
[fastgrind] 一个轻量级C++内存监控及可视化开源库
![[fastgrind] 一个轻量级C++内存监控及可视化开源库](https://img2024.cnblogs.com/blog/3713923/202510/3713923-20251017141247868-1149680955.png) fastgrind 是一个仅单一头文件、轻量级、快速、线程安全、类似 Valgrind 的内存分析器,旨在跟踪 C++ 应用程序中的运行时内存分配并分析调用堆栈。fastgrind 通过自动和手动插桩两种检测方法提供全面的内存使用情况分析。
fastgrind 是一个仅单一头文件、轻量级、快速、线程安全、类似 Valgrind 的内存分析器,旨在跟踪 C++ 应用程序中的运行时内存分配并分析调用堆栈。fastgrind 通过自动和手动插桩两种检测方法提供全面的内存使用情况分析。
Fastgrind
GitHub: https://github.com/adny-code/fastgrind
引言
在高性能计算场景下,常使用perf工具进行函数级别的时间分析、使用valgrind工具进行内存泄漏和内存分配异常检测。
valgrind功能非常强大,能追踪每一段内存申请和释放的栈帧。但是valgrind使用相对复杂,最重要的是valgrind效率极其低下,通常为原始程序运行时间长的10倍以上。对于多线程程序,valgrind无法跑满线程,性能退化能到几十甚至上百倍。
大部分场景下,即使精简case后,valgrind依然难以快速定位内存异常问题。
对于上述问题,fastgrind开源库提供一个轻量级的、函数级别监控、可视化的、高效C++内存监控方案。在64核服务器上测试,64个线程能完全跑满。简单case (调用栈深度10以内),性能几乎无退化;复杂case (调用栈深度30+),性能退化4倍以内。
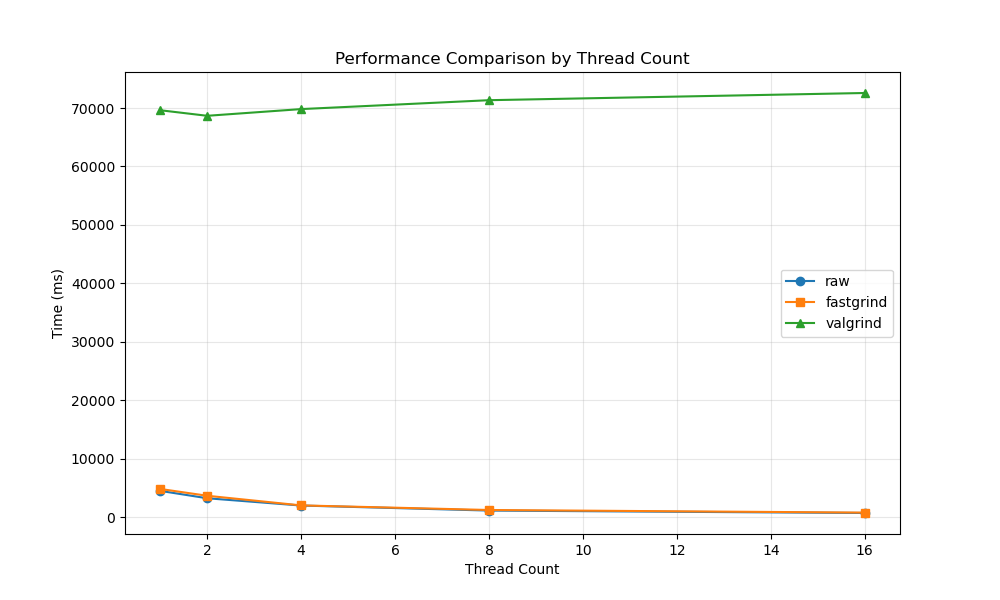
fastgrind仓库的testcase中,提供了一个包含bin query、分组算法的box grouping测例,调整线程数量,测试得到的benchmark如上图所示。
简介
fastgrind 是一个仅单一头文件、轻量级、快速、线程安全、类似 Valgrind 的内存分析器,旨在跟踪 C++ 应用程序中的运行时内存分配并分析调用堆栈。Fastgrind 通过自动和手动插桩两种检测方法提供全面的内存使用情况分析。
fastgrind 兼容C++11以上版本,集成到工程中不影响原始仓库中其它第三方内存管理库或glibc内存管理的正常运行。
仓库结构
fastgrind/
├── include/fastgrind.h # 核心代码 (head only)
|
├── demo/
│ ├── manual_instrument/ # 手动插桩 demos
│ ├── auto_instrument/ # 自动插桩 demos
| └── build_all_demo.sh # 编译所有demo的脚本
|
├── testcase/
│ ├── benchmark_box_grouping/ # 性能测试
│ ├── cpp_feature_test/ # 现代C++特性测试
│ ├── glibc_je_tc_availabe/ # 分配器兼容性测试
│ ├── multi_pkg_compile/ # 多lib编译测试
| ├── thirdparty_leveldb_test/ # 第三方开源库测试 (https://github.com/google/leveldb)
| └── thirdparty_zlib_test # 第三方开源库测试 (https://zlib.net)
|
├── doc/
| ├── compile.md # 集成和编译选项说明
| ├── demo.md # demo说明
| ├── feature_list.md # fastgrind特性说明
| ├── querstion_list.md # fastgrind使用过程中出现的问题及解决方案说明
| └── testcase.md # testcase说明
|
├── tools/fastgrind.py # 可视化工具 (使用方法:python fastgrind.py fastgrind.json)
|
├── CMakeList.txt # testcase的顶层Cmake
├── Doxyfile # Doxyfile生成手册
└── README.md # 存库描述
快速开始
编译 testcase
mkdir build && cd build
cmake ..
