
论文查重之小白都懂
| 这个作业属于哪个课程 | 软件工程2024-双学位(广东工业大学) |
|---|---|
| 这个作业要求在哪里 | 软件工程第二次作业 |
| 这个作业的目标 | 1. 在Gitcode仓库中新建一个学号为名的文件夹 2. 记录PSP表格 3. 使用编程语言完成论文查重程序 4. 使用Code Quality Analysis分析代码 5. 使用Studio Profiling Tools来优化代码 6. 使用Gitcode来管理代码 7. 使用单元测试对项目进行测试,并使用插件查看测试分支覆盖率等指标 |
| 其他参考文献 | 无 |
我的GitCode链接 |
论文查重
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 60 |
| ·Estimate | ·估计这个任务需要多少时间 | 300 | 440 |
| Development | 开发 | 60 | 40 |
| ·Analysis | ·需求分析(包括学习新技术) | 20 | 20 |
| ·Design Spec | ·生成设计文档 | 20 | 30 |
| ·Design Review | ·设计复审 | 10 | 30 |
| ·Coding Standard | ·代码规范(为目前的开发制定合适的规范) | 10 | 10 |
| ·Design | ·具体设计 | 30 | 50 |
| ·Coding | ·具体编码 | 40 | 60 |
| ·Code Review | ·代码复审 | 10 | 20 |
| ·Test | ·测试(自我测试,修改代码,提交修改) | 30 | 50 |
| Reporting | 报告 | 30 | 30 |
| ·TestReport | ·测试报告 | 20 | 10 |
| ·Size Measurement | ·计算工作量 | 10 | 10 |
| ·Postmortem & Process Improvement Plan | ·事后总结,提出过程改进计划 | 10 | 20 |
| ·合计 | 330 | 440 |
论文查询程序设计
首先是编程语言的选择。由于python在数据分析领域已经很成熟,并且数据分析的率也很高,所以综合考虑后,python是最佳选择。
经过查询一些博客,发现python的difflib库非常适合论文查重,所以本博客站在巨人的肩膀上再进行开发。
difflib中常用两个类:SequenceMatcher 和 Differ,它们都可以用来比较两个序列(如字符串、列表、元组等)之间的差异,并生成相应的结果,十分方便。
difflib 库中的 SequenceMatcher 类是 Python 的一个非常有用的工具,用于比较两个序列之间的相似度,找出它们之间最长的连续匹配的子序列。它可以用于比较任何类型的序列(如字符串、列表或元组),非常适合于文本比较和差异分析等场景。以下是 SequenceMatcher 的一些基本使用方法和介绍:
SequenceMatcher基本使用
首先,你需要从 difflib 模块导入 SequenceMatcher 类:
from difflib import SequenceMatcher
然后,你可以创建一个 SequenceMatcher 对象,通过传入两个序列来初始化:
matcher = SequenceMatcher(None, "文本1", "文本2")
在创建 SequenceMatcher 对象时,第一个参数是一个可调用对象,用于指定如何判断两个元素相等。通常,如果你只是想简单地比较序列中的元素,可以将其设置为 None,这样比较就会使用默认的相等判断。
获取匹配度
SequenceMatcher 提供了 ratio() 方法来计算两个序列之间的相似度(返回值是一个在 0 到 1 之间的浮点数,1 表示完全匹配):
similarity = matcher.ratio()
print(similarity)
找出匹配的块
你可以使用 get_matching_blocks() 方法来获取序列之间匹配的块。这个方法返回一个列表,列表中的每个元素都是一个具有三个元素的元组 (a, b, n),表示序列 a 中从索引 a 开始、序列 b 中从索引 b 开始、长度为 n 的子序列是匹配的。
matching_blocks = matcher.get_matching_blocks()
for block in matching_blocks:
print(block)
查找差异
difflib.SequenceMatcher 还提供了 get_opcodes() 方法,返回一个操作码列表,描述如何从第一个序列变换到第二个序列。这个方法非常有用于实现差异比较工具,可以显示两个序列之间的差异。
opcodes = matcher.get_opcodes()
for tag, i1, i2, j1, j2 in opcodes:
print(f"{tag}: a[{i1}:{i2}] b[{j1}:{j2}]")
这里的 tag 表示操作类型(如 'replace'、'delete'、'insert' 或 'equal'),i1:i2 表示第一个序列中受影响的范围,而 j1:j2 表示第二个序列中受影响的范围。
通过使用 SequenceMatcher,你可以非常灵活和高效地进行序列比较和差异分析。它是文本处理、数据清洗等场景中非常实用的工具。
Differ类
Differ类可以用来生成两个序列之间的差异报告,由于本程序只需要查询两篇论文的相似度,并不需要具体的分析,所以此处不展开。
用户输入的异常处理
在本次开发中,出现错误的主要原因是用户在输入可执行程序时,出现参数不正确,论文的格式不正确,或者路径不正确。这些异常都需要在程序中进行处理,以提高程序的完整性和可靠性。
异常处理要用到sys库和os库,主要代码如下:
import sys
import os
#文件格式和文件路径的异常处理
def check_file(file_path, expected_extension):
# 检查文件格式
if not file_path.endswith(expected_extension):
print(f"错误:文件 '{file_path}' 不是期望的文件格式 '{expected_extension}'。")
return False
# 检查文件是否存在
if not os.path.exists(file_path):
print(f"错误:文件路径不存在 '{file_path}'。")
return False
return True
# 获取命令行参数
arguments = sys.argv
# 检查参数数量是否正确
if len(arguments) != 4:
print("Usage: python main.py [原文文件] [抄袭版论文的文件] [答案文件]")
sys.exit(1)
# 检查文件
if not(check_file(arguments[1], '.txt') and
check_file(arguments[2], '.txt') and
check_file(arguments[3], '.txt')):
sys.exit(2)
以下是对异常处理的结果:


