Python并行系统工具_线程派生_thread
线程是同一时间内启动其他操作的另一种方法,和程序的其他部分并行地调用函数(或其他可调用的对象类型)
又被称为"轻量级进程",像分支进程一样并行运行,但是所有的线程均在同一进程中运行
🐱🏍进程通常用来起始独立的程序,而线程经常用于非阻塞的输入调用和GUI中长时间运行的任务
线程还可以作为表达式成为独立运行任务的算法的模型
-
-
不会因为要复制进程本身而产生很大的启动消耗
-
线程在性能开销方面更加理想
-
-
简单易用
-
线程比程序简单的多
-
-
共享全局内存
-
重点🐱👤 每个线程共享的进程的全局内存空间是一样的
-
线程通信:获取和设置所有线程都可以访问的名称和对象
-
如果一个线程给一个全局作用域变量赋值,则该变量的值将为所有的线程所知晓
-
-
可移植性
-
线程比分支进程具有更好的跨平台移植性
-
Python线程工具自动适应平台特有的线程方面的差异,并且
-
-
线程并非启动新的程序
-
线程是用来与程序其他部分并行调用函数的
-
线程运行程序内的函数
-
-
线程的同步化和队列
-
线程共享全局内存空间
-
提供了线程间的通信机制
-
必须对多种操作的同步化小心处理
-
如创建的打印输出的冲突,应为进程只有一个
sys.stdin,所有的线程都在共享
-
-
queue模块可以简化线程的同步化
-
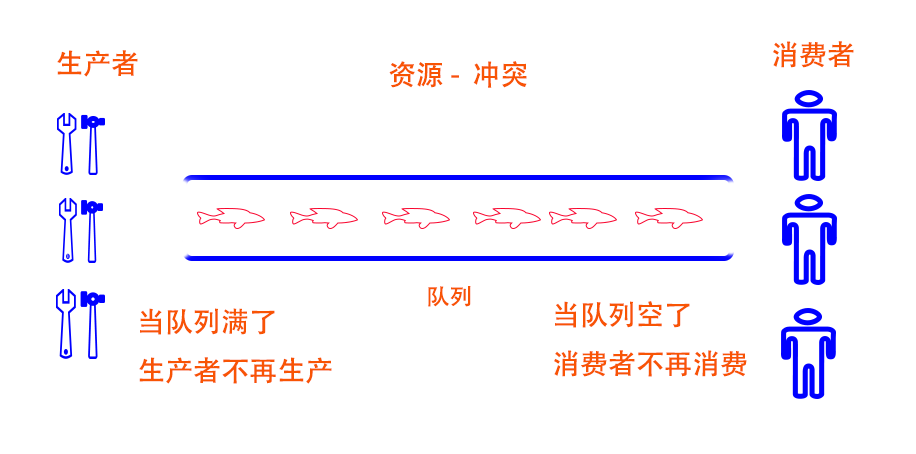
生产者消费者模型
-
一个或多个生产者线程,将数据添加到队列中
-
一个多多个消费者线程,将数据从队列中取出进行处理
-
![]()
- 全局解释器锁GIL
-
-
Python线程是真正的操作系统线程,但是在准备好之后必须获得一把共享锁之后,才能运行
-
每个线程都是,并且每个线程都可能在短时运行后调换到无锁状态
-
Python线程的Python语言部分目前还不能在多核计算机的多个CPU间分配
-
-
Python不能实现真正地在时间上重叠运行
- ★
-
为了确保每个线程都得到运行的机会,解释器在线程间每隔固定的间隔期,以及长时间运行操作开始时(接受文件的输入/输出请求),自动切换焦点
-
切换间隔设置的足够高,允许每个线程结束后还没有切换出去,也许不用锁即可处理某些并发更新问题
-
间隔设置高,表示切换频率降低,开销降低,但是对事件的应答能力下降,反之亦然
-
-
Python的GIL多路技术使得Python线程在利用多核机器方面可用性降低,但是
-
-
依赖这些规则有些冒险,需要对Python内部运作有深入的理解,且每个发行版都不一样
-
相比记住在多线程之间,那类访问安全,哪类不安全,利用锁来控制全局和共享对象的所有访问相对安全
-
-
带有线程的程序中,C扩展必须围绕着长时间运行操作释放并重新获取GIL,以便其他python线程的Python语言部分在这个等待期间得以运行
-
长时间运行的C扩展函数应该在其开始时释放锁,而在退出且继续运行Python代码时重新获取锁
-
Python线程中的Python代码由于GIL同步化无法真正实现时间上的重叠,但是C语言部分可以👌
-
只要在Python虚拟机作用域外运行,可以并行运行任意数据的线程
-
事实上,
在进程中开始执行新的独立线程,Python使用底层的_thread模块在派生出的线程中运行函数调用
也可以在较高层的threading
_thread.start_new_thread(func, (args))
-
-
函数调用与程序其他部分并行运行
-
-
