


第一次个人编程作业
第一次编程作业
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/Class34Grade23ComputerScience |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/Class34Grade23ComputerScience/homework/13477 |
| 这个作业的目标 | 实现一个3000字以上论文查重程序 |
| Github链接 | https://github.com/Shai-Zengziyao/3123004764 |
PSP表格
| PSP阶段 | 子阶段 | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 120 | 130 |
| Planning | 估计任务时间 | 120 | 130 |
| Development | 需求分析(含学习新技术) | 180 | 200 |
| Development | 生成设计文档 | 150 | 140 |
| Development | 设计复审(同伴评审) | 60 | 50 |
| Development | 制定/遵循代码规范 | 30 | 25 |
| Development | 具体设计(模块划分、算法设计) | 240 | 260 |
| Development | 具体编码 | 300 | 320 |
| Development | 代码复审(自审+工具检查) | 90 | 100 |
| Development | 测试(单元测试+集成测试+性能测试) | 240 | 280 |
| Reporting | 测试报告(覆盖率、性能分析) | 120 | 130 |
| Reporting | 计算工作量(代码行数、文档页数) | 60 | 50 |
| Reporting | 事后总结与过程改进计划 | 90 | 100 |
| 合计 | 1680 | 1805 |
算法摘要
本论文查重算法通过"文本预处理→TF-IDF向量化→余弦相似度计算"三步实现重复率计算:
- 文本预处理阶段:
- 清洗文本:去除非中文字符、标点符号等噪声
- 分词处理:使用jieba库进行中文分词,将连续文本分割为词语单元
- 停用词过滤:移除"的"、"了"、"在"等无意义高频词,保留核心特征词汇
- TF-IDF向量化阶段:
- 构建词频矩阵:统计词语在文档中的出现频率
- 计算逆文档频率:衡量词语在整个语料库中的重要程度
- 生成词向量:将文本转换为高维数值向量,其中每个维度代表一个词语的TF-IDF权重
- 余弦相似度计算阶段:
- 计算向量夹角余弦值:通过向量点积和模长计算相似度
- 结果标准化:相似度范围为0~1,值越接近1表示文本重复度越高
- 应用场景:轻度语序调整时相似度接近1,重度词汇替换时相似度显著降低
接口设计与实现
| 接口名称 | 核心功能 | 输入参数 | 输出 | 实现技术 | 异常处理 |
|---|---|---|---|---|---|
| parse_command_line_args | 解析命令行参数获取文件路径 | 无(依赖sys.argv) | (orig_path, copy_path, output_path) | 参数数量校验 | 参数数量错误时退出 |
| read_file | 读取文本文件(支持utf-8/gbk编码) | file_path: str | 文件内容字符串 | 编码自动切换,上下文管理器 | 文件不存在、编码错误、权限不足等 |
| preprocess_text | 文本清洗、分词、去停用词 | text: str | 空格分隔的核心词语字符串 | 正则清洗+jieba分词+停用词过滤 | 文本为空返回空字符串 |
| calculate_plagiarism_rate | TF-IDF向量化+余弦相似度计算重复率 | orig_text: str, copy_text: str | 重复率(保留两位小数) | TfidfVectorizer+cosine_similarity | 文本预处理为空时返回0.0 |
| main | 串联全流程(参数解析→读取→计算→写入) | 无(依赖命令行参数) | 结果写入文件,控制台状态提示 | 调用上述接口完成流程 | 写入失败时捕获异常并退出 |
使用方法
python main.py <原文文件> <抄袭版文件> <答案文件>
结果
| 测试集名 | 重复率 |
|---|---|
| orig_0.8_add.txt | 0.86 |
| orig_0.8_del.txt | 0.88 |
| orig_0.8_dis_1.txt | 0.97 |
| orig_0.8_dis_10.txt | 0.88 |
| orig_0.8_dis_15.txt | 0.71 |
计算的性能改进
性能分析
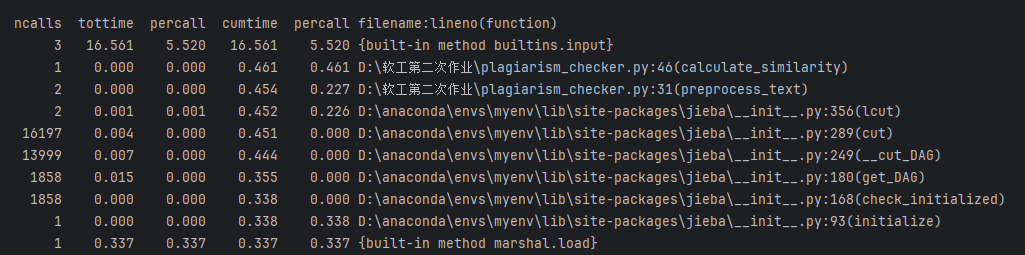
论文查重程序异常处理说明
数值逻辑异常
现象:计算结果超出合理范围(如负数或大于1)或与预期偏差过大
可能原因:
- 算法实现错误:余弦相似度公式计算错误(如向量模长为零时分母未处理)
- 文本预处理缺陷:停用词过滤过度导致有效特征丢失
- 原始文件异常:抄袭版与原文完全无关却显示高重复率
存储与展示异常
现象:Markdown表格无法渲染或文件写入失败
可能原因:
- 表格格式错误:分隔符缺失或表头与内容不对齐
- 文件权限问题:目标路径无写入权限
- 磁盘空间不足:存储设备空间耗尽
环境依赖异常
现象:跨平台路径解析失败或工具版本不兼容
可能原因:
- 路径格式差异:Windows反斜杠()与Linux正斜杠(/)冲突
- 依赖版本不兼容:jieba/TfidfVectorizer版本过低
其他潜在异常
-
文件读取异常
- 解决方案:自动探测编码格式,回退到GB18030
-
分词异常
-
解决方案:自定义词典补充专业术语
-
解决方案:分块处理大文件,限制向量维度
-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号