yolov8学习进程
第6周学习情况笔记:
-
学习内容:
-
环境配置:个人感觉过程不大顺利,电脑没有英伟达的显卡,只能用cpu跑了,问了实验室的计算机同学他说cpu可以跑但是很慢,希望对下面的学习没有影响吧。
Anaconda与
PyCharm的区别:
用 Anaconda 干两件事:
-
分 “小仓库”:比如你做两个项目,一个需要老版本的工具,一个需要新版本,Anaconda 可以给每个项目建一个独立的 “小仓库”(叫虚拟环境),互不打扰。
-
操作:打开 “Anaconda Prompt”(Windows)或终端(Mac),输命令建仓库(比如
conda create -n 我的仓库 python=3.9),用的时候 “激活”(conda activate 我的仓库),不用了 “退出”(conda deactivate)。 -
装工具:在激活的 “小仓库” 里,输
conda install 工具名或pip install 工具名(比如装个画图的matplotlib),它会自动把工具放进当前仓库。
用 PyCharm 干两件事:
-
写代码:打开 PyCharm,新建个项目(选个文件夹存代码),然后就能新建文件写 Python 了,它会帮你自动补全代码、标错。
-
连仓库:写代码时得用 Anaconda 仓库里的工具吧?所以建项目时,告诉 PyCharm 用哪个 “小仓库” 里的工具(选仓库里的
python.exe文件)。之后运行代码、调试(加断点一步步看),都用这个仓库里的工具,保证没错。
配合起来就是:
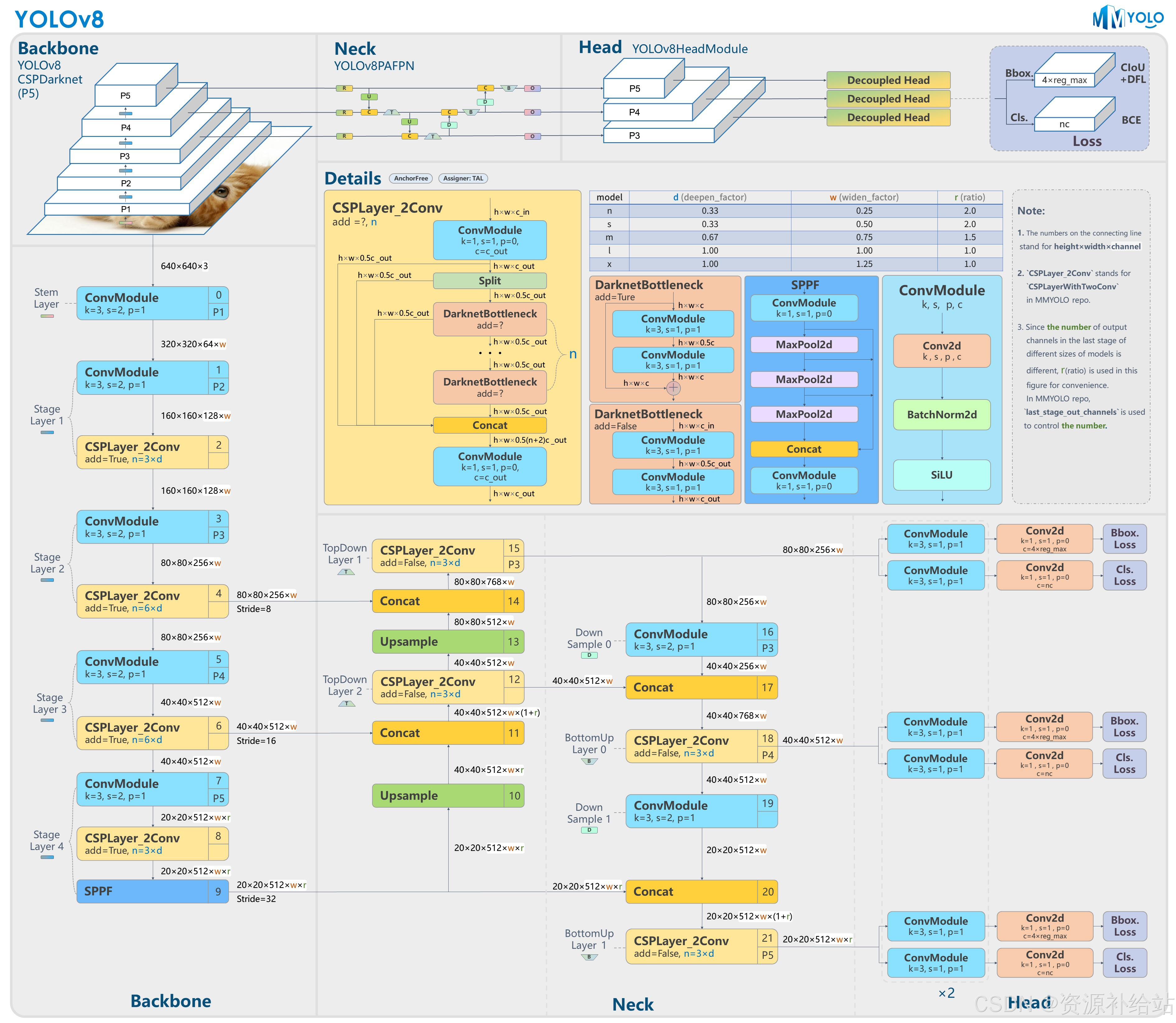
以上结构图由 RangeKing@github 绘制。
YOLOv8 是 Ultralytics 公司在 2023 年 1月 10 号开源的 YOLOv5 的下一个重大更新版本,目前支持图像分类、物体检测和实例分割任务,在还没有开源时就收到了用户的广泛关注。
按照官方描述,YOLOv8 是一个 SOTA 模型,它建立在以前 YOLO 版本的成功基础上,并引入了新的功能和改进,以进一步提升性能和灵活性。
具体创新包括一个新的骨干网络、一个新的 Ancher-Free 检测头和一个新的损失函数,可以在从 CPU 到 GPU 的各种硬件平台上运行。 不过 Ultralytics 并没有直接将开源库命名为 YOLOv8,而是直接使用 Ultralytics 这个词,
原因是 Ultralytics 将这个库定位为算法框架,而非某一个特定算法,一个主要特点是可扩展性。其希望这个库不仅仅能够用于 YOLO 系列模型,而是能够支持非 YOLO 模型以及分类分割姿态估计等各类任务。
总而言之,Ultralytics 开源库的两个主要优点是:
融合众多当前 SOTA 技术于一体
未来将支持其他 YOLO 系列以及 YOLO 之外的更多算法
YOLOv8 性能曲线

下表为官方在 COCO Val 2017 数据集上测试的 mAP、参数量和 FLOPs 结果。可以看出 YOLOv8 相比 YOLOv5 精度提升非常多,但是 N/S/M 模型相应的参数量和 FLOPs 都增加了不少,
从上图也可以看出相比 YOLOV5 大部分模型推理速度变慢了。

3.YOLOv8的主要应用领域(ai跑的):
智能安防与视频监控:YOLOv8在智能安防领域被用于实时监控和异常行为检测,例如识别可疑人物、车辆和包裹,并通过边缘计算进行快速目标检测和事件预警,提升安防系统的响应速度和精准度。
自动驾驶:在自动驾驶领域,YOLOv8用于实时识别路况中的行人、车辆和其他障碍物,为自动驾驶系统提供关键数据支持,包括障碍物检测、车道线检测和交通标志识别等。
工业自动化:YOLOv8在工业自动化中用于产品检测、缺陷检测和机器人视觉导航。它能够提高生产效率和产品质量,减少人工成本,并适应复杂的工作环境。
医疗影像分析:YOLOv8在医学影像处理中用于病灶检测、器官分割和医学图像分类等任务,辅助医生进行诊断和治疗,提高医疗水平。
农业:在农业领域,YOLOv8用于监测作物生长、检测作物病害、识别害虫等,帮助农民提高农作物管理效率。
零售业:YOLOv8在零售业中用于商品检测和库存管理自动化,帮助零售商监控库存水平,检测商店扒手,并跟踪客户行为。
机器人技术:YOLOv8在机器人技术中用于目标定位与导航,帮助机器人识别环境中的物体并与之交互。
无人机侦查:YOLOv8用于无人机侦查任务,实时分析空中拍摄的图像,进行物体跟踪和目标识别。
智能交通系统:YOLOv8在智能交通系统中用于车辆检测、行人检测、交通流量统计和交通标志识别,提高交通管理的效率和安全性。
其他领域:YOLOv8还应用于环境保护、娱乐、野生动物保护、智能养老健康监测等多个领域,展示了其广泛的适用性和高效性。
YOLOv8 算法的核心特性和改动可以归结为如下:
提供了一个全新的 SOTA 模型,包括 P5 640 和 P6 1280 分辨率的目标检测网络和基于 YOLACT 的实例分割模型。和 YOLOv5 一样,基于缩放系数也提供了 N/S/M/L/X 尺度的不同大小模型,用于满足不同场景需求