接受一个函数对象(或者其他可调用对象)和一个参数元组
-
返回一个没有用途的int类型对象(和
threading不同❌) -
如果线程中函数抛出异常且未被捕获的异常,则将打印出堆栈跟踪记录并退出线程,但程序的其他部分依然运行
-
大多数平台上。整个程序在主线程退出时随之退出
-


import _thread def action(i): print(i ** 32) class Power: def __init__(self, i): self.i = i def action(self): print(self.i ** 32) # 传入函数和参数 _thread.start_new_thread(action, (2,)) # 传入匿名函数 _thread.start_new_thread((lambda: action(2)), ()) # 传入绑定方法的类 _thread.start_new_thread(Power(2).action, ()) import time time.sleep(10) # 主程序休眠,线程有足够的时间运行,否则线程一开始就退出了
-
线程中运行的绑定方法引用那个在进程中的原始的实例对象,而非它的副本
-
在线程中对实例对象的状态做出任何改变,对于所有其他线程都是可见的
-
通常使用
time.sleep,使得主线程和它启动的线程的延续时间一样长 -
并发的函数调用在一个进行中运行,共享同一个标准输出流,所有的输出都合并起来并随机混杂
同步访问共享对象和名称
-
-
可以成为进程间通信的简单方法,如退出标识,结果对象,事件指示器等
-
★ 避免多个线程同时改变全局对象和名称
-
带有线程的程序必须控制对全局对象的访问权,保证同一时间内只有一个线程在使用它们
-
-
基于🔒锁的概念
-
想要修改一个共享对象,线程需要获取一把锁
-
修改之后,释放这把锁,再未其他线程获取
-
-
Python确保任何时间点只有一个线程持有这把锁,如果在持有期间其他线程请求获取锁,这些请求将一直被阻塞,直到释放出锁
-
对于共享对象的访问权而言,锁严格来讲并不是必须的
-
如果某个线程对其他检查的对象做更新时
-
首要原则:一般只要同时更新有可能发生,应当使用锁来同步化线程
Lock对象🔒
-
-
状态:
locked和Unlocked -
方法
-
获取锁:
acquire() -
释放锁:
release() -
检查状态:
locked()
-
-
锁的上下文管理器
-
with语句
-
确保一段嵌套代码块周围执行线程操作,实现锁的自动释放获取
-
""" 同步化对stuout的访问 stdout 共享的全局对象 线程输出如果不做同步化,可能会交互在一起 利用线程锁,实现打印的同步化 """ import _thread as thread import time def counter(myId, count): for i in range(count): time.sleep(1) # 使用标准输出,获取锁 mutex.acquire() print(f"[{myId}] ==== > [{i}]") # 释放锁 mutex.release() # 创建全局锁🔒对象 mutex = thread.allocate_lock() for i in range(5): thread.start_new_thread(counter, (i, 5)) time.sleep(6) print("Main thread exiting...")
