yolov8学习笔记(2)
第7周学*进度:
经过一周对yolov8基础知识的学*,现在根据项目进行练*,*一步加深理解能力:
学*目标:
1.1周内跑通YOLOv8官方检测/分类Demo,理解核心概念,搭建稳定的开发环境。
2能标注自己的数据集,训练自定义模型(如“安全帽检测”“水果分类”),并通过调参提升精度,会训练、能调参。
3.
1.Ultralytics提供了“开箱即用”的API,需掌握3个核心操作:加载模型、执行推理、解析结果。
以“目标检测”为例,Jupyter完整代码(复制就能跑):
# 1. 导入库
from ultralytics import YOLO
import cv2
import matplotlib.pyplot as plt
# 2. 加载预训练模型(检测模型,自动下载)
model = YOLO("yolov8s.pt") # s=small,平衡速度与精度
# 3. 执行推理(用官方测试图)
results = model.predict(
source="https://ultralytics.com/images/bus.jpg", # 输入图片URL
conf=0.25, # 置信度阈值(只保留>0.25的目标)
imgsz=640 # 输入图像尺寸
)
# 4. 解析结果(打印检测到的目标)
result = results[0] # 单张图的结果
print(f"检测到 {len(result.boxes)} 个目标:")
for box in result.boxes:
cls_name = model.names[box.cls[0].item()] # 类别名
conf = box.conf[0].item() # 置信度
xyxy = box.xyxy[0].tolist() # 目标框坐标
print(f"类别:{cls_name},置信度:{conf:.2f},坐标:{xyxy}")
# 5. 显示结果
img = cv2.imread(result.path) # 读取图片
img_rgb = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) # 转RGB(matplotlib用)
plt.figure(figsize=(10, 8))
plt.imshow(img_rgb)
plt.axis("off")
plt.title("YOLOv8 检测结果")
plt.show()概念理解:
1. 导入库
ultralytics.YOLO:Ultralytics 库的核心类,封装了 YOLO 模型的加载、训练、推理等功能。cv2:OpenCV 是计算机视觉领域常用的库,用于读取、处理图像 / 视频。matplotlib.pyplot:用于在 Python 中可视化图像(尤其适合 Jupyter 环境)。
2. 加载预训练模型(检测模型,自动下载)
YOLO("yolov8s.pt"):创建 YOLO 模型实例,参数为预训练权重文件路径。yolov8s.pt:YOLOv8 的 "small" 版本模型,预训练于 COCO 数据集(包含 80 个常见类别,如人、车、动物等)。
首次运行时会自动下载权重文件(约 21MB),其他版本可替换为yolov8n.pt(nano,最快)、yolov8m.pt(medium,更精准)。
model:加载后的模型对象,后续可调用predict()方法执行推理。
3. 执行推理(用官方测试图)
model.predict():模型推理的核心方法,对输入的图像 / 视频进行目标检测。source:输入源,可以是本地图片路径(如"test.jpg")、网络图片 URL、视频文件或摄像头 ID(如0表示默认摄像头)。这里使用官方测试图(一辆公交车的图片)。conf=0.25:置信度阈值,过滤掉置信度低于 0.25 的检测结果(减少误检)。imgsz=640:输入图像的尺寸(宽 × 高),模型会自动将输入图像缩放至 640×640 后进行处理。results:推理结果的列表(即使只有一张图,也会包装成列表),每个元素对应一个输入源的检测结果。
4. 解析结果(打印检测到的目标)
box.cls:目标的类别索引(张量格式),box.cls[0].item()将张量转为 Python 数值(如 “人” 对应索引 0,“公交车” 对应索引 5)。model.names:模型预定义的类别名称字典(键为索引,值为类别名),通过类别索引获取具体名称(如model.names[5]为 “bus”)。box.conf:目标的置信度(张量格式),box.conf[0].item()转为 0~1 之间的数值(越接* 1 越可信)。box.xyxy:目标框的坐标(张量格式,格式为[x1, y1, x2, y2],即左上角 x、左上角 y、右下角 x、右下角 y),tolist()转为 Python 列表便于查看。