make -j$(nproc)
运行 testcase
cd build/testcase/benchmark_box_grouping
./benchmark_raw
./benchmark_fastgrind
./run_valgrind.sh
cd build/testcase/cpp_feature_test
./cpp_feature_test
...
cd build/testcase/multi_pkg_compile
./multi_pkg_main
调用堆栈 Report
程序退出时会生成两个报告文件
[FASTGRIND] Start summary memory info
[FASTGRIND] saved: fastgrind.text (size=2335 bytes)
[FASTGRIND] saved: fastgrind.json (size=65952 bytes)
更多细节请看本文段落: fastgrind 输出与分析
如何在你的项目中使用
手动和自动插桩都需要额外的编译标志
有关详细编译和链接选项,请看本文段落: fastgrind 编译选项
手动插桩的使用方法
通过显示的插入__FASTGRIND__::FAST_GRIND宏,选择要监控的函数。
#include "fastgrind.h"
using namespace __FASTGRIND__;
void processData() {
FAST_GRIND; // 启用此函数的调用堆栈跟踪
int* data = new int[1000];
// ... process data ...
delete[] data;
}
int main() {
FAST_GRIND; // 启用此函数的调用堆栈跟踪
processData();
return 0;
}
自动插桩的使用方法
在任何一个.cpp中包含 fastgrind.h,并通过编译选项,使得目标外的所有函数都会自动监控。
fastgrind 输出与分析
当集成 fastgrind 的应用程序退出时,会自动生成两个文件:fastgrind.text和fastgrind.json
fastgrind.text
fastgrind.text 是类似于 Linux 下 perf report 格式的输出。有函数级别的调用栈内存申请/释放统计,在vscode等editor下可以进行子调用栈折叠。
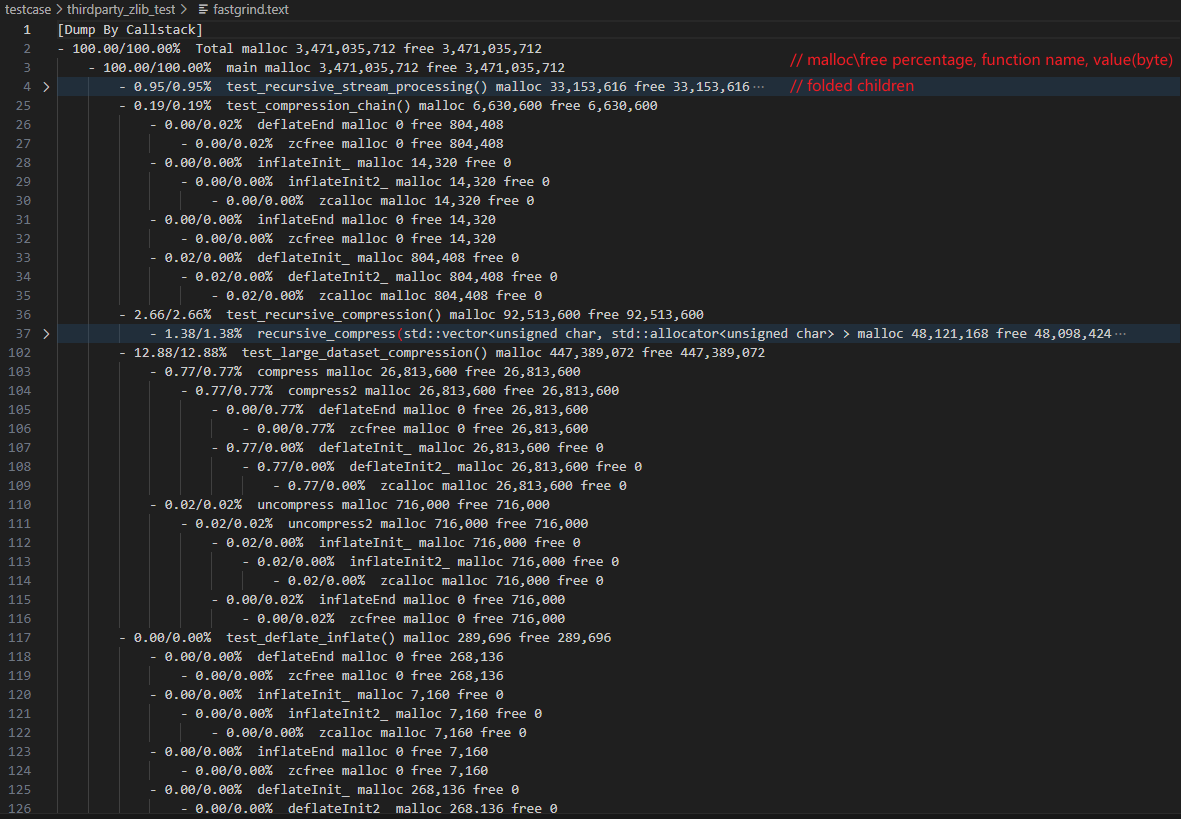
fastgrind.json
fastgrind.json 文件中包含:
- 时间片内存使用统计
- 每线程内存分配详细信息
- 完整的调用堆栈信息
- 函数级分配明细
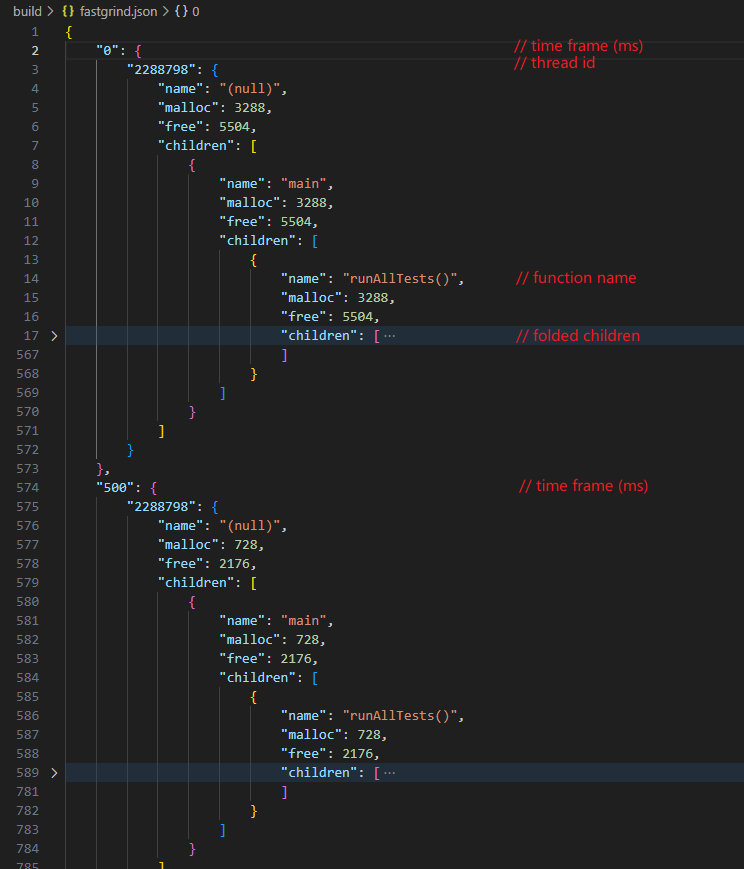
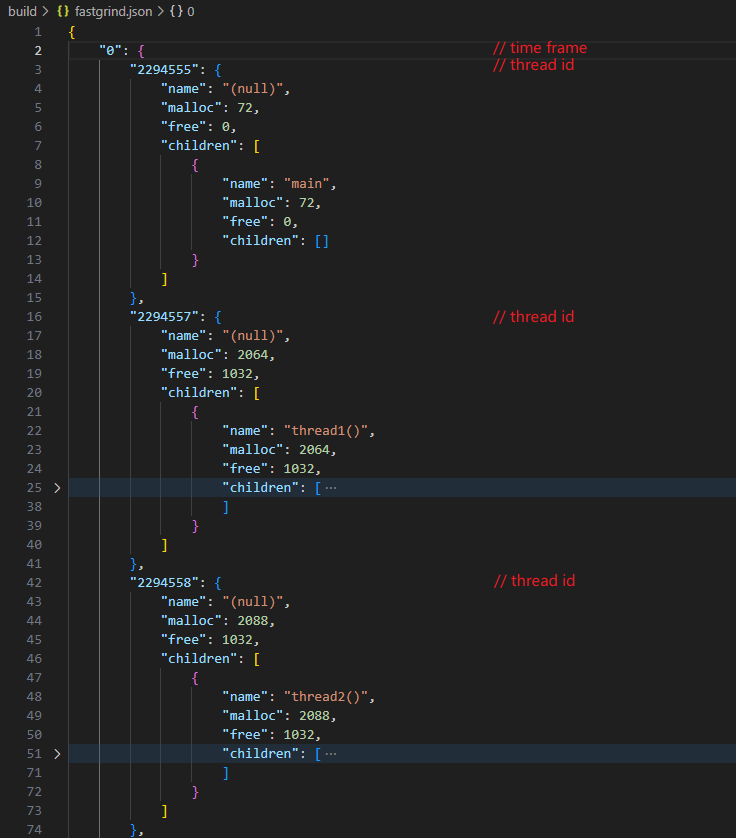
每时间片、每线程、每函数记录器:
-
单线程记录如下
![单线程]()
-
多线程记录如下
![多线程]()
可视化
使用tools/fastgrind.py生成交互式可视化折线图
它将调用 matplotlib 绘制折线图,并生成 fastgrind.html以防用户环境中没有 matplotlib,使用浏览器打开fastgrind.html可以得到与matplotlib相同的折线图
