
kafka
1. 异步通信原理
1.1 观察者模式
观察者模式,又交发布-订阅模式;定义对象间一种一对多的依赖关系,使得当一个对象改变状态,则所有依赖于它的对象都会得到通知并自动更新
一个对象(目标对象)的状态发生改变,所有的依赖对象(观察者对象)都会得到通知
现实中的应用场景: 线上购物的到货通知,降价通知 ,就是这些用户订阅了这些 货物的状态变更消息,一旦状态变更,会主动把这些消息推送给这些订阅的用户。
1.2 生产者消费者模型
传统模式:生产者直接将消息传递给指定的消费者,缺点是耦合性特别高,当生产者或者消费者发生变化,都需要重写业务逻辑。
生产者消费者模式:
通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而通过阻塞队列来进行通讯

在生产者消费者模式中,可以有n 个线程进行生产,同时 m 个线程进行消费,两种角色通过内存缓冲区进行通信,生产者负责向缓冲区里面添加数据单元,消费者负责从缓冲区里面取出数据单元, 其缓存区一般是一个队列,遵循 先进先出 的原则,即先到的数据消息先被消费掉。
优点:
-
-
支持并发。生产者直接调用消费者的某个方法过程中函数调用是同步的,万一消费者处理数据很慢,生产者就会白白糟蹋大好时光。
-
支持忙闲不均,削峰填谷。如果生产者生产数据的速度时快时慢,缓存区的好处就体现出来了,当生产者产生数据快,消费者来不及处理,未处理的数据可以暂时存放在缓冲区,当生产者的生产数据速度慢下来,消费者再慢慢处理掉生产的数据。
数据单元
-
数据单元必须关联到某种业务对象,数据单元和业务对象应该处于一对一或者一对多的关系,如果数据单元的颗粒度太小,会增加数据传输的次数,颗粒度太大会增加单个数据单元传输的时间,影响后期消费。
-
在传输过程中,要保证数据单元的完整性
-
各个数据单元之间没有互相依赖,某个数据单元传输失败不应该影响已经完成传输的单元,,也不影响尚未完成传输的单元
2. 消息系统原理
一个消息系统负责将数据从一个应用传递到另外一个应用,应用只需关注于数据,无需关注数据在两个或多个应用间是如何传递的。
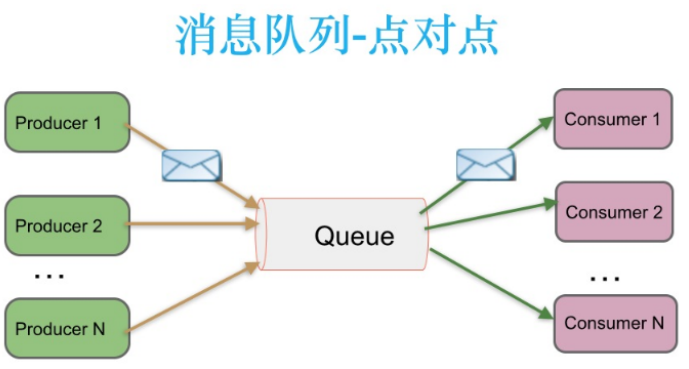
2.1 点对点消息传递