骨干网络和 Neck 部分可能参考了 YOLOv7 ELAN 设计思想,将 YOLOv5 的 C3 结构换成了梯度流更丰富的 C2f 结构,并对不同尺度模型调整了不同的通道数,属于对模型结构精心微调,不再是无脑一套参数应用所有模型,大幅提升了模型性能。
不过这个 C2f 模块中存在 Split 等操作对特定硬件部署没有之前那么友好了
Head 部分相比 YOLOv5 改动较大,换成了目前主流的解耦头结构,将分类和检测头分离,同时也从 Anchor-Based 换成了 Anchor-Free
Loss 计算方面采用了 TaskAlignedAssigner 正样本分配策略,并引入了 Distribution Focal Loss
训练的数据增强部分引入了 YOLOX 中的最后 10 epoch 关闭 Mosiac 增强的操作,可以有效地提升精度
从上面可以看出,YOLOv8 主要参考了最近提出的诸如 YOLOX、YOLOv6、YOLOv7 和 PPYOLOE 等算法的相关设计,本身的创新点不多,偏向工程实践,主推的还是 ultralytics 这个框架本身。
看不懂没关系,下面解释:
SOTA 模型:就是说它现在是同类算法里性能顶尖的,检测又快又准。
两种分辨率可选:
P5 640:输入图像是 640×640 像素,适合普通场景,速度快。
P6 1280:输入是 1280×1280 像素,更清晰,能检测到更小的目标,但计算起来更费劲儿(类似手机拍照片,高清模式更清楚但占内存)。
多种 “大小” 的模型:和 YOLOv5 一样,分 N/S/M/L/X 这几种(从最小到最大)。
小模型(比如 N):速度快,适合手机这类算力弱的设备。
大模型(比如 X):精度高,但跑起来慢,适合电脑或服务器。这样不同场景(比如实时监控要快,科研检测要准)都能选到合适的。
2. 中间 “特征处理” 部分的优化
骨干网络和 Neck:这俩是模型的 “特征提取器” 和 “特征融合器”(相当于先从图片里提取关键信息,再把不同层面的信息整合起来)。
抄了 YOLOv7 的作业:把 YOLOv5 里的 C3 结构换成了 C2f 结构。
好处:C2f 能让信息在网络里流动得更顺畅(梯度流更丰富),提取的特征更全面,模型性能更好。
小缺点:C2f 里有个 “Split(分割)” 操作,导致在某些特定硬件(比如专门的 AI 芯片)上部署时,不如以前的 C3 方便(类似复杂零件不好装到简单机器上)。
不再 “一刀切”:以前 YOLOv5 的不同大小模型,很多参数是一样的;现在 YOLOv8 给不同模型调整了 “通道数”(可以理解为特征的 “维度”),让每个模型的参数更合理,性能自然就上去了。
3. 最终 “决策输出” 部分的大改
Head 部分:这是模型的 “决策中心”,负责判断 “这是啥目标”(分类)和 “目标在哪儿”(定位)。
解耦头:把分类和定位这两个任务分开处理,各用各的 “子网络”。就像写作业时,数学和语文分开做效率更高,模型也能更专注,结果更准。
从 “带模板” 到 “不带模板”:
以前 YOLOv5 是 Anchor-Based:提前设定一堆 “锚框”(类似预设的目标轮廓模板),模型靠匹配模板来检测目标,缺点是模板参数不好调,换个场景可能就不准了。
现在 YOLOv8 是 Anchor-Free:直接根据目标本身的特征(比如中心点、宽高)来定位,不用模板,更灵活,对不同大小的目标适应力更强。
4. 训练过程细节优化
Loss 计算:就是模型训练时,判断 “预测结果和真实结果差多少” 的指标(类似作业错题数)。
用了 TaskAlignedAssigner:让模型在选 “训练样本” 时更聪明,优先选那些 “分类准且定位准” 的样本重点学,避免瞎学。
加了 Distribution Focal Loss:专门优化目标边界的预测(比如更精准地框住目标的边缘),让定位更准。
数据增强:训练时对图片做各种变换(比如裁剪、翻转、拼接),让模型见更多 “世面”,避免学死(比如只认识正面的猫,不认识侧面的)。
抄了 YOLOX 的做法:训练最后 10 轮(epoch)关掉 Mosaic 增强(这种增强是把 4 张图拼在一起),让模型专注学原始图片的细节,进一步提精度(类似考前先做难题拓展思路,最后回归基础题巩固)。
总结:
YOLOv8 自己的全新发明不多,主要是把 YOLOX、YOLOv6、YOLOv7 这些前辈的优点整合了一遍,再做些细节优化,让模型更好用。它真正想推的是ultralytics这个框架 —— 就像一个包装好的工具箱,不管是训练模型、用模型检测,还是部署到各种设备上,都很方便,普通人也能快速上手。
2 模型结构设计(不大看的懂,以后慢慢理解)
1、 概述:
Ultralytics YOLOv8作为目标检测模型,相比于之前版本YOLOv5,v8更适合被称为一个计算机视觉框架。YOLOv8 系列提供了多种模型,这些模型旨在满足从目标检测、分类、图像分割、姿态/关键点检测和定向物体检测等更复杂任务的各种要求。其相比于自身的创新点,更加符合工程领域上的需求。
