Embedding过程,嵌入向量计算示例
嵌入向量计算示例
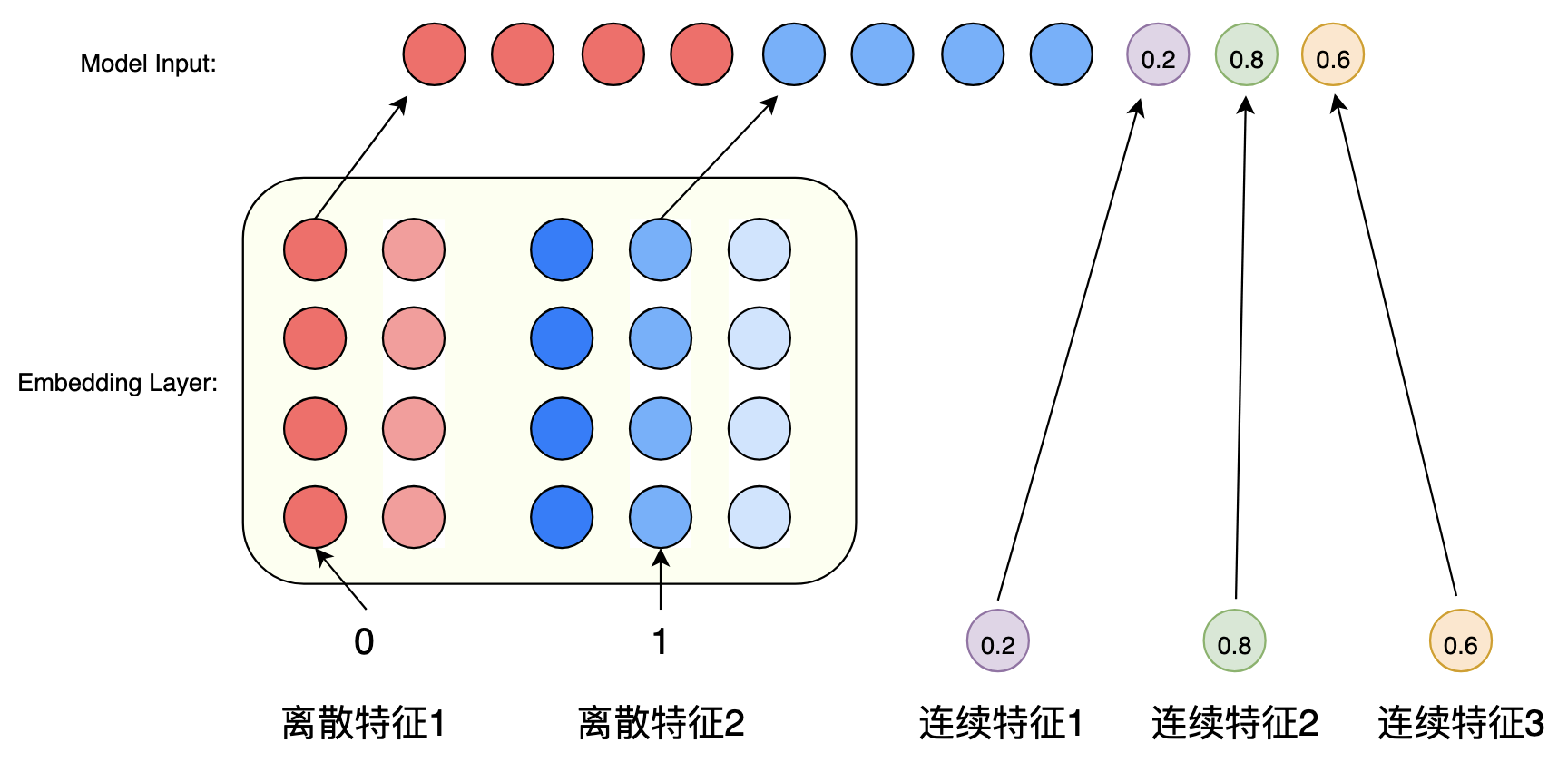
1. 问题设定
- 场景:电影推荐系统中用户对电影类型的偏好嵌入
- 输入特征:4种电影类型(动作片、喜剧片、科幻片、爱情片)
- 嵌入维度:
n_e = 2 - 词汇大小:
n_v = 4
2. 数据表示
(1)独热编码
| 电影类型 | 独热编码向量 |
|---|---|
| 动作片 | [1, 0, 0, 0] |
| 喜剧片 | [0, 1, 0, 0] |
| 科幻片 | [0, 0, 1, 0] |
| 爱情片 | [0, 0, 0, 1] |
(2)初始嵌入矩阵
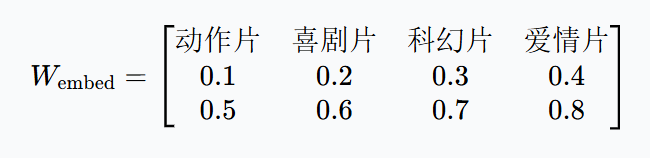

3. 嵌入向量计算
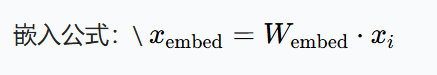

4. 结果分析
| 电影类型 | 嵌入向量 | 语义含义(假设训练后) |
|---|---|---|
| 动作片 | [0.1, 0.5] |
与科幻片接近(高能量特征) |
| 喜剧片 | [0.2, 0.6] |
与爱情片较远(情感特征差异大) |
| 科幻片 | [0.3, 0.7] |
与动作片聚类(科技+刺激关联) |
| 爱情片 | [0.4, 0.8] |
与喜剧片较远(情感类型差异) |
5. 关键公式总结
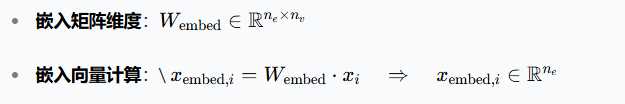
6. 可视化示意图
动作片 (0.1, 0.5) ← 接近 → 科幻片 (0.3, 0.7)
↑
|
爱情片 (0.4, 0.8) ← 远离 → 喜剧片 (0.2, 0.6)
7. 训练后的潜在变化
- 假设训练后:
- 动作片与科幻片的嵌入向量可能更接近(因用户常同时偏好两类)。
- 爱情片与喜剧片的嵌入向量可能分离(因情感类型差异)。
- 学习目标:通过反向传播优化 ( W_{\text{embed}} ),使嵌入向量反映真实语义关联。
注:实际训练中,嵌入矩阵会动态更新,此处仅为初始值示例。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号