在点对点消息系统中,消息持久化到一个队列中。此时,将有一个或多个消费者消费队列中的数据。但是一条消息只能被消费一次。当一个消费者消费了队列中的某条数据之后,该条数据则从消息队列中删除。该模式即使有多个消费者同时消费数据,也能保证数据处理的顺序。基于推送模型的消息系统,由消息代理记录消费状态
消息代理将消息推送(push)到消费者后,标记这条消息为已经被消费,但是这种方式无法很好
地保证消费的处理语义。
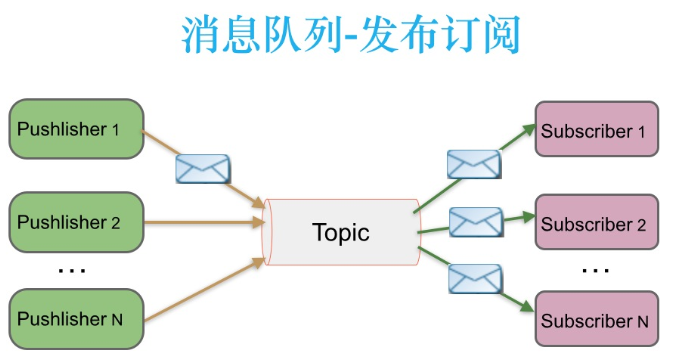
2.2 发布订阅消息传递
在发布-订阅消息系统中,消息的生产者称为发布者,消费者称为订阅者。
消息被持久化到一个topic中,消费者可以订阅一个或多个topic,消费者可以消费该topic中所有的数据,同一条数据可以被多个消费者消费,数据被消费后不会立马删除。
Kafka 采取拉取模型(Poll),由自己控制消费速度,以及消费的进度,消费者可以按照任意的偏移量
进行消费。
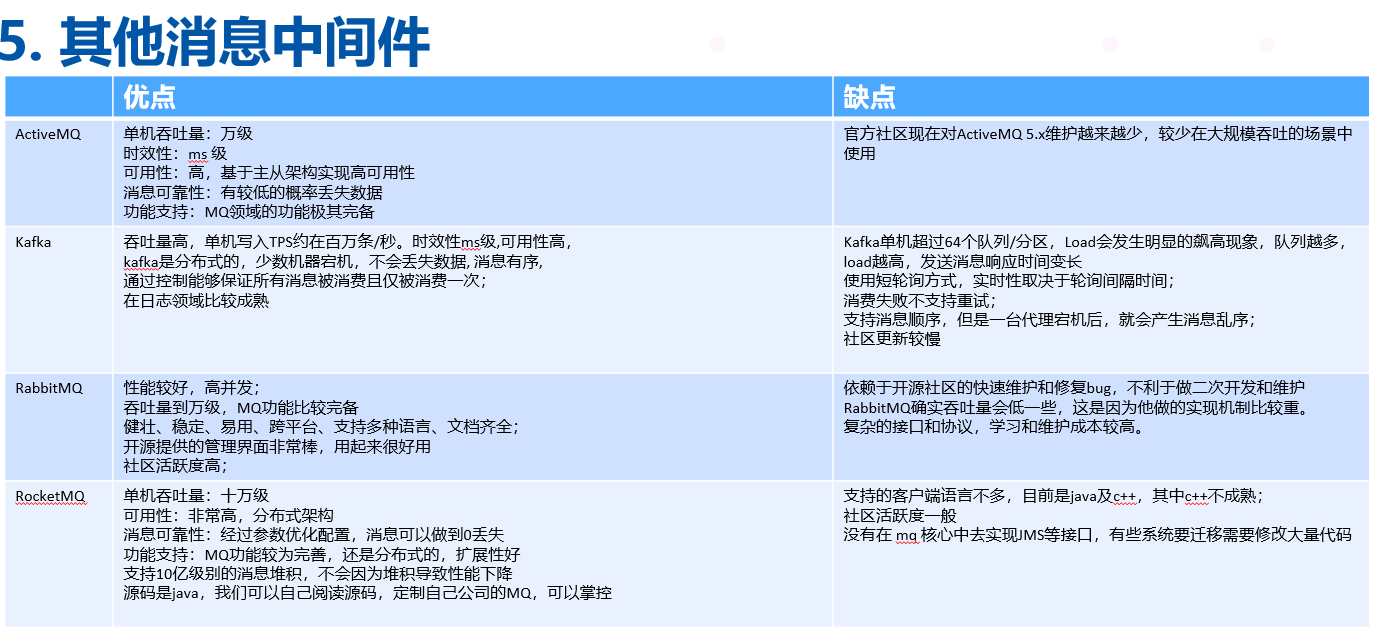
主流的消息中间件有:
ActiveMQ
RocketMQ
RabbitMQ
KAFKA
Redis 也可以做为消息中间件,但是Redis 在数据量超过10k 之后性能很慢,并且基于内存的数据存储有可能丢失数据
3. kafka 简介
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。
Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。
3.1 设计目标
-
以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间的访问性能。
-
高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒100K条消息的传输。
-
支持Kafka Server间的消息分区,及分布式消费,同时保证每个partition内的消息顺序传输。
-
同时支持离线数据处理和实时数据处理。
-
支持在线水平扩展
3.2 Kafka 的优点
-
解耦。
-
冗余。
-
扩展性
-
灵活性&峰值处理能力
