
南昌航空大学大一下学期java-题目集1~3总结性Blog——苏礼顺23201608
一、前言
——总结三次题目集的知识点、题量、难度等情况
《面向对象程序设计》这一门课,是教授我们设计代码,掌握类、类间关系,以及面向对象的三大设计原则——封装、继承、多态等面向对象的基本概念和方法,并以面向对象的编程语言java语言设计程序。因此在这三次的题目集都与类的设计与使用有关。
这三次题目集目前仅涉及“封装继承多态”三大特性中的“封装”,尽管如此,题目集中的题目还是有一定的难度。并且三次题目集对于类的知识点涵盖极广,包括但不限于类的声明,创建,使用方法,类的构造方法,成员变量,成员方法的定义与使用方法。还有java语言中包的概念,以及papckage,import语句的使用,类中的组合、聚合、依赖、关联关系,java中方法的重载的实现方式等。
题目集一有五题,题目集二四题,题目集三三题。题目难度逐渐递增。值得一提的是:每次题目集的最后一题都是“答题判断程序”有关的题目。输入的内容包括:题目内容,试卷内容,删除题目等等,最后要求实现模拟小型测试,按要求输出判断结果。三次题目逐渐迭代,设计的类逐渐增多,可实现的功能也逐渐增多。目前没有增加继承与多态,但是后续的此题迭代则会依次增加。题目具有一定挑战度,同时也是对我们类的掌握程度的考验!!
二、设计与分析
——主要是对题目以及自己提交的源码进行分析,加上自己浅浅的解释和心得
(一)题目集一
题目一二都是对类的简单使用,除了主类之外,其他的类只有一个,且都是实体类只要按照题目要求,定义适当的类的属性与方法就可以解决问题。特别地,在使用toString方法的时候,它的返回类型只能是String类型。
题目三四则是关于计算成绩统计类的题目。第三题通过循环依次读入信息,再进行处理与输出。第四题设计了Score类与Student类。Score类放了平时成绩与期末成绩,Student类与Score类是关联关系,一个学生对应他自己的语文、数学、物理成绩。这题自己的出彩之处在于Main里面的对数据的读入的处理方法,两层循环,减少了写读入语句的次数。见如下代码:
public class Main {
public static void main(String[] args) {
Scanner in = new Scanner(System.in);
for(int i = 0; i < 3; i++) {
String id = in.next();
String name = in.next();
Score chinese = new Score();
Score math = new Score();
Score physics = new Score();
for(int j = 0; j < 3;j++) {
if(j!=0) {
String id0 = in.next();
String name0 = in.next();
}
String subject = in.next();
int score1 =in.nextInt();
int score2 = in.nextInt();
if(subject.equals("语文")) {
chinese.setUsual(score1);
chinese.setTerm(score2);
}
if(subject.equals("数学")) {
math.setUsual(score1);
math.setTerm(score2);
}
if(subject.equals("物理")) {
physics.setUsual(score1);
physics.setTerm(score2);
}
}
Student stu = new Student(name, id, chinese,math,physics);
stu.printlnfo();
System.out.printf("\n");
}
}
}题目五是“答题判题程序-1”
输入格式:
程序输入信息分三部分:
1、题目数量
格式:整数数值,若超过1位最高位不能为0,
样例:34
2、题目内容
一行为一道题,可以输入多行数据。
格式:"#N:"+题号+" "+"#Q:"+题目内容+" "#A:"+标准答案
格式约束:题目的输入顺序与题号不相关,不一定按题号顺序从小到大输入。
样例:#N:1 #Q:1+1= #A:2
#N:2 #Q:2+2= #A:4
3、答题信息
答题信息按行输入,每一行为一组答案,每组答案包含第2部分所有题目的解题答案,答案的顺序号与题目题号相对应。
格式:"#A:"+答案内容
格式约束:答案数量与第2部分题目的数量相同,答案之间以英文空格分隔。
样例:#A:2 #A:78
2是题号为1的题目的答案
78是题号为2的题目的答案答题信息以一行"end"标记结束,"end"之后的信息忽略。
输出格式:
1、题目数量
格式:整数数值,若超过1位最高位不能为0,