主要的创新点有:
- 提供了全新的SOTA模型,基于缩放系数,提供了5种(N/S/M/L/X)不同尺度大小的模型,可以灵活应用与不同的硬件平台;
- BacckBone部分将YOLOv5的C3结构换成了C2f结构,并对不同尺度模型调整了不同的通道数,这种对模型的微调,大幅提升了模型性能;
- Head部分使用双向特征金字塔结构(Top-down + Bottom-up),提升多尺度特征融合能力,增加跳跃连接(Skip Connections),保留更多底层细节信息(对小目标检测关键)。同时,换成了主流的解耦头结构,将分类与检测头分离。放弃了传统的Anchor-based, 采用Anchor-free模式设计模型,直接预测目标中心点和宽高。减少了超参数优化、避免了anchor与目标匹配计算开销,在不减少精度的基础上,提高模型的效率,并且更适合小目标检测;
- 损失函数采用了TaskAlignedAssigner正样本分配策略,在分类任务中选择了二元交叉熵损失(BCE loss),对每一个类别做是或者不是的分类。在回归任务中,引入了Distribution Focal Loss(DFL)和CIoU,CIoU综合考虑重叠区域、中心点距离和长宽比。提升框的定位精度,DFL将边界框预测建模为概率分布,通过聚焦样本优化回归稳定性。

Backbone:
Backbone部分主要由几个Conv(Conv,Bottleneck,C2f) + C2f组成
Conv:
卷积层 + BN层标准化 + SiLu激活函数
1 #ultralytics.ultralytics.nn.modules.conv.Conv 2 class Conv(nn.Module): 3 """Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation).""" 4 5 default_act = nn.SiLU() # default activation 6 7 def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True): 8 """Initialize Conv layer with given arguments including activation.""" 9 super().__init__() 10 self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False) 11 self.bn = nn.BatchNorm2d(c2) 12 self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity() 13 14 def forward(self, x): 15 """Apply convolution, batch normalization and activation to input tensor.""" 16 return self.act(self.bn(self.conv(x))) 17 18 def forward_fuse(self, x): 19 """Perform transposed convolution of 2D data.""" 20 return self.act(self.conv(x))
Bottleneck:
Bottleneck模块就是标准的一个bottleneck设计,两个卷积层,以及一个表示是否使用残差连接的标记,当shortcut为True,并且输入输出通道数相同时,就使用残差连接。
1 #ultralytics.ultralytics.nn.modules.block.Bottleneck 2 class Bottleneck(nn.Module): 3 """Standard bottleneck.""" 4 5 def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5): 6 """Initializes a standard bottleneck module with optional shortcut connection and configurable parameters.""" 7 super().__init__() 8 c_ = int(c2 * e) # hidden channels 9 self.cv1 = Conv(c1, c_, k[0], 1) 10 self.cv2 = Conv(c_, c2, k[1], 1, g=g) 11 self.add = shortcut and c1 == c2 12 13 def forward(self, x): 14 """Applies the YOLO FPN to input data.""" 15 return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
