
OO第一单元作业分析——我们为什么要面向“对象”
一, 基于经典度量的分析
作业1:多项式
“天地玄黄,宇宙洪荒。日月盈昃,辰宿列张。”——《千字文》
由于刚刚接触Java语言,对于很多功能,比如正则表达式,StringBuffer,ArrayList等必不可少的功能与结构还相当陌生。另一方面,“对象”的概念彼时刚刚进入我们的世界。虽然从形而上的角度并不是特别难理解,但是想要迅速地掌握并应用,却绝不是一件非常容易的事。言而总之,这次的任务难就难在一个“新”上面:一切都是新的,新的思想,新的方法,新的工具,因此个人认为第一次作业现在看来甚是容易,实际上在当时还是蛮有挑战的。
第一次作业仅仅包含幂函数与常数项,因此类的关系相对简单一些。主要是关于输入处理,我的思路是先以乘积项为单位,一项一项进行匹配,一旦匹配成功便将其复制到新的一个StringBuffer当中,并从原串中删除。最后考虑原串当中剩下的内容,显然此时如果仍有字符残余(即原串不是仅仅由空字符组成)则可知输入格式错误。这样做的优势有二:其一,避免了大正则式子匹配整个串因而导致爆栈。这往往是因为正则表达式的回溯操作使得CPU计算量过大导致的。而如果像这样一项一项匹配则会好很多。其二,可以实现检验,处理与简化一起完成。每当我们匹配一项之后,就将其提取出来,这样只要完毕之后(即字符残余仅有空字符)接着依项分析即可,而不必重新开始。
下面首先先给出此次project的整体视图,这里用到了UML工具:

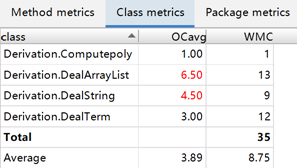
接着再对各个类与方法的规模,复杂度与分支数进行分析。我们采用Intellij IDEA强大的插件实现评价功能:

(Statistic:统计代码行数)
其实从表像上来看,模块化看似还是有些可圈可点的——至少除去ComputePoly这个类(主函数)之外,其他的类代码数量都相差不大,然而事实上,我们的结构仍存在很大的问题,下文将会进行详细描述。

(MetrixReloaded统计复杂程度)
其中,ev(G)表示基本复杂度,iv(G)表示模块结构的复杂度,v(G)表示独立路径条数。
然后是类之间的耦合或关联程度,我们采用软件自带的Dependency Matrix功能:

(Dependency Matrix:度量耦合程度)
最后总结一下,此次作业虽然表面上看似已经摆脱了面向过程,实际上在“面向对象”思想实践中也是相当糟糕的。事实上从类的名字——清一色的动宾短语就可以看出来,本质上我们并没有做到真正的面向对象,而仅仅是把过程模块化,而每个模块赋予一个“对象”。各个类就像是一条流水线的机器,承接上一个类传过来的产品,再传给下一个类。换言之,我们所谓的“对象”仍然是如假包换的“过程”,正如披着羊皮的狼一般。
正因此,我们的类内聚程度仍然过高——从上面的矩阵可以看出DealTerm类一行明显高于其他的值。换句话说,DealTerm几乎承包了所有工作。这一点从类图也不难看出:DealString只负责处理输入,然后DealArrayList只负责最终优化,打印,掐头去尾,中间的过程全部甩给辛苦的DealTerm。
作业2:多项式与三角函数
“奋六世之余烈,振长策而御宇内。”——《过秦论》
第二次作业可以看作仅仅是第一次作业的升级版,无非是多了两种“未知数”(sin(x),cos(x))。从这个角度来看,只要把之前成绩项类的属性再增加两个(正弦函数次数与余弦函数次数)即可,与第一次大同小异。因此第二次作业的完成可以说是一马平川,顺理成章,算是歪打正着地尝到了架构好的甜头。不再赘述,我们直接来看结构:

规模与复杂度表格如下:



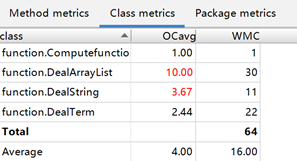
然后是耦合度矩阵:

在这里还是想提一句,其实我们的思路(即前面分析中提到的“伪对象”思想)并不是一无是处,相反它在处理前两次作业的时候可谓是得心应手,十分便捷而清晰。但是,这并不意味着我们应该满足于此(事实上,第三次作业这样就行不通了,或者说至少需要一番伤筋动骨才能继续)。
不出意料,这里由于题目的繁琐度增加,DealTerm相当于要承担更多的任务了,于是耦合度矩阵数值再次增加。
作业3:函数嵌套
“穷则变,变则通,通则久。”——《周易》
果不其然,该来的还是来的。这一次我仍然想果(tou)断(lan)地沿用前两回的思路,结果发现真个出师不利:正则怎样匹配嵌套结构?情急之下,看来只能使用上课讲授的继承那些东西了。
这次作业我主要是基于表达式树的构建,对于嵌套采取递归处理的策略。由于结构较为复杂,这里我们结合类图再进行详细阐释。

由图可知,首先构造一个抽象类BasicTerm,然后再建立常数类(Constant),幂函数(Power)类,三角函数类(Sinnest,Cosnest),乘积类(Product)和和类(Sum)等多达六个继承类。BuildTree实际上功能非常简单,更多的是依赖各个子类对其的调用。最后,我们在输入处理依旧沿袭上次的策略——交由CheckInput类处理。
下面是性能度量:
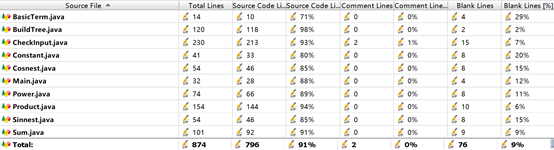



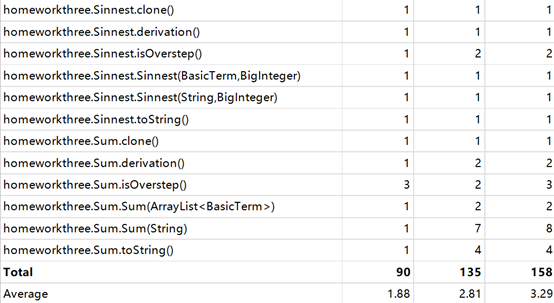


(即便是耦合度矩阵也平衡多了!)
这一次,可以说真正进入面向对象的大门!
二, 程序中存在的bug分析
与很多人想象中的不一样,bug的来源往往并不是所谓个人行为上的疏漏,而以逻辑层面居多。换言之,我们需要将重心关注在自己的整个思路是否足够严密之上。然而很不幸,由于从理论上证明绝对严谨对于程序而言是不可取的,因此最有效的检查方式不是闷着看(这当然是初期必不可少的,但是对于复杂任务往往显得力不从心),而是测试,包括自测,互测等等。
这里就举我第一次作业中出现的一个bug,因为它令我深刻领会到我们看似强大的程序逻辑实际上很可能弱不禁风:
+ + +x +1
根据前述思路,我在第一次匹配时会提取+ +x,而原式变成:
+ +1
同样是符合要求的!
换言之,我完全没有考虑提取之后前面的乱七八糟东西和后面的乱七八糟的东西能够组合成满足要求的东西。
三, 发现bug(dao ren)经验分享
关于互测,很让人困惑的一点是,究竟是该老老实实地读对方代码,然后找出漏洞,还是用各种“危险”数据去尝试?从个人体会而言,尤其是当的对手代码相对完善的情况下,后一种方法无疑是低效的。事实上,就像一千个读者眼中有一千个哈姆雷特,一千个程序也都有各自的bug,很难说哪种bug能够放之四海而皆准。因此发现bug应当是基于特异性与针对性的。当然,从头到尾仔细读代码可能也没有这么多的时间和精力(尤其是现在的规则变成一个屋子八个人,这意味着你要在两天之内读完七个人的代码,想想头都大)。因此个人以为,最佳的方式是折中——尽量读,并找bug。我们当然要有尝试的心理准备,但这应当建立在分析的基础之上。
为了具体说明,在这里分享一个个人经历。
第二次作业中,同学A的代码写的非常漂亮,但是读到他的输入处理的时候,我发现他居然只有一个正则表达式——这意味着在他眼里,第一项(乘积项)和后面的项并没有什么区别。于是,抱着试试看的心态,我尝试了如下输入:
x x
令人十分遗(jing)憾(xi),栽了。
四, 结语
总而言之,此单元的三次作业令我以实践的视角,审视了“对象”的真正含义。我想对于一个已经过于习惯面向“过程”的人而言,这种转变绝对不是一朝一夕所能完成的。但是我想这至少应当标志着一个开始,事实上从三次作业的变化,也能看出个人思维的转变。总之,希望今后的面向对象学习之路能够更加精彩。