-
可恢复性
-
顺序保证
-
缓冲
-
异步通信
4.Kafka 系统架构
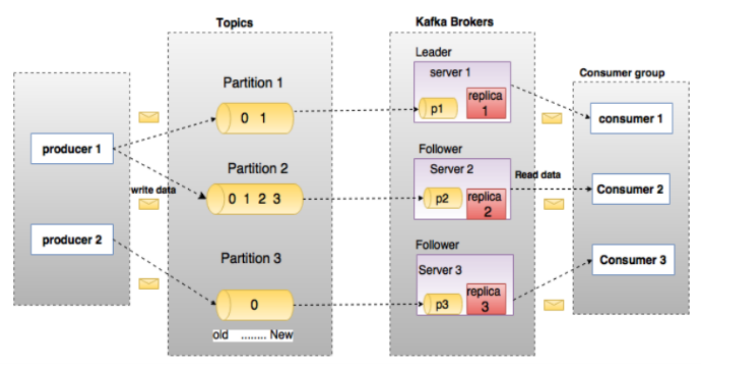
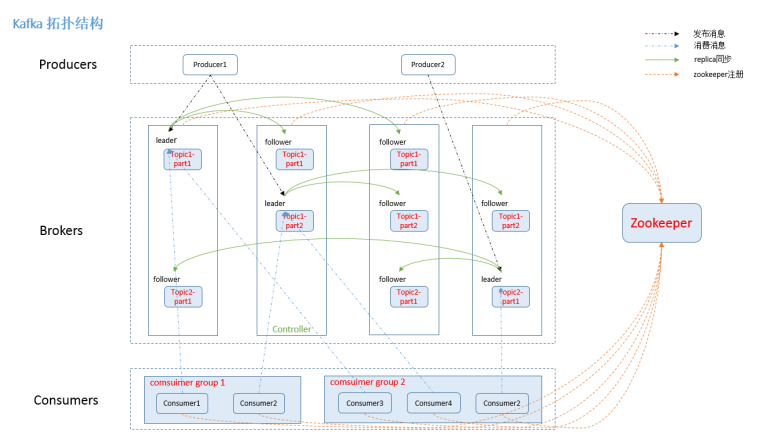
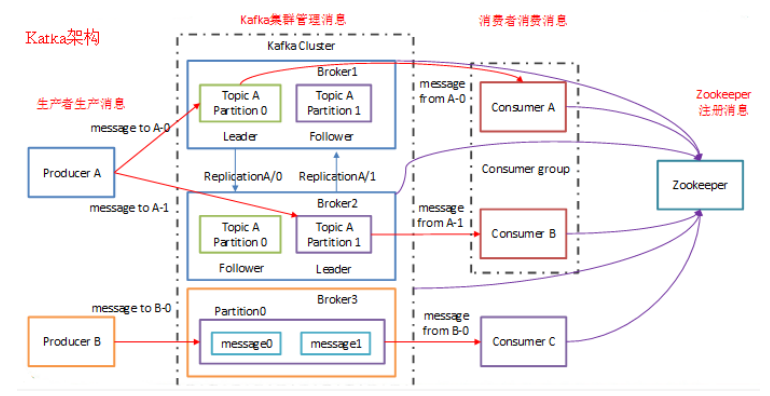
4.1. Broker
Kafka 集群包含一个或多个服务器,服务器节点称为broker。
4.2. Topic
每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。类似于数据库的表名 或者ES的 Index
物理上不同 Topic 的消息分开存储,逻辑上一个Topic 的消息虽然保存于一个或多个broker上但用户只需指定消息的 Topic 即可生产或消费数据而不必关心数据存于何处)
创建流程:
-
controller在ZooKeeper的/brokers/topics节点上注册watcher,当topic被创建,则 controller会通过watch得到该topic的partition/replica分配。
-
controller从/brokers/ids读取当前所有可用的broker列表,对于set_p中的每一个 partition:
2.1 从分配给该partition的所有replica(称为AR)中任选一个可用的broker作为新的 leader,并将AR设置为新的ISR
2.2 将新的leader和ISR写 入/brokers/topics/[topic]/partitions/[partition]/state
-
controller通过RPC向相关的broker发送LeaderAndISRRequest。
删除流程:
-
controller在zooKeeper的/brokers/topics节点上注册watcher,当topic被删除,则 controller会通过watch得到该topic的partition/replica分配。
-
若delete.topic.enable=false,结束;否则controller注册在/admin/delete_topics上 的watch被fire controller 通过回调向对应的broker发送StopReplicaRequest。