C2f:
YOLOv8对比v5,在backbone部分将C3结构换成了C2f部件。相比于C3,C2f增加了split和更多的跳跃连接操作,主要结构包括:
- 一个1 * 1的Conv层
- split后n个带有shortcu的Bottleneck层
- Concat后用于调整通道数的Conv层
1 #ultralytics.ultralytics.nn.modules.block.C2f 2 class C2f(nn.Module): 3 """Faster Implementation of CSP Bottleneck with 2 convolutions.""" 4 5 def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5): 6 """Initializes a CSP bottleneck with 2 convolutions and n Bottleneck blocks for faster processing.""" 7 super().__init__() 8 self.c = int(c2 * e) # hidden channels 9 self.cv1 = Conv(c1, 2 * self.c, 1, 1) 10 self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2) 11 self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n)) 12 13 def forward(self, x): 14 """Forward pass through C2f layer.""" 15 y = list(self.cv1(x).chunk(2, 1)) 16 y.extend(m(y[-1]) for m in self.m) 17 return self.cv2(torch.cat(y, 1)) 18 19 def forward_split(self, x): 20 """Forward pass using split() instead of chunk().""" 21 y = list(self.cv1(x).split((self.c, self.c), 1)) 22 y.extend(m(y[-1]) for m in self.m) 23 return self.cv2(torch.cat(y, 1))
SPFF:
Spatial Pyramid Pooling(空间金字塔池化)
1 #ultralytics.ultralytics.nn.modules.block.SPPF 2 class SPPF(nn.Module): 3 """Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher.""" 4 5 def __init__(self, c1, c2, k=5): 6 """ 7 Initializes the SPPF layer with given input/output channels and kernel size. 8 This module is equivalent to SPP(k=(5, 9, 13)). 9 """ 10 super().__init__() 11 c_ = c1 // 2 # hidden channels 12 self.cv1 = Conv(c1, c_, 1, 1) 13 self.cv2 = Conv(c_ * 4, c2, 1, 1) 14 self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2) 15 16 def forward(self, x): 17 """Forward pass through Ghost Convolution block.""" 18 y = [self.cv1(x)] 19 y.extend(self.m(y[-1]) for _ in range(3)) 20 return self.cv2(torch.cat(y, 1))
Head:
head部分相对改动较大,使用了自下而上和自上而下的双向特征金字塔结构,提升多尺度特征融合能力。在检测头部分将耦合头改成了解耦头,使用三个检测头,输出三个特征图(以 YOLOv8 L 为例,特征图大小分别为:80 x 80 x 256,40 x 40 x 512,20 x 20 x 512),每个检测头包含Conv + Conv + nn.Conv2d 网络,分别用于预测框和分类。
