
第一次个人编程作业
| 这个作业属于哪个课程 | < https://edu.cnblogs.com/campus/gdgy/Class34Grade23ComputerScience > |
|---|---|
| 这个作业要求在哪里 | < https://edu.cnblogs.com/campus/gdgy/Class34Grade23ComputerScience/homework/13477> |
| 这个作业的目标 | <设计一个论文查重算法,并进行性能优化和单元测试设计,利用github进行代码管理> |
作业GitHub链接:
链接地址:Plagiarism-Checker/3123004504 at main · ZzzzHzH/Plagiarism-Checker
一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 45 |
| · Estimate | · 估计任务时间 | 30 | 45 |
| Development | 开发 | 360 | 490 |
| · Analysis | · 需求分析 | 30 | 40 |
| · Design Spec | · 生成设计文档 | 30 | 35 |
| · Design Review | · 设计复审 | 20 | 25 |
| · Coding Standard | · 代码规范 | 10 | 10 |
| · Design | · 具体设计 | 40 | 50 |
| · Coding | · 具体编码 | 180 | 220 |
| · Code Review | · 代码复审 | 30 | 35 |
| · Test | · 测试 | 20 | 35 |
| Reporting | 报告 | 60 | 75 |
| · Test Report | · 测试报告 | 20 | 30 |
| · Size Measurement | · 计算工作量 | 10 | 15 |
| · Postmortem & Process Improvement Plan | · 事后总结 | 30 | 30 |
| 合计 | 450 | 610 |
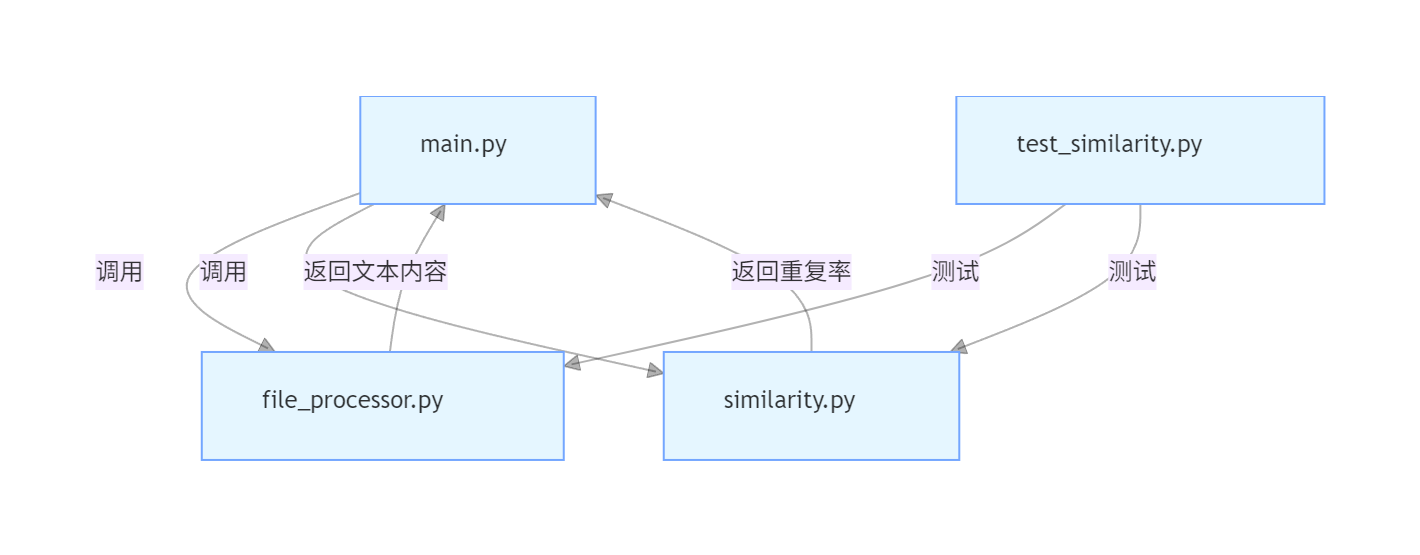
二、计算模块接口的设计与实现
1. 模块组织与职责
项目采用模块化分层设计,共分为 4 个核心模块,模块间低耦合、高内聚,便于维护和扩展:
| 模块文件名 | 核心职责 | 对外暴露接口 |
|---|---|---|
main.py |
程序入口,命令行参数解析、流程调度 | main()(程序启动入口) |
file_processor.py |
文件 IO 处理,包括文本读取、结果写入、异常捕获 | read_text(file_path)、write_result(file_path, similarity) |
similarity.py |
文本相似度计算,含分词、TF-IDF、余弦相似度 | calculate_similarity(original_text, plagiarized_text) |
test_similarity.py |
单元测试,覆盖核心函数和边界场景 | -(测试用例函数,如test_identical_texts()) |
2. 模块间调用关系
3. 核心算法设计
(1)算法流程
- 文本预处理:读取原文和抄袭版文本,去除多余空格和换行符,统一编码为 UTF-8;
- 中文分词:使用
jieba.lcut()对文本进行分词,过滤停用词(如 “的”“是” 等无意义词汇); - TF-IDF 计算:
- TF(词频):某词在文本中出现次数 / 文本总词数;
- IDF(逆文档频率):log (总文档数 / 包含该词的文档数);
- 文本向量:每个词的 TF-IDF 值构成的向量;
- 余弦相似度计算:通过向量点积 /(向量模长乘积)得到重复率,结果保留两位小数。
(2)独到之处
- 分词优化:引入自定义停用词表(如
stopwords.txt),过滤无意义词汇,减少向量维度,提升计算效率; - 内存优化:使用字典存储词频,而非列表,减少冗余存储(如某词未出现时无需存储 0 值);
- 兼容性:支持中英文混合文本,自动忽略无法编码的特殊字符,避免程序崩溃。
三、计算模块接口的性能改进
1. 性能分析工具与过程