""" 使用mutexes在父/主线程中探知线程何时结束 """ import _thread as thread from collections import Counter stdoutmutex = thread.allocate_lock() # 生产10个锁,分别分配个每个线程,记录线程的退出状态 # 为每个线程创建一把锁并加入全局对象中,主线程和线程都可以共享 exitmutex = [thread.allocate_lock() for i in range(10)] def counter(myId, count): for i in range(count): # 使用标准输出,获取锁 stdoutmutex.acquire() print(f"[{myId}] ==== > [{i}]") # 释放锁 stdoutmutex.release() # 线程退出的时候,添加一个锁,并且获取锁 exitmutex[myId].acquire() # 向主线程发送信号 # print(exitmutex[myId]) for i in range(10): thread.start_new_thread(counter, (i, 100)) # 判断所有的退出锁的状态。当所有锁已经释放,即所有线程已经运行结束,主线程就结束 # 会不断的循环,知道所有的锁对象全部释放 # 主线程一直是繁忙的,可以加入sleep调用,主线程站厅以释放CPU处理其他任务 time.sleep(0.2) exitlist = [] for mutex in exitmutex: # print(mutex) while not mutex.locked(): # print(".....", mutex) exitlist.append(mutex) pass exitCount = Counter(exitlist) for key, value in exitCount.items(): print(key, value) """ 会一直探测 <locked _thread.lock object at 0x000001ECD46A05A8> 6640906 <locked _thread.lock object at 0x000001ECD47D9B48> 5530120 <locked _thread.lock object at 0x000001ECD49245A8> 610853 """ print("Main thread exiting...")
""" 传入所有线程共享的mutex而非所有的全局对象 上下文管理器一起使用,实现锁的自动释放/获取 添加休眠功能的调用可以避免繁忙的循环并模拟真是工作 """ import _thread as thread import time stdout_mutex = thread.allocate_lock() num_threads = 5 exit_mutex = [thread.allocate_lock() for i in range(num_threads)] def counter(myId, count, mutex): for i in range(count): with mutex: print(f"[{myId}] === > [{i}]") exit_mutex[myId].acquire() for i in range(num_threads): thread.start_new_thread(counter, (i, 5, stdout_mutex)) while not all(mutex.locked() for mutex in exit_mutex): time.sleep(0.25) print("Main thread exitimng ...")
-
继承threading.Thread -
定义类的状态信息(属性)
-
锁的创建threading.Lock()
""" 带有状态和run()行为的线程类实例 """ import threading class MyThread(threading.Thread): def __init__(self, myId, count, mutex): self.myId = myId self.count = count self.mutex = mutex threading.Thread.__init__(self) def run(self): for i in range(self.count): with self.mutex: print(f"[{self.myId}] =====> [{i}]") stdout_mutex = threading.Lock() threads = [] for i in range(10): thread = MyThread(i, 100, stdout_mutex) print(thread) # <MyThread(Thread-1, initial)> thread.start() print(thread) # <MyThread(Thread-1, started 8076)> 和_thread开始线程类似 threads.append(thread) # for thread in threads: # thread.join() print("Mian thread exiting ...")
