飞猪杭州旅游项目爬虫分析
飞猪杭州旅游项目爬虫分析
一、选题背景
随着网络技术的发展与应用,报旅行社、电话预定等方式已经不能够适应当今的发展要求,如今的各大专门做旅游的平台,如飞猪旅行、美团、携程、去哪儿等已经被广泛应用,从多方面角度分析来看,具有很大的开发价值和发展空间。飞猪旅行平台上提供国内外交通、酒店住宿、景区门票、目的地游玩等产品及旅游周边服务,可以为用户提供充足的信息以及快速的查询方式,本次课题通过飞猪旅行查询杭州项目对其爬虫分析。
二、设计方案
1.主题式网络爬虫名称
飞猪旅行杭州旅游项目爬虫系统
2.主题式网络爬虫爬取内容与数据特征分析
通过飞猪旅行开放平台对项目主题、价格、销售数、评论数内容爬取,同时对网页文本进行数据特征分析
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
(1)实现思路
①查看网页结构与网页爬取内容的位置,利用requests库获取网页数据
②遍历数据,利用xtree.xpath解析网页内容
③数据存储,利用open()函数创建表格模板、wirtelines()函数进行输出存储
(2)技术难点
①分析HTML的页面结构
②数据抓取及解析
③数据批量存储
④数据进行可视化处理
⑤页面及目标元素定位
⑥matplotlib绘图
三、实现步骤及代码
1.爬虫设计
(1)主题页面结构特征与特征分析
目标网址:https://travelsearch.fliggy.com/index.htm?spm=181.15077045.1398723350.1.48f3620d7UbQ9z&searchType=product&keyword=%E6%9D%AD%E5%B7%9E&category=MULTI_SEARCH&pagenum=72&conditions=v_from_city_not_abroad%3A%E6%9D%AD%E5%B7%9E
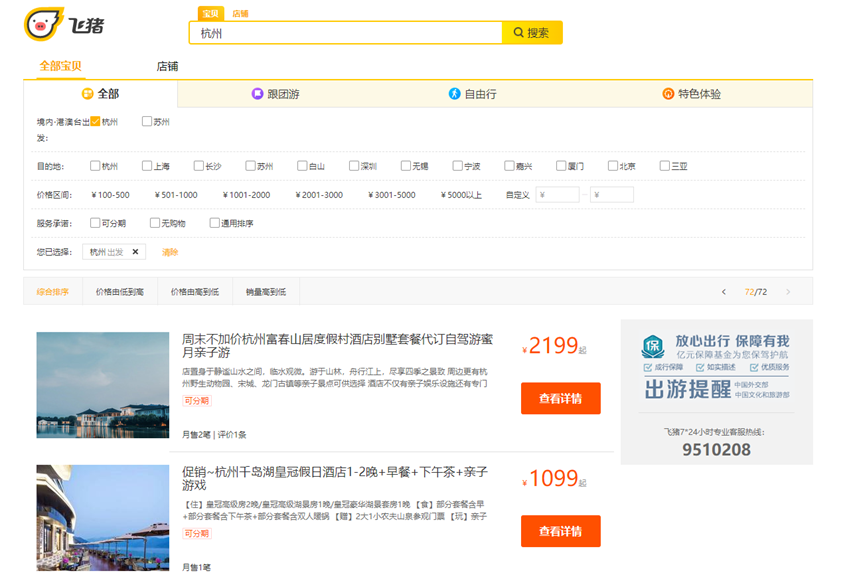
(2)Htmls页面解析
url= 'https://travelsearch.fliggy.com/index.htm?spm=181.15077045.1398723350.1.48f3620d7UbQ9z&searchType=product&keyword=%E6%9D%AD%E5%B7%9E&category=MULTI_SEARCH&pagenum='+str(page)+'&-1=popular&conditions=-1%3Apopular'
主题:
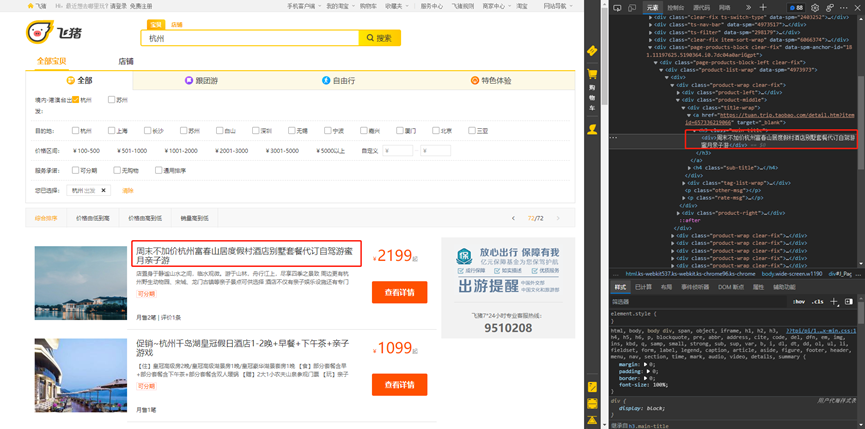
价格:
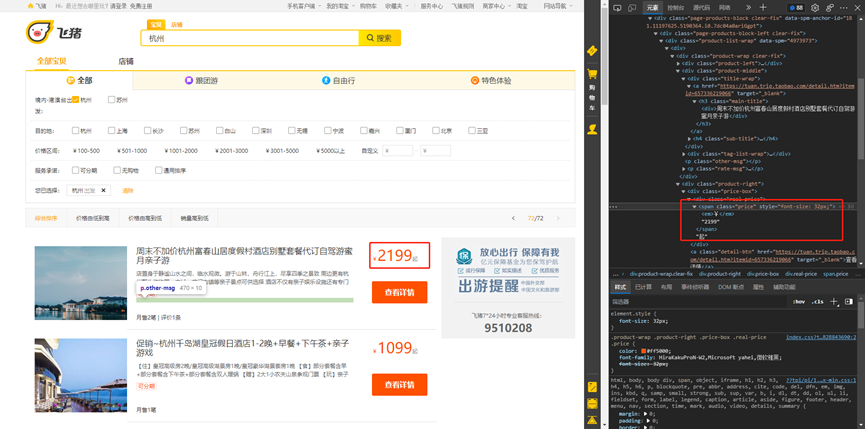
销售数:

评论数:
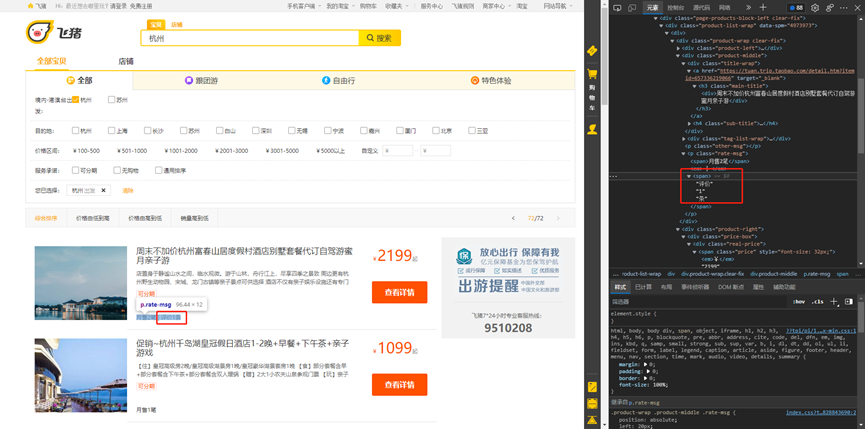
(3)节点查找方法与遍历方法
查找方法:
1 # 主题 2 title = html.xpath("//* 3 [@id='content']/div[6]/div[1]/div[1]/div/div[{}] 4 /div[2]/div[1]/a/h3/div/text()" 5 6 # 价格 7 price = html.xpath("//* 8 [@id='content']/div[6]/div[1]/div[1]/div/div[{}] 9 /div[3]/div/div/span/text()" 10 11 # 销售数 12 sell = html.xpath("//* 13 [@id='content']/div[6]/div[1]/div[1]/div/div[{}] 14 /div[2]/p[2]/span[1]/text()" 15 16 # 评论数 17 coumm = html.xpath("//* 18 [@id='content']/div[6]/div[1]/div[1]/div/div[{}] 19 /div[2]/p[2]/span[2]/text()"
遍历方法:
使用for循环将xpath定位的元素遍历出来。
(4)数据爬取与采集
1 # 综合排序 2 def synthesize(page): 3 # 创建Feizhu_synthesize.xlsx 4 file = open("Feizhu_synthesize.xlsx", "a") 5 file.write("title" + "," + "price" + "," + "sell" + "," + "coumm" + '\n') 6 file = file.close() 7 try: 8 for i in range(page): 9 # 请求访问 10 url = 'https://travelsearch.fliggy.com/index.htm?spm=181.15077045.1398723350.1.48f3620d7UbQ9z&searchType=product&keyword=%E6%9D%AD%E5%B7%9E&category=MULTI_SEARCH&pagenum='+str(page)+'&-1=popular&conditions=-1%3Apopular' 11 res = requests.get(url, headers=headers) 12 res.encoding = 'utf-8' 13 html = etree.HTML(res.text) 14 coun = 1 15 # 主题title、价格price、已售sell、评论数coumm 16 for i in range(48): 17 title = html.xpath("//*[@id='content']/div[6]/div[1]/div[1]/div/div[{}]/div[2]/div[1]/a/h3/div/text()".format(coun)) 18 for