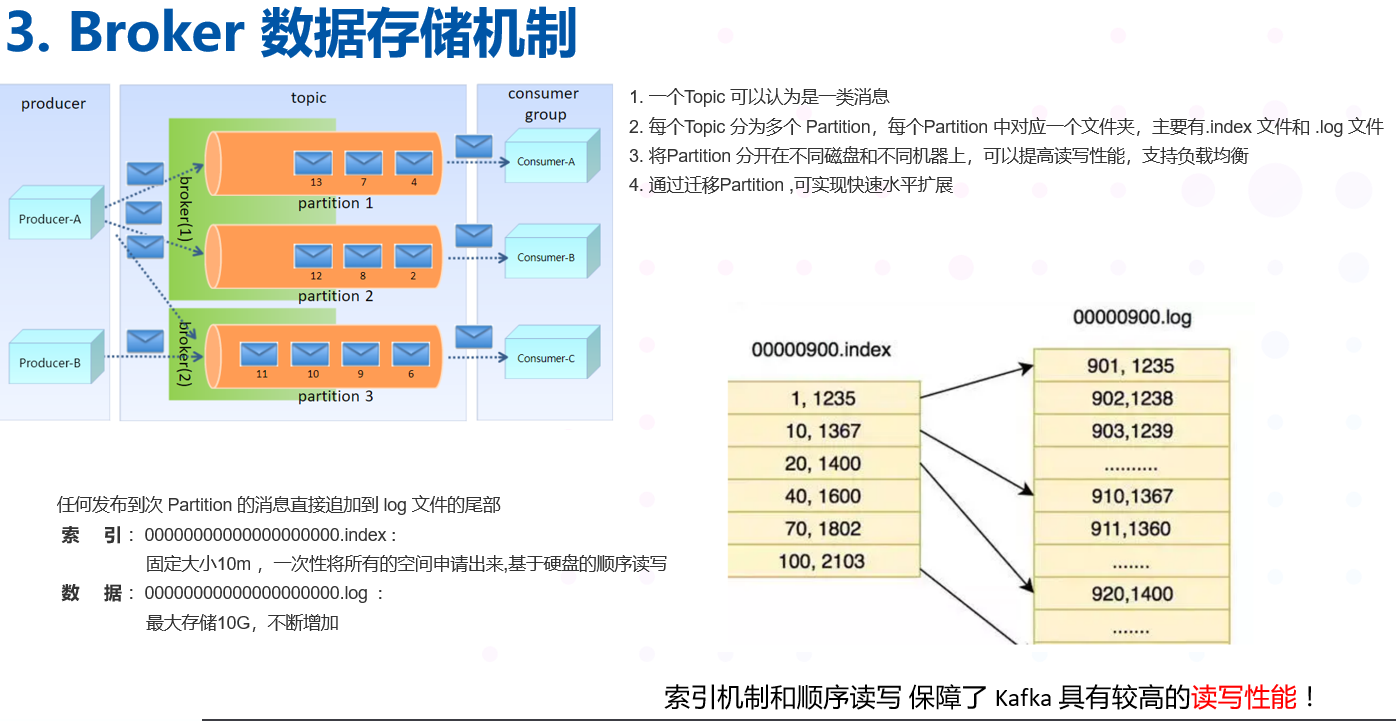
4.3 Partition
-
一个topic 中的数据被分割为一个或者多个partition , 每个topic 至少有一个partition.
-
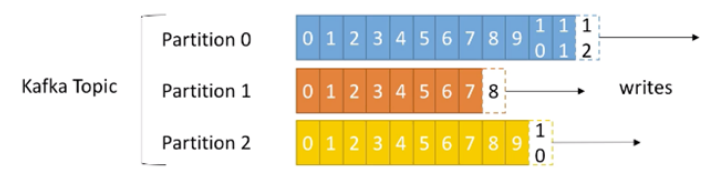
当生产者生产数据的时候,根据分配策略,选择分区,然后将消息追加到指定的分区的末尾,即队列的末尾
3. Partition 数据路由规则: 如果指定了partition ,则直接使用,没有指定partition ,但指定了key ,通过对key 的value 进行Hash, 选出一个partition, 如果partition 和key 都没有指定,使用轮询选出一个partition
-
每个消息都会有一个自增的编号,offset , 用来标识顺序和标识消息的偏移量
-
每个partition 中的数据使用多个 segment 文件进行存储
-
partition 中的数据是有序的,不同partition 之间的数据丢失了数据的顺序。
-
如果topic 中有多个 partition ,消费数据时不能保证数据的顺序,严格保证消息的消费顺序的场景下,需要将partition 的数目 设置为 1 。
PS :
这点我们在实际的项目中,在 十分钟损失电量计算过程中,由于同一个测点可能多发,我们选用后到的为最终的值进行计算,如果上游 topic 中设置的 partition 数目不为1 的话,可能在消费的时候,先到的错误数据反而后消费,这就导致错误的数据覆盖正确的数据。这单需要验证,验证 partion 的数据,以及 key 是什么 ?
4.4 Leader
-
每个 partition 有多个副本,并且有且仅有一个作为 Leader, Leader 是当前负责数据的读写的partition
-
操作顺序:
2.1 producer 先从zookeeper 的 state 节点找到该 partition 的 Leader
2.2 producer 将消息发送给该 Leader
2.3 Leader 将消息写入本地 log
