
模型评估与选择
模型评估与选择
1 经验误差和过拟合
- 错误的样本占样本的总数的比例叫做error rate,精度为1-a/m。
- 学习器的实际预测输出与样本的真实输出直接的差异叫做误差(error)。
- 学习器在训练集上的误差为训练误差(trainning error)或者经验误差(empirical error)。
- 学习器在新样本上的误差称为泛化误差(generalization error)。 显然,我们希望泛化误差越小越好。
- 过拟合(overfitting):学习器把训练样本学的太好了,导致泛化能力下降。与之相对应的是欠拟合(underfitting)。 导致过拟合的常见原因是学习能力过于强大,而欠拟合是由于学习能力低下造成的。 过拟合是机器学习面临的关键障碍,是无法彻底避免的。
- 泛化误差告诉我们在模型选择的时候要尽量选择泛化误差比较小的模型。但是这个需要我们对模型有一个准确的评估,因为我们无法事先知道模型的泛化误差。
2 评估方法
-
我们通常使用一个测试集(testing set)来评估模型的泛化误差,用测试集的误差近似的作为模型的范围误差。 测试集一般要求尽可能的在样本世界里面独立同分布,测试集要和训练集互斥。可是,我们只有一个包含m个样例的数据集\(D=\{(x_1,y_1),(x_2,y_2),...,(x_m,y_m)\}\),既要训练又要测试,怎么才能做到? 答案是我们对D进行适当的处理,产生训练集S和测试集T。有几种常见的方法:
-
留出法(hold-out)
把数据集划分成成为两个互斥的集合,其中一个作为训练集S,一个作为测试集T,即$D=S\cup T,S\cap T=\emptyset $。需要注意的是训练集和测试集要尽可能保持数据分布的一致性。通常采用分层采样,比如D里面有1000个样例,其中500个正例,500个反例,那么我们S里面也要保持这个比例,比如350个正例,350个反例,T里面包含了150个正例,150个反例。
现在的问题是即使我们分层采样和保持数据分布一致性,这样的划分方法人仍旧有很多种。不同的划分方法将导致不同的泛化误差。因此,使用单次的留出法得到的结果不可靠,所以我们一般都会多次划分,取平均值。
此外,D数据集既要训练又要测试,S和T的规模会影响最终的结果。常见的是,我们把2/3~4/5的样本作为训练集。
-
交叉验证法(cross validation)
把数据集分为k个大小相似的互斥子集,即\(D=D_1 \cup D_2 \cup ... \cup D_k,D_i \cap D_j=\emptyset(i\ne j)\)。每个\(D_i\)都尽可能的保持数据分布的一致性,即从D中通过分层采样得到。 然后每次k-1个子集的并集作为训练集,余下的作为测试集。这样就可以进行k次训练和测试,最终返回他们的平均值。 交叉验证法的k次影响了最终的结果,叫做k折交叉验证,k最常用的取值是10,叫做10折交叉验证。
与留出法一样,分成k个子集有多少方法,一般我们会重复p次,叫做p次k折交叉验证结果的均值。
如果k=m,那么叫做留一法,这个方法比较准确,但是运算量比较大。
-
自助法(bootstrapping)
留出法和交叉验证法由于保留了一部分样本用于测试,使得实际评估的模型所使用的训练集比D小,这会产生因训练规模不同而导致的估计偏差。
自助法对于一个包含m个样本的数据集D,我们每次从D里面挑选一个样本,将其放入D',然后把这个样本放回去,这样重复执行m次,就产生了D'这个训练集。显然,D'里面有些样本可能会重复出现。在m次采样的过程中,某个样本始终没有被采用的概率是\((1-\frac{1}{m})^m\),这个极限是\(\frac{1}{e}\approx 0.368\)。
由于自助法产生的数据集改变了初始数据集的分布,这会产生估计偏差。 因此在数据量比较足够的时候,我们还是采用留出法和交叉验证法。
-
调参和最终模型