i in title: 19 title = i 20 price = html.xpath("//*[@id='content']/div[6]/div[1]/div[1]/div/div[{}]/div[3]/div/div/span/text()".format(coun)) 21 for i in price: 22 price = i 23 sell = html.xpath("//*[@id='content']/div[6]/div[1]/div[1]/div/div[{}]/div[2]/p[2]/span[1]/text()".format(coun)) 24 sell1 = [] 25 for i in sell: 26 sell = i.strip('月售') 27 sell = sell.strip('笔') 28 if sell == sell1: 29 sell = '0' 30 # print(sell) 31 coumm = html.xpath("//*[@id='content']/div[6]/div[1]/div[1]/div/div[{}]/div[2]/p[2]/span[2]/text()".format(coun)) 32 coumm1 = [] 33 for i in coumm: 34 if i in '评价': 35 pass 36 elif i in '条': 37 pass 38 elif int(i) > 1: 39 coumm = i 40 if coumm == coumm1: 41 coumm = '0' 42 coun += 1 43 # 保存数据 44 with open("Feizhu_synthesize.xlsx", "a", encoding='utf-8') as f2: 45 f2.writelines(title + "," + price + "," + sell + "," + coumm + "," + '\n') 46 print('主题:', title, '\n', 47 '价格:', price, '元\n', 48 '已售出:', sell, '笔\n', 49 '评论:', coumm, '条\n') 50 page +=1 51 time.sleep(1) 52 except: 53 pass
(5)爬虫系统运行演示

2.数据分析
导入数据:
1 import numpy as np 2 import pandas as pd 3 import matplotlib.pyplot as plt 4 Fz_data = pd.read_excel('Feizhu_synthesize.xlsx')
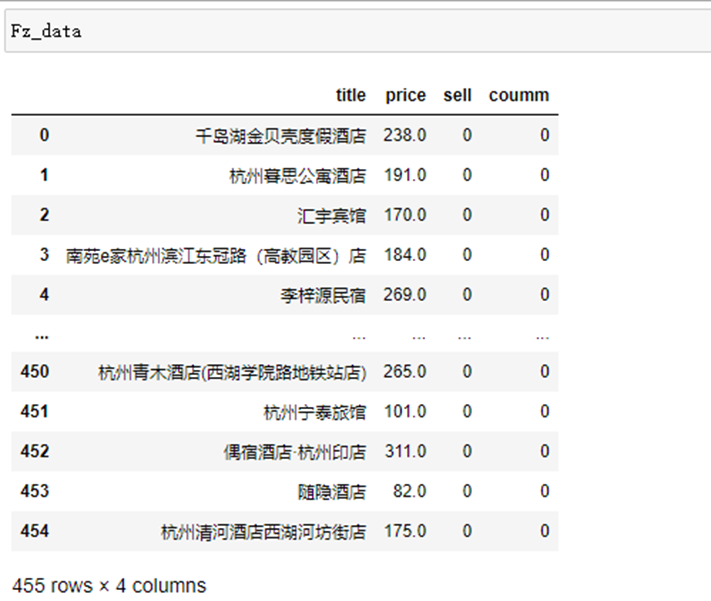
(1)数据清洗和处理
1 # 重复值处理 2 Fz_data = Fz_data.drop_duplicates() 3 # Nan处理 4 Fz_data = Fz_data.dropna(axis = 0) 5 # 删除无效行 6 Fz_data = Fz_data.drop([''], axis = 1) 7 # 空白值处理 8 Fz_data = Fz_data.dropna() 9 # 替换值 10 Fz_data.replace('条', '0',inplace = True) 11 Fz_data.replace('分', '0',inplace = True)
(2)数据分析与可视化
折线图:
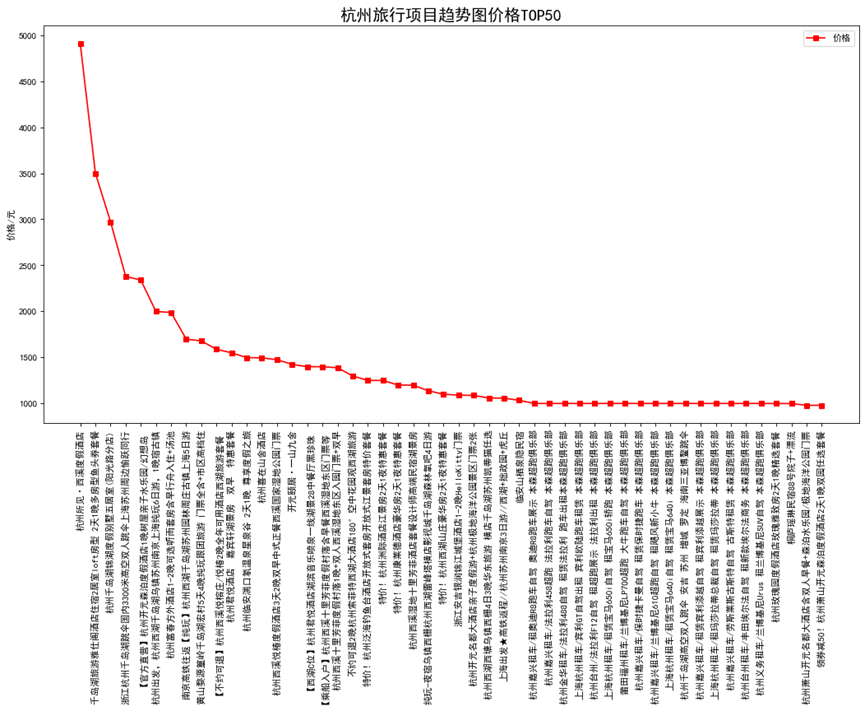
1 # 价格进行降序排列分析 2 Fz_data.sort_values(by=["price"],inplace=True,ascending=[False]) 3 x = Fz_data['title'].head(50) 4 y = Fz_data['price'].head(50) 5 fig = plt.figure(figsize=(16, 8), dpi=80) 6 plt.rcParams['font.sans-serif']=['SimHei'] # 用来正常显示中文标签 7 plt.rcParams['axes.unicode_minus']=False 8 plt.xticks(rotation=90) 9 plt.plot(x,y,'s-',color = 'r',label="价格")# s-:方形 10 plt.legend(loc = "best")# 图例 11 plt.title("杭州旅行项目趋势图价格TOP50",fontsize=18) 12 plt.ylabel("价格/元")# 纵坐标名字 13 plt.show()
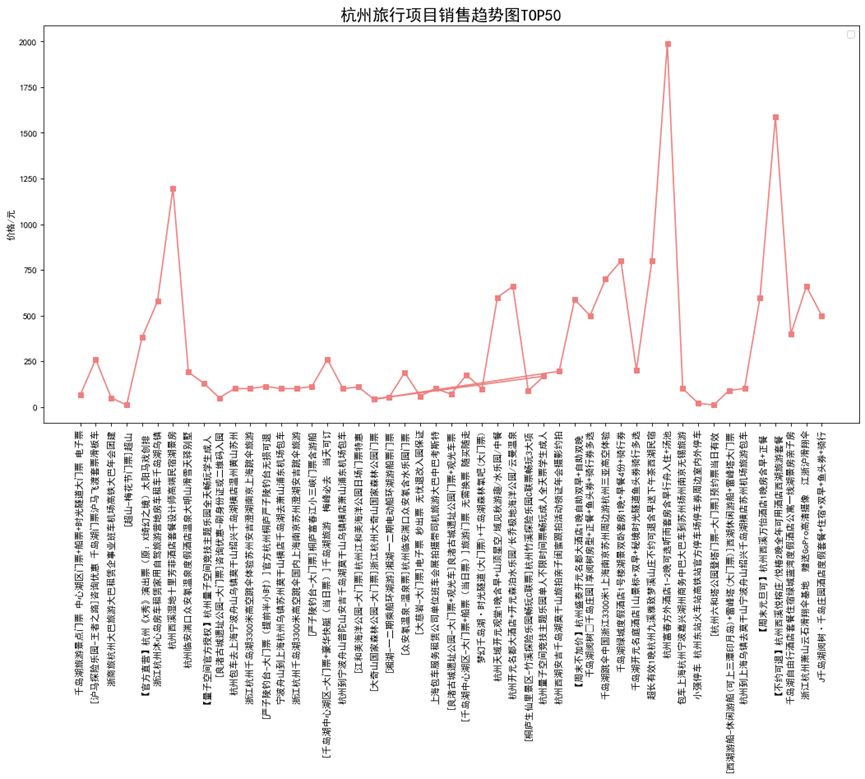
1 # 销售情况进行降序排列分析 2 Fz_data.sort_values(by=["sell"],inplace=True,ascending=[False]) 3 x = Fz_data['title'].head(50) 4 y = Fz_data['price'].head(50) 5 fig = plt.figure(figsize=(16, 8), dpi=80) 6 plt.rcParams['font.sans-serif']=['SimHei'] # 用来正常显示中文标签 7 plt.rcParams['axes.unicode_minus']=False 8 plt.xticks(rotation=90) 9 plt.plot(x,y,'s-',color = 'lightcoral')# s-:方形 10 plt.legend(loc = "best")# 图例 11 plt.title("杭州旅行项目销售趋势图TOP50",fontsize=18) 12 plt.ylabel("价格/元")# 纵坐标名字 13 plt.show()