样例:34
2、答题信息
一行为一道题的答题信息,根据题目的数量输出多行数据。
格式:题目内容+" ~"+答案
样例:1+1=~2
2+2= ~4
3、判题信息
判题信息为一行数据,一条答题记录每个答案的判断结果,答案的先后顺序与题目题号相对应。
格式:判题结果+" "+判题结果
格式约束:
1、判题结果输出只能是true或者false,
2、判题信息的顺序与输入答题信息中的顺序相同样例:true false true
输入样例1:
单个题目。例如:
1
#N:1 #Q:1+1= #A:2
#A:2
end输出样例1:
在这里给出相应的输出。例如:
1+1=~2
true输入样例2:
单个题目。例如:
1
#N:1 #Q:1+1= #A:2
#A:4
end输出样例2:
在这里给出相应的输出。例如:
1+1=~4
false输入样例3:
多个题目。例如:
2
#N:1 #Q:1+1= #A:2
#N:2 #Q:2+2= #A:4
#A:2 #A:4
end输出样例3:
在这里给出相应的输出。例如:
1+1=~2
2+2=~4
true true输入样例4:
多个题目。例如:
2
#N:1 #Q:1+1= #A:2
#N:2 #Q:2+2= #A:4
#A:2 #A:2
end输出样例4:
在这里给出相应的输出。例如:
1+1=~2
2+2=~2
true false输入样例5:
多个题目,题号顺序与输入顺序不同。例如:
2
#N:2 #Q:1+1= #A:2
#N:1 #Q:5+5= #A:10
#A:10 #A:2
end输出样例5:
在这里给出相应的输出。例如:
5+5=~10
1+1=~2
true true输入样例6:
含多余的空格符。例如:
1
#N:1 #Q: The starting point of the Long March is #A:ruijin
#A:ruijin
end输出样例6:
在这里给出相应的输出。例如:
The starting point of the Long March is~ruijin
true输入样例7:
含多余的空格符。例如:
1
#N: 1 #Q: 5 +5= #A:10
#A:10
end输出样例7:
在这里给出相应的输出。例如:
5 +5=~10
true让我们分析下题目:
题目输入分为三个部分
1.输入题目数量,因此已知题目数量,便可以考虑利用确定长度的数组进行对题目的存储。
2.题目输入的形式为“#N:1 #Q:1+1= #A:2”,其中我们只要“1 1+1= 2”这题号,题目内容,标准答案这三个部分,因此考虑正则表达式进行分割。
3.接着是输入答题信息,每一行便会输入所有题目的答题信息,因此我们有两种读取方式:
- 一是:我们整行读取信息后,便需要提取对我们有用的信息,即他输入“#A:2”,但是我们只需要他的“2”,先进行空字符进行分割,然后再对每一个分割的部分进行去除“#A:”的操作得到我们想要的最终答案。
- 二是:因为我们前面已经知道了题目总数,而且题目也告知我们“答案数量与第二部分题目数量相同”,因此我们进行循环读入,读入次数就为题目的总数量,这样我们就一次的得到了“#A:2”的内容,然后我们进行去除“#A:”的操作就可以了。
经过上述的分析,我们也大致可以确定了我们可以用三个实体类来进行我们的信息读入。
- Question类存储no-题目序号,questionTest-题目文本,standAnwer-题目标准答案。
- Paper类用来存储Question类型的数组,即组装试卷。
- Answer类有Paper类型的对象,也有String类型的数组,来是对我们的自己的答案进行存储,还有一个boolean类型的名为judgeAnswer的数组,进行我们的判断答案进行存储。
题目输出形式也为三个部分
1.输出题目数量
2.输出答题信息,输出形式为“题目内容+" ~"+答案”。另外我们观察一种题目的输入输出样例:
输入:2 输出:5+5=~10
#N:2 #Q:1+1= #A:2 1+1=~2
#N:1 #Q:5+5= #A:10 true true
#A:10 #A:2
end
在这一个输入与输出样例中,输入的题目顺序是21但是题目数出的顺序是1,2,再联想到上面的输入答题信息时,“题目的输入顺序与题号不相关,不一定按题号顺序从小到大输入。”以及:输入自己的答题信息时:“答案的顺序号与题目题号相对应”,因此自己对题目信息进行存储后,需要进行题目序号的排序,才能进行相应的后面的判断处理。
3.输出题目数量,输出答题信息,输出形式为“题目内容+" ~"+答案”,然后输出判题信息即trur 或者 false。
下面是自己代码:
代码如上述所述,根据SOURCEMONITIOR生成的情况来看: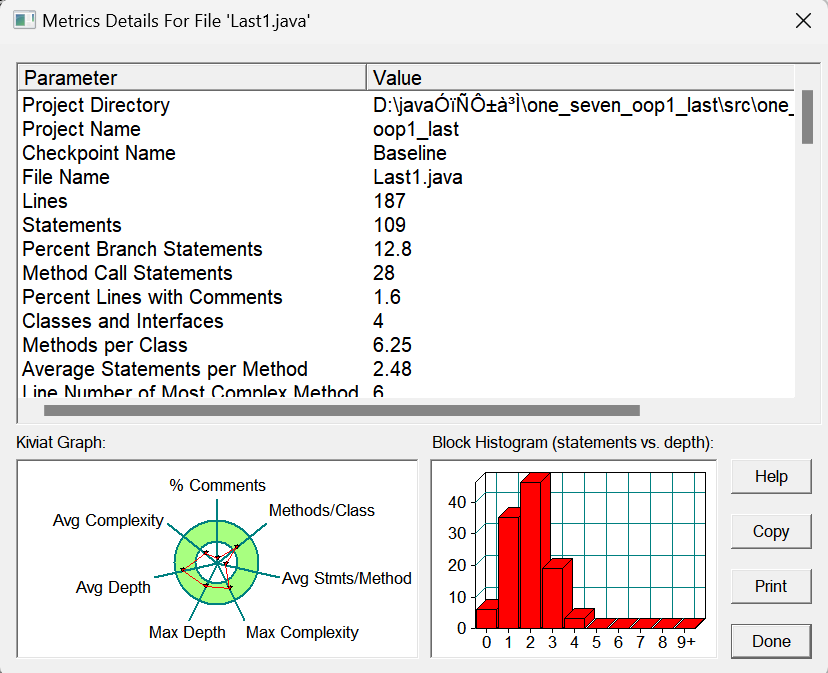
根据数据与雷达图分析:
- 分支语句占比总语句数的百分比为12.8%,此比例较低,说明此代码中分支逻辑较少,更易于理解与维护