5.显示结果
运算结果:

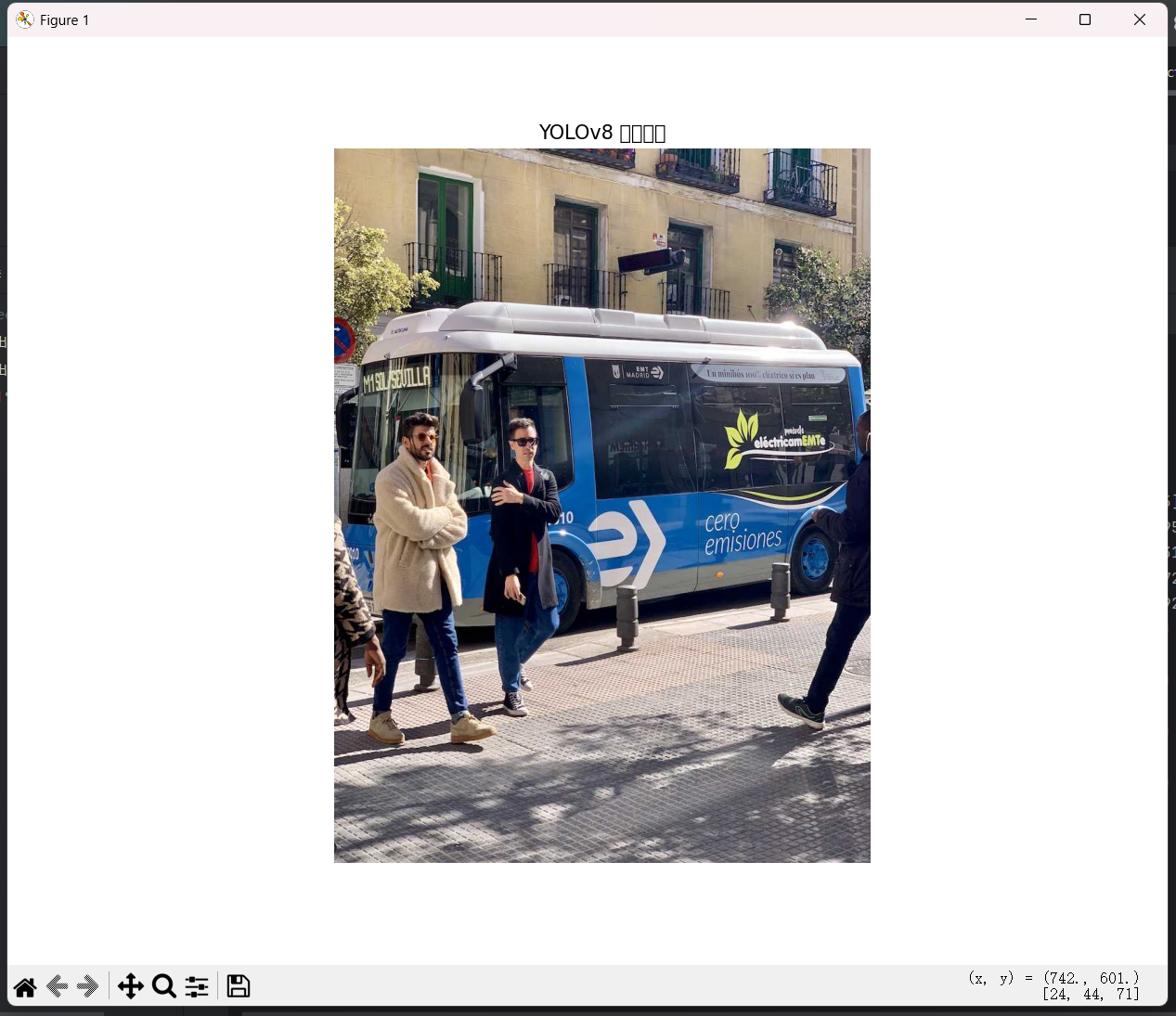
2.对图片进行识别与分类:
from ultralytics import YOLO
if __name__ == '__main__':
model = YOLO(r"yolo11n.pt")
model.train(
data=r"coco8.yaml",
epochs=30,imgsz=640,
batch=2,
cache=False,
workers=0,
val=False,
)1.data=r"coco8.yaml"
指定数据集配置文件的路径。coco8.yaml是 Ultralytics 提供的一个小型 COCO 数据集示例(仅包含 8 张图片),用于快速测试训练流程。
配置文件中定义了:训练集 / 验证集的路径、类别数量(nc)、类别名称(names)等信息。实际应用中需替换为自定义数据集的配置文件。
2.epochs=30
训练的总轮数(即整个数据集被模型学*的次数)。30 表示模型会对训练集迭代 30 次。
轮数越多,模型可能拟合越好,但也可能过拟合(需根据验证集效果调整)。
输入图像的尺寸(宽 × 高),模型会自动将输入图像缩放为 640×640 像素后进行训练。
YOLO 系列通常推荐 640 或 1280,需根据硬件性能和精度需求调整。
批次大小:每次模型参数更新时使用的样本数量。这里设置为 2,表示每次输入 2 张图片计算损失并更新权重。
批次大小受 GPU 显存限制:显存小则设小(如 2、4),显存大则可设大(如 16、32),更大的批次通常训练更稳定。
是否缓存数据集到内存或磁盘。False表示不缓存,适合小数据集(如coco8)或内存有限的情况;True则会提前加载数据到缓存,加速后续训练(适合大数据集)。
数据加载的工作进程数量。0表示在主进程中加载数据(不启用多进程),适用于 Windows 系统(避免多进程路径问题);Linux/Mac 可设为大于 0 的数(如 4,根据 CPU 核心数调整),加速数据加载。
是否在训练过程中关闭验证步骤。默认情况下,YOLO 会在每个 epoch 结束后用验证集评估模型性能(如 mAP 指标),val=False会跳过验证,适用于快速测试训练流程(不关心模型精度时)。
训练输出

内容分析:
3.对车牌进行识别与分类:
1. main.py:项目的核心入口
main.py 作为整个项目的主入口,负责整体流程的控制。该模块的核心功能包括加载YOLO模型、读取输入视频、进行图像处理以及输出检测结果。
加载模型
在项目开始时,首先导入必要的库和模块,如 OpenCV、YOLO 和自定义的工具模块。接着,使用 YOLO 模型加载函数载入预训练的模型文件。这一步骤至关重要,因为它为后续的车辆和车牌检测提供了必要的网络结构和参数。
import torch
import cv2
import numpy as np
import argparse
import copy
import time
import os
from ultralytics.nn.tasks import attempt_load_weights
from plate_recognition.plate_rec import get_plate_result,init_model,cv_imread
from plate_recognition.double_plate_split_merge import get_split_merge
from fonts.cv_puttext import cv2ImgAddText
2.读取视频/文件导入
接下来,使用 OpenCV 读取输入视频并逐帧进行处理。每帧的处理包括检测车辆和车牌的过程。
# 加载视频
cap = cv2.VideoCapture('./sample.mp4')
# 初始化帧计数器
frame\_nmr = -1
ret = True
while ret:
frame\_nmr += 1
ret, frame = cap.read()
if ret:
results[frame\_nmr] = {}
...def allFilePath(rootPath, allFileList): # 读取文件夹内的所有文件路径,存储到列表中
fileList = os.listdir(rootPath) # 获取当前目录下的所有文件和文件夹名
for temp in fileList: # 遍历每个文件/文件夹
