



python--循环和字符串
Task 5和6 循环和字符串
for循环和循环范围
for循环的特点
基于特定的范围,重复执行规定次数的操作
def f(m,n):
total = 0
for i in range(m,n+1):
total += i
return total
f(5,10)
计算机会计算5+6+7+8+9+10最后输出计算结果
range()函数
需要注意的是这个范围是一个左闭右开的情况
range()可以有三个参数的,第一个参数为起始值,第二个参数是终止值,一定要注意是左闭右开的,其次的话,第三个参数表示的是步长
以上边那个函数为例的话
def f(m,n):
total = 0
for i in range(m,n+1,7):
total += i
return total
f(5,20)
这个程序的运算就会变成5+12+19,因为步长为7,需要移动7位
而且,range()函数还可以实现逆序输出,只需要将大的数字写在range函数的第一个参数位置即可
for循环的嵌套
下面这个例子是输出一个二维坐标:
def f(Min,Max):
for i in range(1,Min):
for j in range(1,Max):
print(f"{x} , {y}",end=" ")
f(3,3)

利用这样的做法可以输出一个m*n的矩阵图
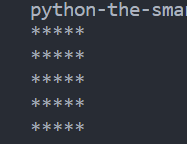
def f(m,n):
for i in range(m):
for j in range(n):
print("*",end="")
print( )
f(5,5)
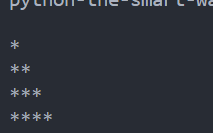
在这个的基础上我们还可以输出一个三角形的星图
def f(m,n):
for i in range(m):
for j in range(i):
print("*",end="")
print( )
f(5,5)
那么,在这些的基础上,我们还可以发散思维,思考输出杨辉三角形
我们还可以输出一个矩阵
在python语言中还可以有一些工具让我们去做类似于矩阵的操作
import numpy as np #矩阵的函数库
import matplotlib.pyplot as plt #绘图的函数库
%matplotlib inline
while循环
当你不知道循环要在什么时候停下来的时候,可以考虑用到while循环
# 我不知道它什么时候停下来
def leftmostDigit(n):
n = abs(n)
while n >= 10:
n = n//10
return n
leftmostDigit(45678)
输出的结果为4
def isMultipleOf4or7(x):
return ((x % 4) == 0) or ((x % 7) == 0)
def nthMultipleOf4or7(n):
found = 0
guess = -1
while found <= n:
guess += 1
if isMultipleOf4or7(guess):
found += 1
return guess
print("4 或 7 的倍数: ", end="")
for n in range(15):