- 在雷达图中注释语句占总语句数的百分比最低,说明我的代码可读性较差,可能也难以理解和维护,因此要增加代码的注释比例
- 同时,每个方法的平均语句和数量也较低,可能是因为这段代码不是很复杂,较多的set与get语句使得方法的平均语句和数量较低
而结合自己的代码编写的实际来看,三个类的类间关系设计的并不合理,Question与Paper之间是聚合关系,因为试卷包含题目,而Answer与paper是关联关系,这两个之间的耦合性太强了。我们学过MVC模式,应该放置一个控制类controller,进行对信息的处理,同时写一个view类,来进行对信息的输出。此外,对于题目序号的排序可以进行compareTo方法的重写。而不是用冒泡排序。
(二)题目集二
题目一是是对手机的价格排序以及查找。
这一题新学到了两个东西,一个是ArrayList实现动态数组大小没有限制,一个是利用实现comparable接口,重写compareTo方法,,实行对price的大小来确定手机对象的大小关系 。通过Collections类的sort方法对链表中的对象按照price升序排序。
题目二三则是对类的成员变量,构造方法,等的简单使用。
题目四是“答题判题程序-2”
设计实现答题程序,模拟一个小型的测试,以下粗体字显示的是在答题判题程序-1基础上增补或者修改的内容。
要求输入题目信息、试卷信息和答题信息,根据输入题目信息中的标准答案判断答题的结果。
输入格式:
程序输入信息分三种,三种信息可能会打乱顺序混合输入:
1、题目信息
一行为一道题,可输入多行数据(多道题)。
格式:"#N:"+题目编号+" "+"#Q:"+题目内容+" "#A:"+标准答案
格式约束:
1、题目的输入顺序与题号不相关,不一定按题号顺序从小到大输入。
2、允许题目编号有缺失,例如:所有输入的题号为1、2、5,缺少其中的3号题。此种情况视为正常。样例:#N:1 #Q:1+1= #A:2
#N:2 #Q:2+2= #A:4
2、试卷信息
一行为一张试卷,可输入多行数据(多张卷)。
格式:"#T:"+试卷号+" "+题目编号+"-"+题目分值
题目编号应与题目信息中的编号对应。
一行信息中可有多项题目编号与分值。样例:#T:1 3-5 4-8 5-2
3、答卷信息
答卷信息按行输入,每一行为一张答卷的答案,每组答案包含某个试卷信息中的题目的解题答案,答案的顺序与试卷信息中的题目顺序相对应。
格式:"#S:"+试卷号+" "+"#A:"+答案内容
格式约束:答案数量可以不等于试卷信息中题目的数量,没有答案的题目计0分,多余的答案直接忽略,答案之间以英文空格分隔。
样例:#S:1 #A:5 #A:22
1是试卷号
5是1号试卷的顺序第1题的题目答案
22是1号试卷的顺序第2题的题目答案答题信息以一行"end"标记结束,"end"之后的信息忽略。
输出格式:
1、试卷总分警示
该部分仅当一张试卷的总分分值不等于100分时作提示之用,试卷依然属于正常试卷,可用于后面的答题。如果总分等于100分,该部分忽略,不输出。
格式:"alert: full score of test paper"+试卷号+" is not 100 points"
样例:alert: full score of test paper2 is not 100 points
2、答卷信息
一行为一道题的答题信息,根据试卷的题目的数量输出多行数据。
格式:题目内容+"~"+答案++"~"+判题结果(true/false)
约束:如果输入的答案信息少于试卷的题目数量,答案的题目要输"answer is null"
样例:3+2=~5~true
4+6=~22~false.
answer is null3、判分信息
判分信息为一行数据,是一条答题记录所对应试卷的每道小题的计分以及总分,计分输出的先后顺序与题目题号相对应。
格式:题目得分+" "+....+题目得分+"~"+总分
格式约束:
1、没有输入答案的题目计0分
2、判题信息的顺序与输入答题信息中的顺序相同样例:5 8 0~13
根据输入的答卷的数量以上2、3项答卷信息与判分信息将重复输出。
4、提示错误的试卷号
如果答案信息中试卷的编号找不到,则输出”the test paper number does not exist”,参见样例9。
设计建议:
参考答题判题程序-1,建议增加答题类,类的内容以及类之间的关联自行设计。
输入样例1:
一张试卷一张答卷。试卷满分不等于100。例如:
#N:1 #Q:1+1= #A:2
#N:2 #Q:2+2= #A:4
#T:1 1-5 2-8
#S:1 #A:5 #A:22
end输出样例1:
在这里给出相应的输出。例如:
alert: full score of test paper1 is not 100 points
1+1=~5~false
2+2=~22~false
0 0~0输入样例2:
一张试卷一张答卷。试卷满分不等于100。例如:
#N:1 #Q:1+1= #A:2
#N:2 #Q:2+2= #A:4
#T:1 1-70 2-30
#S:1 #A:5 #A:22
end输出样例2:
在这里给出相应的输出。例如:
1+1=~5~false
2+2=~22~false
0 0~0输入样例3:
一张试卷、一张答卷。各类信息混合输入。例如:
#N:1 #Q:1+1= #A:2
#N:2 #Q:2+2= #A:4
#T:1 1-70 2-30
#N:3 #Q:3+2= #A:5
#S:1 #A:5 #A:4
end输出样例:
在这里给出相应的输出。例如:
1+1=~5~false
2+2=~4~true
0 30~30输入样例4:
试卷题目的顺序与题号不一致。例如:
#N:1 #Q:1+1= #A:2
#N:2 #Q:2+2= #A:4
#T:1 2-70 1-30
#N:3 #Q:3+2= #A:5
#S:1 #A:5 #A:22
end输出样例:
在这里给出相应的输出。例如:
2+2=~5~false
1+1=~22~false
0 0~0输入样例5:
乱序输入。例如:
#N:3 #Q:3+2= #A:5
#N:2 #Q:2+2= #A:4
#T:1 3-70 2-30
#S:1 #A:5 #A:22
#N:1 #Q:1+1= #A:2
end输出样例:
在这里给出相应的输出。例如:
3+2=~5~true
2+2=~22~false
70 0~70输入样例6:
乱序输入+两份答卷。例如:
#N:3 #Q:3+2= #A:5
#N:2 #Q:2+2= #A:4
#T:1 3-70 2-30
#S:1 #A:5 #A:22
#N:1 #Q:1+1= #A:2
#S:1 #A:5 #A:4
end输出样例:
在这里给出相应的输出。例如:
3+2=~5~true
2+2=~22~false
70 0~70
3+2=~5~true
2+2=~4~true
70 30~100输入样例7:
乱序输入+分值不足100+两份答卷。例如:
#N:3 #Q:3+2= #A:5
#N:2 #Q:2+2= #A:4
#T:1 3-7 2-6
#S:1 #A:5 #A:22
#N:1 #Q:1+1= #A:2
#S:1 #A:5 #A:4
end输出样例:
在这里给出相应的输出。例如:
alert: full score of test paper1 is not 100 points
3+2=~5~true
2+2=~22~false
7 0~7
3+2=~5~true
2+2=~4~true
7 6~13输入样例8:
乱序输入+分值不足100+两份答卷+答卷缺失部分答案。例如:
#N:3 #Q:3+2= #A:5
#N:2 #Q:2+2= #A:4
#T:1 3-7 2-6
#S:1 #A:5 #A:22
#N:1 #Q:1+1= #A:2
#T:2 2-5 1-3 3-2
#S:2 #A:5 #A:4
end输出样例:
在这里给出相应的输出。例如:
alert: full score of test paper1 is not 100 points
alert: full score of test paper2 is not 100 points
3+2=~5~true
2+2=~22~false
7 0~7
2+2=~5~false
1+1=~4~false
answer is null
0 0 0~0输入样例9:
乱序输入+分值不足100+两份答卷+无效的试卷号。例如:
#N:3 #Q:3+2= #A:5
#N:2 #Q:2+2= #A:4
#T:1 3-7 2-6
#S:3 #A:5 #A:4
end输出样例:
在这里给出相应的输出。例如:
alert: full score of test paper1 is not 100 points
The test paper number does not exist让我们分析下题目:
对于输入信息
1.首先是此次题目相对于上次题目最大的不同-就是增加了试卷信息,对于试卷信息里面包含了试卷号,题目编号与题目分值然后是输入信息:
2.题目信息-这次没有输入题目数量,只是题目信息,因此不能用定长度的数组来进行对题目信息的存储,而是利用题目一学的Arraylist存储题目的数据。
3.试卷信息-一行为一张试卷,可输入多行试卷,
4.答卷信息-这次的答案信息也多试卷的卷号这一条信息,然后自己的答案按照对应试卷的题目顺序来进行输入
5.设计考虑:试卷类在上一次题目中已经被定义了,因此在上次设计上增加答卷类,用于封装答卷信息。
对于输出信息:
1.输出试卷总分警示:仅当一张试卷的总分分值不等于100分时作提示之用。