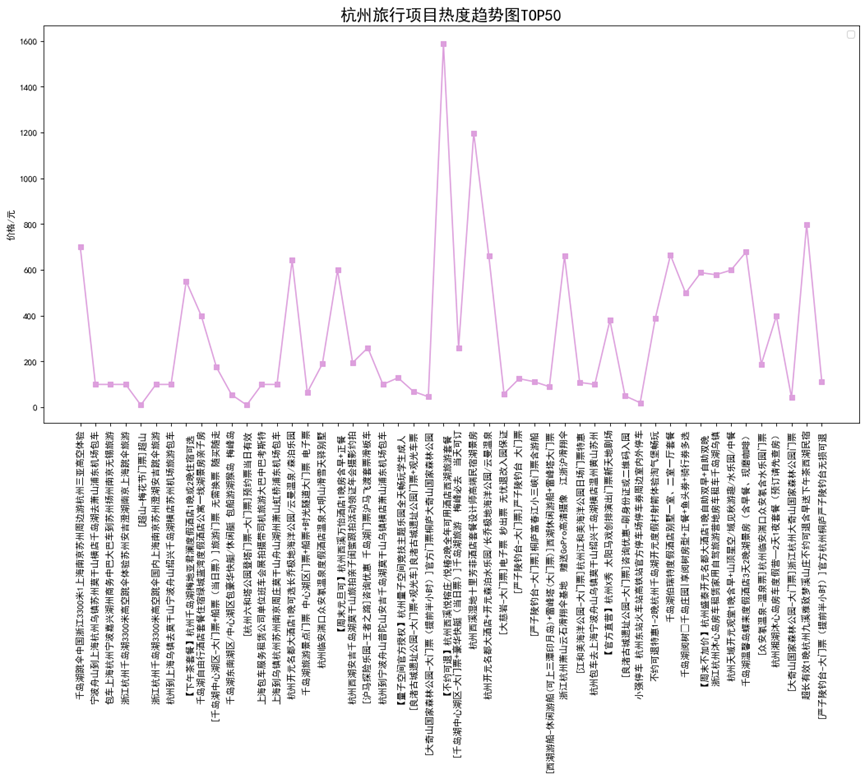
1 Fz_data.sort_values(by=["coumm"],inplace=True,ascending=[False]) 2 x = Fz_data['title'].head(50) 3 y = Fz_data['price'].head(50) 4 fig = plt.figure(figsize=(16, 8), dpi=80) 5 plt.rcParams['font.sans-serif']=['SimHei'] # 用来正常显示中文标签 6 plt.rcParams['axes.unicode_minus']=False 7 plt.xticks(rotation=90) 8 plt.plot(x,y,'s-',color = 'plum')# s-:方形 9 plt.legend(loc = "best")# 图例 10 plt.title("杭州旅行项目热度趋势图TOP50",fontsize=18) 11 plt.ylabel("价格/元")# 纵坐标名字 12 plt.show()
柱状图:
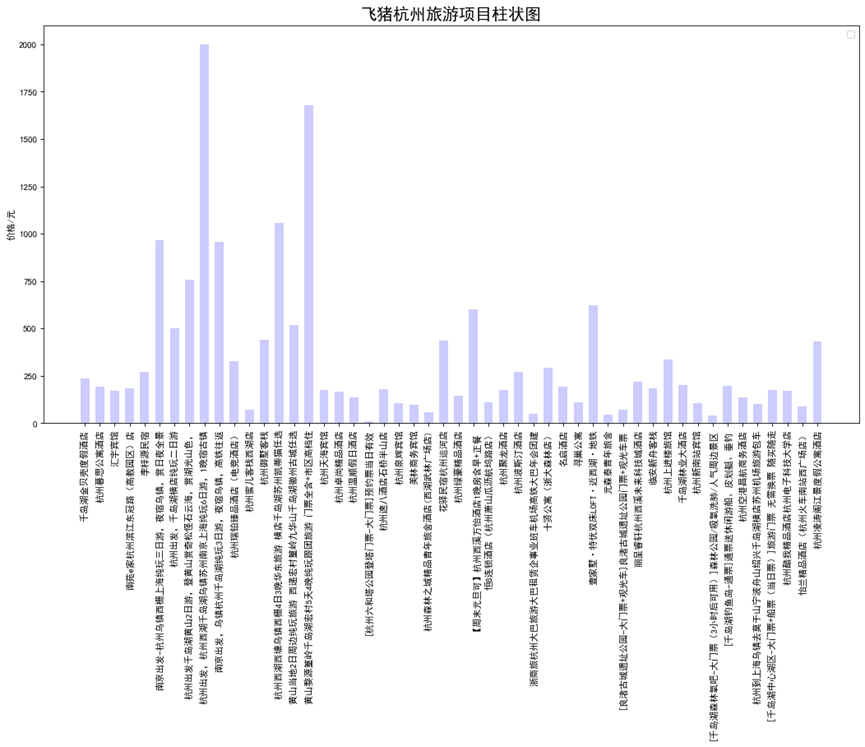
1 x = Fz_data['title'].head(50) 2 y = Fz_data['price'].head(50) 3 fig = plt.figure(figsize=(16, 8), dpi=80) 4 plt.rcParams['font.sans-serif']=['SimHei'] # 用来正常显示中文标签 5 plt.rcParams['axes.unicode_minus']=False 6 plt.xticks(rotation=90) 7 plt.bar(x,y,alpha=0.2, width=0.6, color='b', lw=3) 8 plt.legend(loc = "best")# 图例 9 plt.title("飞猪杭州旅游项目柱状图",fontsize=18) 10 plt.ylabel("价格/元")# 纵坐标名字 11 plt.show()
水平图:
1 # 水平图 2 x = Fz_data['title'].head(40) 3 y = Fz_data['price'].head(40) 4 fig = plt.figure(figsize=(16, 8), dpi=80) 5 plt.barh(x,y, alpha=0.2, height=0.6, color='coral') 6 plt.title("飞猪杭州旅游项目水平图",fontsize=18) 7 plt.legend(loc = "best")# 图例 8 plt.xticks(rotation=90) 9 plt.xlabel("下载次数/亿次",)# 横坐标名字

散点图:
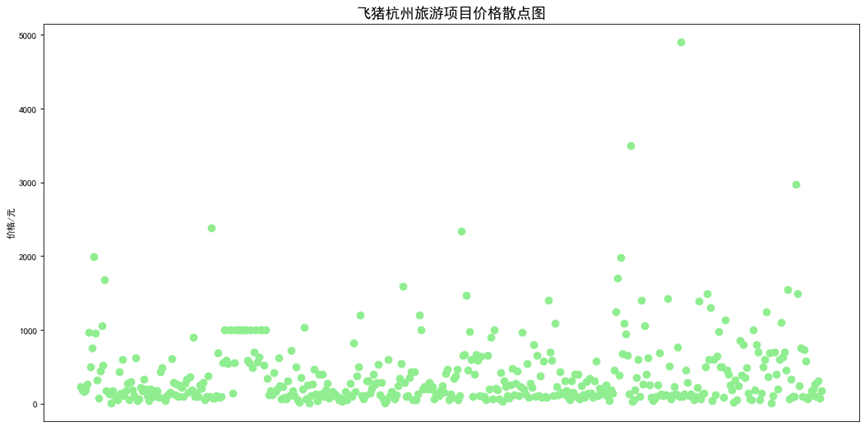
1 # 散点图 2 x = Fz_data['title'] 3 y = Fz_data['price'] 4 fig = plt.figure(figsize=(16, 8), dpi=80) 5 ax = plt.subplot(1, 1, 1) 6 plt.rcParams['font.sans-serif']=['SimHei'] # 用来正常显示中文标签 7 plt.scatter(x,y,color='lightgreen',marker='o',s=60,alpha=1) 8 plt.xticks(rotation=90) 9 plt.xticks([]) 10 plt.ylabel("价格/元")# 纵坐标名字 11 plt.title("飞猪杭州旅游项目价格散点图",fontsize=16)
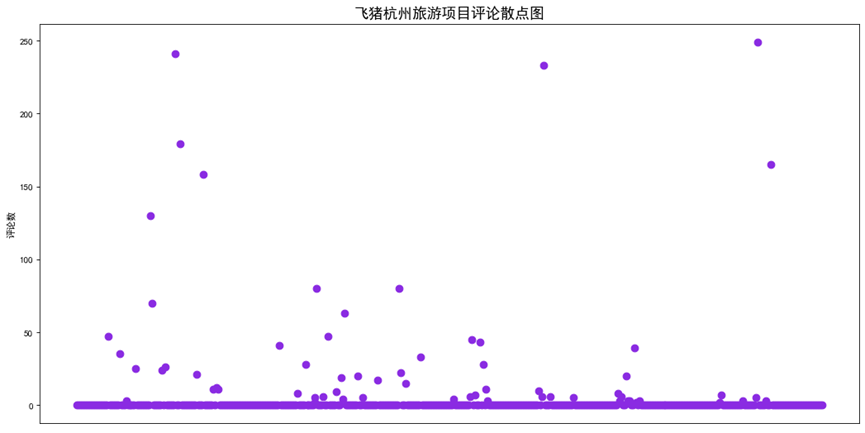
1 # 散点图 2 x = Fz_data['title'] 3 y = Fz_data['coumm'] 4 fig = plt.figure(figsize=(16, 8), dpi=80) 5 ax = plt.subplot(1, 1, 1) 6 plt.rcParams['font.sans-serif']=['SimHei'] # 用来正常显示中文标签 7 plt.scatter(x,y,color='blueviolet',marker='o',s=60,alpha=1) 8 plt.xticks(rotation=90) 9 plt.xticks([]) 10 plt.ylabel("评论数")# 纵坐标名字 11 plt.title("飞猪杭州旅游项目评论散点图",fontsize=16)
盒图:
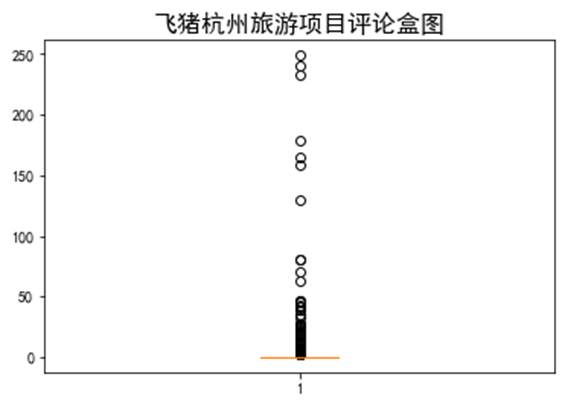
1 # 盒图 2 y = Fz_data['coumm'] 3 plt.boxplot(y) 4 plt.title("飞猪杭州旅游项目评论盒图",fontsize=16) 5 plt.show()
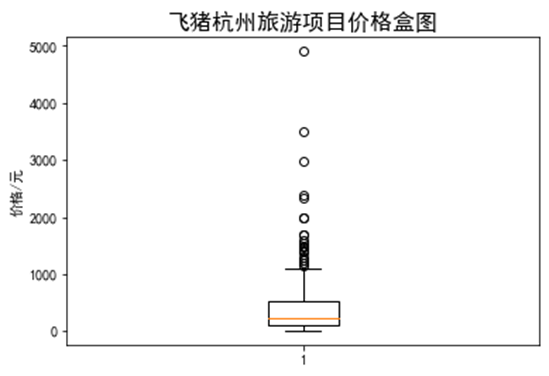
1 # 盒图 2 y = Fz_data['price'] 3 plt.boxplot(y) 4 plt.title("飞猪杭州旅游项目价格盒图",fontsize=16) 5 plt.ylabel("价格/元")# 纵坐标名字 6 plt.show()
(3)词云