print(nthMultipleOf4or7(n), end=" ")

如果是在知道循环范围的情况下的话,尽管程序能正常进行,也是一个不推荐的做法
break和countine语句·
break语句
如果想要提前结束循环,那么可以用到break语句
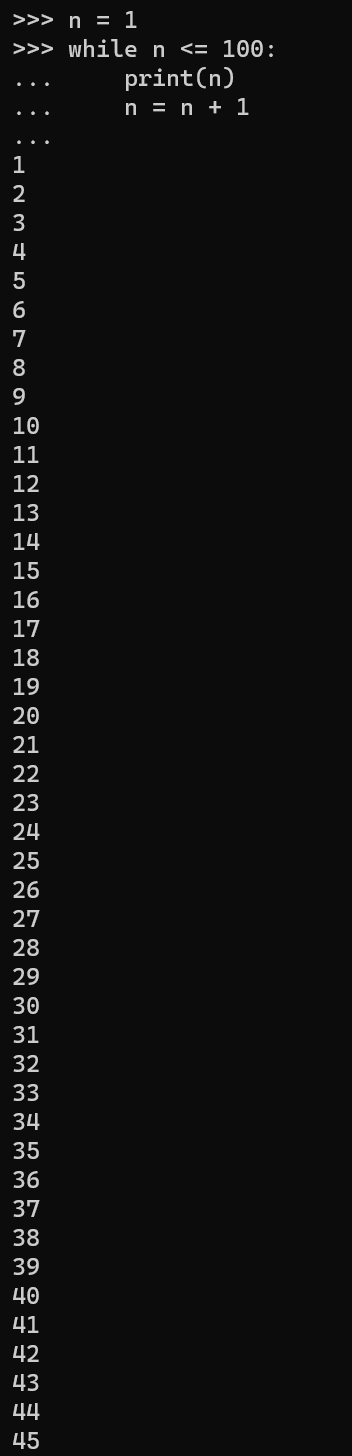
在循环中,break语句可以提前退出循环。例如,本来要循环打印1~100的数字:
n = 1
while n <= 100:
print(n)
n = n + 1
print('END')
上面的代码可以打印出1~100。
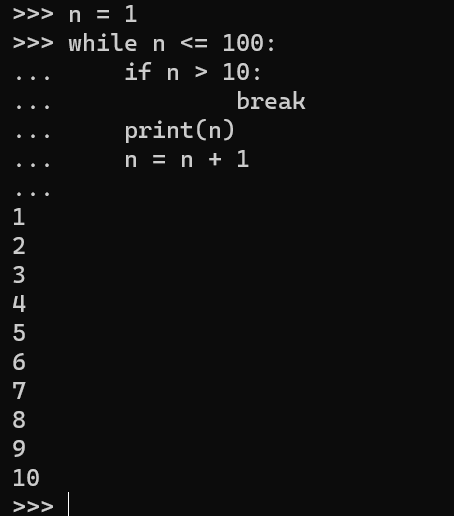
如果要提前结束循环,可以用break语句:
n = 1
while n <= 100:
if n > 10: # 当n = 11时,条件满足,执行break语句
break # break语句会结束当前循环
print(n)
n = n + 1
print('END')
执行上面的代码可以看到,打印出1~10后,紧接着打印END,程序结束。
可见break的作用是提前结束循环
示例如下:
continue函数
在循环过程中,也可以通过continue语句,跳过当前的这次循环,直接开始下一次循环。
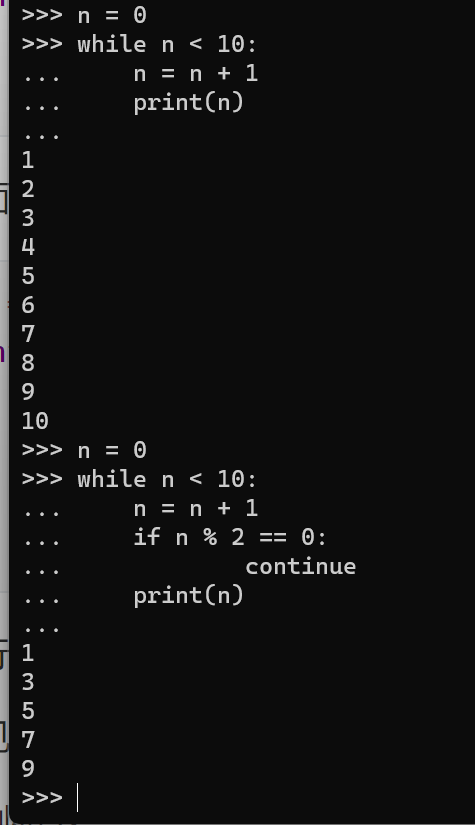
n = 0
while n < 10:
n = n + 1
print(n)
上面的程序可以打印出1~10。但是,如果我们想只打印奇数,可以用continue语句跳过某些循环:
n = 0
while n < 10:
n = n + 1
if n % 2 == 0: # 如果n是偶数,执行continue语句
continue # continue语句会直接继续下一轮循环,后续的print()语句不会执行
print(n)
执行上面的代码可以看到,打印的不再是1~10,而是1,3,5,7,9。
可见continue的作用是提前结束本轮循环,并直接开始下一轮循环
示例如下:
注意:
break语句可以在循环过程中直接退出循环,而continue语句可以提前结束本轮循环,并直接开始下一轮循环。这两个语句通常都必须配合if语句使用。
要特别注意,不要滥用break和continue语句。break和continue会造成代码执行逻辑分叉过多,容易出错。大多数循环并不需要用到break和continue语句,上面的两个例子,都可以通过改写循环条件或者修改循环逻辑,去掉break和continue语句。
有些时候,如果代码写得有问题,会让程序陷入“死循环”,也就是永远循环下去。这时可以用Ctrl+C退出程序,或者强制结束Python进程。
假·死循环
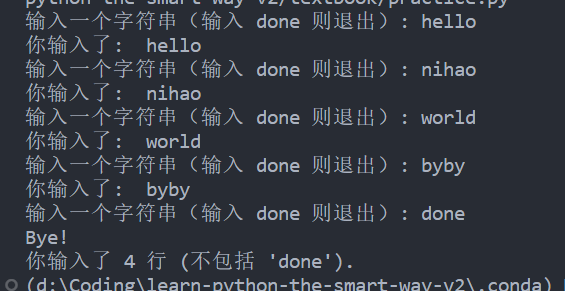
def readUntilDone():
linesEntered = 0
while True:
response = input("输入一个字符串(输入 done 则退出): ")
if response == "done":
break
print("你输入了: ", response)
linesEntered += 1
print("Bye!")