2.答卷信息-与上一次的输入一样,不同的是有输出“answer is null”这一种信息。因此最初的设计思路是考虑先遍历试卷,因为题目的试卷的题目数量是一定的,然后找出对应的答题卷,当没有这一题的时候将输出 “answer is null”。同时当对应的答题卷子 找不到的时候,则会输出“the test paper number does not exist”。
3.接着输出判分信息判断每一题的得分。并且汇总总分数。
下面是自己代码:
代码如上述所述,接着将对自己的源码进行分析。
1.因为题目对于题目信息,试卷信息,答题信息的输入是乱序输入的,所以自己在放入题目前是先判断他是何种信息,采用contains函数,来确定放入何处。
2.但是对于信息处理的不足之处是,所有信息的处理都放在了主方法。一个大的while循环 ,里面包含了所有的信息的读取与处理。对于日后的题目的迭代并不好修改以及阅读。
3.然后再在后面一个遍历所有试卷的大循环之中,先找到对应的答卷。在里面我自己使用了choice1与choice2来判断是否找没找到 ,首先从变量的名字上来说,自己的命名就不很规范,应该是以found来表示更能增加可读性。其次自己大可以不必用两个变量来判断。一个足以,要是在遍历答卷的时候没找到就continue,然后遍历整个答卷found仍未false,那么便说明,这个没有找到。然后输出“The test paper number does not exist”便可以了。
4.在上述的那个遍历所有试卷的大循环,这个部分代码数太长,应该拆成几部分:一是判断正误,二是存储分数,三是输出判断结果与与得分。而且这个部分也不应该是放在主方法中,主方法只进行信息的读入与输出。而不是对信息的处理。
根据SOURCEMONITIOR生成的情况来看:
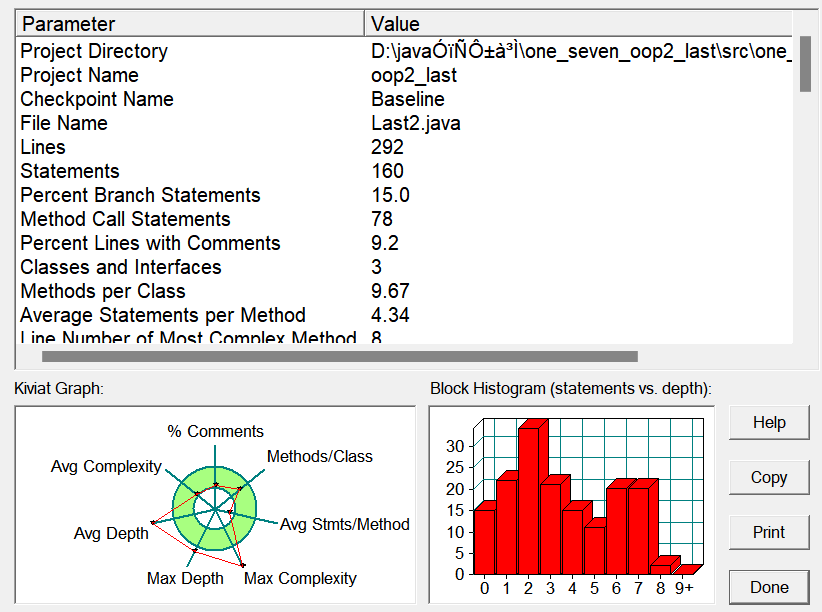
根据数据与雷达图分析:
- 分支语句占总语句数的百分比为 15%。仍然处于较低的水平
- 方法调用语句数目为78,这次与上次相比增加很多,说明了这段代码的模块化程度比上次更高,但也是可能因为这段代码的难度比上次的更大的缘故。
- 含有注释的行占比大幅度增大,上次只是1,6这次到了9.2,注释的增多,说明了代码的可读性也增强了。
- 这段代码的平均深度与最大深度都比较大,可能就是因为我的while大循环与遍历试卷的大循环的缘故。
- 每个方法的平均语句数量比较少,这一点与上面的点相映衬。要是上面的大循环被拆除同时化为其他小部分,那么这段代码就质量更高了。
(三)题目集三
题目一是对输入信息的简单读取并封装到类中,然后提取信息,以设置的格式输出出来。
题目二是要求我们对日期类的简单使用,对输入的日期进行验证和分析。首先,需要验证给定的日期是否为合法日期,然后判断该年是否为闰年,并计算该日期是当年第几天、当月第几天、当周第几天。接着,需要判断输入的起始日期和结束日期是否合法,同时结束日期是否早于起始日期。如果输入的日期全部合法且结束日期不早于起始日期,则输出日期之间的相差天数、月数和年数。如果有任何日期输入非法或结束日期早于起始日期,则输出相应的错误信息。
题目三是“答题判题程序-3”
设计实现答题程序,模拟一个小型的测试,以下粗体字显示的是在答题判题程序-2基础上增补或者修改的内容,要求输入题目信息、试卷信息、答题信息、学生信息、删除题目信息,根据输入题目信息中的标准答案判断答题的结果。
输入格式:
程序输入信息分五种,信息可能会打乱顺序混合输入。
1、题目信息
题目信息为独行输入,一行为一道题,多道题可分多行输入。
格式:"#N:"+题目编号+" "+"#Q:"+题目内容+" "#A:"+标准答案
格式约束:
1、题目的输入顺序与题号不相关,不一定按题号顺序从小到大输入。
2、允许题目编号有缺失,例如:所有输入的题号为1、2、5,缺少其中的3号题。此种情况视为正常。
样例:#N:1 #Q:1+1= #A:2
#N:2 #Q:2+2= #A:4
2、试卷信息
试卷信息为独行输入,一行为一张试卷,多张卷可分多行输入数据。
格式:"#T:"+试卷号+" "+题目编号+"-"+题目分值+" "+题目编号+"-"+题目分值+...
格式约束:
题目编号应与题目信息中的编号对应。
一行信息中可有多项题目编号与分值。
样例:#T:1 3-5 4-8 5-2
3、学生信息
学生信息只输入一行,一行中包括所有学生的信息,每个学生的信息包括学号和姓名,格式如下。
格式:"#X:"+学号+" "+姓名+"-"+学号+" "+姓名....+"-"+学号+" "+姓名
格式约束:
答案数量可以不等于试卷信息中题目的数量,没有答案的题目计0分,多余的答案直接忽略,答案之间以英文空格分隔。
样例:
#S:1 #A:5 #A:22
1是试卷号
5是1号试卷的顺序第1题的题目答案 4、答卷信息
答卷信息按行输入,每一行为一张答卷的答案,每组答案包含某个试卷信息中的题目的解题答案,答案的顺序号与试 卷信息中的题目顺序相对应。答卷中:
格式:"#S:"+试卷号+" "+学号+" "+"#A:"+试卷题目的顺序号+"-"+答案内容+...
