AimTS: 用于时间序列分类的增强序列和图像对比学习《AimTS: Augmented Series and Image Contrastive Learning for Time Series Classification》(时间序列分类、对比学习、自监督预训练框架、多源泛化范式、原型(平均表征)、时序(数值)-图像表征融合对齐)
2025年4月22日,看一篇论文。
论文:AimTS: Augmented Series and Image Contrastive Learning for Time Series Classification
GitHub:
ICDE 2025的论文。
得抓紧做了,感觉再不加速,思路又被别人做出来了。(唉,加速加速,加油。)
摘要
(24号了,大哥,你怎么回事.)
时间序列分类(TSC)是时间序列分析中的一项重要任务。现有的时间序列分类方法主要是对每个单一域进行单独训练,当某些域的训练样本不足时,准确率就会下降。预训练和微调范式为解决这一问题提供了一个很好的方向。然而,来自不同领域的时间序列差异很大,这对多源数据的有效预训练和预训练模型的泛化能力提出了挑战。为了解决这个问题,我们引入了用于时间序列分类的增强序列和图像对比学习(AimTS),这是一种从多源时间序列数据中学习可泛化表征的预训练框架。我们提出了一种基于两级原型的对比学习方法,可在多源预训练中有效利用各种增强,从而为 TSC 学习可推广到不同领域的表征。此外,考虑到单一时间序列模式下的增强不足以完全解决分布漂移的分类问题,我们引入了图像模式来补充结构信息,并建立了序列-图像对比学习,以提高学习到的 TSC 任务表征的泛化能力。广泛的实验表明,经过多源预训练后,AimTS 实现了良好的泛化性能,可以在各种下游 TSC 数据集上进行高效学习,甚至可以进行少量学习。
索引词条-时间序列分类,对比学习
I. 引言
时间序列分类(TSC)是许多领域中的一项经典而具有挑战性的任务,例如动作识别[1]、医疗保健[2]和交通[3]。确保高分类精度需要大量的训练样本,对于最新的深度模型来说尤其如此。如图 1 所示,现有的时间序列分类方法主要遵循三种范式: (a) 逐个案例范式[4]-[6],即针对每个数据集训练一个特定模型,并在同一数据集上进行测试;(b) 单源泛化范式[7]、[8],即在一个数据集上训练一个可迁移模型,然后迁移到另一个数据集上进行微调和推理;(c) 多源适应范式[9]、[10],即在由下游数据集组成的多个数据集上预训练一个通用模型。
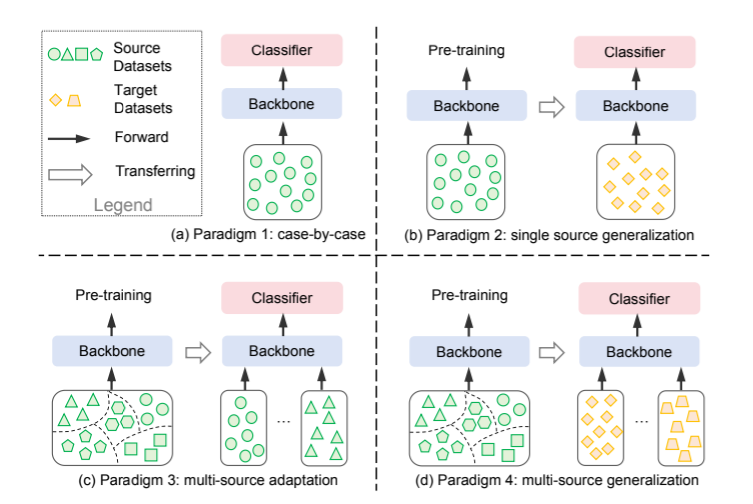
图 1:用于 TSC 的现有深度学习方法示意图。
然而,为每项任务获取足够的训练数据并不总是切实可行的,因为标注时间序列数据本身就具有挑战性,需要大量的专业知识。例如,对大多数人来说,解读癫痫系列数据以评估健康状况是很困难的,只有医疗专业人员才能可靠地将其标记为健康或不健康,从而导致训练样本不足。在这种训练样本稀缺的数据集上使用范式 1 非常容易造成过拟合。范式 2 的目的是利用单源数据进行预训练,然后将其迁移到下游数据,以克服数据的限制。然而,当预训练数据和下游数据之间存在显著的领域差异时,例如手势和癫痫之间的差异,这种方法就会表现不佳。范式 3 使用多源数据进行预训练,但当下游数据(如癫痫系列)在预训练数据集中不可用时,其性能就会大打折扣。
这促使我们设计了一种自监督预训练方法,它可以从多个数据源中学习一般表征,然后在特定的下游任务中使用少量样本对模型进行微调,而这些样本在预训练期间不一定能看到(图 1(d))。因此,我们提出了一种新颖的多源泛化范式来解决数据限制问题。与单数据集预训练相比,多源数据预训练有助于模型学习更多样化的时间序列模式。同时,自监督学习解决了训练数据不足的问题,从而有效地解决了标签稀缺的问题。在这种模式下获得的表征具有更强的通用性,从而在不同领域的下游任务中发挥更好的性能。