return linesEntered
linesEntered = readUntilDone()
print("你输入了", linesEntered, "行 (不包括 'done').")
判断质数isPrime
way 1:
从2开始遍历到它本身的前一位数,如果该数可以整除遍历的这些数的话,那么就不是质数
def isPrime(num):
if num < 2:
return False
for i in range(2,num):
if num % i == 0:
return False
return True
这种方法的一大缺点就是不能节省时间,会有超时现象存在
way 2:
排除掉一部分肯定不是素数的,在其他可能存在的的地方去找
我们知道所有的偶数都能被2整除,因此偶数一定不是素数
那么我们就可以缩小范围去搜索
# 快了一点
def fasterIsPrime(n):
if n < 2:
return False
if n == 2:
return True
if n % 2 == 0:
return False
maxFactor = round(n**0.5) #代表该数字的最大因子
for factor in range(3, maxFactor+1, 2):
if n % factor == 0:
return False
return True
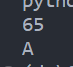
for n in range(100):
if fasterIsPrime(n):
print(n, end=" ")
字符串文字
四种不同的引号
单引号和双引号是常见的两种引号
print('单引号') #输出单引号
print("双引号") #输出双引号
三引号的情况不太常见,但是在某些场合下必须要用到
那么我们为什么需要俩种不同的引号呢
print("聪明办法学python'p2s'")
结果会把这个句子全部打印出来
但是如果不使用单数昂引号的话,就会出现报错的情况
print("聪明办法学pyton"p2s"")
这样的写法python编译器会将俩个较近的引号看作一起的,那么聪明办法学python会被当作一个字符串,而另外两个双引号之间没有内容,为空,那么p2s就识别不了了
字符中的换行符
前面有反斜杠\的字符叫做转义序列
比如说\n代表换行,尽管他俩看起来相似,但在python里边还是有所不同的
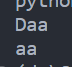
print("Data\nwhale")
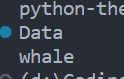
print("""Data
whale""")
print("""你可以在字符串后面使用 反斜杠 `\` 来排除后面的换行。\
比如这里是第二行文字,但是你会看到它会紧跟在上一行句号后面。\
这种做法在 CIL 里面经常使用(多个 Flag 并排保持美观),\
但是在编程中的应用比较少。\
""")
你可以在字符串后面使用反斜杠来排除后面的换行
print("""你可以在字符串后面使用 反斜杠 `\` 来排除后面的换行。
比如这里是第二行文字,但是你会看到它会紧跟在上一行句号后面。
这种做法在 CIL 里面经常使用(多个 Flag 并排保持美观),
但是在编程中的应用比较少。
""")

其他转义字符序列
print("双引号:\"")
print("反斜杠:\\")
print("换\n行")
print("这是\t制\t表\t符")
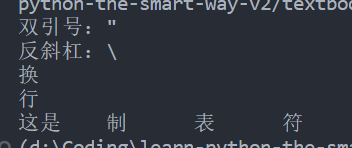
s = "D\\a\"t\ta"
print("s =", s)
print("\ns 的长度为:", len(s))
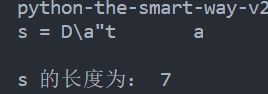
转义字符只作为一个字符存在
repr()VSprint()
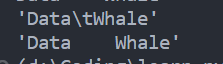
s1 = "Data\tWhale"
s2 = "Data Whale"
print(s1)
print(s2)

根据运行结果来看的话,s1与s2看起来是一样的,但是实际上是不一样的
要想进行区分,可以用到repr()函数来判断
print(repr(s1))
print(repr(s2))
一些字符串常量
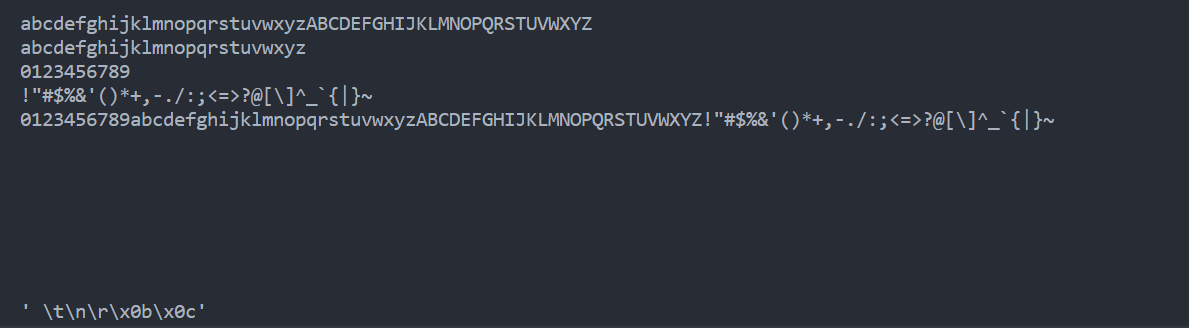
import string
print(string.ascii_letters)
print(string.ascii_lowercase)