大多数学习算法都有参数需要设定,而且参数的不同,结果往往有显著的区别。参数的设置往往在实数范围内选取,例如在[0,0.2]范围内以0.05为步长,那么我们就有5个参数。 这只是其中一个参数就有5种情况,如果一个模型有几十个甚至几百个参数,那么调参的工作量将是巨大的。所以在很多任务里面,参数调的好不好是决定模型性能的关键因素。
3 性能度量(performance measure)
-
对模型泛化能力的评价,就是性能度量(performance measure)。
在预测任务中,给定样例集\(D=\{(x_1,y_1),(x_2,y_2),...,(x_m,y_m)\}\),其中\(y_i\)是\(x_i\)的真实标记,要评估学习器\(f\)的性能,就要把学习器预测结果\(f(x)\)与真实标记\(y\)进行比较。
回归任务最常用的性能度量是“均方误差”(mean squared error):
\[E(f;D)=\frac{1}{m}\sum_{i=1}^{m}(f(x_i)-y_i)^2 \]更一般的,对于数据分布D和概率密度函数\(p(\cdot)\),均方误差可以描述为:
\[E(f;D)=\int_{x\in D}(f(x)-y)^2p(x)dx \] -
错误率和精度
对于样例集D,分类错误率定义为:
\[E(f;D)=\frac{1}{m}\sum_{i=1}^{m}\mathbb{I}(f(x_i)\ne y_i) \]精度为:
\[acc(f;D)=\frac{1}{m}\sum_{i=1}^{m}\mathbb{I}(f(x_i)=y_i)=1-E(f;D) \]更一般的,表述为连续型的值,就是:
\[E(f;D)=\int_{x\in D}\mathbb{I}(f(x)=y)p(x)dx \]\[acc(f;D)=\int_{x\in D}(f(x)=y)p(x)dx=1-E(f;D) \] -
查准率和查全率
查准率(precision): 查出来的信息有多少比例是用户感兴趣的。
查全率(recall):用户感兴趣的东西有多少比例被查出来了。
对于二分类问题,将真实类别和学习器预测类别的组合进行划分为4例,即真正例(true positive=TP),FP,TN,jN。 显然\(TP+FP+TN+FN=\)样例总数。 有矩阵如下:
真实情况 预测结果 正例 反例 正例 TP(真正例) FN(假反例) 反例 FP(假正例) TN(真反例) 此时查准率为:
\[P=\frac{TP}{TP+FP} \]查全率:
\[R=\frac{TP}{TP+FN} \]查准率和查全率是一对矛盾的变量。例如,希望将尽可能多的好瓜选出来的时候,则可以通过增加选瓜的数量来实现,如果将所有西瓜选上,那么所有的好瓜必然都在了,但是此时查准率会较低。 若希望选出的瓜中好瓜的比例尽可能的高,则只挑选最有把握的瓜,这样会遗漏一些好瓜,使得查全率较低。只有在一些简单的任务里面,查准率和查全率才能都很高。我们以查准率为Y轴,以查全率是X轴,绘制一个P-R曲线图:

ps:我们自己也用python画了一张,但是感觉好丑:
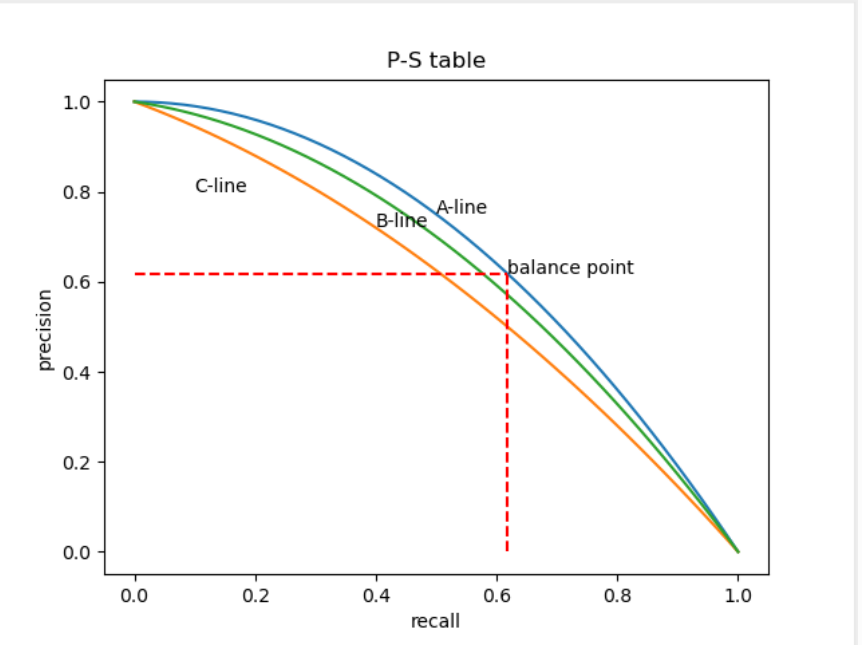
附录python代码:
import matplotlib.pyplot as plt
import numpy as np
plt.figure() # 定义一个图像窗口
plt.title('P-S table')
x = np.linspace(0, 1, 50)
y1 = -x*x+1
y2=-0.5*x*x-0.5*x+1
y3=-0.8*x*x-0.2*x+1
plt.plot(x, y1,) # 绘制曲线 y1
plt.plot(x,y2)
plt.plot(x,y3)
plt.xlabel("recall")
plt.ylabel("precision")
x=np.linspace(0,0.618,50)
y4=0*x+0.618
plt.plot(x,y4,color='red',linestyle='--')
y=np.linspace(0,0.618,50)
x=0*y+0.618
plt.plot(x,y,color='red',linestyle='--')