1 # 词云 2 import random 3 import wordcloud as wc 4 import matplotlib.pyplot as plt 5 6 # 定义图片尺寸 7 word_cloud = wc.WordCloud( 8 background_color='mintcream', 9 font_path='msyhbd.ttc', 10 max_font_size=300, 11 random_state=50, 12 ) 13 text = Fz_data['title'] 14 text = " ".join(text) 15 # 绘制词云 16 fig = plt.figure(figsize=(10, 5), dpi=80) 17 ax = plt.subplot(1, 1, 1) 18 word_cloud.generate(text) 19 plt.imshow(word_cloud) 20 plt.show()

(4)线性回归方程
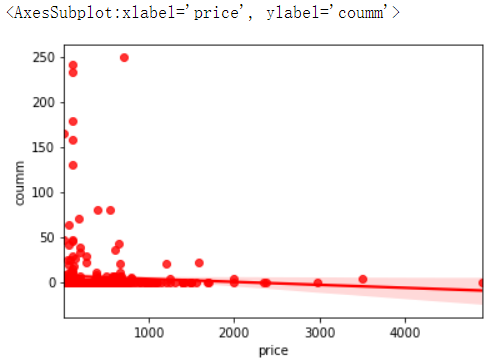
1 # 散点图 2 import seaborn as sns 3 import matplotlib.pyplot as plt 4 import pandas as pd 5 import numpy as np 6 import warnings 7 warnings.filterwarnings("ignore") 8 four=pd.DataFrame(pd.read_excel('C:/Users/TR/Desktop/Feizhu_synthesize.xlsx')) 9 sns.regplot(x='price',y='coumm',data=four,color='r')
1 # 线性回归方程 2 from sklearn import datasets 3 from sklearn.linear_model import LinearRegression 4 import pandas as pd 5 import numpy as np 6 import seaborn as sns 7 predict_model = LinearRegression() 8 three=pd.DataFrame(pd.read_excel('C:/Users/TR/Desktop/Feizhu_synthesize.xlsx')) 9 X = three['price'].values 10 X = X.reshape(-1,1) 11 predict_model.fit(X , three['coumm']) 12 np.set_printoptions(precision = 3, suppress = True) 13 a = predict_model.coef_ 14 b = predict_model.intercept_ 15 print("回归方程系数{}".format(predict_model.coef_)) 16 print("回归方程截距{0:2f}".format(predict_model.intercept_)) 17 print("线性回归预测模型表达式为{}*x+{}".format(predict_model.coef_,predict_model.intercept_))
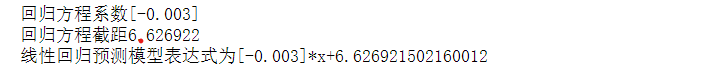
3.代码汇总
1 # 爬虫 2 import time 3 import random 4 import requests 5 from lxml import etree 6 import sys 7 import re 8 9 USER_AGENTS = [ 10 'Mozilla/5.0 (Windows NT 6.2; rv:22.0) Gecko/20130405 Firefox/22.0', 11 'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:22.0) Gecko/20130328 Firefox/22.0', 12 'Mozilla/5.0 (Windows NT 6.1; rv:22.0) Gecko/20130405 Firefox/22.0', 13 'Mozilla/5.0 (Microsoft Windows NT 6.2.9200.0); rv:22.0) Gecko/20130405 Firefox/22.0', 14 'Mozilla/5.0 (Windows NT 6.2; Win64; x64; rv:16.0.1) Gecko/20121011 Firefox/21.0.1', 15 'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:16.0.1) Gecko/20121011 Firefox/21.0.1', 16 'Mozilla/5.0 (Windows NT 6.2; Win64; x64; rv:21.0.0) Gecko/20121011 Firefox/21.0.0', 17 'Mozilla/5.0 (Windows NT 6.2; WOW64; rv:21.0) Gecko/20130514 Firefox/21.0', 18 'Mozilla/5.0 (Windows NT 6.2; rv:21.0) Gecko/20130326 Firefox/21.0', 19 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:21.0) Gecko/20130401 Firefox/21.0', 20 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:21.0) Gecko/20130331 Firefox/21.0', 21 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:21.0) Gecko/20130330 Firefox/21.0', 22 