现有的自监督方法,如对比学习方法 [7]、[11]、[12],已在分类任务中证明了其有效性。这些方法得到了各种数据增强策略[13]-[15]的支持,这些策略将相同样本的增强作为正对,将其他样本的增强作为负对,以提高模型的准确性和泛化能力。然而,不同领域的时间序列数据会因语义漂移而出现显著差异 [13],[16]-[19]。这使得现有的对比学习和数据增强方法很难在预训练中对多个领域的数据进行泛化(同意这个问题的存在.)。
第一个挑战是,不同的数据增强可能无法保持与原始时间序列相同的语义,这使得在多域预训练中使用增强时间序列进行对比学习具有挑战性。现有方法 [7]、[12] 在进行对比学习时,将同一时间序列样本的各种增强视图视为正对,其假设是增强数据保留了与原始数据相似的语义信息,而这正是区分不同样本的关键。然而,某些数据增强可能会改变原始样本的语义[14]。例如,对运动时间序列应用抖动增强可能不会改变运动状态,但对心电图(ECG)时间序列应用抖动增强可能会使其从健康状态转变为不健康状态[13],如图 2 所示。将两个语义不同的视图作为正对放在一起会混淆模型,从而影响所学表征的分辨性能[20]。在面对多个领域数据时,我们无法手动调查增强样本是否与原始时间序列表现出相同的语义。因此,在避免错误使用增强数据的同时有效利用多个增强数据是一项挑战。

图 2:增强导致语义变化的示例。ECG200 数据集记录了健康人和心肌梗塞(MI)患者的心电图。(a) 两个标签的模式图示。T 波倒置是心肌梗塞的标志。(b) 黑线表示正常心电图,绿线表示心肌梗死心电图。(c) 蓝色虚线显示正常心电图上的抖动增强,该增强样本的 T 波已经倒置。(d) 经过抖动后,正常样本与心肌梗死样本变得更加相似,导致其语义发生变化。
第二个挑战是,单一时间序列模式下的数据增强限制了模型从跨多个领域的整个时间序列样本中学习一般表征的能力。如图 2 所示,形态(即结构)信息,如线条或曲线的组成,对于区分 TSC 中的类别至关重要[21],[22]。然而,时间序列模式将数据描述为随时间变化的数值序列。它主要捕捉的是基于数值的统计信息,在解决数据集分布漂移的分类问题时可能仍有局限性。仅仅增强时间序列数据并不能完全捕捉结构信息,而结构信息有助于以互补的方式对 TSC 进行泛化。(同意,仅靠增强数值并不能实现完全的结构信息的获取.)
为了解决这些问题,我们提出了用于时间序列分类的增强序列和图像对比学习(AimTS),该方法通过在多源预训练中增强时间序列值和结构来学习可概括的表征,从而实现时间序列分类。
为了应对第一个挑战,我们提出了基于原型的两级对比学习,包括原型间对比学习和原型内对比学习。由于大多数扩增不会改变原始样本的语义,因此将扩增样本聚合到原型中可以最大限度地减少某些扩增可能造成的语义变化的影响。与现有的由同类样本聚合而成的原型[23]不同,我们提出了新颖的原型间对比学习方法,即从多个增强样本中学习原型。在原型间对比学习中,不同样本的原型作为负对,而原型及其对应的样本作为正对。在使用多源数据进行训练时,增强会对不同领域产生不同的影响。为了进一步实现所学表征的泛化,不同的增强方法对原型的贡献应该相同(赞同,这样会更有泛化性.)。因此,我们提出了具有自适应温度的原型内对比学习方法。它鼓励来自不同增强方法的表征均匀分布,使聚合原型能够充分利用所有增强方法,而不是被特定的增强方法所支配。