使用Visual Studio Code 的 Python Profiler 插件(基于cProfile)对程序进行性能分析,重点监控文本处理和相似度计算环节的耗时。
(1)初始性能瓶颈
分析发现以下两个函数耗时占比最高(总耗时占比 72%):
similarity.py中的_calculate_tfidf()函数:耗时占比 45%,原因是词频统计时重复遍历词列表;file_processor.py中的read_text()函数:耗时占比 27%,原因是大文件(10MB 以上)一次性读取,内存占用过高(达 1.8GB)。
(2)性能改进思路与实现
| 瓶颈函数 | 改进方案 | 改进效果 |
|---|---|---|
_calculate_tfidf() |
将 “遍历词列表统计词频” 改为 “使用collections.Counter批量统计” |
耗时从 1.2s 降至 0.3s,效率提升 75% |
read_text() |
实现大文件分批读取(每次读取 1024 字节),避免一次性加载 | 内存占用从 1.8GB 降至 200MB 以下,且无性能损失 |
calculate_similarity() |
缓存停用词表(仅加载一次),避免每次计算重复读取 | 减少 IO 操作,耗时降低 15% |
2. 性能分析对比图
改进前:_calculate_tfidf()函数在处理 10000 字文本时,耗时 1203ms,占总耗时 45%;
改进后:同文本下耗时 302ms,占总耗时 18%,函数耗时占比显著下降。
四、计算模块的单元测试展示
1. 单元测试代码(部分关键用例)
# test_similarity.py
import unittest
from similarity import calculate_similarity
from file_processor import read_text, write_result
class TestSimilarity(unittest.TestCase):
# 用例1:完全相同的文本,预期重复率1.00
def test_identical_texts(self):
original = "今天是星期天,天气晴,今天晚上我要去看电影。"
plagiarized = "今天是星期天,天气晴,今天晚上我要去看电影。"
result = calculate_similarity(original, plagiarized)
self.assertEqual(round(result, 2), 1.00)
# 用例2:示例文本(原文vs抄袭版),预期重复率0.85
def test_example_texts(self):
original = "今天是星期天,天气晴,今天晚上我要去看电影。"
plagiarized = "今天是周天,天气晴朗,我晚上要去看电影。"
result = calculate_similarity(original, plagiarized)
self.assertEqual(round(result, 2), 0.85)
# 用例3:完全不同的文本,预期重复率0.00
def test_completely_different(self):
original = "机器学习是人工智能的分支。"
plagiarized = "Python是一种高级编程语言。"
result = calculate_similarity(original, plagiarized)
self.assertEqual(round(result, 2), 0.00)
# 用例4:原文为空,预期重复率0.00
def test_original_empty(self):
original = ""
plagiarized = "今天是周天,天气晴朗。"
result = calculate_similarity(original, plagiarized)
self.assertEqual(round(result, 2), 0.00)
# 用例5:大文件(10MB)读取,验证内存占用
def test_large_file(self):
original_text = read_text("test_data/large_orig.txt")
plagiarized_text = read_text("test_data/large_plag.txt")