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:21.0) Gecko/20100101 Firefox/21.0', 23 'Mozilla/5.0 (Windows NT 6.1; rv:21.0) Gecko/20130401 Firefox/21.0', 24 'Mozilla/5.0 (Windows NT 6.1; rv:21.0) Gecko/20130328 Firefox/21.0', 25 'Mozilla/5.0 (Windows NT 6.1; rv:21.0) Gecko/20100101 Firefox/21.0', 26 'Mozilla/5.0 (Windows NT 5.1; rv:21.0) Gecko/20130401 Firefox/21.0', 27 'Mozilla/5.0 (Windows NT 5.1; rv:21.0) Gecko/20130331 Firefox/21.0', 28 'Mozilla/5.0 (Windows NT 5.1; rv:21.0) Gecko/20100101 Firefox/21.0', 29 'Mozilla/5.0 (Windows NT 5.0; rv:21.0) Gecko/20100101 Firefox/21.0', 30 'Mozilla/5.0 (Windows NT 6.2; Win64; x64;) Gecko/20100101 Firefox/20.0', 31 'Mozilla/5.0 (Windows NT 6.1; rv:6.0) Gecko/20100101 Firefox/19.0', 32 'Mozilla/5.0 (Windows NT 6.1; rv:14.0) Gecko/20100101 Firefox/18.0.1', 33 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:18.0) Gecko/20100101 Firefox/18.0', 34 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36' 35 ] 36 headers = { 37 'User-Agent':random.choice(USER_AGENTS), 38 'Connection':'keep-alive', 39 'Accept-Language':'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2' 40 } 41 42 # 销量排序 43 def sales_volume(page): 44 # 创建Feizhu_sales_volume.xlsx 45 file = open("Feizhu_sales_volume.xlsx", "a") 46 file.write("title" + "," + "price" + "," + "sell" + "," + "coumm" + '\n') 47 file = file.close() 48 49 for i in range(page): 50 # 请求访问 51 try: 52 url = 'https://travelsearch.fliggy.com/index.htm?spm=181.15077045.1398723350.1.48f3620d7UbQ9z&searchType=product&keyword=%E6%9D%AD%E5%B7%9E&category=MULTI_SEARCH&pagenum='+str(page)+'&-1=sales_des&conditions=-1%3Asales_des' 53 res = requests.get(url,headers=headers) 54 res.encoding = 'utf-8' 55 html = etree.HTML(res.text) 56 coun = 1 57 # 主题title、价格price、已售sell、评论数coumm 58 for i in range(48): 59 title = html.xpath("//*[@id='content']/div[6]/div[1]/div[1]/div/div[{}]/div[2]/div[1]/a/h3/div/text()".format(coun)) 60 for a in title: 61 title = a 62 price = html.xpath("//*[@id='content']/div[6]/div[1]/div[1]/div/div[{}]/div[3]/div/div/span/text()".format(coun)) 63 for a in price: 64 price = a 65 sell = html.xpath("//*[@id='content']/div[6]/div[1]/div[1]/div/div[{}]/div[2]/p[2]/span[1]/text()".format(coun)) 66 for a in sell: 67 sell = a.strip('月售') 68 sell = sell.strip('笔') 69 coumm = html.xpath("//*[@id='content']/div[6]/div[1]/div[1]/div/div[{}]/div[2]/p[2]/span[2]/text()".format(coun)) 70 for i in coumm: 71 if i in '评价': 72 pass 73 elif i in '条': 74 pass 75 elif int(i) > 1: 76 coumm = str(i) 77 coun +=1 78 # 保存数据 79 with open("Feizhu_sales_volume.xlsx", "a", encoding='utf-8') as