特征交叉FM
FM的全称是Factorization Machines,翻译过来就是因式分解机,这么翻译很拗口,不得其神也不得其形,所以我们一般都不翻译简称为FM模型。
FM模型的优点有如下几点:
FM模型的参数支持非常稀疏的特征,而SVM等模型不行
FM的时间复杂度为O(n),并且可以直接优化原问题的参数,而不需要依靠支持向量或者是转化成对偶问题解决
FM是通用的模型,可以适用于任何实数特征的场景,其他的模型不行
稀疏场景
在真实场景中,都有一个问题绕不开就是特征的稀疏。举个很简单的例子,比如我们对商品的类目进行one-hot处理,在电商场景下商品的类目动辄上万个,那么one-hot之后的结果就是一个长度上万的数组,并且这个数组当中只有一位为1,其他均为0。当然这只是一个例子,除此之外还有许多许多的特征有可能是非常稀疏的。
一个真实场景的例子,预测用户对于一部电影的评分
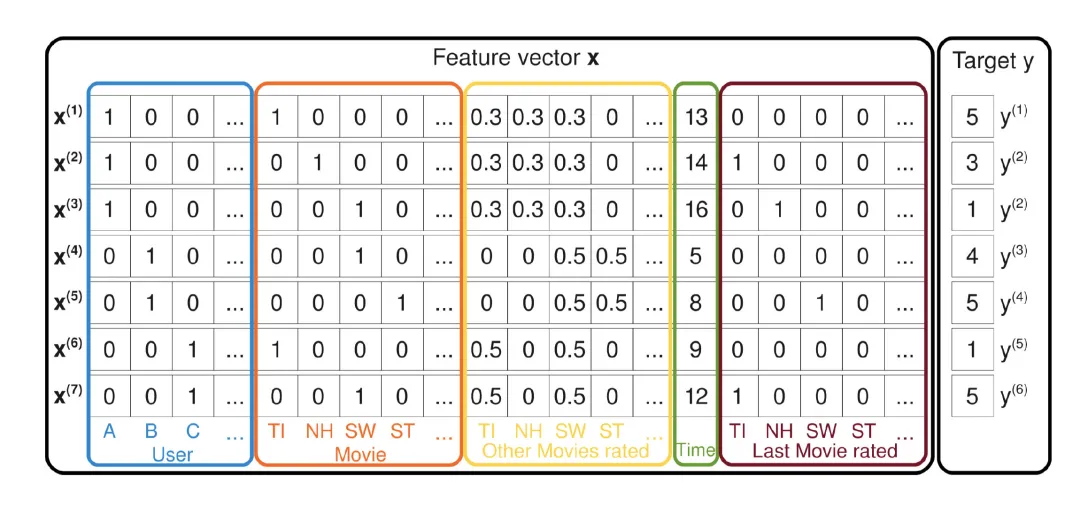
一个简单的线性方程只有一次项,尤其在稀疏场景下,刻画能力很差,所以FM对此引入二次项
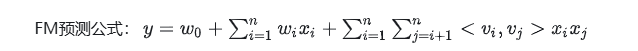
这里的
对与FM模型的介绍可以参考:https://link.zhihu.com/?target=https%3A//mp.weixin.qq.com/s%3F__biz%3DMzg5NTYyMDgyNg%3D%3D%26mid%3D2247489278%26idx%3D1%26sn%3Df3652394955d719bf02a91ca3b179ed2%26source%3D41%23wechat_redirect


 浙公网安备 33010602011771号
浙公网安备 33010602011771号