print(string.digits)
print(string.punctuation)
print(string.printable)
print(string.whitespace)
print(repr(string.whitespace))
一些字符串的运算
字符串的加乘
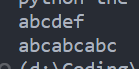
print("abc"+"def")
print("abc"*3)
但是不能使用字符串加数字去计算
in运算
print("ring" in "strings") # True
print("wow" in "amazing!") # False
print("Yes" in "yes!") # False
print("" in "No way!") # True
print("聪明" in "聪明办法学 Python") # True
字符串的索引和切片
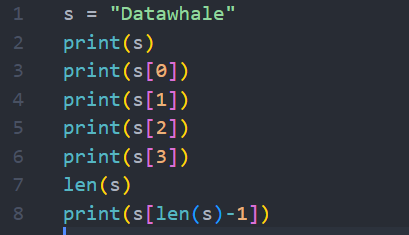
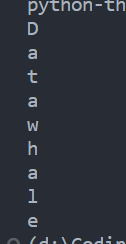
s = "Datawhale"
print(s)
print(s[0])
print(s[1])
print(s[2])
print(s[3])
len(s)
print(s[len(s)-1])
负数索引
print(s)
print(s[-5])
print(s[-4])
print(s[-3])
print(s[-2])
print(s[-1])
正数索引的话是从左往右去数的,负数索引的话是从右往左去索引的
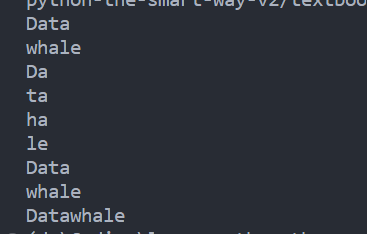
用切片来获取字符串
print(s[0:4])
print(s[4:9])
print(s[0:2])
print(s[2:4])
print(s[5:7])
print(s[7:9])
print(s[:4])
print(s[4:])
print(s[:])
注意的是该切片同range()函数一样,都是左闭右开的情况
切片的第三个参数表示的是步长(step)
print(s[:9:3])
print(s[1:4:2])
翻转字符串
print(s[::-1])
还可以使用join函数
print("".join(reversed(s)))
reversed函数的用法
最好的办法是使用一个函数将反转的过程封装起来
def reverseString(s):
return s[::-1]
print(reverseString(s))
字符串的循环
像C语言一样可以使用for循环
for i in range(0,10):
print(i,s[i])
也可以不用循环,使用in函数
for c in s:
print(c)
可以使用空格来循环字符串
# class_name.split() 本身会产生一个新的叫做“列表”的东西,但是它不存储任何内容
class_name = "learn python the smart way 2nd edition"
for word in class_name.split():
print(word)

# 跟上面一样,class_info.splitlines() 也会产生一个列表,但不存储任何内容
class_info = """\
聪明办法学 Python 第二版是 Datawhale 基于第一版教程的一次大幅更新。我们尝试在教程中融入更多计算机科学与人工智能相关的内容,制作“面向人工智能的 Python 专项教程”。
我们的课程简称为 P2S,有两个含义:
Learn Python The Smart Way V2,“聪明办法学 Python 第二版”的缩写。
Prepare To Be Smart, 我们希望同学们学习这个教程后能学习到聪明的办法,从容的迈入人工智能的后续学习。
"""
for line in class_info.splitlines():
if (line.startswith("Prepare To Be Smart")):
print(line)
与上边不同的是一个是循环的一个句子中的字符串,另一个是循环的是一段话中的某几个句子

<[Python startswith()方法 | 菜鸟教程 (runoob.com)]>(https://www.runoob.com/python/att-string-startswith.html)
一些字符串相关的内置函数
name = input("输入你的名字: ")
print("Hi, " + name + ", 你的名字有 " + str(len(name)) + " 个字!")