为了应对第二个挑战,我们提出了序列-图像对比学习法,目的是通过同时捕捉时间序列和图像模式中的数字和结构信息来学习一般的时间序列表示。我们首先将每个时间序列样本转换成 RGB 图像。与现有的单纯图像建模不同,我们建议分别对图像和时间序列进行编码,以提取每种模态的表征。接下来,序列-图像对比学习将每个时间序列样本的相应图像作为正样本,将其他样本的图像作为负样本。仅仅将图像作为负样本还不足以区分不同的时间序列样本,因为它们的数字方面缺失了,而这在 TSC 中也是至关重要的。我们进一步设计了一种新颖的测地线序列-图像混合策略,以创建混合模式表示作为负样本,同时考虑时间序列的数值和结构方面,从而更好地区分属于不同类别的时间序列样本。
总之,我们的贡献如下:
- 我们提出了首个 TSC 预训练框架,从多个数据集中学习通用时间序列表征,从而提高各种下游数据集的性能。
- 我们设计了一种基于原型的对比学习方法,可在预训练期间有效地增强多源数据集,从而获得通用表征。
- 我们引入了图像模式,以克服单一模式增强策略的局限性,并通过序列-图像对比学习利用图像模式获得更具普适性的表征。
- 广泛的实验表明,AimTS 在下游分类任务中实现了良好的泛化性能,在 128 个 UCR 数据集和 30 个 UEA 数据集上的平均准确率分别为 0.870 和 0.780,优于最先进的方法。
II. 相关工作
A. 时间序列对比学习
对比学习作为一种常见的预训练方法,已在许多领域取得了成功 [24]-[26]。对于时间序列分析,这种无监督表示学习方法在各种任务中都取得了良好的效果。T-Loss [27] 使用时间序列中的随机子序列,当它们属于该子序列时,将其视为正对,如果属于其他序列的子序列,则视为负对。TNC [28] 使用正态分布定义窗口的时间邻域,将邻域内的样本视为正样本,邻域外的样本视为负样本。TS-TCC [12] 使用弱增强和强增强生成两种数据视图。TS2Vec [6] 提出了增强上下文视图,以获得时间序列不同语义层次的表示。TimesURL [29] 提出了用于构建负对的双 universums,并引入了时间重构。CoST [30] 引入了频域对比损失(frequency-domain contrastive loss),以分别学习分离的趋势和季节表征。TFC [7] 提出了一个对比学习目标,即最小化基于时间的嵌入和基于频率的嵌入之间的距离。SoftCLT [31] 为对比损失引入了 0 到 1 的软赋值。与这些方法不同,AimTS 不再局限于提取特定数据集中的表征,而是通过多源预训练为下游时间序列分类任务获取通用表征。
B. 自适应数据增强
数据增强是对比学习的关键组成部分。通过增强不同样本的对比学习已被应用于深度学习的各个领域 [11]、[32]、[33]。不同领域的研究表明,最合适的增强方法因目标任务和数据集而异 [13], [14]。在时间序列领域,有一些研究侧重于为给定数据集开发自适应选择最佳增强和参数的方法。CADDA [34] 提出了一种基于梯度的框架,该框架扩展了 AutoAugment [35] 的双层框架,用于搜索脑电信号的分类数据增强策略。InfoTS [36] 根据信息感知的高保真和多样性定义,提出了一种选择有效增强的标准。AutoTCL [37] 提出了一种基于因式分解的自适应数据增强搜索框架,它以统一的形式总结了最常用的增强方法,并将其扩展为参数化增强方法。虽然这些研究实现了对比学习中的自适应搜索,但它们仅限于单数据集应用,无法同时为多个目标数据集选择最佳增强和参数。
C. 时间序列的图像模式
将图像模式用于时间序列分析是一个尚未充分开发的领域。现有方法通过格拉米安场 [38]、递归图 [39]、[40] 和马尔可夫转换场 [41] 等方法将时间序列数据可视化。这些方法需要领域专家设计专门的成像技术,并非普遍适用。ViTST [42] 将时间序列绘制成折线图,并取得了很好的效果,这表明要实现有效的可视化,可能并不需要大量的专门设计。除了时间序列分类任务外,近期的研究还探索了利用图像进行时间序列预测和异常检测。VisionTS [43] 将时间序列转换成二值图像用于预测,而 HCR-AdaAD [44] 则从时间序列图像中提取表征来帮助异常检测。然而,目前的方法往往在将原始时间序列数据转换为图像后就将其丢弃,而只专注于图像分析。AimTS 通过同时处理时间序列和图像模式解决了这一局限性,通过整合图像模式建模提高了 TSC 任务的性能。(是多模态的意思.)
