
【C】字符统计程序
Github项目源码地址:https://github.com/ututono/software-programmen
-
任务要求
wc.exe 是一个常见的工具,它能统计文本文件的字符数、单词数和行数。这个项目要求写一个命令行程序,模仿已有wc.exe 的功能,并加以扩充,给出某程序设计语言源文件的字符数、单词数和行数。
实现一个统计程序,它能正确统计程序文件中的字符数、单词数、行数,以及还具备其他扩展功能,并能够快速地处理多个文件。
具体功能要求:
- 基本功能列表:(完成)
wc.exe -c //返回文件 file.c 的字符数
wc.exe -w //返回文件 file.c 的词的数目
wc.exe -l //返回文件 file.c 的行数- 扩展功能:(完成)
-s 递归处理目录下符合条件的文件。
-a 返回更复杂的数据(代码行 / 空行 / 注释行)。- 高级功能:(完成)
-x 参数。这个参数单独使用。如果命令行有这个参数,则程序会显示图形界面,用户可以通过界面选取单个文件,程序就会显示文件的字符数、行数等全部统计信息。
-
PSP
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
| Planning | 计划 | 30 | |
| Estimate | 估计时间 | 1000 | 1200 |
| Development | 开发 | 800 | 800 |
| Analysis | 需求分析 | 10 | 10 |
| Design Spec | 生成设计文档 | 20 | 20 |
| Design Review | 审计复审 | 30 | 20 |
| Coding Standard | 代码规范 | 30 | 60 |
| Design | 具体设计 | 120 | 180 |
| Coding | 具体编码 | 600 | 800 |
| Code Review | 代码复审 | 300 | 600 |
| Test | 测试 | 200 | 400 |
| Reporting | 报告 | 60 | 60 |
|
Test Report |
测试报告 | 60 | 60 |
| Size Measurement | 计算工作量 | 30 | 30 |
|
Postmorem & Process Improvement Plan |
事后总结 | 100 | 180 |
| 合计 |
-
解题思路
对程序简单分析,将其主要分为三个部分
- 对字数、行数做分析和统计的函数
- 对文件进行查询操作的函数
- GUI界面
对于第一点,程序的整体代码并不复杂,只是起初在对于扩展功能中的空行、注释行、代码行的定义有所混淆
满足空行的条件:
- 除制表符以外,每行空行只能出现至多一次的 “}” 或 “{”
满足代码行的条件:
- 除了 “}” 或 “{”和制表符,每行代码行至少有一个或以上的字符
满足空行的条件
- 在满足空行的条件下,带有“//”或“/*”(即,不是所有带“//”或“/*”都是注释行,也有可能是代码行)
第二点通过查阅C中关于文件操作的函数得以解决
第三点通过查阅之后之后,发现通过C来写GUI界面主要有以下几点:
- 通过Windows API编写
较为复杂,入门时间成本较大,不适合短时间开发,参考图书《Windows程序设计》
- 通过MFC
是微软公司提供的一个类库,以C++类的形式封装了Windows API,并且包含一个应用程序框架,其中包含大量Windows句柄封装类和很多Windows的内建控件和组件的封装类。
- 通过一些第三方作者提供的库
-
设计实现过程
代码主要函数
1 //基本功能 2 int CharCount(char *path); //字符统计函数 -c 3 int WordCount(char *path); //单词统计函数 -w 4 int LineCount(char *path); //函数统计函数 -l 5 6 void UebrigFunktion(char *path); //复杂行数统计函数 7 int EmptylineCount(char *path); //空行统计函数 8 int CoCount(char *path); //注释行统计函数 9 int CodeCount(char *path); //代码统计函数 10 11 void Filefind(char *path,char *filename); //递归查找文件
-
代码说明
空行统计代码,考虑的特殊情况比较多,包括"{"或"}"前后都是制表符等情况