格式约束:
答案数量可以不等于试卷信息中题目的数量,没有答案的题目计0分,多余的答案直接忽略,答案之间以英文空格分隔。
答案内容可以为空,即””。
答案内容中如果首尾有多余的空格,应去除后再进行判断。
样例:
#T:1 1-5 3-2 2-5 6-9 4-10 7-3
#S:1 20201103 #A:2-5 #A:6-4
1是试卷号
20201103是学号
2-5中的2是试卷中顺序号,5是试卷第2题的答案,即T中3-2的答案
6-4中的6是试卷中顺序号,4是试卷第6题的答案,即T中7-3的答案
注意:不要混淆顺序号与题号
5、删除题目信息
删除题目信息为独行输入,每一行为一条删除信息,多条删除信息可分多行输入。该信息用于删除一道题目信息,题目被删除之后,引用该题目的试卷依然有效,但被删除的题目将以0分计,同时在输出答案时,题目内容与答案改为一条失效提示,例如:”the question 2 invalid~0”
格式:"#D:N-"+题目号
格式约束:
题目号与第一项”题目信息”中的题号相对应,不是试卷中的题目顺序号。
本题暂不考虑删除的题号不存在的情况。 样例:
#N:1 #Q:1+1= #A:2
#N:2 #Q:2+2= #A:4
#T:1 1-5 2-8
#X:20201103 Tom-20201104 Jack
#S:1 20201103 #A:1-5 #A:2-4
#D:N-2
end
输出
alert: full score of test paper1 is not 100 points
1+1=~5~false
the question 2 invalid~0
20201103 Tom: 0 0~0答题信息以一行"end"标记结束,"end"之后的信息忽略。
输出格式:
1、试卷总分警示
该部分仅当一张试卷的总分分值不等于100分时作提示之用,试卷依然属于正常试卷,可用于后面的答题。如果总分等于100 分,该部分忽略,不输出。
格式:"alert: full score of test paper"+试卷号+" is not 100 points"
样例:alert: full score of test paper2 is not 100 points
2、答卷信息
一行为一道题的答题信息,根据试卷的题目的数量输出多行数据。
格式:题目内容+"~"+答案++"~"+判题结果(true/false)
约束:如果输入的答案信息少于试卷的题目数量,答案的题目要输"answer is null"
样例:
3+2=~5~true
4+6=~22~false.
answer is null
3、判分信息
判分信息为一行数据,是一条答题记录所对应试卷的每道小题的计分以及总分,计分输出的先后顺序与题目题号相对应。
格式:**学号+" "+姓名+": "**+题目得分+" "+....+题目得分+"~"+总分
格式约束:
1、没有输入答案的题目、被删除的题目、答案错误的题目计0分
2、判题信息的顺序与输入答题信息中的顺序相同样例:20201103 Tom: 0 0~0
根据输入的答卷的数量以上2、3项答卷信息与判分信息将重复输出。
4、被删除的题目提示信息
当某题目被试卷引用,同时被删除时,答案中输出提示信息。样例见第5种输入信息“删除题目信息”。
5、题目引用错误提示信息
试卷错误地引用了一道不存在题号的试题,在输出学生答案时,提示”non-existent question~”加答案。例如:
输入:
#N:1 #Q:1+1= #A:2
#T:1 3-8
#X:20201103 Tom-20201104 Jack-20201105 Www
#S:1 20201103 #A:1-4
end
输出:
alert: full score of test paper1 is not 100 points
non-existent question~0
20201103 Tom: 0~0如果答案输出时,一道题目同时出现答案不存在、引用错误题号、题目被删除,只提示一种信息,答案不存在的优先级最高,例如:
输入:
#N:1 #Q:1+1= #A:2
#T:1 3-8
#X:20201103 Tom-20201104 Jack-20201105 Www
#S:1 20201103
end
输出:
alert: full score of test paper1 is not 100 points
answer is null
20201103 Tom: 0~0
6、格式错误提示信息
输入信息只要不符合格式要求,均输出”wrong format:”+信息内容。
例如:wrong format:2 #Q:2+2= #47、试卷号引用错误提示输出
如果答卷信息中试卷的编号找不到,则输出”the test paper number does not exist”,答卷中的答案不用输出,参见样例8。
8、学号引用错误提示信息
如果答卷中的学号信息不在学生列表中,答案照常输出,判分时提示错误。参见样例9。