(有罪,现在是5月6日了.)
III. 前言
我们首先介绍重要概念,然后提出问题陈述。
A. 定义
定义 1:时间序列。时间序列定义为 X = ⟨x 1 , x 2 , ... , x 𝑀 ⟩∈R 𝑀×𝑇 ,其中 𝑀 是变量数(或维数),𝑇 是时间步数。当 𝑀 = 1 时,是单变量时间序列。当 𝑀 > 1 时,它是一个多变量时间序列,我们也称 X 为时间序列样本。
定义 2:时间序列分类。时间序列分类是为时间序列分配预定义类别标签的任务。给定数据集 D = {X 1 , X 2 , . 目标是学习一个映射函数 𝑓 (X 𝑖 )→ 𝑦 𝑖,该函数将每个时间序列 X 𝑖 分配给一个标签 𝑦 𝑖∈ {1, 2, . , 𝐶},其中 𝐶 是类的数量。
定义 3:增强视图。数据增强 𝑔(-) 是一种通过修改真实数据样本来人为扩增数据集的技术。时间序列样本 X 的增强视图是经过转变的时间序列 X ′ = [𝑔(x 1 ),𝑔(x 2 ), ...,𝑔(x 𝑀 )] ,其中 𝑔(-) 应用于每个变量 x∈R 𝑇 。
定义 4:对比学习。对比学习的目的是通过拉近相似对和拉开不同对来学习表征。给定一个锚点 X、一个正向视图 X + 和一个负向视图 X -,对比损失的定义为:
![]() 其中,r、r + 和 r - 分别是 X、X + 和 X - 的表征。
其中,r、r + 和 r - 分别是 X、X + 和 X - 的表征。
B. 问题陈述
在预训练期间,我们使用由 𝑘 个不同子数据集或源域组成的数据集![]() 。第 𝑘 个源域表示为
。第 𝑘 个源域表示为![]() ,其中 𝑁 𝑘 是该源域中的样本数,
,其中 𝑁 𝑘 是该源域中的样本数,![]() 是用于预训练的时间序列样本总数。在𝑘-th 源域中𝑖-th 样本表示为
是用于预训练的时间序列样本总数。在𝑘-th 源域中𝑖-th 样本表示为![]() 其中𝑀 𝑘 是其变量数,𝑇 𝑘 是其长度。预训练的目的是学习一个模型𝐹 (-),以便从 D pret 中获得可泛化的表征,从而帮助完成新领域的分类任务。我们将 D target 称为下游分类的目标数据集之一,
其中𝑀 𝑘 是其变量数,𝑇 𝑘 是其长度。预训练的目的是学习一个模型𝐹 (-),以便从 D pret 中获得可泛化的表征,从而帮助完成新领域的分类任务。我们将 D target 称为下游分类的目标数据集之一,![]()
![]() 作为其训练数据,其中,𝑦𝑖 是时间序列 X 𝑖∈ R 𝑀×𝑇 的标签,𝑁 target 表示该下游任务的训练样本数。该训练集用于微调预训练模型 𝐹 (-) 和训练特定任务分类器 𝑃 cls,然后对每个目标数据
作为其训练数据,其中,𝑦𝑖 是时间序列 X 𝑖∈ R 𝑀×𝑇 的标签,𝑁 target 表示该下游任务的训练样本数。该训练集用于微调预训练模型 𝐹 (-) 和训练特定任务分类器 𝑃 cls,然后对每个目标数据![]() 进行准确分类,即
进行准确分类,即![]() 。
。
IV. 方法
A. 总体框架
我们提出的 AimTS 是一个预训练框架,旨在通过基于原型的序列-图像对比学习来增强多源数据集表征的泛化,从而完成 TSC 任务。图 3 给出了 AimTS 框架的概览,该框架由预训练阶段和微调阶段组成。如图 3(a)所示,我们首先使用两个对比学习任务预训练一个时间序列(TS)编码器和一个图像编码器,然后在下游任务中通过微调迁移预训练的 TS 编码器并训练一个分类器,如图 3(b)所示。