用法
python fastgrind.py fastgrind.json
or
python fastgrind.py # 自动搜索当前文件夹中的 fastgrind.json
以第三方开源库 leveldb 为例,监控其内存分配:
-
matplot结果
![leveldb_plot]()
-
html结果
![leveldb_html]()


fastgrind 编译选项
手动插桩的编译选项
描述: 手动检测要求开发人员在源代码中显式添加__FASTGRIND__::FAST_GRIND到需要监控的函数,但只需要更简单的编译配置
编译选项:
g++ -O3 -Wall -Wextra -std=c++11 \
-I/path/to/fastgrind/include \
source_files...
# -DFASTGRIND_JE_MALLOC (如果原工程中使用jemalloc的话需要定义该选项)
# -DFASTGRIND_TC_MALLOC (如果原工程中使用tcmalloc的话需要定义该选项)
链接选项:
-
Wrap flags: 内存分配器的符号包装(下面列出了所有支持的)
WRAP_FLAGS=( # C standard library memory allocation functions -Wl,--wrap=malloc # Standard memory allocation -Wl,--wrap=calloc # Zero-initialized memory allocation -Wl,--wrap=realloc # Memory reallocation -Wl,--wrap=free # Memory deallocation # C++ standard operator new/delete (basic versions) -Wl,--wrap=_Znwm # operator new(size_t) -Wl,--wrap=_Znam # operator new[](size_t) -Wl,--wrap=_ZdlPv # operator delete(void*) -Wl,--wrap=_ZdaPv # operator delete[](void*) # C++ nothrow operator new/delete -Wl,--wrap=_ZnwmRKSt9nothrow_t # operator new(size_t, nothrow) -Wl,--wrap=_ZnamRKSt9nothrow_t # operator new[](size_t, nothrow) -Wl,--wrap=_ZdlPvRKSt9nothrow_t # operator delete(void*, nothrow) -Wl,--wrap=_ZdaPvRKSt9nothrow_t # operator delete[](void*, nothrow) # POSIX and Linux-specific memory allocation functions -Wl,--wrap=valloc # Page-aligned memory allocation -Wl,--wrap=pvalloc # Page-aligned allocation (multiple of