这里的str(len(name))进行强制类型转换的原因是字符串与数字是不能进行直接相加的,因此要对数字进行强制类型转换,转换成字符型,这样可以利用字符串相加,将这个句子连接起来

chr()和ord()函数
这两个函数时字符和ASCII的转换
print(ord("A")) #将字符转换成ASCII码
print(chr(65)) #将ASCII转换成字符
eval()函数
<[Python eval() 函数 | 菜鸟教程 (runoob.com)]>(https://www.runoob.com/python/python-func-eval.html)
直白一点来讲:这个函数就是来执行该函数()中的语句的内容
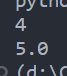
s = "2*2"
print(eval(s))
# 它可以正常运行,但是我们不推荐你使用这个方法
s = "(3**2 + 4**2)**0.5"
print(eval(s))
但是一般是不建议去使用这个函数的,因为如果()中的内容是对计算机有害的,那么会对计算机造成一些严重的后果
# 推荐使用 ast.literal_eval()
import ast
s_safe = "['p', 2, 's']"
s_safe_result = ast.literal_eval(s_safe)
print(s_safe_result)
print(type(s_safe_result))
<[Python中函数 eval 和 ast.literal_eval 的区别详解_literal_eval python-CSDN博客]>(https://blog.csdn.net/nanhuaibeian/article/details/102143356)
其实该函式就是为了降低对计算机的危险性
一些字符串的使用方法
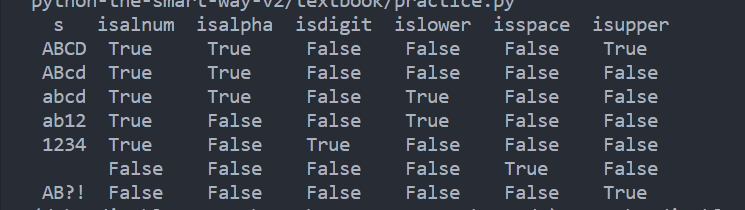
def p(test):
print("True " if test else "False ", end="")
def printRow(s):
print(" " + s + " ", end="")
p(s.isalnum())
p(s.isalpha())
p(s.isdigit())
p(s.islower())
p(s.isspace())
p(s.isupper())
print()
def printTable():
print(" s isalnum isalpha isdigit islower isspace isupper")
for s in "ABCD,ABcd,abcd,ab12,1234, ,AB?!".split(","):
printRow(s)
printTable()
print("YYDS YYSY XSWL DDDD".lower()) #将所有大写字母转换成小写的
print("fbi! open the door!!!".upper()) #将所有小写字母转换成大写的
print(" strip() 可以将字符串首尾的空格删除 ".strip())
#输出是删除首尾多余的空格
print("聪明办法学 Python".replace("Python", "C"))
print("Hugging LLM, Hugging Future".replace("LLM", "SD", 1)) # count = 1
第二个print()中的replace中的最后一个参数表示的是次数,意思是如果说有两个LLM的话,只代替第一个
print("This is a history test".count("is"))
print("This IS a history test".count("is"))
print("Dogs and cats!".startswith("Do"))
print("Dogs and cats!".startswith("Don't"))
print("Dogs and cats!".endswith("!"))
print("Dogs and cats!".endswith("rats!"))
