
Python爬虫及数据分析
------------恢复内容开始------------
python爬虫分类和robots协议
网络爬虫、网络机器人、网络蚂蚁
通用爬虫 URL
聚焦爬虫
Robots协议
robots.txt
User-agent:浏览器
Allow:许爬
Disallow:不许爬
Sitemap:网站站点地图
User-agent: *
Disallow: /
Disallow: /poi/detail.php
Sitemap: http://www.mafengwo.cn/sitemapIndex.xml
python爬虫urllib使用和进阶
urllib包
urllib.request 用于打开和读写url
urllib.error 包含了有urllib.request引起的异常
urllib.parse 用于解析url
urllib.robotparser 分析robots.txt 文件
urllib.request 模块
urlopen方法 urllib.request.urlopen(url,data=None,[timeout,]*,cafile=None,capath=None,cadefaule=False,context=None)
urlopen(url, data=None)
data=None,发起GET请求,否则POST
from urllib.request import urlopen response = urlopen('http://www.bing.com') print(response.closed) with response: print(1, type(response)) # http.client.HTTPResponse 类型文件对象 print(2, response.status, response.reason) # 状态 print(3, response.geturl()) # 返回真正的URL print(4, response.info()) # headers print(5, response.read()) # 读取返回的内容 print(response.closed)
User-Agent问题
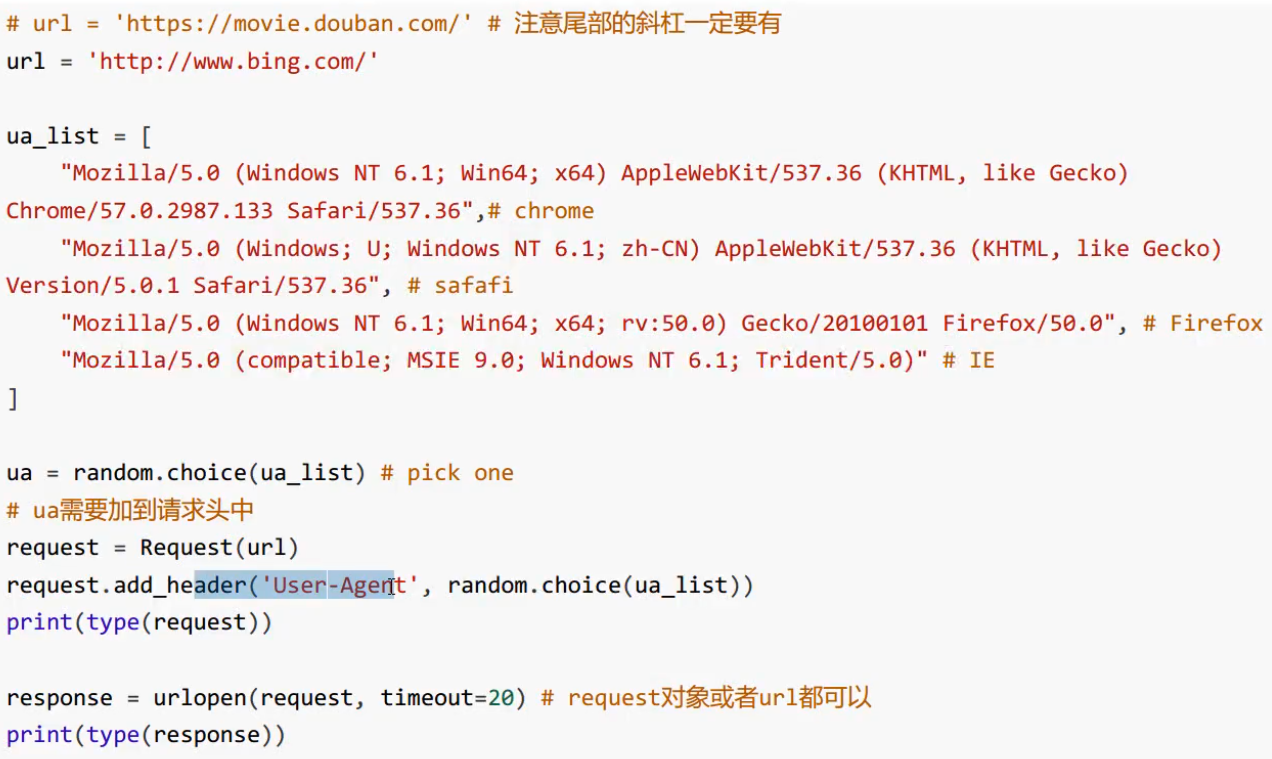

------------恢复内容结束------------

 浙公网安备 33010602011771号
浙公网安备 33010602011771号