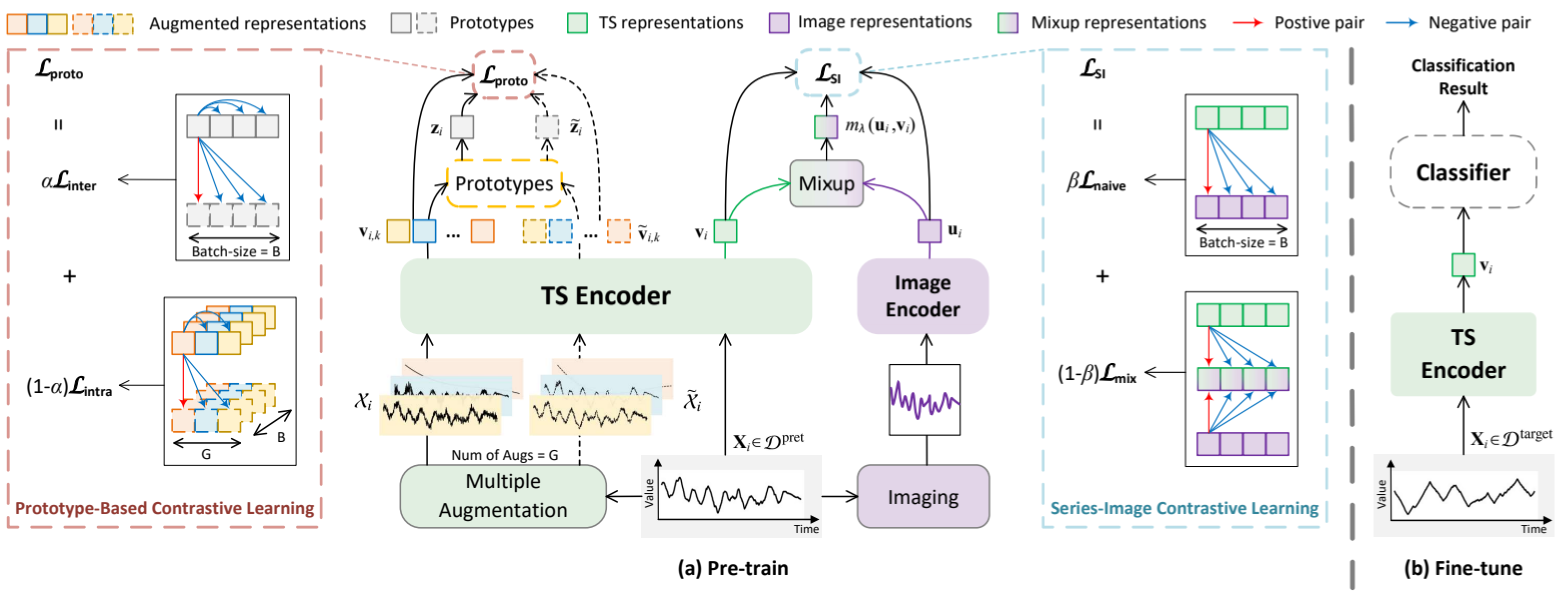
图 3:AimTS 概览。
在预训练阶段,对于每个输入时间序列样本,我们会应用多个数据增强来生成多个增强视图。然后将这些视图输入 TS 编码器,生成各自的表征。通过汇总这些不同视图的表征,我们得到了样本的原型。基于这些原型,我们提出了原型内对比学习和原型间对比学习。通过添加这两种对比策略,我们提出了基于原型的两级损失 L proto 来捕捉广义表征。
同时,每个时间序列样本都会被转换成图像。图像编码器将时间序列数据生成的标准化图像作为输入,并将输入转换为图像表征。为了补充一般的时间序列表征学习,我们在时间序列表征和相应的图像表征之间采用测地线混合策略进行序列-图像对比学习损失 L SI。
在预训练期间,AimTS 通过基于原型的对比损失 L proto 和序列-图像对比损失 L SI 来优化 TS 编码器和图像编码器的参数。总损失定义为:
![]() 在微调阶段,我们使用目标数据集的训练集数据来微调预训练 TS 编码器的参数,并训练特定任务的分类器。在这一阶段,时间序列输入被直接输入 TS 编码器,无需任何数据增强或图像转换,即可生成一个表示。然后将该表示传递给分类器,以获得类变量值的概率分布。利用交叉熵损失,我们可以微调 TS 编码器的参数,同时为下游任务训练特定任务分类器。
在微调阶段,我们使用目标数据集的训练集数据来微调预训练 TS 编码器的参数,并训练特定任务的分类器。在这一阶段,时间序列输入被直接输入 TS 编码器,无需任何数据增强或图像转换,即可生成一个表示。然后将该表示传递给分类器,以获得类变量值的概率分布。利用交叉熵损失,我们可以微调 TS 编码器的参数,同时为下游任务训练特定任务分类器。
B. 基于原型的对比学习
为确保在多源预训练中有效利用各种数据增强,以获得可应用于不同下游分类任务的通用表征,我们提出了一种新颖的两级基于原型的对比学习,作为该框架的第一个学习目标。在这里,我们首先详细介绍通过聚合多个增强视图来生成原型,然后构建基于原型的对比学习,包括原型内对比学习和原型间对比学习。
1) 原型生成: 通过不同的数据增强操作生成的视图可以捕捉不同变换下时间序列数据的特征。然而,对于给定的数据集来说,在多领域预训练的背景下,哪些数据增强方法可能会扭曲数据的语义往往并不清楚。考虑到现有方法使用的大多数增强方法不会改变原始样本的语义[13]、[14],我们将时间序列样本的增强视图聚合到原型中,以尽量减少特定增强方法带来的任何语义变化的潜在负面影响。(还是从整体角度考虑的,忽略存在改变语义的增强样本带来的影响,虽然确实可能会有一点影响.)同时,聚合增强视图可以产生更稳定的样本表示,减少表示中的随机性或噪音,突出原始数据的基本特征。
如图 4(a)所示。4(a) 对于每个时间序列样本 X𝑖 ,我们首先从包含𝐺种增强类型的数据增强库中随机生成两个不同的增强视图,即生成两组增强视图 X𝑖 = {X𝑖,1 , X𝑖,2 、 --- , X 𝑖,𝐺 } 和 ˜X 𝑖 = { ˜X 𝑖,1 , ˜X 𝑖,2 , --- , ˜X 𝑖,𝐺 },其中 X 𝑖,𝑘 和 ˜X 𝑖、 分别代表第 𝑖 个样本 X 𝑖 的两个增强视图,它们是由𝑘 -th 增强方法使用不同的随机参数得到的。然后,将增强视图 X 𝑖,𝑘 , ˜X 𝑖,𝑘 输入 TS 编码器 𝐹 TS (-) 以获得它们的高维潜在表示 r 𝑖,𝑘 , r˜ 𝑖,𝑘 。最后,我们使用各种增强视图的平均表示作为原型(有点平均值的意思)。X 𝑖 的原型表述为:
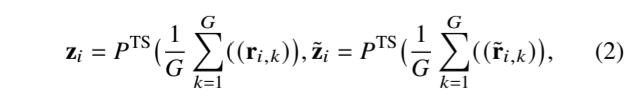 其中,z 𝑖 , z˜ 𝑖 ∈R 𝐽 和 𝐺 表示扩增的次数。
其中,z 𝑖 , z˜ 𝑖 ∈R 𝐽 和 𝐺 表示扩增的次数。
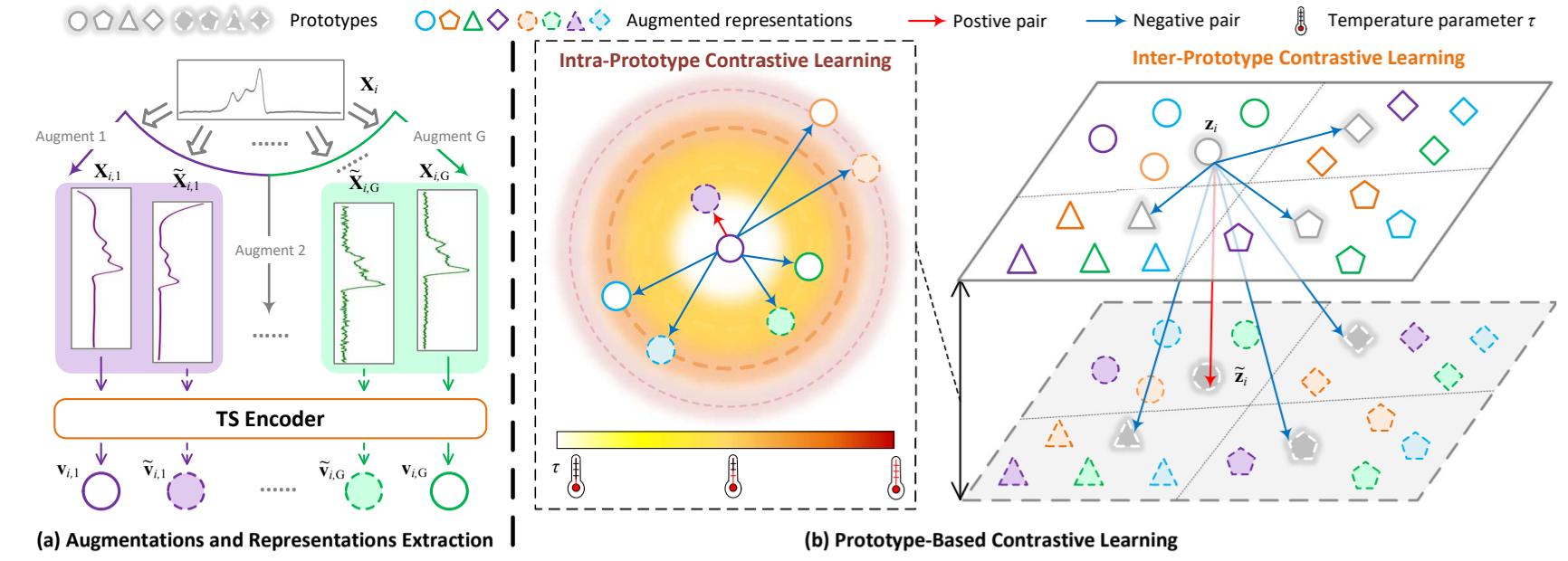
图 4:基于原型的对比学习概述。相同颜色和相同形状的实线和虚线代表在同一样本上进行相同增强后的两个增强视图。不同颜色表示不同的增强方法。不同的形状代表不同的样本。灰色形状表示每个样本的原型,每个样本生成两个原型。(a) 对时间序列数据进行 G 种类型的增强,每种方法应用两次以提取表征。(b) 基于原型的对比学习图解。原型内对比学习在同一样本及其增强中进行。色带表示不同增强体的表征之间的距离,从白色过渡到红色表示它们之间的距离增加,温度参数𝜏 相应减少。原型间的对比学习在不同的样本中进行。
一个增强视图的振幅与其他视图有明显不同,它可能会主导原型的表征分布。这种观点会严重影响原型的价值。理想情况下,原型应该平衡所有视图的表征,而不是被任何单一视图所支配。因此,在对比学习中,这需要额外的处理方法来防止单一视图的表征主导原型,确保每种视图都能做出公平的贡献。
2) 原型内对比损失: 为了实现不同增强视图在表征空间内的均匀分布,我们提出了带有自适应温度参数的原型内对比学习。我们使用温度参数𝜏 来控制对负样本的惩罚力度。具体来说,较低温度的对比损失会对负样本施加更大的惩罚,从而产生更多分离的表征。在样本内对比损失中,我们为每对负样本设计了不同的𝜏。
对于 X𝑖 来说,由相同的𝑘-th 增量 X𝑖,𝑘 和 ˜X𝑖,𝑘 生成的视图被视为一对正视图(如图 4(b) 中的紫色实线圆圈和紫色虚线圆圈)。由不同扩增(如 X 𝑖、𝑗 和 X 𝑖、𝑘)生成的视图被视为负对(如图 4(b) 中的紫色实心圆和其他颜色的圆)。然后,我们改变每个负对的𝜏,以控制不同增强视图在表示空间中的分离度。具体来说,对于距离较远的两个视图,我们会增加𝜏,使它们在表征空间中的表征更加相似(例如,紫色实心圆和蓝色圆)。反之,对于已经相似(距离较小)的视图,我们会减小𝜏,使它们在空间中的表现形式更易于区分(例如,紫色实心圆和绿色圆)。
为了得到每一对的𝜏,我们首先使用距离度量 𝐷 ( -, -) 来得到距离𝑑 ( 𝑗,𝑘)𝑖 = 𝐷(X 𝑖, 𝑗 、 X 𝑖, 𝑗 和 X 𝑖,𝑘 之间的 X 𝑖,𝑗 和 X 𝑖,𝑘 (用的什么距离度量的?),它们分别来自第 𝑗 次和第𝑘 次增强类型。然后,我们使用 softmax 函数将距离映射到𝜏。一对 X 𝑖, 𝑗 和 X 𝑖,𝑘 的 𝜏 公式为:
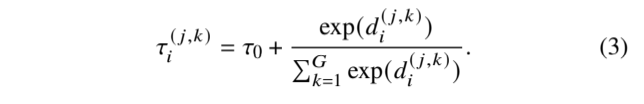 在原型中的多个增强视图之间进行对比学习,有助于防止振幅明显不同的视图主导原型,从而间接优化从视图到原型的聚合。为了输出用于对比学习的较低维度表示,r 𝑖,𝑘 和 r˜ 𝑖、 输入非线性投影𝑃 TS (-),输出低维表征 v𝑖,𝑘 = 𝑃 TS (r 𝑖,𝑘 ) 和 v˜ 𝑖,𝑘 = 𝑃 TS (r˜ 𝑖,𝑘 ) 。(这是表层意义上的,使用非线性投影用于生成低维度的表征,从底层和实验经验层面来讲,这样做会增强模型的效果,具体原理未知,其中一种解释是动量学角度,另一种就是单纯的实验经验,从实验结果的角度而言,加上非线性投影头,模型的效果会变好.)X 𝑖 的原型内对比损失定义为:
在原型中的多个增强视图之间进行对比学习,有助于防止振幅明显不同的视图主导原型,从而间接优化从视图到原型的聚合。为了输出用于对比学习的较低维度表示,r 𝑖,𝑘 和 r˜ 𝑖、 输入非线性投影𝑃 TS (-),输出低维表征 v𝑖,𝑘 = 𝑃 TS (r 𝑖,𝑘 ) 和 v˜ 𝑖,𝑘 = 𝑃 TS (r˜ 𝑖,𝑘 ) 。(这是表层意义上的,使用非线性投影用于生成低维度的表征,从底层和实验经验层面来讲,这样做会增强模型的效果,具体原理未知,其中一种解释是动量学角度,另一种就是单纯的实验经验,从实验结果的角度而言,加上非线性投影头,模型的效果会变好.)X 𝑖 的原型内对比损失定义为:
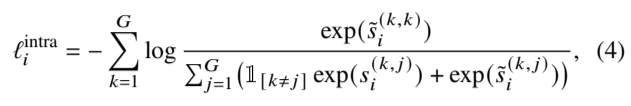 其中
其中![]() 并且
并且![]() 。在计算 𝜏 之前,我们将 𝑑 ( 𝑗,𝑗)𝑖 设为负无穷大,这样 𝜏 ( 𝑗,𝑗) 𝑖 = 𝜏 0,以确保正数对彼此接近。
。在计算 𝜏 之前,我们将 𝑑 ( 𝑗,𝑗)𝑖 设为负无穷大,这样 𝜏 ( 𝑗,𝑗) 𝑖 = 𝜏 0,以确保正数对彼此接近。
3) 原型间对比损失: 我们选择不同原型之间的正负对来识别样本的鉴别信息。这种鉴别信息能更好地捕捉样本之间的差异,从而显著提高下游任务的分类性能。第 𝑖 个样本、z 𝑖 和 z˜ 𝑖 将彼此视为正样本(如灰色实线圆和灰色虚线圆),而将批次中其他样本的原型视为负样本(如灰色圆和其他颜色的圆)。X 𝑖 的原型间对比损失定义如下:
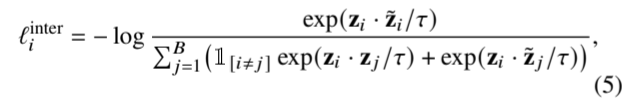 其中,𝐵 表示批量大小。
其中,𝐵 表示批量大小。
基于上述两个训练目标,我们的基于原型的对比学习方法能有效地利用各种增强方法来创建广义表征,从而提高下游任务的分类性能。基于原型的总体对比损失定义如下:
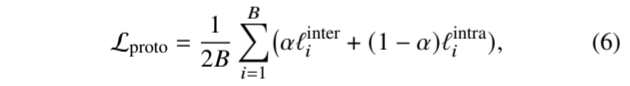 其中,𝛼 是超参数。
其中,𝛼 是超参数。
C. 序列-图像对比学习
从时间序列模式中获取数值模型,难以捕捉对类别识别至关重要的结构信息。来自不同领域的时间序列数据总是由线条或曲线段组成,因此,根据形状捕捉时间序列的结构信息比根据数值捕捉更直接。为了捕捉时间序列的结构信息,我们引入了图像模式,并提出了具有测地线混合策略的序列-图像对比学习,以同时捕捉数值和结构信息。
首先,我们将每个时间序列样本转换成图像。然后,时间序列样本和相应的图像被视为正对,而时间序列和同一批次中其他样本的图像被视为负对。朴素对比学习(The naive contrastive learning)建立了时间序列和图像之间的对应关系,但这种差异仍不足以区分不同的时间序列样本,因为在负样本中没有考虑时间序列的数字方面。因此,我们设计了一种测地线混合方法,以创建位于这两种模态子空间表征之间的混合表征。在对比学习中,将这些混合表征视为负值,以扩增所学表征的有效子空间,从而使样本更容易分类。(两种模态的表征空间向中间的某个潜在表征空间上靠近.)
1) 图像特征提取: 通过折线图将时间序列数据可视化,是将数字数据转化为图像模态的自然直觉。在折线图中,X 轴表示时间戳,Y 轴表示数值。我们使用符号 “*”来表示观察到的数据点,并用直线将它们连接起来。如图 3(a)所示,对于多元时间序列样本 X 𝑖 ,我们分别为每个变量绘制折线图,因为每个变量都有不同的刻度,表示为 Image(X 𝑖 ) 。我们将不同变量的图像标准化为相同的正方形大小。此外,我们还为不同的变量配备了不同的颜色,并将每个变量对应的子图像拼接成一幅图像。然后,我们使用图像编码器获得表示:![]() 。同时,我们通过 TS 编码器提取相应的表示
。同时,我们通过 TS 编码器提取相应的表示![]() 。
。
2) 序列-图像对比损失: 时间序列建模有助于捕捉数据的数字信息,而图像模态建模则提供结构信息。捕捉每个样本的不同模态之间的相似信息,可以在学习通用表征时提供每个模态的独特方面。因此,我们提出了一种序列-图像对比损失法,以最大限度地提高 TS 表示法与基于图像的对应表示法之间的相似性。它将输入样本与相应图像视为正对,将批次中其他样本生成的图像视为负对。(这是跨模态的对比学习吗?应该是的吧.)