f2: 80 f2.writelines(title + "," + price + "," + sell + "," + coumm + "," + '\n') 81 print('主题:',title,'\n', 82 '价格:',price,'元\n', 83 '已售出:',sell,'笔\n', 84 '评论:',coumm,'条\n') 85 except: 86 pass 87 88 synthesize(page) 89 page+=1 90 time.sleep(1) 91 92 # 综合排序 93 def synthesize(page): 94 # 创建Feizhu_synthesize.xlsx 95 file = open("Feizhu_synthesize.xlsx", "a") 96 file.write("title" + "," + "price" + "," + "sell" + "," + "coumm" + '\n') 97 file = file.close() 98 try: 99 for i in range(page): 100 # 请求访问 101 url = 'https://travelsearch.fliggy.com/index.htm?spm=181.15077045.1398723350.1.48f3620d7UbQ9z&searchType=product&keyword=%E6%9D%AD%E5%B7%9E&category=MULTI_SEARCH&pagenum='+str(page)+'&-1=popular&conditions=-1%3Apopular' 102 res = requests.get(url, headers=headers) 103 res.encoding = 'utf-8' 104 html = etree.HTML(res.text) 105 coun = 1 106 # 主题title、价格price、已售sell、评论数coumm 107 for i in range(48): 108 title = html.xpath("//*[@id='content']/div[6]/div[1]/div[1]/div/div[{}]/div[2]/div[1]/a/h3/div/text()".format(coun)) 109 for i in title: 110 title = i 111 price = html.xpath("//*[@id='content']/div[6]/div[1]/div[1]/div/div[{}]/div[3]/div/div/span/text()".format(coun)) 112 for i in price: 113 price = i 114 sell = html.xpath("//*[@id='content']/div[6]/div[1]/div[1]/div/div[{}]/div[2]/p[2]/span[1]/text()".format(coun)) 115 sell1 = [] 116 for i in sell: 117 sell = i.strip('月售') 118 sell = sell.strip('笔') 119 if sell == sell1: 120 sell = '0' 121 # print(sell) 122 coumm = html.xpath("//*[@id='content']/div[6]/div[1]/div[1]/div/div[{}]/div[2]/p[2]/span[2]/text()".format(coun)) 123 coumm1 = [] 124 for i in coumm: 125 if i in '评价': 126 pass 127 elif i in '条': 128 pass 129 elif int(i) > 1: 130 coumm = i 131 if coumm == coumm1: 132 coumm = '0' 133 coun += 1 134 # 保存数据 135 with open("Feizhu_synthesize.xlsx", "a", encoding='utf-8') as f2: 136 f2.writelines(title + "," + price + "," + sell + "," + coumm + "," + '\n') 137 print('主题:', title, '\n', 138 '价格:', price, '元\n', 139 '已售出:', sell, '笔\n', 140 '评论:', coumm, '条\n') 141 page +=1 142 time.sleep(1) 143 except: 144 pass 145 146 if __name__ == '__main__': 147 page = 72 148 sales_volume(page) 149 150 # 数据分析 151 import numpy as np 152 import pandas as pd 153 import matplotlib.pyplot as plt 154 Fz_data = pd.read_excel('Feizhu_synthesize.xlsx') 155 # 重复值处理 156 Fz_data = Fz_data.drop_duplicates() 157 # Nan处理 158 Fz_data = Fz_data.dropna(axis = 0) 159 # 删除无效行 160 Fz_data = Fz_data.drop([''], axis = 1) 161 # 空白值处理 162 Fz_data = Fz_data.dropna() 163 # 替换值 164 