple(this); } private sealed class ArrayListEnumeratorSimple : IEnumerator { private ArrayList _list; private int _index; private int _endIndex; internal ArrayListEnumeratorSimple(ArrayList list) { _list = list; _index = -1; _endIndex = list.Count; } public bool MoveNext() { if (_index < _endIndex) { _index++; return (_index < _endIndex); } return false; } public Object Current { get { if (_index < 0) throw new InvalidOperationException("还没开始"); if (_index >= _endIndex) throw new InvalidOperationException("已经到头"); return _list[_index]; } } }}
看来事实验证了我们的想法.
还有什么可以改进的呢?
我们看到Array与ArrayList等各对象集合都实现了 IEnumerator GetEnumerator()
那么我们是不是应该为它们定义一个接口呢?当然. IEnumerable
public interface IEnumerable{ IEnumerator GetEnumerator();}现在就让我们来看看UML图,让我们更清晰点.
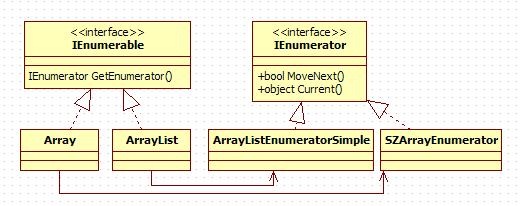
这便是迭代模式.
它在.Net Framework中真可谓无处不在.
string name = "a-peng";foreach(char c in name){ Console.WriteLine(c);}(应该会联想到迭代模式吧,foreach便是它给予的魔力,如果还联想不到,那小菜真是太失败了)
看来string也应该有提供类似的代码.否则它怎么能foreach呢?
那就让我们来看看String的代码吧.(string是String的别名而已)
public sealed class String : IEnumerable{ public CharEnumerator GetEnumerator() { return new CharEnumerator(this); } public IEnumerator IEnumerable.GetEnumerator() { return new CharEnumerator(this); }}类似之前的Array中的SZArrayEnumerator 还有 ArrayList中的ArrayListEnumeratorSimple
public sealed class CharEnumerator : IEnumerator{ private string _str; private int _index; private int _length; internal CharEnumerator(string str) { _str = str; _index = -1; _length = str.Length; } public bool MoveNext() { if (_index < _length) { _index++; return (_index < _length); } return false; } object IEnumerator.Current { get { if (_index == -1 || _index >= _length) throw new InvalidOperationException("索引值无效"); return _str[_index]; } }}.Net在2.0的时候引入了泛型,所以也对IEnumerable和IEnumerator做了改进.
引入了IEnumerable<T>与IEnumerator<T>
using System;namespace System.Collections.Generic{ public interface IEnumerable<T> : IEnumerable { new IEnumerator<T> GetEnumerator(); }}using System;namespace System.Collections.Generic{ public interface IEnumerator<T> : IDisposable, IEnumerator { new T Current { get; } }}那看来小菜也要与时俱进.来实现个.
using System;using System.Collections.Generic;namespace APeng{ public class Persons : IEnumerable<Person>,System.Collections.IEnumerable { private const int MAX_PERSONS = 4; private Person[] _persons; private int _index = 0; public Persons() { _persons = new Person[MAX_PERSONS]; } public void AddPerson(string name, int age) { Person p = new Person(name, age); if (_index >= MAX_PERSONS) throw new InvalidOperationException("容量已超出"); else { _persons[_index] = p; _index++; } } //隐式实现System.Collections.Generic.IEnumerable<T>接口 public IEnumerator<Person> GetEnumerator() { return new PersonEnumerator(_persons); } //显示实现System.Collections.IEnumerable接口 System.Collections.IEnumerator System.Collections.IEnumerable.GetEnumerator() { return new PersonEnumerator(_persons); } private class PersonEnumerator : IEnumerator<Person>, System.Collections.IEnumerator { private Person[] _list; private int _index; private int _length; internal PersonEnumerator(Person[] list) { _list = list; _index = -1; _length = list.Length; } public void Dispose() { } public bool MoveNext() { if (_index < _length) { _index++; return (_index < _length); } return false; } //隐式实现System.Collections.Generic.IEnumerator<T>接口 public Person Current { get { if (_index == -1 || _index >= _length) throw new InvalidOperationException("索引值无效"); return _list[_index]; } } //显示实现System.Collections.IEnumerator接口 object System.Collections.IEnumerator.Current { get { return Current; } } void System.Collections.IEnumerator.Reset() { _index = -1; } } }}其实上面的public class Persons : IEnumerable<Person>,System.Collections.IEnumerable
完全可以用public class Persons : IEnumerable<Person>来替换,不过为了增强代码的可读性,所以小菜加上.
这种做法很类似微软的ArrayList : IList , ICollection, IEnumerable 也可被替换为 ArrayList : IList
需要注意的地方
1.实现IEnumerable<T> 要记得实现IEnumerable
2.同理实现IEnumerator<T> 要记得实现IEnumerator和IDisposable
那接下来就来使用Persons吧
static void Main(string[] args){ Persons persons = new Persons(); persons.AddPerson("小东", 10); persons.AddPerson("小西", 11); persons.AddPerson("小南", 12); persons.AddPerson("小北", 13); //第一种遍历方法 IEnumerator<Person> enumerator = persons.GetEnumerator(); while (enumerator.MoveNext()) { Console.WriteLine("姓名:" + enumerator.Current.Name); Console.WriteLine("年龄:" + enumerator.Current.Age); } //第二种遍历方法 foreach (Person p in persons) { Console.WriteLine("姓名:" + p.Name); Console.WriteLine("年龄:" + p.Age); }}其实上面的两种遍历方法是等效的,可相互转换.
四)有没有更简单的实现方式啊.有使用yield (在.Net2.0中引入的关键字)
using System;using System.Collections.Generic;namespace APeng{ public class Persons : IEnumerable<Person>,System.Collections.IEnumerable { private const int MAX_PERSONS = 4; private Person[] _persons; private int _index = 0; public Persons() { _persons = new Person[MAX_PERSONS]; } public void AddPerson(string name, int age) { Person p = new Person(name, age); if (_index >= MAX_PERSONS) throw new InvalidOperationException("容量已超出"); else { _persons[_index] = p; _index++; } } public IEnumerator<Person> GetEnumerator() { for (int i = 0; i < _persons.Length; i++) yield return _persons[i]; } System.Collections.IEnumerator System.Collections.IEnumerable.GetEnumerator() { for (int i = 0; i < _persons.Length; i++) yield return _persons[i]; } }}通过yield告诉编译器在什么时候返回什么值,再由编译器自动完成实现IEnumerator<Person>接口的登记工作。
我们还可以使用yield break语句支持从迭代块中直接结束.
:) 就到这里.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号