1 #ultralytics.ultralytics.nn.modules.head.Detect 2 class Detect(nn.Module): 3 """YOLOv8 Detect head for detection models.""" 4 5 dynamic = False # force grid reconstruction 6 export = False # export mode 7 end2end = False # end2end 8 max_det = 300 # max_det 9 shape = None 10 anchors = torch.empty(0) # init 11 strides = torch.empty(0) # init 12 13 def __init__(self, nc=80, ch=()): 14 """Initializes the YOLOv8 detection layer with specified number of classes and channels.""" 15 super().__init__() 16 self.nc = nc # number of classes 17 self.nl = len(ch) # number of detection layers 18 self.reg_max = 16 # DFL channels (ch[0] // 16 to scale 4/8/12/16/20 for n/s/m/l/x) 19 self.no = nc + self.reg_max * 4 # number of outputs per anchor 20 self.stride = torch.zeros(self.nl) # strides computed during build 21 c2, c3 = max((16, ch[0] // 4, self.reg_max * 4)), max(ch[0], min(self.nc, 100)) # channels 22 self.cv2 = nn.ModuleList( 23 nn.Sequential(Conv(x, c2, 3), Conv(c2, c2, 3), nn.Conv2d(c2, 4 * self.reg_max, 1)) for x in ch 24 ) 25 self.cv3 = nn.ModuleList(nn.Sequential(Conv(x, c3, 3), Conv(c3, c3, 3), nn.Conv2d(c3, self.nc, 1)) for x in ch) 26 self.dfl = DFL(self.reg_max) if self.reg_max > 1 else nn.Identity() 27 28 if self.end2end: 29 self.one2one_cv2 = copy.deepcopy(self.cv2) 30 self.one2one_cv3 = copy.deepcopy(self.cv3) 31 32 def forward(self, x): 33 """Concatenates and returns predicted bounding boxes and class probabilities.""" 34 if self.end2end: 35 return self.forward_end2end(x) 36 37 for i in range(self.nl): 38 x[i] = torch.cat((self.cv2[i](x[i]), self.cv3[i](x[i])), 1) 39 if self.training: # Training path 40 return x 41 y = self._inference(x) 42 return y if self.export else (y, x)
3. Loss计算
YOLOv8在回归分支使用了Distribution Focal Loss(DFLoss)和 CIoU Loss,在分类分支中使用了BCE Loss,通过三个损失函数一定权重比例的加权求和得到总的loss值。
1. 回归分支:关注 “框准不准”(物体位置和大小)
- CIoU Loss(Complete Intersection over Union Loss)直接衡量预测框和真实框的 “重合度”。不仅看两者重叠面积,还考虑中心距离、宽高比例,更全面地判断框是否准。比如预测框和真实框重叠越多、中心越近、形状越像,这个损失就越小。
CloU是预测框和真实框的交集面积和并集面积的比值,反应了两者之间的重叠程度,但是当两个框无重叠时,即CIoU=0时,无法提供梯度反馈,并且当IoU相同时,预测框和真实框也有可能会出现不同的长宽比或中心点距离,因此无法区分对其方式,对如中心点轻微偏移类的小偏差不敏感。
为了解决这些问题,CIoU引入了中心点偏移和长宽比一致性的惩罚项。
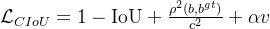
其中:
 中心点距离:是预测框和真实框中心点之间的欧式距离,c是两个框的最小外接矩形的对角线长度
中心点距离:是预测框和真实框中心点之间的欧式距离,c是两个框的最小外接矩形的对角线长度
 长宽比一致性:是衡量长宽比一致性项,是权重系数.
长宽比一致性:是衡量长宽比一致性项,是权重系数.
代码:
1 #ultralytics.ultralytics.utils.metrics.bbox_iou 2 def bbox_iou(box1, box2, xywh=True, GIoU=False, DIoU=False, CIoU=False, eps=1e-7): 3 """ 4 Calculate Intersection over Union (IoU) of box1(1, 4) to box2(n, 4). 5 Args: 6 box1 (torch.Tensor): A tensor representing a single bounding box with shape (1, 4). 7 box2 (torch.Tensor): A tensor representing n bounding boxes with shape (n, 4). 8 xywh (bool, optional): If True, input boxes are in (x, y, w, h) format. If False, input boxes are in 9 (x1, y1, x2, y2) format. Defaults to True. 10 GIoU (bool, optional): If True, calculate Generalized IoU. Defaults to False. 11 DIoU (bool, optional): If True, calculate Distance IoU. Defaults to False. 12 CIoU (bool, optional): If True, calculate Complete IoU. Defaults to False. 13 eps (float, optional): A small value to avoid division by zero. Defaults to 1e-7. 14 Returns: 15 (torch.Tensor): IoU, GIoU, DIoU, or CIoU values depending on the specified flags. 16 """ 17 # Get the coordinates of bounding boxes 18 if xywh: # transform from xywh to xyxy 19 (x1, y1, w1, h1), (x2, y2, w2, h2) = box1.chunk(4, -1), box2.chunk(4, -1) 20 w1_, h1_, w2_, h2_ = w1 / 2, h1 / 2, w2 / 2, h2 / 2 21 b1_x1, b1_x2, b1_y1, b1_y2 = x1 - w1_, x1 + w1_, y1 - h1_, y1 + h1_ 22 b2_x1, b2_x2, b2_y1, b2_y2 = x2 - w2_, x2 + w2_, y2 - h2_, y2 + h2_ 23 else: # x1, y1, x2, y2 = box1 24 b1_x1, b1_y1, b1_x2, b1_y2 = box1.chunk(4, -1) 25 b2_x1, b2_y1, b2_x2, b2_y2 = box2.chunk(4, -1) 26 w1, h1 = b1_x2 - b1_x1, b1_y2 - b1_y1 + eps 27 w2, h2 = b2_x2 - b2_x1, b2_y2 - b2_y1 + eps 28 29 # Intersection area 30 inter = (b1_x2.minimum(b2_x2) - b1_x1.maximum(b2_x1)).clamp_(0) * ( 31 b1_y2.minimum(b2_y2) - b1_y1.maximum(b2_y1) 32 ).clamp_(0) 33 34 # Union Area 35 union = w1 * h1 + w2 * h2 - inter + eps 36 37 # IoU 38 iou = inter / union 39 if CIoU or DIoU or GIoU: 40 cw = b1_x2.maximum(b2_x2) - b1_x1.minimum(b2_x1) # convex (smallest enclosing box) width 41 ch = b1_y2.maximum(b2_y2) - b1_y1.minimum(b2_y1) # convex height 42 if CIoU or DIoU: # Distance or Complete IoU https://arxiv.org/abs/1911.08287v1 43 c2 = cw.pow(2) + ch.pow(2) + eps # convex diagonal squared 44 rho2 = ( 45 (b2_x1 + b2_x2 - b1_x1 - b1_x2).pow(2) + (b2_y1 + b2_y2 - b1_y1 - b1_y2).pow(2) 46 ) / 4 # center dist**2 47 if CIoU: # https://github.com/Zzh-tju/DIoU-SSD-pytorch/blob/master/utils/box/box_utils.py#L47 48 v = (4 / math.pi**2) * ((w2 / h2).atan() - (w1 / h1).atan()).pow(2) 49 with torch.no_grad(): 50 alpha = v / (v - iou + (1 + eps)) 51 return iou - (rho2 / c2 + v * alpha) # CIoU 52 return iou - rho2 / c2 # DIoU 53 c_area = cw * ch + eps # convex area 54 return iou - (c_area - union) / c_area # GIoU https://arxiv.org/pdf/1902.09630.pdf 55 return iou # IoU
- DFLoss(Distribution Focal Loss)YOLOv8 预测边界框时,不是直接给出一个固定的坐标值,而是预测坐标的 “概率分布”(比如预测框的 x 坐标可能在 10-15 之间,其中 12 的概率最高)。DFLoss 的作用是让这个分布更 “集中”—— 也就是让模型对正确的坐标更有信心,减少模糊预测。比如真实 x 坐标是 12,DFLoss 会迫使模型预测 12 的概率远高于 10 或 15,让框的位置更精准。
在遮挡、边界模糊或小目标场景下,真实框的位置存在多种合理性估计,传统方法会强制网络拟合单一值,导致训练不稳定或者欠拟合。
DFL将边界框坐标建模为连续值的离散化概率分布{y0,y1,...yn},通过优化分布的形状(而非单一值)来更鲁棒地学习边界框位置,从而更灵活地建模边界框的不确定性,提升检测精度。
- 让网络预测每个
的概率
- 最终坐标通过期望值计算
假设目标坐标真实值y在和
之间,
, 且
,
DFL 计算公式为:
其中:
- y是真实标签
是相邻的离散标签
和
是模型预测的对应概率
1 #ultralytics.ultralytics.utils.loss.DFLoss 2 class DFLoss(nn.Module): 3 """Criterion class for computing DFL losses during training.""" 4 5 def __init__(self, reg_max=16) -> None: 6 """Initialize the DFL module.""" 7 super().__init__() 8 self.reg_max = reg_max 9 10 def __call__(self, pred_dist, target): 11 """ 12 Return sum of left and right DFL losses. 13 Distribution Focal Loss (DFL) proposed in Generalized Focal Loss 14 https://ieeexplore.ieee.org/document/9792391 15 """ 16 target = target.clamp_(0, self.reg_max - 1 - 0.01) 17 tl = target.long() # target left 18 tr = tl + 1 # target right 19 wl = tr - target # weight left 20 wr = 1 - wl # weight right 21 return ( 22 F.cross_entropy(pred_dist, tl.view(-1), reduction="none").view(tl.shape) * wl 23 + F.cross_entropy(pred_dist, tr.view(-1), reduction="none").view(tl.shape) * wr 24 ).mean(-1, keepdim=True)
2. 分类分支:关注 “认对了没”(物体类别)
- BCE Loss(Binary Cross-Entropy Loss)