plt.text(0.618,0.618,'balance point')
plt.text(0.5,0.75,'A-line')
plt.text(0.4,0.72,'B-line')
plt.text(0.1,0.8,'C-line')
plt.show()
这里的平衡点(Break-Even Point,BEP)就是这样一个度量,查全率=查准率。 但是用BEP来衡量还是过于简单了一些,更常用的是F1度量。
F1可以看成是P和R的调和平均。
在一些情况下,查准率和查全率的重视程度是不一样的,我们要用加权调和平均来计算,用符号\(\beta\)表示查全率相对查准率的相对重要性,\(\beta >1\)时查全率有更大的影响。
很多时候我们有多个二分类混淆矩阵,进行多次训练/测试,得到一个混淆矩阵。一种方法是直接i在各个混淆矩阵上分别计算出查准率和查全率,记为\((P_1,R_1),(P_2,R_2),...,(P_n,R_n)\),再计算平均值。这样就得到宏查准率(macro-P)和宏查全率(macro-R),以及相应的宏F1。 具体见P32。
-
ROC和AUC
很多学习器是为测试样本产生一个实值或者概率预测,然后将这个预测值与一个分类阈值(threshold)进行比较,如果大于阈值则为正类,否则为反类。我们可以把所有测试样本的预测值进行排序,然后设置一个截断点(阈值),前面都判断为正例,后面都判断为反例。ROC曲线是研究学习器泛化性能的有利工具。
与P-R图不同,ROC曲线以真正例率(TPR)作为纵坐标,以假正例率作为横坐标:
\[TPR=\frac{TP}{TP+FN} \]\[FPR=\frac{FP}{TN+FP} \]我用python画了一个图:
![]()
import matplotlib.pyplot as plt import numpy as np plt.figure() # 定义一个图像窗口 plt.title('ROC and AUC') plt.xlabel('FPR') plt.ylabel('TPR') x = np.linspace(0, 1, 100) y1=-x**2+2*x plt.plot(x,y1,color='black') y2=x plt.plot(x,y2,color='red',linewidth=1,linestyle='--') y3=0*x plt.fill_between(x,y1,y3,where=y1>=y3,facecolor='grey',interpolate=True) plt.text(0.5,0.4,'AUC') plt.text(0.4,0.8,'ROC line') plt.show()AUC就是灰色部分的面积。明显的,对角线就是随机猜测的模型。 右上角的阈值最小,对应坐标点(1,1);左下角阈值最大,对应坐标点为(0,0)。从左下角到右上角,随着阈值的逐渐变小,越来越多的实例被划分为正类,但是这些正类中同样也掺杂着真正的负实例,即TPR和FPR会同时增大。
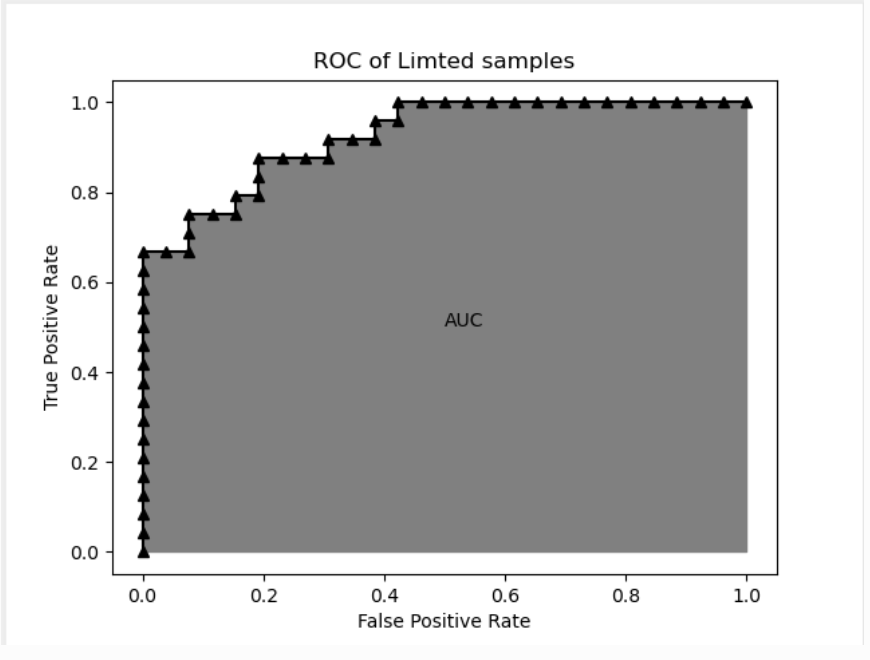
现实任务中通常是利用有限个测试样例来绘制ROC图,此时仅能获得有限个坐标对,无法产生光滑的ROC曲线。假设我们\(m^+\)个正例和\(m^-\)个反例,根据学习器预测结果对样例进行排序,然后把分类阈值设置为最大,即把所有样例均预测为反例,此时的点的坐标为(0,0),设置为\((x_0,y_0)\)。然后,将分类阈值依次设置为每个样例的预测值,即依次将每个样例划分为正例。设前一个坐标为(x,y),当前若为真正例,则对应的标记点的坐标为\((x,y+\frac{1}{m^+})\),当前若为假正例,则对应标记点的坐标为\((x+\frac{1}{m^-},y)\),然后用线段连接相邻点即可。
我们python随机模拟了50个测试样例,得到了如下的图:
![]()
附录python代码:
import matplotlib.pyplot as plt import numpy as np import random predict=[random.random() for i in range(0,50)] predict.sort(reverse=True) print(predict) real=[0 for i in range(0,50)] num=10 for i in range(0,40): t=random.randint(50-i,50) if t>=40: real[i]=1 else: num=num+1 s=[1]+predict x=[0.0 for i in range(51)] y=[0.0 for i in range(51)] for i in range(51): num1=0 num2=0 for j in range(50): if predict[j]>=s[i] and real[j]==1: num1=num1+1 else: if predict[j]>=s[i] and real[j]==0: num2=num2+1 x[i]=num2/num y[i]=num1/(50-num) print(x) print(y) plt.plot(x,y,color='black',marker='^') x2=x y2=[0 for i in range(51)] plt.fill_between(x,y,y2,where=y>=y2,color='grey') plt.text(0.5,0.5,"AUC") plt.title('ROC of Limted samples') plt.xlabel('False Positive Rate') plt.ylabel('True Positive Rate') plt.show()我们对学习器的比较时,与P-R图相似,若一个学习器的ROC曲线被另一个学习器的曲线完全包住,则可以断言后者的性能优于前者,若两个学习器的ROC曲线交叉,则难以一般性的断言孰优孰劣。比较合理的是比较他们的面积,即AUC(area under ROC curve)。 因为AUC越大,表明排序的质量越高,表明当FPR低的时候,TPR容易越高,这样面积就会越大。
从AUC的定义来看,面积可以计算为:
\[AUC=\frac{1}{2}\sum_{i=0}^{m-1}(x_{i+1}-x_i)\cdot(y_i+y_{i+1}) \]即梯形的面积的累加。
我们定义有\(m^+\)个正例有\(m^-\)个反例,令\(D^+\)和\(D^-\)分布表示正反例集合,则排序损失(loss)定义为

即考虑每一对正反例,若正例的预测值小于反例,则记录为一个罚分,若相等,则记录为0.5个罚分。容易看出:
即AUC就是正例的f值大于反例的f值的概率,对AUC的解释证明: https://www.alexejgossmann.com/auc/。
-
代价敏感错误率与代价曲线
很多时候,错误的代价不是等价的,为权衡不同类型错误所造成的不同损失,可为错误赋予“非均等代价”(unequal cost)。
以二分类任务为例,我们可以根据任务的领域知识设定一个代价矩阵(cost matrix),如下表所示,其中\(cost_{i,j}\)表示将第i类样本预测为第j类样本的代价。一般来说\(cost_{ii}=0\)。
真实类别 预测类别 第0类 第1类 第0类 0 cost_01 第1类 cost_10 0 代价敏感(cost-sensitive)错误率为:
\[E(f;D;cost)=\frac{1}{m}(\sum_{x_i \in D^+}\mathbb{I}(f(x_i)\ne y_i)\times cost_{01}+\sum_{x_i \in D^-}\mathbb{I}(f(x_i)\ne y_i)\times cost_{10}) \]在非均等代价下,ROC曲线不能直接反映学习器的期望总体代价,而代价曲线(cost curve)则可达到该目的,代价曲线图的横轴是取值为[0,1]的正例概率代价。
\[P(+)cost=\frac{p\times cost_{01}}{p\times cost_{01}+(1-p)\times cost_{10}} \]其中p是样例为正例的概率,纵轴是取值为[0,1]的归一化代价。