本题暂不考虑出现多张答卷的信息的情况。
输入样例1:
简单输入,不含删除题目信息。例如:
#N:1 #Q:1+1= #A:2
#T:1 1-5
#X:20201103 Tom
#S:1 20201103 #A:1-5
end输出样例1:
在这里给出相应的输出。例如:
alert: full score of test paper1 is not 100 points
1+1=~5~false
20201103 Tom: 0~0输入样例2:
简单输入,答卷中含多余题目信息(忽略不计)。例如:
#N:1 #Q:1+1= #A:2
#T:1 1-5
#X:20201103 Tom
#S:1 20201103 #A:1-2 #A:2-3
end输出样例3
简单测试,含删除题目信息。例如:
alert: full score of test paper1 is not 100 points
1+1=~2~true
20201103 Tom: 5~5输入样例3:
简单测试,含删除题目信息。例如:
#N:1 #Q:1+1= #A:2
#N:2 #Q:2+2= #A:4
#T:1 1-5 2-8
#X:20201103 Tom-20201104 Jack-20201105 Www
#S:1 20201103 #A:1-5 #A:2-4
#D:N-2
end输出样例3:
在这里给出相应的输出,第二题由于被删除,输出题目失效提示。例如:
alert: full score of test paper1 is not 100 points
1+1=~5~false
the question 2 invalid~0
20201103 Tom: 0 0~0输入样例4:
简单测试,含试卷无效题目的引用信息以及删除题目信息(由于题目本身无效,忽略)。例如:
#N:1 #Q:1+1= #A:2
#N:2 #Q:2+2= #A:4
#T:1 1-5 3-8
#X:20201103 Tom-20201104 Jack-20201105 Www
#S:1 20201103 #A:1-5 #A:2-4
#D:N-2
end输出样例4:
输出不存在的题目提示信息。例如:
alert: full score of test paper1 is not 100 points
1+1=~5~false
non-existent question~0
20201103 Tom: 0 0~0输入样例5:
综合测试,含错误格式输入、有效删除以及无效题目引用信息。例如:
#N:1 +1= #A:2
#N:2 #Q:2+2= #A:4
#T:1 1-5 2-8
#X:20201103 Tom-20201104 Jack-20201105 Www
#S:1 20201103 #A:1-5 #A:2-4
#D:N-2
end输出样例5:
在这里给出相应的输出。例如:
wrong format:#N:1 +1= #A:2
alert: full score of test paper1 is not 100 points
non-existent question~0
the question 2 invalid~0
20201103 Tom: 0 0~0输入样例6:
综合测试,含错误格式输入、有效删除、无效题目引用信息以及答案没有输入的情况。例如:
#N:1 +1= #A:2
#N:2 #Q:2+2= #A:4
#T:1 1-5 2-8
#X:20201103 Tom-20201104 Jack-20201105 Www
#S:1 20201103 #A:1-5
#D:N-2
end输出样例6:
答案没有输入的优先级最高。例如:
wrong format:#N:1 +1= #A:2
alert: full score of test paper1 is not 100 points
non-existent question~0
answer is null
20201103 Tom: 0 0~0输入样例7:
综合测试,正常输入,含删除信息。例如:
#N:2 #Q:2+2= #A:4
#N:1 #Q:1+1= #A:2
#T:1 1-5 2-8
#X:20201103 Tom-20201104 Jack-20201105 Www
#S:1 20201103 #A:2-4 #A:1-5
#D:N-2
end输出样例7:
例如:
alert: full score of test paper1 is not 100 points
1+1=~5~false
the question 2 invalid~0
20201103 Tom: 0 0~0输入样例8:
综合测试,无效的试卷引用。例如:
#N:1 #Q:1+1= #A:2
#T:1 1-5
#X:20201103 Tom
#S:2 20201103 #A:1-5 #A:2-4
end输出样例8:
例如:
alert: full score of test paper1 is not 100 points