- 对每个类别单独计算 “是否属于该类” 的概率损失。比如真实是 “猫”,模型预测 “猫” 的概率是 0.8,“狗” 是 0.1,BCE Loss 会让模型更倾向于把 “猫” 的概率往 1.0 调,“狗” 往 0 调,确保类别判断准确。
BCE Loss是常用于二分类任务的损失函数,输出[0, 1]之间的概率分布,例如大于0.5为正样本,小于则认为是负样本。当在多类别任务中,对每个类别做交叉熵损失,判断是否是该类别,从而支持多标签分类。
2..恢复中断训练:
从先前保存的状态恢复训练是处理深度学习模型时一项关键功能。在多种情况下,这项功能都非常有用,比如当训练过程意外中断时,或者当你希望使用新数据或延长训练周期继续训练模型时。
恢复训练时,Ultralytics YOLO 会加载上次保存的模型权重,并恢复优化器状态、学习率调度器和轮次编号,从而让你可以无缝地从中断的地方继续训练。
1 # 中断后继续训练 2 from ultralytics import YOLO 3 # Load a model 4 model = YOLO("path/to/last.pt") # load a partially trained model 5 # Resume training 6 results = model.train(resume=True)
3.训练参数设置:
YOLO 模型的训练设置包括在训练过程中使用的各种超参数和配置。这些设置会影响模型的性能、速度和精度。关键的训练设置包括批量大小、学习率、动量和权重衰减。
此外,优化器的选择、损失函数以及训练数据集的组成也会对训练过程产生影响。通过对这些设置进行仔细调整和实验,对于优化性能至关重要。
链接:ttps://docs.ultralytics.com/modes/train/#why-choose-ultralytics-yolo-for-training
6.模型推理过程:
YOLOv8 的推理过程和 YOLOv5 几乎一样,唯一差别在于前面需要对 Distribution Focal Loss 中的积分表示 bbox 形式进行解码,变成常规的 4 维度 bbox,后续计算过程就和 YOLOv5 一样了。
以 COCO 80 类为例,假设输入图片大小为 640x640,MMYOLO 中实现的推理过程示意图如下所示:

7 特征图可视化:
在MMYOLO中,特征图可视化是一个重要的功能,可以帮助用户更好地理解模型的特征分布情况。以YOLOv8-s模型为例,进行特征图可视化的步骤如下:
1.先拿官方 “基础模型”从 YOLOv8 的官方网站下载它已经训练好的 YOLOv8-s 模型文件(相当于一个 “半成品模型”,已经学过一些通用知识)。
2.转个格式让 MMYOLO 认识因为 YOLOv8 和 MMYOLO 是两个不同的工具,它们保存模型的 “格式” 不一样。所以需要用一个专门的脚本(yolov8_to_mmyolo)把下载的模型文件转换成 MMYOLO 能看懂的格式,就像把 “Word 文件转成 PDF” 方便不同软件打开一样。注意这个脚本要放在 MMYOLO 的安装文件夹里才能用。
3.用工具看特征图转换后得到一个新的模型文件(比如叫 mmyolov8s.pth),然后用 MMYOLO 自带的可视化工具,就能看到模型处理图片时产生的特征图了。
4.调整显示方式特征图可能很复杂,工具里有几种简化显示的方法(比如取平均值、找最大值),可以选一个看得清楚的。还能调整特征图和原图的对齐方式,让它们对应得更准,方便观察模型到底 “看” 到了图片的哪些部分。
基本步骤:
下载官方权重:首先需要从YOLOv8的官方仓库下载预训练的权重文件。
转换权重文件:使用yolov8_to_mmyolo脚本将YOLOv8的权重文件转换为MMYOLO兼容的格式。这个脚本必须放置在MMYOLO的官方库中才能正确运行。转换后的权重文件通常命名为mmyolov8s.pth 。
可视化特征图:如果需要可视化YOLOv8模型的特征图,可以使用MMYOLO提供的特征图可视化工具。具体步骤如下:
进入MMYOLO的开发分支目录:cd mmyolo
注意:为了确保特征图和图片叠加显示能对齐,需要先将原先的test_pipeline替换为特定的配置。
MMYOLO特征图可视化工具支持的通道压缩策略主要有以下几种:
- select_max:选择每个通道中最大值进行压缩。这种方法的优点是能够保留最重要的特征信息,缺点是可能会忽略一些次要但仍然重要的特征。
- select_mean:选择每个通道的平均值进行压缩。这种方法的优点是能够平滑特征图,减少噪声,缺点是可能会丢失一些重要的细节信息。
- select_min:选择每个通道中最小值进行压缩。这种方法的优点是能够突出背景或低强度区域的特征,缺点是可能会忽略一些重要的前景特征。
- select_sum:选择每个通道的总和进行压缩。这种方法的优点是能够增强特征图的整体强度,缺点是可能会导致过饱和,使得特征图难以区分。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号