

学习进度笔记(六)
这次实验很困难,尤其是sbt部分,因为要在外网上下东西,很慢。
这次实验因为恢复了快照,下载了spark、scala、sbt等

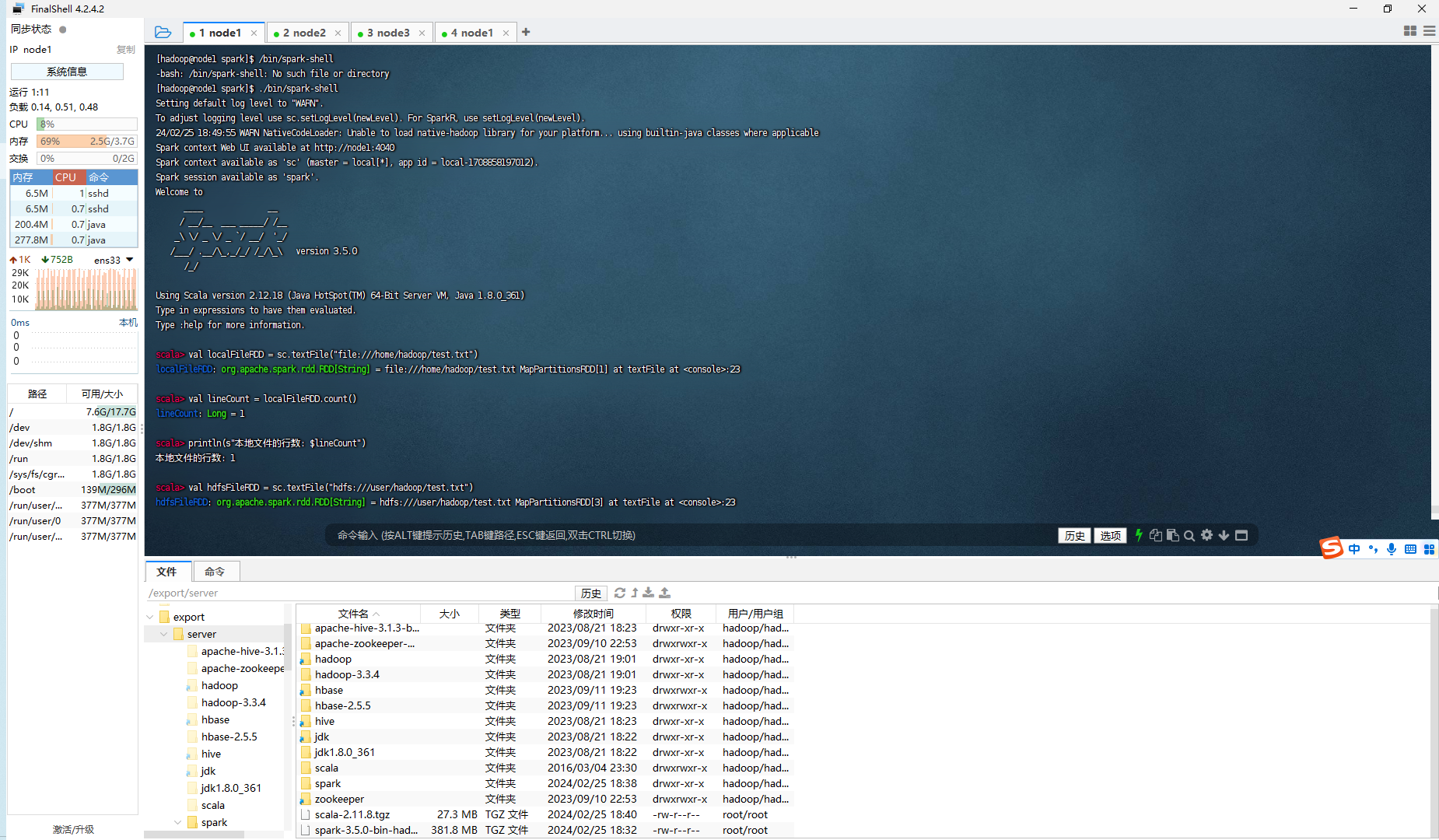
首先启动 spark-shell
$ spark-shell
val localFileRDD = sc.textFile("file:///home/hadoop/test.txt")
val lineCount = localFileRDD.count()
println(s"本地文件的行数: $lineCount")