# 判断是否为文件
if os.path.isfile(os.path.join(rootPath, temp)):
# 若是文件则拼接完整路径并添加到列表
allFileList.append(os.path.join(rootPath, temp))
else:
# 若是文件夹则递归调用自身继续遍历
allFilePath(os.path.join(rootPath, temp), allFileList)3.检测车辆
对于每帧图像,首先使用 YOLO 模型检测车辆。检测结果包含每个车辆的边界框信息及其置信度分数。通过过滤车辆类别,只保留主要关心的车辆(如轿车、SUV等)。
# 检测车辆
detections = coco\_model(frame)[0]
detections\_ = []
for detection in detections.boxes.data.tolist():
x1, y1, x2, y2, score, class\_id = detection
if int(class\_id) in vehicles:
detections\_.append([x1, y1, x2, y2, score])4.裁剪和处理车牌
成功分配车牌后,裁剪出车牌区域,并对其进行灰度转换和二值化处理,以便于后续的字符识别。
if car\_id != -1:
# 裁剪车牌图像
license\_plate\_crop = frame[int(y1):int(y2), int(x1): int(x2), :]
# 处理车牌图像
license\_plate\_crop\_gray = cv2.cvtColor(license\_plate\_crop, cv2.COLOR\_BGR2GRAY)
\_, license\_plate\_crop\_thresh = cv2.threshold(license\_plate\_crop\_gray, 64, 255, cv2.THRESH\_BINARY\_INV)
# 读取车牌号码
license\_plate\_text, license\_plate\_text\_score = read\_license\_plate(license\_plate\_crop\_thresh)
if license\_plate\_text is not None:
results[frame\_nmr][car\_id] = {'car': {'bbox': [xcar1, ycar1, xcar2, ycar2]},
'license\_plate': {'bbox': [x1, y1, x2, y2],
'text': license\_plate\_text,
'bbox\_score': score,
'text\_score': license\_plate\_text\_score}}5.写入结果
最后,将处理后的检测结果写入 CSV 文件,以便后续的数据分析和处理。
# 写入结果
write\_csv(results, './test.csv')visualize.py:结果可视化模块
visualize.py 模块的主要功能是将车牌识别的结果以可视化的形式展示在视频中。这不仅可以帮助开发者直观地理解识别系统的表现,还能用于展示最终的产品效果,增强用户体验。
导入所需库
首先需要导入一些必要的库:
cv2:用于图像和视频处理。numpy:用于数值计算和数组操作。pandas:用于数据处理和分析。
import ast
import cv2
import numpy as np
import pandas as pd绘制边框的函数
draw\_border 函数负责在图像上绘制车辆和车牌的边框。通过这种可视化,可以清晰地看到识别的区域,帮助分析模型的准确性。
def draw\_border(img, top\_left, bottom\_right, color=(0, 255, 0), thickness=10, line\_length\_x=200, line\_length\_y=200):
x1, y1 = top\_left
x2, y2 = bottom\_right
# 绘制左上角边框
cv2.line(img, (x1, y1), (x1, y1 + line\_length\_y), color, thickness) # 左侧
cv2.line(img, (x1, y1), (x1 + line\_length\_x, y1), color, thickness) # 上侧
# 绘制左下角边框
cv2.line(img, (x1, y2), (x1, y2 - line\_length\_y), color, thickness) # 左侧