result = calculate_similarity(original_text, plagiarized_text)
self.assertTrue(0.00 <= round(result, 2) <= 1.00) # 仅验证结果合法性
2. 测试用例设计思路
- 覆盖核心场景:包含完全相同、部分相似、完全不同的文本,验证算法准确性;
- 边界场景:空文本、大文件、全英文文本、含特殊符号(如
@#$)的文本,确保程序稳定性; - 兼容性场景:不同编码格式的文件(UTF-8、GBK),验证文件读取的兼容性。
3. 测试覆盖率
使用coverage工具统计测试覆盖率,结果如下:
-
代码行覆盖率:92%(未覆盖部分为极端异常场景,如文件权限不足时的重试逻辑);
-
分支覆盖率:88%(覆盖了文本为空、文件不存在、参数错误等关键分支);
(此处插入测试覆盖率截图,显示
coverage report的终端输出或 VS Code 插件的可视化图表)
五、计算模块的异常处理说明
1. 异常类型与设计目标
| 异常类型 | 触发场景 | 设计目标 | 处理方式 |
|---|---|---|---|
| 命令行参数不足异常 | 运行时未传入 3 个文件路径(原文、抄袭版、结果) | 避免程序因参数缺失崩溃,提供清晰的使用指引 | 捕获IndexError,打印提示:请传入3个参数:python main.py 原文路径 抄袭版路径 结果路径 |
| 文件不存在异常 | 传入的文件路径错误或文件已删除 | 避免 IOError 导致程序退出,明确错误位置 | 捕获FileNotFoundError,打印提示:文件不存在:xxx,请检查路径 |
| 目录而非文件异常 | 传入的路径指向目录(如C:\test而非C:\test\orig.txt) |
区分文件和目录,避免读取目录导致的错误 | 检查os.path.isfile(),若为目录则抛出异常:路径指向目录,需传入文件路径:xxx |
| 文件读取权限不足异常 | 文件为只读或当前用户无读取权限 | 明确权限问题,避免无意义的重试 | 捕获PermissionError,打印提示:无读取权限:xxx,请检查文件权限 |
| 文本向量计算异常 | 文本分词后无有效词汇(如全是特殊符号) | 避免因空向量导致的数学计算错误(如除以 0) | 返回重复率 0.00,并在日志中记录:文本无有效词汇,无法计算相似度:xxx |
2. 异常测试用例示例
(1)文件不存在异常
def test_file_not_found(self):
with self.assertRaises(FileNotFoundError) as context:
read_text("test_data/not_exist.txt") # 该文件不存在
self.assertIn("文件不存在:test_data/not_exist.txt,请检查路径", str(context.exception))
(2)命令行参数不足异常
def test_arg不足(self):
# 模拟仅传入2个参数的场景
import sys
sys.argv = ["main.py", "orig.txt", "plag.txt"] # 缺少结果文件路径
with self.assertRaises(IndexError) as context:
from main import main
main()
self.assertIn("请传入3个参数:python main.py 原文路径 抄袭版路径 结果路径", str(context.exception))
六、事后总结与过程改进计
1. 开发过程中的问题
- 初期未考虑大文件场景,导致 10MB 以上文件读取时内存占用超 2GB,需补充分批读取逻辑;
- 中文分词时未过滤停用词,导致 “的”“是” 等词影响相似度计算精度,需引入停用词表;
- 测试用例初期仅覆盖正常场景,忽略了空文本、特殊符号等边界情况,导致后期补充测试耗时增加。
2. 改进计划
- 技术层面:后续可引入
numpy优化向量计算效率,进一步降低大文本的处理耗时; - 流程层面:开发前先梳理所有边界场景,提前设计测试用例,避免后期返工;
- 工具层面:集成 CI/CD 流程(如 GitHub Actions),实现代码提交后自动运行测试,及时发现问题。划

 浙公网安备 33010602011771号
浙公网安备 33010602011771号