使用cprofile进行性能分析


由上面两图的对比可以看出,在程序的执行中,异常处理的函数调用是占最多的,尤其是对文件路径是否存在的处理,要大量调用'get' of 'str' objects方法,所以如果想让程序执行得更快,可以将异常处理进行简化,下图是简化后的结果(将文件路径是否存在部分的异常处理去掉):
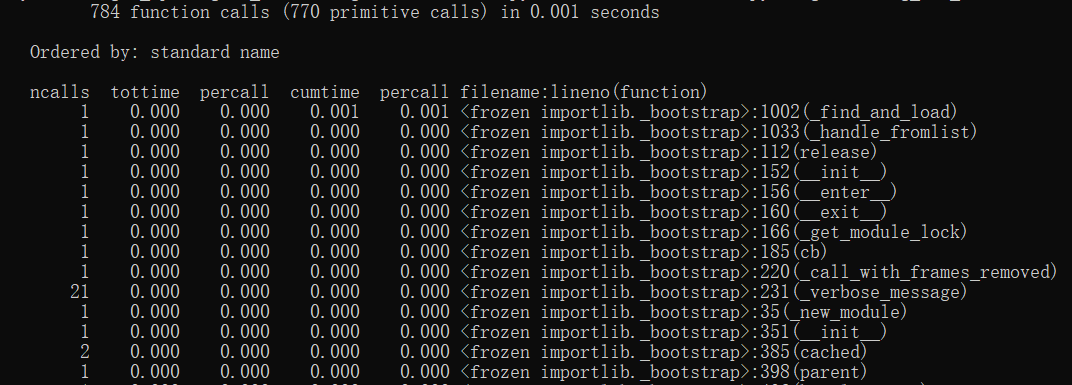
我们可以看出,程序的函数调用次数打打减少了,而且执行时间也从0.397s下降到0.001s。所以最终还是要看功能和性能之间的取舍的。
单元测试
代码如下:(由于异常单元部分在上面已经测试完毕,所以只测试 calculate_similarity单元)
由上可知测试结果无异常


 浙公网安备 33010602011771号
浙公网安备 33010602011771号