在 spark-shell 中读取 HDFS 系统文件"/user/hadoop/test.txt",然后,统计出文件的行数:
// 读取 HDFS 文件并计算行数
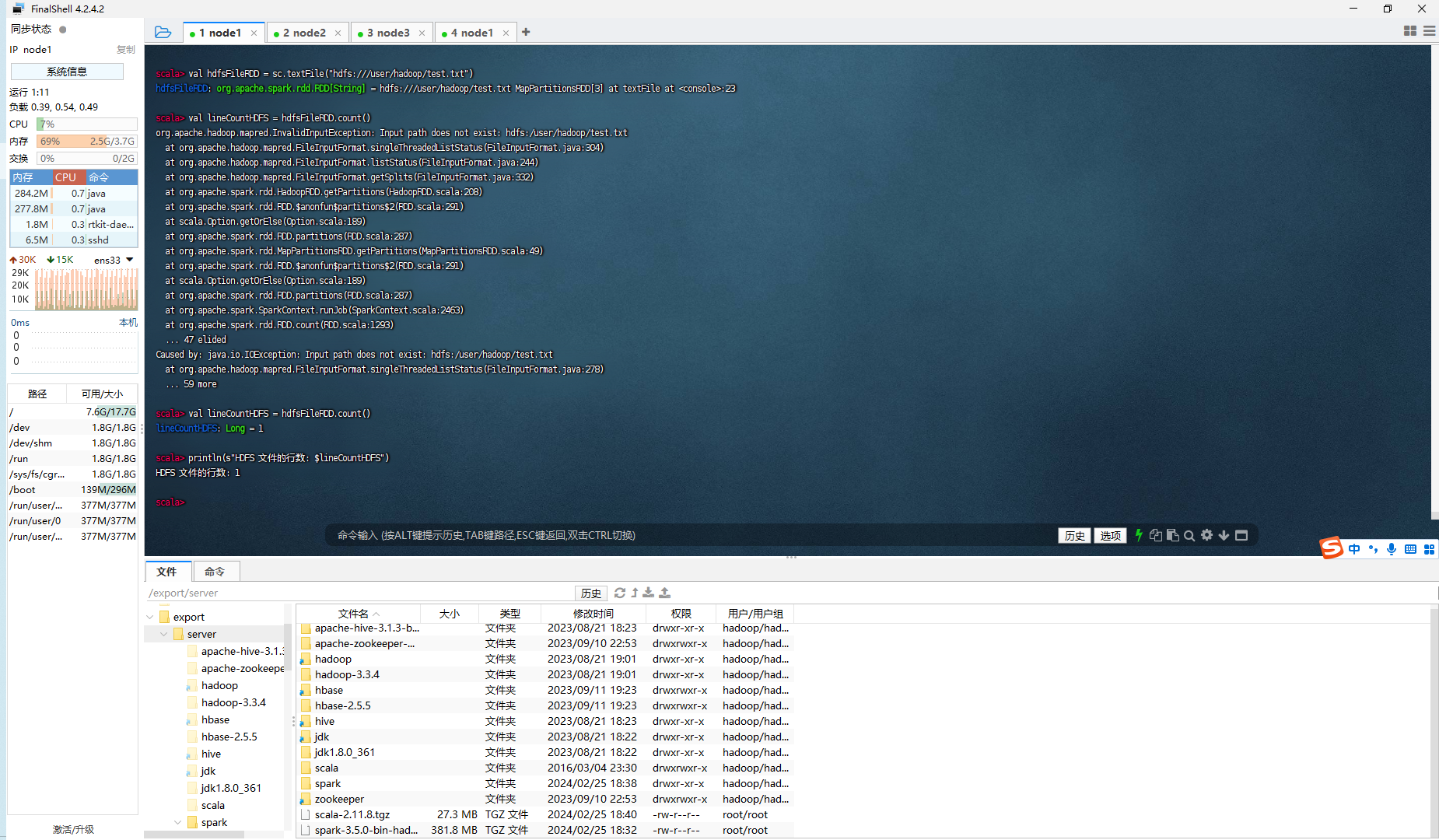
val hdfsFileRDD = sc.textFile("hdfs:///user/hadoop/test.txt")
val lineCountHDFS = hdfsFileRDD.count()
println(s"HDFS 文件的行数: $lineCountHDFS")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号