page size) -Wl,--wrap=memalign # Aligned memory allocation -Wl,--wrap=posix_memalign # POSIX aligned memory allocation -Wl,--wrap=reallocarray # Array reallocation with overflow check -Wl,--wrap=aligned_alloc # C11 aligned allocation # C++ sized delete operators (C++14) -Wl,--wrap=_ZdaPvm # operator delete[](void*, size_t) -Wl,--wrap=_ZdlPvm # operator delete(void*, size_t) # C++ aligned allocation operators (C++17) -Wl,--wrap=_ZnwmSt11align_val_t # operator new(size_t, align_val_t) -Wl,--wrap=_ZnamSt11align_val_t # operator new[](size_t, align_val_t) -Wl,--wrap=_ZdlPvSt11align_val_t # operator delete(void*, align_val_t) -Wl,--wrap=_ZdaPvSt11align_val_t # operator delete[](void*, align_val_t) # C++ sized aligned delete operators (C++17) -Wl,--wrap=_ZdlPvmSt11align_val_t # operator delete(void*, size_t, align_val_t) -Wl,--wrap=_ZdaPvmSt11align_val_t # operator delete[](void*, size_t, align_val_t) # C++ nothrow sized delete operators -Wl,--wrap=_ZdlPvmRKSt9nothrow_t # operator delete(void*, size_t, nothrow) -Wl,--wrap=_ZdaPvmRKSt9nothrow_t # operator delete[](void*, size_t, nothrow) # C++ nothrow aligned allocation operators (C++17) -Wl,--wrap=_ZnwmSt11align_val_tRKSt9nothrow_t # operator new(size_t, align_val_t, nothrow) -Wl,--wrap=_ZnamSt11align_val_tRKSt9nothrow_t # operator new[](size_t, align_val_t, nothrow) -Wl,--wrap=_ZdlPvSt11align_val_tRKSt9nothrow_t # operator delete(void*, align_val_t, nothrow) -Wl,--wrap=_ZdaPvSt11align_val_tRKSt9nothrow_t # operator delete[](void*, align_val_t, nothrow) # C++ nothrow sized aligned delete operators -Wl,--wrap=_ZdlPvmSt11align_val_tRKSt9nothrow_t # operator delete(void*, size_t, align_val_t, nothrow) -Wl,--wrap=_ZdaPvmSt11align_val_tRKSt9nothrow_t # operator delete[](void*, size_t, align_val_t, nothrow) )
具体示例可看原仓库中demo/manual_instrument
自动插桩的编译选项
描述: 自动插桩能监控所有非排除函数,但需要更复杂的编译配置
编译选项:
# 不需要监控的库或pkg
EXCLUDE_FILE_LISTS=(
/usr/include/
/usr/lib/
/usr/local/
fastgrind.h
)
EXCLUDE_FILE_LISTS=$(IFS=,; echo "${EXCLUDE_FILE_LISTS[*]}")
# 函数插桩的编译选项
INSTRUMENT_FLAGS=(
-finstrument-functions
-finstrument-functions-exclude-file-list=${EXCLUDE_FILE_LISTS}
)
# "${INSTRUMENT_FLAGS[@]}": 不要监控的库或pkg
# -DFASTGRIND_INSTRUMENT: 定义 FASTGRIND_INSTRUMENT 以启动自动插桩
# -Wl,--export-dynamic: 导出符号表,便于fastgrind抓取函数名
g++ -O3 -Wall -Wextra -std=c++11 \
"${INSTRUMENT_FLAGS[@]}" \
-DFASTGRIND_INSTRUMENT \
-Wl,--export-dynamic \
-I/path/to/fastgrind/include \
source_files...
# -DFASTGRIND_JE_MALLOC (如果原工程中使用jemalloc的话需要定义该选项)
# -DFASTGRIND_TC_MALLOC (如果原工程中使用tcmalloc的话需要定义该选项)
链接选项:
同 手动插桩 一致
具体示例可看原仓库中demo/auto_instrument
限制和注意事项
- 跨函数栈帧分配: 在一个函数中分配并在另一个函数中释放的内存将被如实记录,导致这些函数堆栈帧记录释放的数量少于或超过分配的数量,在另一些则相反.
- 模板复杂性支持: 复杂的模板元编程可能会在报告中显示通用名称
- 文件覆盖: 每次运行时输出文件都会覆盖以前的内容
- GUN依赖: 需要 GNU ld 来实现
--wrap功能
原作者
- Email: zfzmalloc@gmail.com
- GitHub: https://github.com/adny-code/fastgrind

 浙公网安备 33010602011771号
浙公网安备 33010602011771号