如果run方法没有重新定义
-
默认的
run方法直接调用传递给其构造器的target参数的调用对象,其参数为任意传给arg参数 -
可以保证用
Thread运行简单的函数,虽然并不比_thread模块简单
""" 带有状态的子类 """ import threading import _thread class MyThread(threading.Thread): def __init__(self, i): self.i = i threading.Thread.__init__(self) def run(self): print(self.i ** 32) MyThread(2).start() def action(x): print(x ** 32) # 传入行为, run调用target thread = threading.Thread(target=(lambda : action(2))) thread.start() # 没有使用lambda函数将状态封存起来,调用对象即参数 thread = threading.Thread(target=action, args=(2,)) thread.start() # 基本线程模块 thread = _thread.start_new_thread(action, (2,))
-
-
threading使用函数时或者对象的方法时,如果没有参数,不需要传入空元组,_thread
""" 带有状态的非线程类,OOP方式 """ import threading class Power: def __init__(self, i): self.i = i def action(self): print(self.i ** 32) obj = Power(2) thread = threading.Thread(target=obj.action).start() # 利用嵌套作用域保存状态 def action(i): def power(): print(i ** 32) return power # 线程运行返回的函数 thread = threading.Thread(target=action(2)).start() # 基本的线程模块实现 import _thread _thread.start_new_thread(obj.action, ()) _thread.start_new_thread(action(2), ())
-
-
参数是:时间,默认表示线程结束,设置时间表示: 线程执行多长时间,主线程就阻塞多长时间
-
threading保证主线程在所有非守护线程退出后才退出 -
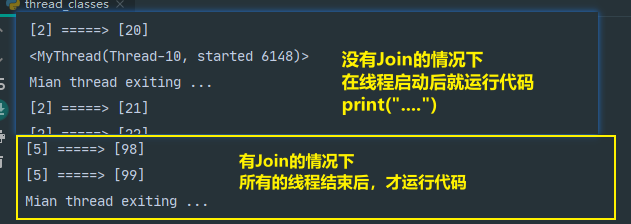
-
-
线程对象返回一个随机的整数
-
-
threading创建的线程并不会立即开始,而是通过start()方法启动的
-
创建的线程对象:
<MyThread(Thread-1, initial)> -
启动之后的线程对象:
-
-
-
从队列中取出数据
-
-
-
队列对象自动由线程锁🔒获取和释放操作控制,任意时间点只能有一个线程能够修改队列(存入和获取)
-
使用队列进行线程间的通信的程序是线程安全的
-
""" 生产者和消费者共享队列进行通信 """ num_consumers = 2 # 消费者线程的数量 num_producers = 4 # 生产者线程的数量 num_messages = 4 # 每个生产者传入的消息的数量 import _thread as thread import queue import time safeprint = thread.allocate_lock() # 打印操作的锁,防止方法重叠 data_queue = queue.Queue() # 共享的全局对象,大小无限 def producer(idnum): for msgnum in range(num_messages): time.sleep(idnum) data_queue.put(f'[producer id={idnum}, count={msgnum}]') def consumer(idnum): while True: time.sleep(0.1) try: data = data_queue.get(block=False) except queue.Empty: pass else: with safeprint: print('consumer', idnum, 'got =>', data) if __name__ == '__main__': for i in range(num_consumers): thread.start_new_thread(consumer, (i,)) for i in range(num_producers): thread.start_new_thread(producer, (i,)) # 从0开始的,不需要等待时间 1*4+2*4+3*4 + 消费者 time.sleep(((num_producers - 1) * num_messages) + 1) print("Main thread Exit")
""" 生产者和消费者共享队列进行通信 """ num_consumers = 2 # 消费者线程的数量 num_producers = 4 # 生产者线程的数量 num_messages = 4 # 每个生产者传入的消息的数量 import _thread as thread import queue import threading import time safeprint = thread.allocate_lock() # 打印操作的锁,防止方法重叠 data_queue = queue.Queue() # 共享的全局对象,大小无限 def producer(idnum): for msgnum in range(num_messages): time.sleep(idnum) data_queue.put(f'[producer id={idnum}, count={msgnum}]') def consumer(idnum): while True: time.sleep(0.1) try: data = data_queue.get(block=False) except queue.Empty: pass else: with safeprint: print('consumer', idnum, 'got =>', data) if __name__ == '__main__': for i in range(num_consumers): thread = threading.Thread(target=consumer, args=(i, )) thread.daemon = True # 设置为守护线程,不阻塞进行退出 thread.start() for i in range(num_producers): thread = threading.Thread(target=producer, args=(i, )) thread.start() # time.sleep(((num_producers - 1) * num_messages) + 1) print("Main thread Exit")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号