The test paper number does not exist输入样例9:
无效的学号引用。例如:
#N:1 #Q:1+1= #A:2
#T:1 1-5
#X:20201106 Tom
#S:1 20201103 #A:1-5 #A:2-4
end输出样例9:
答案照常输出,判分时提示错误。例如:
alert: full score of test paper1 is not 100 points
1+1=~5~false
20201103 not found输入样例10:
信息可打乱顺序输入:序号不是按大小排列,各类信息交错输入。但本题不考虑引用的题目在被引用的信息之后出现的情况(如试卷引用的所有题目应该在试卷信息之前输入),所有引用的数据应该在被引用的信息之前给出。例如:
#N:3 #Q:中国第一颗原子弹的爆炸时间 #A:1964.10.16
#N:1 #Q:1+1= #A:2
#X:20201103 Tom-20201104 Jack-20201105 Www
#T:1 1-5 3-8
#N:2 #Q:2+2= #A:4
#S:1 20201103 #A:1-5 #A:2-4
end输出样例10:
答案按试卷中的题目顺序输出。例如:
alert: full score of test paper1 is not 100 points
1+1=~5~false
中国第一颗原子弹的爆炸时间~4~false
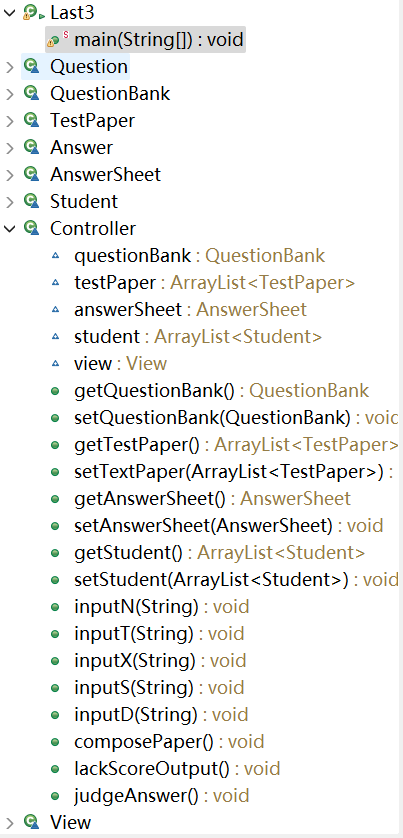
20201103 Tom: 0 0~0代码结构如图所示——
分析自己的代码:
1.主方法进行信息的读入:因为会有错误信息的输入所以要进行正则表达式的匹配,只是之前的contains是远不能足以胜任的。当输入的信息匹配这种模式的时候,才可能被读入,否则就输出出来。但是我的正则表达式太长太复杂了。可读性非常差,也不利于后面的代码的维护。
2.比上次好的是,增加了controller类,里面的各种方法来进行对信息的输入切割与处理判断。
3.controller来进行对nstxd的读入,以及组装试卷compose功能,judgeAnswer功能。降低了其他实体类之间的耦合度。
4.而view类则存放输出语句,提高代码的覆用性。
根据SOURCEMONITIOR生成的情况来看:
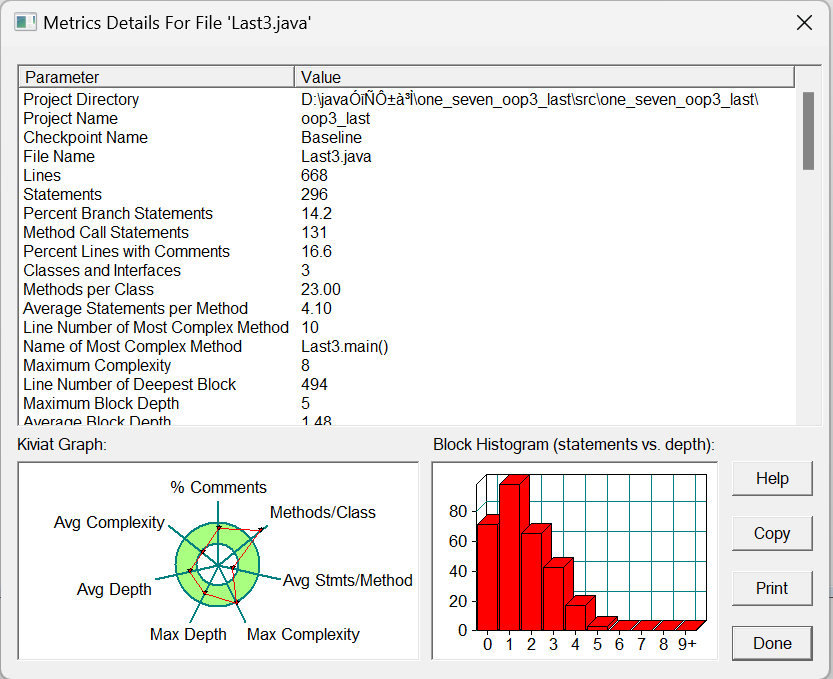
根据数据与雷达图分析:
- 分支语句占总语句数的百分比为 14.2%。仍然处于较低的水平,保持。
- 方法调用语句数目为131,这次与上次相比增加很多,说明了这段代码的模块化程度比上次更高,但也是可能因为这段代码的难度比上次的进一步更大的缘故。
- 这段代码的平均深度与最大深度都比较适中
- 每个方法的平均语句数量比较少,这一点估计是因为controller类中一个大循环干了很多功能的缘故。
三、踩坑心得
四、改进建议
鉴于最后一题目是迭代的,所以我的最终的改进建议只是在最后一题的基础上提出改进想法
1.在主方法中,修改掉那个大循环,只是读入一条语句,然后交由controller进行匹配,匹配到某种信息再进行切割。
2.切割设置一个方法,用于不同类型的切割,也方便对后续的不同的切割类型进行继承。
3.主类的形式大体不会改变,question存储单个题目信息,queationBank存储多个题目,构成题库,testPaper是对应的试卷。但是Answer由存储一个答卷改为存储一道答案,包括他的序号,答案,分数。为后续的增加多选题与填空题做准备。AnswerPaper是组装试题卷。
4.对于大循环中,将主要只是进行遍历,判断的事情另写一个方法,交由那个方法,降低代码深度。
五、总结
终于啊。今天上从9点开始手打敲到了下午5点多!就只是今天的打字,还不算我之前的打字的数目,我的输入法就刚告诉我已经打了4931个字。好了言归正传。
这几次pta真的写的令我酣畅淋漓,令我等胆颤心惊。前一秒还大风卷我三重茅,举杯销愁愁更愁。后一秒就千树万树梨花开,一日看尽长安花了。
其实总结看来,现在回首,之前的题目也不是有多难。现在闭着眼睛都能把题目复述一遍。可能很大的情况就是畏难情绪,以及看到别人得到分了时候让你急躁。其余就只是自己的认真读懂题目 ,多读几遍,一定多读几遍,把需求看清了,然后按照需求来写!写错了大不了重新删了重新来过呗,也不是要死要活的,毕竟提升代码能力,锻炼设计能力才是正道!!然后平常注意休息,保持精神充沛,提高写代码时的专注度,也为自己日后某天猛熬夜做准备。
自己的边写边调试的习惯是蛮好的。当写完一个模块的时候,就自己调试验证他的正确性,保证代码的正确。
需要提升的就是自己的效率了,要是别人和我同时写代码,我可能要读题目理解题目,构思好长时间,而构思的程度也可能是和别人差不多的。所以这部分要加强。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号