1 while (!feof(fp)) 2 { 3 int tag = 0; 4 int len = 0; 5 int tag1 = 0; //tag1<2表示行内只有格式控制符或者单个 '}' '{' 6 if (fgets(str, sizeof(str), fp)) 7 { 8 for(len = 0;(len<strlen(str)&&(tag1<2));len++) 9 { 10 if (str[0] == '\n') 11 { 12 n++; 13 break; 14 } 15 else if (!(str[len] == '\n' || str[len] == '\t' || str[len] == ' ')) 16 { 17 if (str[len] == '{' || str[len] == '}'&& !tag1) 18 tag1=1; 19 else tag1 = 2; 20 } 21 if (len == strlen(str) - 1) n++; //如果行内只有格式控制符或者单个 '}' '{'则为空行 22 } 23 }
第二点的文件操作在实现的时候主要学习了一些文件的操作方法,尤其是有关于句柄
1 void Filefind(char * path,char *filename) //$ review:check chinese word 2 { 3 HANDLE Find; 4 WIN32_FIND_DATA finddata; 5 char dir[200]; 6 char dirChoose[200]; 7 int n = 0; 8 9 strcpy(dir, path); 10 strcat(dir, "\\*.*"); //这里一定要指明通配符,不然不会读取所有文件和目录 11 Find = FindFirstFile(charstrtowcharstr(dir), &finddata); 12 do 13 { 14 if ((finddata.dwFileAttributes & FILE_ATTRIBUTE_DIRECTORY != 0)) //判断是否具有某个属性,可以用按位and运算符(&) 15 { 16 if (strcmp(wchartochar(finddata.cFileName), ".") != 0 && strcmp(wchartochar(finddata.cFileName), "..") != 0) //一旦找到'.'或"..",则不为空文件夹 17 { 18 strcpy(dir, path); 19 strcat(dir, "\\"); 20 strcat(dir, wchartochar(finddata.cFileName)); 21 Filefind(dir, filename); 22 } 23 } 24 else 25 { 26 27 if (MatchWithAsteriskW(wchartochar(finddata.cFileName), filename)) //文件判断 28 { 29 strcpy(m_path[n++].filename,wchartochar(finddata.cFileName)); 30 printf("%2d Lage ist:%s\\%s\n", n,path,wchartochar(finddata.cFileName)); 31 } 32 } 33 } while (FindNextFile(Find,&finddata)); 34 m_path; 35 printf("choose the num(nur Num):"); 36 scanf("%d", &n); 37 strcat(path, "\\"); 38 liemain(strcat(path, m_path[n - 1].filename)); 39 FindClose(Find); 40 }
此外因为<windows.h>中的函数都是使用w*类变量,例如wchar、LPCWSTR(* wchar)。
wchar_t是采用win32两个字节UNICODE编码,可以正确存储汉字。
char属于C和C++的最常见的基本数据类型,长度为一个字节,只能存储ASII码。
下面这行代码不会报错但是c的值却不是汉字‘汉’,因为只有一个字节,所以无法存储,打印出来是乱码(?)。
char c = '汉';
wchar_t是采用win32两个字节UNICODE编码,可以正确存储汉字。
对于两种类型的数组同样都可以保存汉字,下面的两行代码没有错误
char* c = "汉字";
wchar_t* cc = L"汉字";
但是长度不同,c的长度是5而cc的长度是3,一个汉字同样需要占据两个char的存储空间。
在vc++6.0和vs中一个字符串默认是按照单字节编码,也就是char*类型,如果要使用两个字节编码wchar_t*存储字符串,
需要在字符串前添加L或使用TEXT("你的字符串")函数。
在调用之前的函数时会出现值类型转换不兼容的问题,在查阅相关资料之后,使用了以下函数