Fz_data.replace('条', '0',inplace = True) 165 Fz_data.replace('分', '0',inplace = True) 166 # 价格进行降序排列分析 167 Fz_data.sort_values(by=["price"],inplace=True,ascending=[False]) 168 x = Fz_data['title'].head(50) 169 y = Fz_data['price'].head(50) 170 fig = plt.figure(figsize=(16, 8), dpi=80) 171 plt.rcParams['font.sans-serif']=['SimHei'] # 用来正常显示中文标签 172 plt.rcParams['axes.unicode_minus']=False 173 plt.xticks(rotation=90) 174 plt.plot(x,y,'s-',color = 'r',label="价格")# s-:方形 175 plt.legend(loc = "best")# 图例 176 plt.title("杭州旅行项目趋势图价格TOP50",fontsize=18) 177 plt.ylabel("价格/元")# 纵坐标名字 178 plt.show() 179 # 销售情况进行降序排列分析 180 Fz_data.sort_values(by=["sell"],inplace=True,ascending=[False]) 181 x = Fz_data['title'].head(50) 182 y = Fz_data['price'].head(50) 183 fig = plt.figure(figsize=(16, 8), dpi=80) 184 plt.rcParams['font.sans-serif']=['SimHei'] # 用来正常显示中文标签 185 plt.rcParams['axes.unicode_minus']=False 186 plt.xticks(rotation=90) 187 plt.plot(x,y,'s-',color = 'lightcoral')# s-:方形 188 plt.legend(loc = "best")# 图例 189 plt.title("杭州旅行项目销售趋势图TOP50",fontsize=18) 190 plt.ylabel("价格/元")# 纵坐标名字 191 plt.show() 192 Fz_data.sort_values(by=["coumm"],inplace=True,ascending=[False]) 193 x = Fz_data['title'].head(50) 194 y = Fz_data['price'].head(50) 195 fig = plt.figure(figsize=(16, 8), dpi=80) 196 plt.rcParams['font.sans-serif']=['SimHei'] # 用来正常显示中文标签 197 plt.rcParams['axes.unicode_minus']=False 198 plt.xticks(rotation=90) 199 plt.plot(x,y,'s-',color = 'plum')# s-:方形 200 plt.legend(loc = "best")# 图例 201 plt.title("杭州旅行项目热度趋势图TOP50",fontsize=18) 202 plt.ylabel("价格/元")# 纵坐标名字 203 plt.show() 204 # 水平图 205 x = Fz_data['title'].head(40) 206 y = Fz_data['price'].head(40) 207 fig = plt.figure(figsize=(16, 8), dpi=80) 208 plt.barh(x,y, alpha=0.2, height=0.6, color='coral') 209 plt.title("飞猪杭州旅游项目水平图",fontsize=18) 210 plt.legend(loc = "best")# 图例 211 plt.xticks(rotation=90) 212 plt.xlabel("下载次数/亿次",)# 横坐标名字 213 x = Fz_data['title'].head(50) 214 y = Fz_data['price'].head(50) 215 fig = plt.figure(figsize=(16, 8), dpi=80) 216 plt.rcParams['font.sans-serif']=['SimHei'] # 用来正常显示中文标签 217 plt.rcParams['axes.unicode_minus']=False 218 plt.xticks(rotation=90) 219 plt.bar(x,y,alpha=0.2, width=0.6, color='b', lw=3) 220 plt.legend(loc = "best")# 图例 221 plt.title("飞猪杭州旅游项目柱状图",fontsize=18) 222 plt.ylabel("价格/元")# 纵坐标名字 223 plt.show() 224 # 散点图 225 x = Fz_data['title'] 226 y = Fz_data['price'] 227 fig = plt.figure(figsize=(16, 8), dpi=80) 228 ax = plt.subplot(1, 1, 1) 229 plt.rcParams['font.sans-serif']=['SimHei'] # 用来正常显示中文标签 230 