2.4 followers 从 Leader pull 消息,写入本地 log 后向 Leader 发送ACK ,确定同步完成
2.5 Leader 收到所有ISR中的 replica 发送的ACK 消息后,确定所有的从节点同步完成之后,增加HW (high watermark ,最后commit 的 offset ) ,并向 producer 发送ACK
4.5 Follower
-
Follower 跟随 Leader ,所有写请求都通过Leader 路由,数据变更会广播给所有的Follower, Follower 与Leader 保持数据一致
-
如果Leader 失效,则从Follower 中选举一个新的Leader
-
当Follower 挂掉、卡主或者同步太慢,Leader 会把这个Follower 从 ISR 列表中删除,重新创建一个Follower
4.6 Replication
-
数据会存放到 topic 的partition 中,但是有可能分区会损坏,因此我们需要对分区的数据进行备份,备份多少份取决数据的重要程度
-
将分区分为Leader(1) 和Follower (n) ,Leader 负责写入和读取数据,Follower 只负责备份,保证了数据的一致性
-
备份数 设置 为 n ,则表示 Leader + Follower = n 个,主数据加备份数据一共 n 份
-
Kafka 分配Replica的算法如下: 顺序取余
4.1 将所有 broker (假设共 n 个 broker ) 和待分配的 partition 顺序
4.2 将第 i 个 partition 分配到 第 ( i % n ) 个 broker 上
4.3 将第 i 个 partition 的第 j 个 replica 分配到 第 (i + j )% n 个 broker 上。
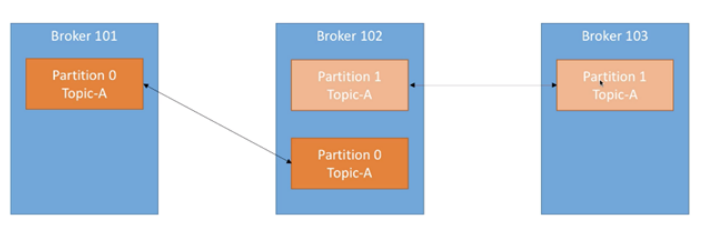
4.7 Producer
-
生产者即数据的发布者,该角色将消息发布到kafka 的 topic 中
-
broker 接收到生产者发送的消息后, broker 将该消息追加到当前用于追加数据的 segment 文件中
-