1 char * wchartochar(const wchar_t* wchar) //WCHAR转换为CHAR 2 { 3 char * m_char; 4 int len = WideCharToMultiByte(CP_ACP, 0, wchar, wcslen(wchar), NULL, 0, NULL, NULL); 5 m_char = new char[len + 1]; 6 WideCharToMultiByte(CP_ACP, 0, wchar, wcslen(wchar), m_char, len, NULL, NULL); 7 m_char[len] = '\0'; 8 return m_char; 9 } 10 11 const LPCWSTR charstrtowcharstr(char *charstr) //charstr转化成LPCWSTR 12 { 13 14 WCHAR wszClassName[256]; 15 memset(wszClassName, 0, sizeof(wszClassName)); 16 MultiByteToWideChar(CP_ACP, 0, charstr, strlen(charstr) + 1, wszClassName,sizeof(wszClassName) / sizeof(wszClassName[0])); 17 return wszClassName; 18 }
MFC相关函数:因为直接套用MFC的框架,所以GUI的界面基本不用写,只要处理Button的事件相应就行。
1 void CMFCApplication2Dlg::OnClickedSaveButton() 2 { 3 UpdateData(TRUE); 4 char *pathstr = wchartochar(m_filename_edit); 5 m_chc_edit = CharCount(pathstr); 6 m_wc_edit = WordCount(pathstr); 7 m_linec_edit = LineCount(pathstr); 8 m_emptyline_edit = EmptylineCount(pathstr); 9 m_coc_edit = CodeCount(pathstr); 10 m_commitoutc_edit = CoCount(pathstr); 11 12 UpdateData(FALSE); 13 }
-
测试运行
(单元测试等占位)
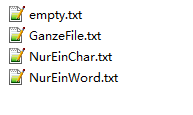
测试文件:空文件、一个字符文件、空行文件、包含源代码文件
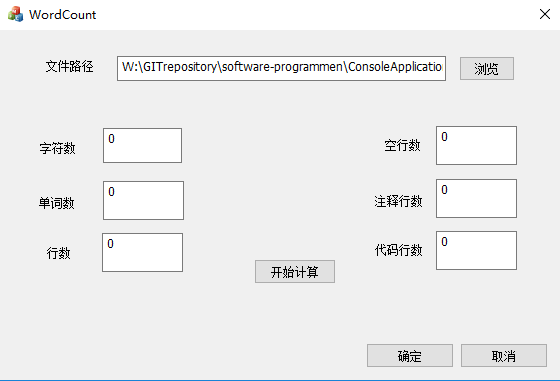
空文件
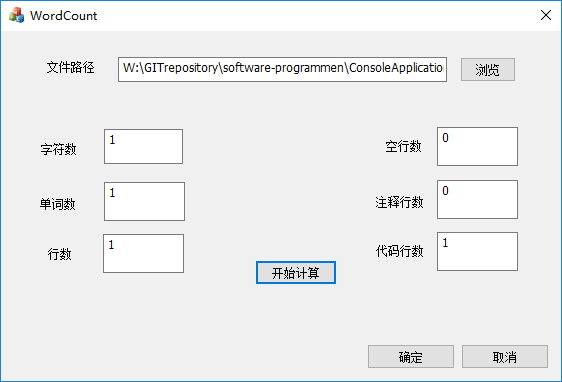
只有一个字符

只有一个单词
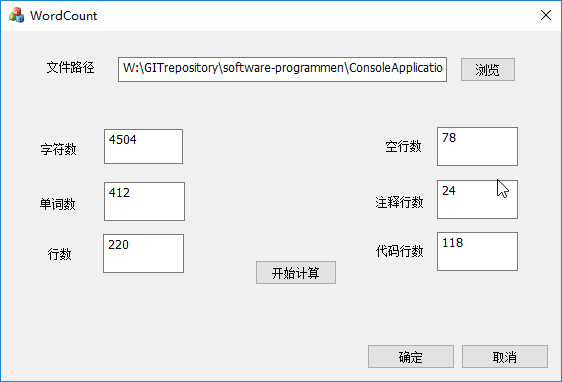
源文件
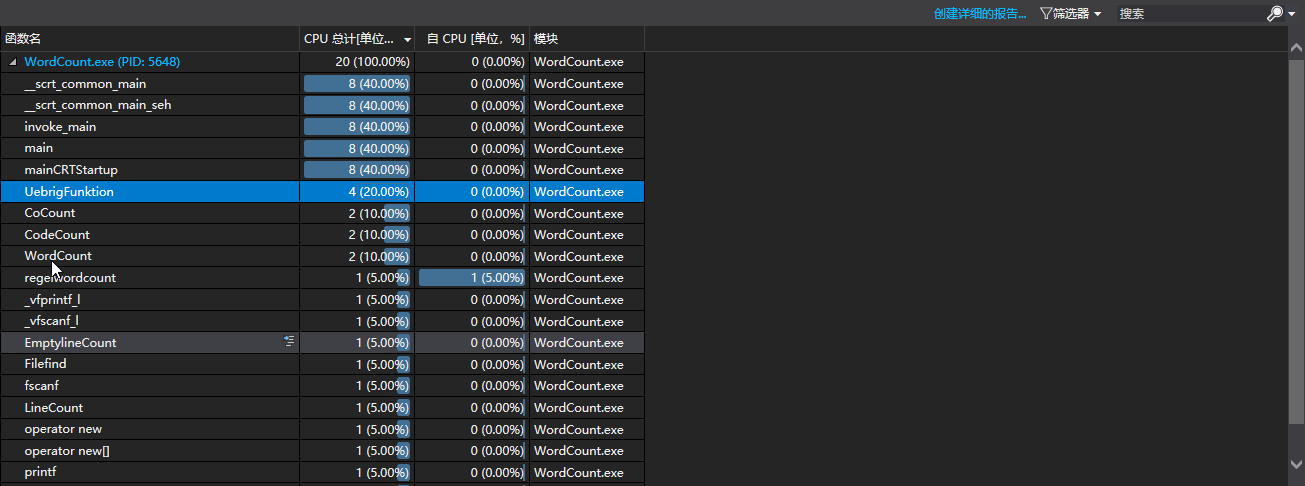
性能分析
耗时比较多的是
UebringFunktion函数:计算并输出代码行、注释行和空行。
可能是打印比较费时
GUI界面选择文件

GUI界面计算
-
项目小结
- 对Git有了初步了解,以前虽然也使用过git,但是没有这次碰到的问题多,实际上在开发工程的市场中有接近一半的时间在调试Git的各种问题,主要碰到过但不仅包括以下几点
- .gitignore不起作用,导致push的文件过大
- 给本地仓库瘦身,删除本地仓库中的大文件
- 两个不同远程仓库的连接冲突问题
- clone远程仓库后新建的本地仓库无法与相关联
- ssh证书所引起的一系列问题
2. 翻阅了《构建之法》,虽不甚了解,但是也依葫芦画瓢慢慢学习
3.了解并使用了一些基础的C语言中文件相关的函数
4.软件开发中的测试方法
5.C/C++的图形化界面开发方法MFC的简单尝试
-
参考
- MFC入门编程系列:http://www.jizhuomi.com/software/147.html
- C对汉字的处理:http://www.cnblogs.com/this-543273659/archive/2011/07/26/2117200.html
- Git删除大文件:https://blog.csdn.net/zcf1002797280/article/details/50723783
- ,gitignore无效处理方法:https://blog.csdn.net/q664243624/article/details/78343400
- Git忽略处理规则:https://www.cnblogs.com/kevingrace/p/5690241.html
- web端VSTS使用方法:http://www.cnblogs.com/jiangyongtao/p/8285171.html