cv2.line(img, (x1, y2), (x1 + line\_length\_x, y2), color, thickness) # 下侧
# 绘制右上角边框
cv2.line(img, (x2, y1), (x2 - line\_length\_x, y1), color, thickness) # 上侧
cv2.line(img, (x2, y1), (x2, y1 + line\_length\_y), color, thickness) # 右侧
# 绘制右下角边框
cv2.line(img, (x2, y2), (x2, y2 - line\_length\_y), color, thickness) # 右侧
cv2.line(img, (x2, y2), (x2 - line\_length\_x, y2), color, thickness) # 下侧
return img6.取识别结果数据
通过 Pandas 读取 CSV 文件中的识别结果,这些结果是模型处理视频后生成的,包括每个车牌的置信度和位置信息。
# 加载视频
video\_path = 'sample.mp4'
cap = cv2.VideoCapture(video\_path) # 创建视频捕获对象
# 指定视频编码和帧率
fourcc = cv2.VideoWriter\_fourcc(\*'mp4v')
fps = cap.get(cv2.CAP\_PROP\_FPS) # 获取原视频的帧率
width = int(cap.get(cv2.CAP\_PROP\_FRAME\_WIDTH)) # 获取视频宽度
height = int(cap.get(cv2.CAP\_PROP\_FRAME\_HEIGHT)) # 获取视频高度
out = cv2.VideoWriter('./out.mp4', fourcc, fps, (width, height)) # 创建输出视频文件7.初始化车牌信息字典
为每个车辆提取最大置信度的车牌信息,并存储对应的车牌图像。这样做的目的是在后续绘制过程中,能够快速访问每辆车的识别结果
license\_plate = {}
for car\_id in np.unique(results['car\_id']): # 遍历所有唯一的车ID
max\_ = np.amax(results[results['car\_id'] == car\_id]['license\_number\_score']) # 找到最大置信度
license\_plate[car\_id] = {
'license\_crop': None, # 初始化车牌裁剪图像
'license\_plate\_number': results[(results['car\_id'] == car\_id) &
(results['license\_number\_score'] == max\_)]['license\_number'].iloc[0] # 存储车牌号
}
# 设置视频帧的位置
cap.set(cv2.CAP\_PROP\_POS\_FRAMES, results[(results['car\_id'] == car\_id) &
(results['license\_number\_score'] == max\_)]['frame\_nmr'].iloc[0])
ret, frame = cap.read() # 读取该帧
# 获取车牌的边界框坐标
x1, y1, x2, y2 = ast.literal\_eval(results[(results['car\_id'] == car\_id) &
(results['license\_number\_score'] == max\_)]['license\_plate\_bbox'].iloc[0].replace('[ ', '[').replace(' ', ' ').replace(' ', ' ').replace(' ', ','))
# 裁剪车牌图像并调整大小
license\_crop = frame[int(y1):int(y2), int(x1):int(x2), :]
license\_crop = cv2.resize(license\_crop, (int((x2 - x1) \* 400 / (y2 - y1)), 400)) # 调整裁剪图像的大小
license\_plate[car\_id]['license\_crop'] = license\_crop # 保存裁剪的车牌图像