<[python中find()的用法_python中find的用法-CSDN博客]>(https://blog.csdn.net/mtbaby/article/details/53101344)
print("Dogs and cats!".find("and"))
print("Dogs and cats!".find("or"))
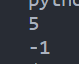
注意一下这个函数的返回值
<[Python的index函数用法_python .index-CSDN博客]>(https://blog.csdn.net/zhuan_long/article/details/109260995)
这个函数只能用于表,用于字符串的话是会报错的
格式化
在Python中,采用的格式化方式和C语言是一致的,用%实现,举例如下:
>>> 'Hello, %s' % 'world'
'Hello, world'
>>> 'Hi, %s, you have $%d.' % ('Michael', 1000000)
'Hi, Michael, you have $1000000.'
你可能猜到了,%运算符就是用来格式化字符串的。在字符串内部,%s表示用字符串替换,%d表示用整数替换,有几个%?占位符,后面就跟几个变量或者值,顺序要对应好。如果只有一个%?,括号可以省略。
常见的占位符有:
| 占位符 | 替换内容 |
|---|---|
| %d | 整数 |
| %f | 浮点数 |
| %s | 字符串 |
| %x | 十六进制整数 |
format()
另一种格式化字符串的方法是使用字符串的format()方法,它会用传入的参数依次替换字符串内的占位符{0}、{1}……,不过这种方式写起来比%要麻烦得多:
>>> 'Hello, {0}, 成绩提升了 {1:.1f}%'.format('小明', 17.125)
'Hello, 小明, 成绩提升了 17.1%'
{1: .lf}中1代表的是format中的,记住要加上:和 . 这两个符号,lf代表的是占位符
f-string
最后一种格式化字符串的方法是使用以f开头的字符串,称之为f-string,它和普通字符串不同之处在于,字符串如果包含{xxx},就会以对应的变量替换:
>>> r = 2.5
>>> s = 3.14 * r ** 2
>>> print(f'The area of a circle with radius {r} is {s:.2f}')
The area of a circle with radius 2.5 is 19.62
上述代码中,{r}被变量r的值替换,{s:.2f}被变量s的值替换,并且:后面的.2f指定了格式化参数(即保留两位小数),因此,{s:.2f}的替换结果是19.62
字符串是不可变的
s = "Datawhale"
s[3] = 'e'
这样的做法是会报错的
你必须创建一个新的字符串
s = s[:3] + "e" + s[4:]
print(s)
字符串和别名
字符串是不可变的,所以说字符串的别名也是不可变的
s = 'Data' # s 引用了字符串 “Data”
t = s # t 只是 “Data” 的一个只读别名
s += 'whale'
print(s)
print(t)
基础文件操作
要注意的是打开文件,用完之后一定要进行关闭
open 函数会返回一个 文件对象。在进行文件操作前,我们首先需要了解文件对象提供了哪些常用的方法:
-
close( ): 关闭文件 -
在 r 与 rb 模式下:
-
read(): 读取整个文件 -
readline(): 读取文件的一行 -
readlines(): 读取文件的所有行
-
-
在 w 与 a 模式下:
-
write(): -
writelines():
-
## 通过 read 方法读取整个文件
content = file.read()
print(content)
## 通过 readline() 读取文件的一行
content = file.readline()
print(content)
这个代码执行之后什么都没有输出
因为执行完第一次的代码之后,文件中的光标会移动到下一行,而下一行是没有内容的,自然而然是不会输出的
这个时候就需要先关闭打开的文件,再重新进行打开
## 以 w 模式打开文件chap6_demo.txt
file = open('chap6_demo.txt', 'w')
## 创建需要写入的字符串变量 在字符串中 \n 代表换行(也就是回车)
content = 'Data\nwhale\n'
## 写入到 chap6_demo.txt 文件中
file.write(content)
## 关闭文件对象
file.close()
w模式下会覆盖之前的内容,如果你想要追加内容的话,最好使用a来表示
如果说不想写close的话,那么可以用到另一个函数with()
with open("ZenOfPy.py", "w", encoding="utf-8") as file:
file.write(Caesar_cipher)
print(len(Caesar_cipher))
这个方法也是比较推荐的一种方法,这样就不用写close


 浙公网安备 33010602011771号
浙公网安备 33010602011771号