plt.scatter(x,y,color='lightgreen',marker='o',s=60,alpha=1) 231 plt.xticks(rotation=90) 232 plt.xticks([]) 233 plt.ylabel("价格/元")# 纵坐标名字 234 plt.title("飞猪杭州旅游项目价格散点图",fontsize=16) 235 # 散点图 236 x = Fz_data['title'] 237 y = Fz_data['coumm'] 238 fig = plt.figure(figsize=(16, 8), dpi=80) 239 ax = plt.subplot(1, 1, 1) 240 plt.rcParams['font.sans-serif']=['SimHei'] # 用来正常显示中文标签 241 plt.scatter(x,y,color='blueviolet',marker='o',s=60,alpha=1) 242 plt.xticks(rotation=90) 243 plt.xticks([]) 244 plt.ylabel("评论数")# 纵坐标名字 245 plt.title("飞猪杭州旅游项目评论散点图",fontsize=16) 246 # 盒图 247 y = Fz_data['coumm'] 248 plt.boxplot(y) 249 plt.title("飞猪杭州旅游项目评论盒图",fontsize=16) 250 plt.show() 251 # 盒图 252 y = Fz_data['price'] 253 plt.boxplot(y) 254 plt.title("飞猪杭州旅游项目价格盒图",fontsize=16) 255 plt.ylabel("价格/元")# 纵坐标名字 256 plt.show() 257 # 词云 258 import random 259 import wordcloud as wc 260 import matplotlib.pyplot as plt 261 # 定义图片尺寸 262 word_cloud = wc.WordCloud( 263 background_color='mintcream', 264 font_path='msyhbd.ttc', 265 max_font_size=300, 266 random_state=50, 267 ) 268 text = Fz_data['title'] 269 text = " ".join(text) 270 # 绘制词云 271 fig = plt.figure(figsize=(10, 5), dpi=80) 272 ax = plt.subplot(1, 1, 1) 273 word_cloud.generate(text) 274 plt.imshow(word_cloud) 275 plt.show() 276 # 散点图 277 import seaborn as sns 278 import matplotlib.pyplot as plt 279 import pandas as pd 280 import numpy as np 281 import warnings 282 warnings.filterwarnings("ignore") 283 four=pd.DataFrame(pd.read_excel('C:/Users/TR/Desktop/Feizhu_synthesize.xlsx')) 284 sns.regplot(x='price',y='coumm',data=four,color='r') 285 # 线性回归方程 286 from sklearn import datasets 287 from sklearn.linear_model import LinearRegression 288 import pandas as pd 289 import numpy as np 290 import seaborn as sns 291 predict_model = LinearRegression() 292 three=pd.DataFrame(pd.read_excel('C:/Users/TR/Desktop/Feizhu_synthesize.xlsx')) 293 X = three['price'].values 294 X = X.reshape(-1,1) 295 predict_model.fit(X , three['coumm']) 296 np.set_printoptions(precision = 3, suppress = True) 297 a = predict_model.coef_ 298 b = predict_model.intercept_ 299 print("回归方程系数{}".format(predict_model.coef_)) 300 print("回归方程截距{0:2f}".format(predict_model.intercept_)) 301 print("线性回归预测模型表达式为{}*x+{}".format(predict_model.coef_,predict_model.intercept_))
四、总结
1.经过对主题数据的分析与可视化,可以得到哪些结论?是否达到预期的目标?
根据数据分析和可视化可以得出杭州旅游项目价格开销在酒店方面占用了大部分,从销售情况与评论数来看杭州千岛湖景点最收游客的欢迎,热度最高,分析效果达到了预期的目标。
2.在完成此设计过程中,得到哪些收获?以及要改进的建议?
通过飞猪旅行开放平台对数据内容进行爬取分析,学会了利用requests库获取网页数据的使用,但对绘图的库较为生疏,在爬虫时缺少代码经验,耗时比较久,需要加强代码编写。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号