8逐帧读取视频并绘制识别结果
在这一部分,逐帧读取视频,并根据识别结果在每帧上绘制车辆和车牌的边界框。通过这种方式,用户可以直观地看到模型的识别效果,并评估其准确性和可靠性。
frame\_nmr = -1 # 帧计数器
cap.set(cv2.CAP\_PROP\_POS\_FRAMES, 0) # 重置视频到开头
# 读取帧
ret = True
while ret:
ret, frame = cap.read() # 读取一帧
frame\_nmr += 1 # 增加帧计数
if ret:
df\_ = results[results['frame\_nmr'] == frame\_nmr] # 获取当前帧的结果
for row\_indx in range(len(df\_)):
# 绘制车辆边界框
car\_x1, car\_y1, car\_x2, car\_y2 = ast.literal\_eval(df\_.iloc[row\_indx]['car\_bbox'].replace('[ ', '[').replace(' ', ' ').replace(' ', ' ').replace(' ', ','))
draw\_border(frame, (int(car\_x1), int(car\_y1)), (int(car\_x2), int(car\_y2)), (0, 255, 0), 25,line\_length\_x=200, line\_length\_y=200)
# 绘制车牌边界框
x1, y1, x2, y2 = ast.literal\_eval(df\_.iloc[row\_indx]['license\_plate\_bbox'].replace('[ ', '[').replace(' ', ' ').replace(' ', ' ').replace(' ', ','))
cv2.rectangle(frame, (int(x1), int(y1)), (int(x2), int(y2)), (0, 0, 255), 12) # 绘制车牌的矩形框
# 获取并显示车牌裁剪图像
license\_crop = license\_plate[df\_.iloc[row\_indx]['car\_id']]['license\_crop'] # 获取车牌裁剪图像
H. W, \_ = license\_crop.shape # 获取车牌裁剪图像的高度和宽度
try:
# 在车辆上方插入车牌图像
frame[int(car\_y1) - H - 100:int(car\_y1) - 100,
int((car\_x2 + car\_x1 - W) / 2):int((car\_x2 + car\_x1 + W) / 2), :] = license\_cro
# 在车牌上方添加白色背景
frame[int(car\_y1) - H - 400:int(car\_y1) - H - 100,
int((car\_x2 + car\_x1 - W) / 2):int((car\_x2 + car\_x1 + W) / 2), :] = (255, 255, 255)
# 获取文本的尺寸
(text\_width, text\_height), \_ = cv2.getTextSize( license\_plate[df\_.iloc[row\_indx]['car\_id']]['license\_plate\_number'],
cv2.FONT\_HERSHEY\_SIMPLEX, 4.3, 17)
# 在帧中绘制车牌号
cv2.putText(frame, license\_plate[df\_.iloc[row\_indx]['car\_id']]['license\_plate\_number'],
(int((car\_x2 + car\_x1 - text\_width) / 2), int(car\_y1 - H - 250 + (text\_height / 2))), cv2.FONT\_HERSHEY\_SIMPLEX, 4.3, (0, 0, 0), 17)
except:
pass # 忽略可能出现的错误
out.write(frame) # 将处理后的帧写入输出视频
frame = cv2.resize(frame, (1280, 720)) # 调整输出帧的尺寸
out.release() # 释放视频写入对象
cap.release() # 释放视频捕获对象图片展示:

输出结果:



4.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号