生产者发送的消息,存储到一个partioton 中,生产者也可以指定数据存储的partition
4.8 consumer
-
消费者可以从 broker 中读取数据,消费者可以消费多个 topic 中的数据
-
kafka 提供的两套 consumer API :
2.1 The hige-level Consumer API
2.2 The simpleConsumer API
-
High-level Consumer API 提供了一个从kafka 消费数据的高层抽象,而 SimpleConsumer API 则需要开发人员更多的关注细节
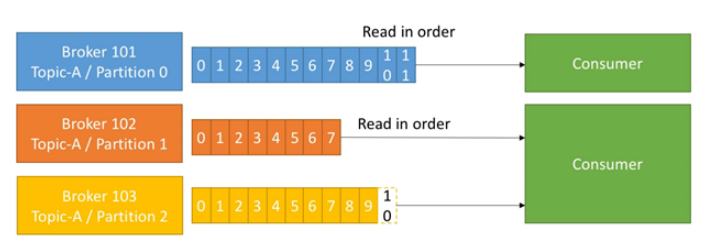
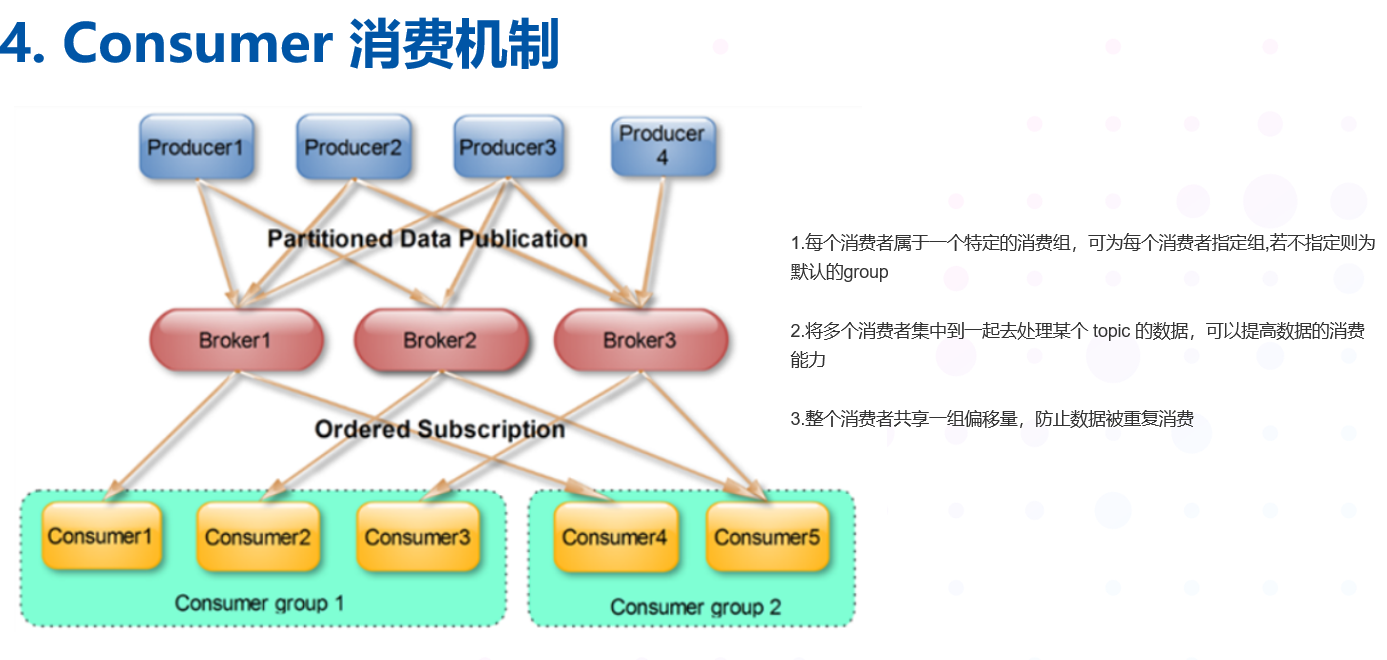
4.9 Consumer Group
-
每个Consumer 属于一个特定的Consumer Group ,可为每个Consumer 指定Group name ,若不指定则属于默认的group
-
将多个消费者集中到一起去处理某个 topic 的数据,可以更快的提高数据的消费能力
-
整个消费者共享一组偏移量,防止数据被重复读取消费
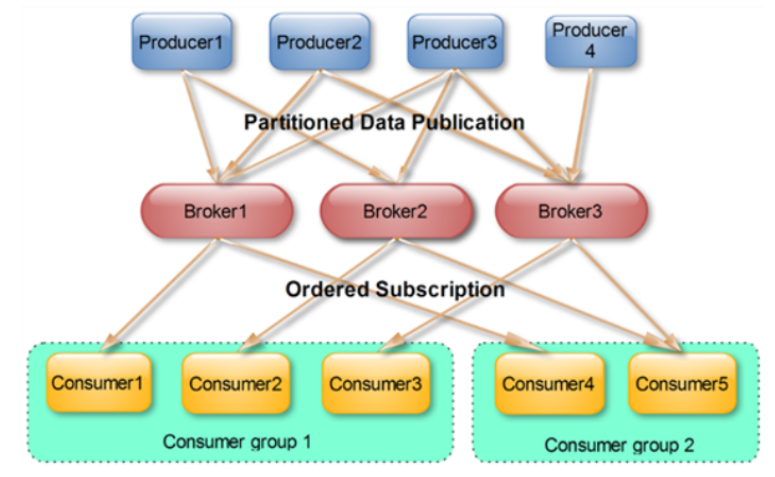
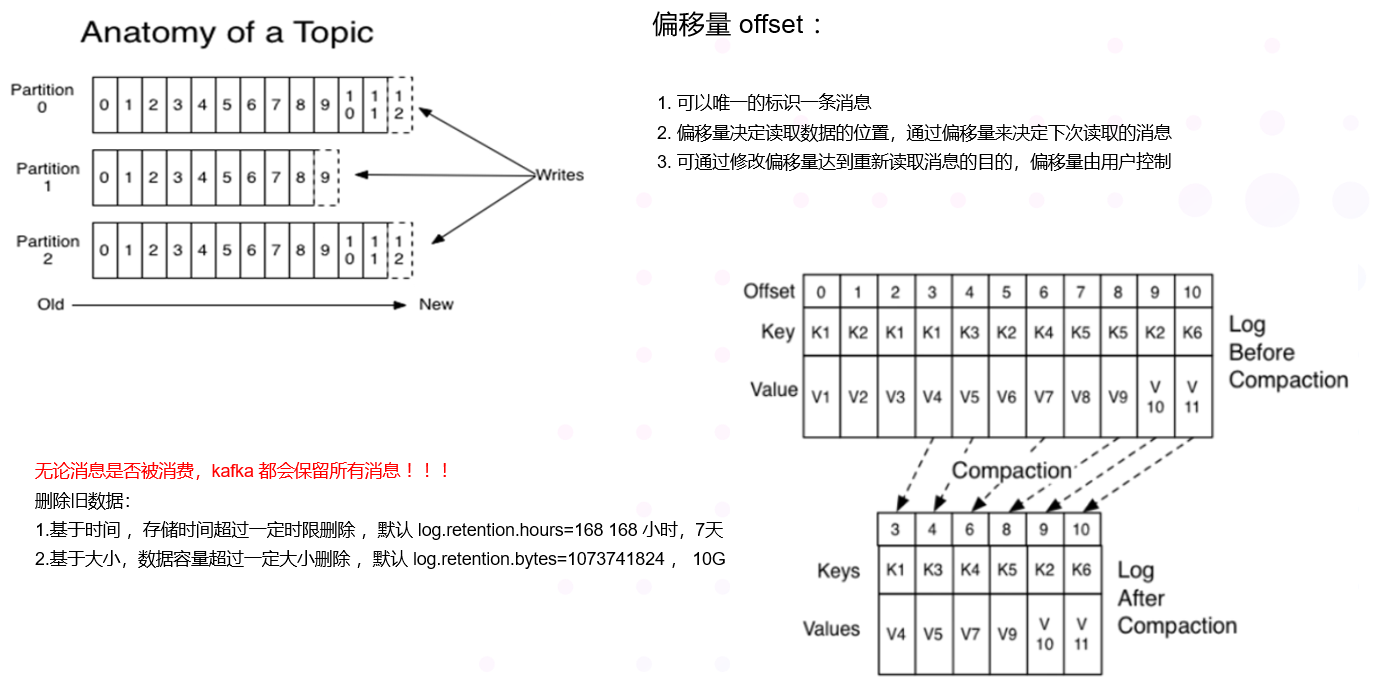
4.10 offset 偏移量
-
可以唯一的标识一条消息
-
偏移量决定读取数据的位置,不会有线程安全的问题,消费者可以通过偏移量来决定下次读取的消息
-
消息被消费之后,并不一定马上删除,这样多个业务就可以重复使用kafka的消息
-
我们某一个业务也可以通过修改偏移量达到重新读取消息的目的,偏移量由用户控制
-
消息最终还是会被删除的,默认生命周期 为 7 天
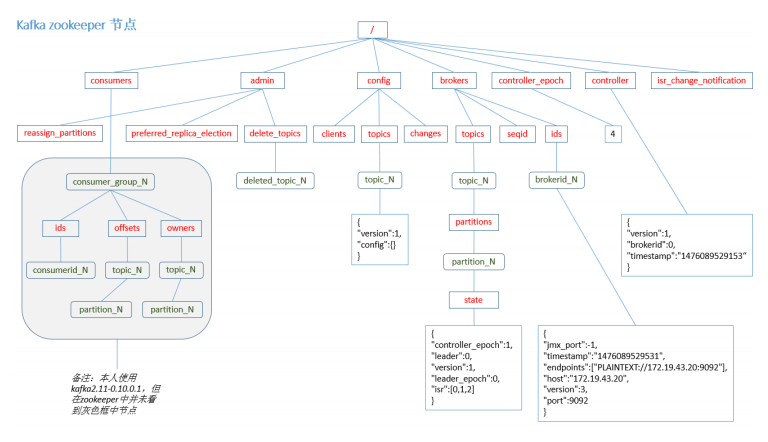
4.11 Zookeeper
kafka 通过 zookeeper 来存储集群的 meta 信息
5. Kafka 数据检索机制
为什么kafka 的性能如此高,是 这个要重点看看,做两页PPT ,对比redis 的B+ 树结构

-
topic在物理层面以partition为分组,一个topic可以分成若干个partition