\[cost_{norm}=\frac{FNR\times p \times cost_{01}+FPR\times (1-p)\times cost_{10}}{p\times cost_{01}+(1-p)\times cost_{10}} \]将(18)式代入到(19)式可以得到:
\[cost_{norm}=FNR\cdot P(+)+FPR\cdot (1-P(+)) \]将\(p(+)\in [0,1]\)整体看成是参数(自变量),这是一个线性的参数方程,左端在(0,FPR),右端在(1,FNR)的一条线段,这种参数方程的定义在凸函数的定义里面也可以看到。
其中FPR是假正例率,FNR=1-TPR是假反例率。
单根线段与横轴之间的(梯形)面积=模型对于某一阈值的期望总体代价?
该面积和代价无关。期望总体代价很容易产生误解,给定一个阈值,相应的统计出(FNR,FPR),然后再画一条线,全程没有用到代价。
奇怪的是如果我们把 期望 —— 总体 —— 代价 拆开来一个个说,该命名还是有嚼头的。“期望”和“代价”是针对纵轴而言,毕竟纵轴表示归一化后的代价期望。“总体”是针对横轴,横轴是一个关于正例概率
的函数,故“总体”指的是所有
。
对概念的命名是件很难的事情,从不同角度着手理解,一个不完美的命名可以呈现既合适又不合适的情形。本人斗胆觉得用“期望总体代价”来描述围成面积是不可接受的,应该命名为“总体错误率”更为妥帖,即模型对于某一阈值的期望总体错误率,即:
\[\int_{p\in [0,1]} err(p)\cdot dp \]其中:
\[err(p)=FNR\cdot p+FPR \cdot(1-p) \]所有线段围成的下包络线与横轴之间的面积=模型对于所有阈值的期望总体代价?
既然任一直线的绘制与代价无关,那么所有直线拟出下包络线(即 CC 曲线)也与代价无关。依旧建议命名“总体错误率”,稍许不同的是
的表述:
\[err(p)=inf_{(FNR,FPR)\in \mathbb{O}} \quad FNR \cdot p+FPR\cdot (1-p) \]这里,\(\mathbb{O}\)指的是一个模型对应的所有(FNR,FPR)的集合,即 CC 空间中所有线段的端点。inf操作对应了寻 找下包络线。
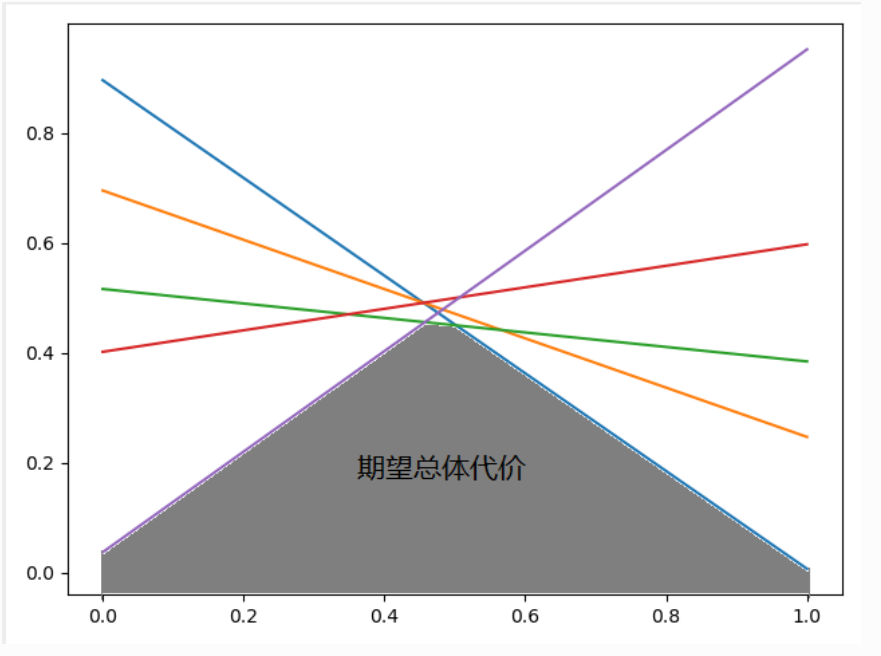
用python画一个图,附录代码:
import matplotlib.pyplot as plt
import numpy as np
import random
x=np.linspace(0,1,100)
fnr=[random.random() for i in range(5)]
fnr.sort()
fpr=[random.random() for i in range(5)]
fpr.sort(reverse=True)
for i in range(5):
t1=fnr[i]
t2=fpr[i]
y=(t1-t2)*x+t2
plt.plot(x,y)
plt.tight_layout()
plt.show()
还有一副是神奇的海螺:
4 Probabilistic interpretation(AUC)
As above, assume that we are looking at a dataset where we want to distinguish data points of type 0 from those of type 1. Consider a classification algorithm that assigns to a random observation \(x\in \mathbb{R}^p\) a score (or probability) \(\hat{p}(x)\in [0,1]\) signifying membership in class 1. If the final classification between class 1 and class 0 is determined by a decision threshold \(t \in [0,1]\), then the true positive rate (a.k.a. sensitivity or recall) can be written as a conditional probability:
For brevity of nation let's say \(y(x)=1\) instead of "x belongs to class 1", and \(y(x)=0\) instead of "x doesn't belong to class 1".
The ROC curve simply plots \(T(t)\) against \(F(t)\) while varying t from 0 to 1.Thus, if we view T as a function of F,the AUC can be rewritten as follows:
So we find the meaning of AUC is the probability of \(\hat{p}(x)>\hat{p}(x')\).
5 比较检验
-
统计假设检验(hypothesis test)为我们进行学习器性能比较提供了重要依据。基于假设检验结果我们可以推断出,若在测试集上观察到学习器A比B好,则A的泛化性是否在统计意义上由于B,以及这个结论的把我有多大。
-
假设检验
假设检验中的假设是对学习器泛化错误率分布的某种判断和猜想,例如\(\xi=\xi_0\)。现实任务 中我们并不知道学习器的泛化错误率,只能知道测试错误率\(\hat{\xi}\)。泛化错误率和测试错误率未必相同,但在直观上,二者接近的可能性比较大。
泛化错误率\(\xi\)的学习器在一个样本上犯错的概率是\(\xi\),测试错误率\(\hat{\xi}\)意味着在m个测试样本中恰有 \(\hat{\xi}\times m\)个被误分类。假定测试样本从样本总体分布中独立采样得到,那么泛化错误率是\(\xi\)的学习器将其中m'个样本错误分类,其余样本全部都分类正确的概率是\(\binom{m}{m'}\xi^{m'}(1-\xi)^{m-m'}\)。 由此可估算出其恰将\(\hat{\xi}\times m\)个样本误分类的概率如下:
\[P(\hat{\xi};\xi)=\binom{m}{\hat{\xi}\times m}\xi^{\hat{\xi}\times m}(1-\xi)^{m-\hat{\xi}\times m} \]给定测试错误率,则解:
\[\frac{\partial P(\hat{\xi};\xi)}{\partial \xi}=0 \]可以在\(\xi=\hat{\xi}\)时\(P(\hat{\xi};\xi)\)最大,\(|\xi -\hat{\xi}|\)增大时,P会减小。 这符合二项分布(binomial),若 \(\xi=0.3\),则10个样本中测得3个被误分类的概率最大。
python代码:
import matplotlib.pyplot as plt import numpy as np import random print(plt.style.available) plt.style.use('fivethirtyeight') j x=[0,1,2,3,4,5,6,7,8,9,10] y=[0.025,0.125,0.24,0.27,0.2,0.1,0.07,0.02,0.01,0.005,0.05] plt.bar(x,y,color='r') plt.xlabel('Wrong Classification Of Samples') plt.ylabel('Probability') plt.tight_layout() plt.show()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号