-
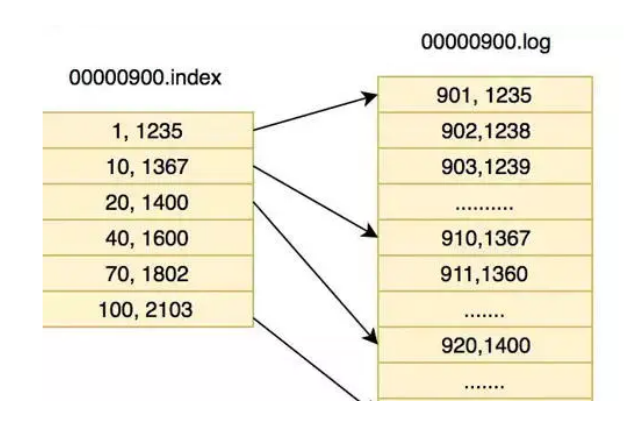
partition还可以细分为Segment,一个partition物理上由多个Segment组成 , segment 的参数有两个:
log.segment.bytes:单个segment可容纳的最大数据量,默认为1GB
log.segment.ms:Kafka在commit一个未写满的segment前,所等待的时间(默认为7天)
-
LogSegment 文件由两部分组成,分别为“.index”文件和“.log”文件,分别表示为 Segment 索引文
件和数据文件。
3.1 partition全局的第一个segment从0开始,后续每个segment文件名为上一个segment文件最后一条消息的offset值
3.2 数值大小为64位,20位数字字符长度,没有数字用0填充

-
消息都具有固定的物理结构,包括:offset(8 Bytes)、消息体的大小(4 Bytes)、crc32(4 Bytes)、
magic(1 Byte)、attributes(1 Byte)、key length(4 Bytes)、key(K Bytes)、payload(N Bytes)等等
字段,可以确定一条消息的大小,即读取到哪里截止。
 PS:
PS:
有一个参数 anto.commit.enable 默认为 true ,消费之后自动更新 offset ,增加偏移量,将这个改为 false ,然后再消费使用完之后,再去手动提交这个 offset ,这样就不会因为服务挂掉,而导致数据丢失。结合我们实际的服务,订阅到测点的数据之后,要写入到clikhouse 之后,才默认为这条数据 消费处理完了,才更新这个offset ,这样才能最大限度的保障,我们的服务不会因为故障而导致数据丢失,也不会有重复消费,基于此分布式架构,最大限度的提升可靠性和稳定性
6. 数据的安全性
6.1 Producer delivery guarantee
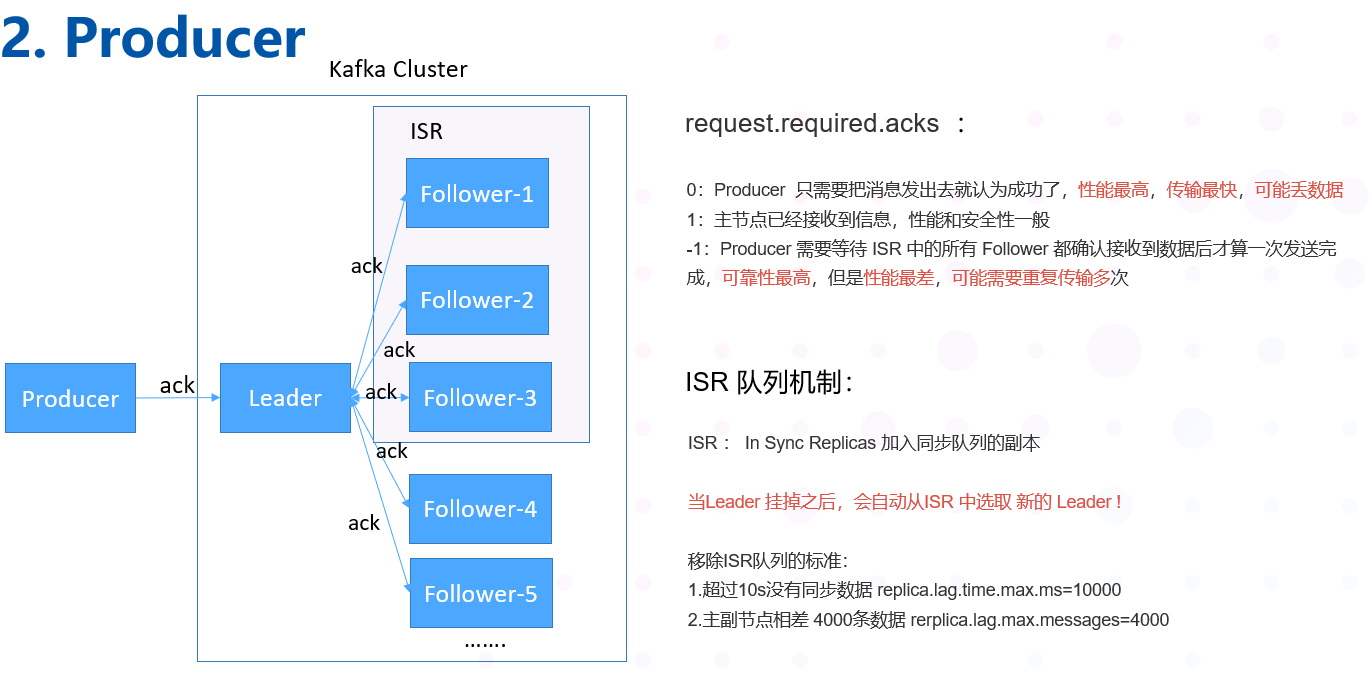
Producers可以选择是否为数据的写入接收ack,有以下3种ack的配置选项:
request.required.acks :
0:Producer 只需要把消息发出去就认为成功了,性能高,安全性低,传输最快,但可能会丢数据
1:主节点已经接收到信息,性能一般,安全性一般
-1:Producer 需要等待 ISR 中的所有 Follower 都确认接收到数据后才算一次发送完成,可
靠性最高,但是性能较慢。性能最差,可能需要重复传输多次
6.2 ISR 机制
ISR : In Sync Replicas 加入同步队列的副本
ISR = Leader + 没有落后太多的副本
当主节点挂掉之后,会从ISR 中挑选一个新的节点作为新的主节点
判断的标准:
-
超过10s没有同步数据 replica.lag.time.max.ms=10000
-
主副节点相差 4000条数据 rerplica.lag.max.messages=4000
脏节点选举
kafka采用一种降级措施来处理:选举第一个恢复的node作为leader提供服务,以它的数据为基准,这个措施被称为脏 leader选举; 如果在 follower 还没来得及同步数据的时候,主节点挂了,并且 生产者不会重发数据,这个时候就有可能导致数据丢失。
6.3 Broker 数据存储机制
无论消息是否被消费,kafka 都会保留所有消息
有两种策略可以删除旧数据
-
基于时间 ,存储时间超过一定时限删除 ,默认 log.retention.hours=168 168 小时,7天
-
基于大小,数据容量超过一定大小删除 ,默认 log.retention.bytes=1073741824 , 10G
6.4 重复消费和数据的丢失
有可能一个消费者取出了一条数据(offset=88),但是还没有处理完成,但是消费者被关闭了
如果下次还能从88重新处理就属于完美情况
如果下次数据从86开始,就属于数据的重复消费
如果下次数据从89开始,就是与数据的丢失
消费者自动提交偏移量的时间间隔props.put("auto.commit.interval.ms", "1010");
提交间隔 > 单条执行时间 (重复)
提交间隔 < 单条执行时间 (丢失)




 浙公网安备 33010602011771号
浙公网安备 33010602011771号