由于不同模态的特点,时间序列和图像模态之间存在着不可比较的信息。例如,图像的对比度与时间序列数据的内在属性无关,这种信息不适合跨模态对比学习。因此,为了过滤掉不可比较的信息,我们对每种模态的表征进行非线性投影,让它们在训练过程中进行比较。通过序列-图像对比学习过滤(有点想知道实现细节,难不成是通过MLP直接过一下?这样就可以实现过滤操作吗?),我们可以从 r 𝑖 和 r I 𝑖 中获得更合适的时间序列表示 v 𝑖 和图像表示 u 𝑖。批次中第 i 个样本的序列-图像对比损失可表述为:
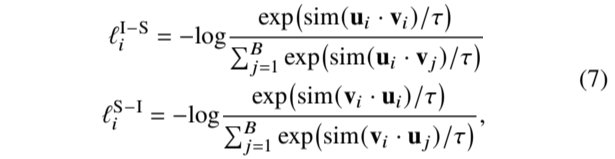 其中,ℓ I-S 𝑖 是 𝑖 次图像表征与一批(one batch)中所有 TS 表征的对比度,ℓ S-I 𝑖 是 𝑖 次 TS 表征与图像表征的对比度。朴素序列-图像对比损失定义为:
其中,ℓ I-S 𝑖 是 𝑖 次图像表征与一批(one batch)中所有 TS 表征的对比度,ℓ S-I 𝑖 是 𝑖 次 TS 表征与图像表征的对比度。朴素序列-图像对比损失定义为:
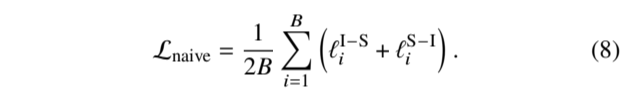 为此,需要对位于表示空间两个子部分的序列和图像表征进行对齐(是因为对齐了才方便做对比吗?不对齐会怎么样?)。
为此,需要对位于表示空间两个子部分的序列和图像表征进行对齐(是因为对齐了才方便做对比吗?不对齐会怎么样?)。
3) 测地线混合策略: 虽然序列和图像表征可以通过公式 8 中的对比学习进行对齐。过去的研究[45]表明,即使在训练有素的模型中,两种模态的表征也往往分别位于整个表征空间的两个子空间,如图 5(a)所示的图像子空间和序列子空间。这一现象意味着在这两个子空间之间存在着很大的未开发间隙。如果两种模态的表征出现在这些间隙中,则表明一种模态的表征更接近另一种模态的表征,因此更有可能包含另一种模态提供的信息,如图 5(b)所示的间隙。这促使我们设计出一种测地线混合策略,即:
![]()
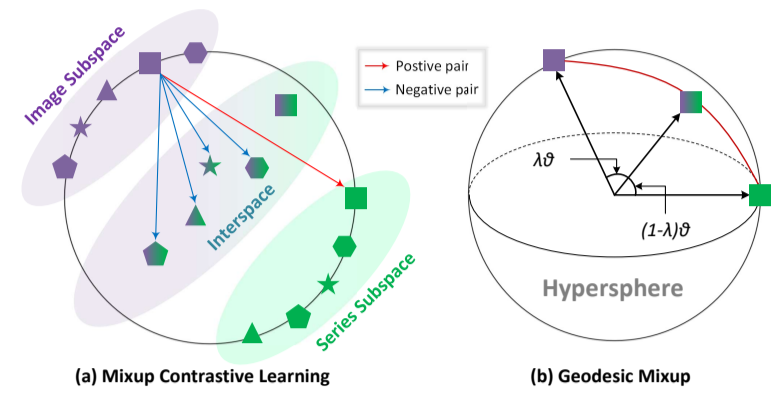
图 5:测地线混合策略和混合对比学习。(a) 混合对比学习示意图。各种绿色图形,如星星、三角形等,代表时间序列表示法,而紫色图形则表示相应的图像表示法。(b) 测地线混合图示。绿色和紫色方块分别代表超球面上的时间序列和图像表示。绿紫色正方形代表通过测地线混合产生的混合表示,可以看到混合表示仍保留在超球面上。
其中,𝜃 = cos -1 (u - v) 是图像表示法 u 和序列表示法 v 之间的角度,由测地线距离测量,如图 9(b) 中红色弧线所示。参数𝜆 ∼ Beta(𝛾, 𝛾)是一个随机系数,用于控制两个表征之间的混合比例,而𝛾是一个超参数。根据经验[46]-[48],在超球中限制序列和图像表征可确保学习到的混合表征𝑚 𝜆 (u, v) 同时包含时间序列的数值和结构信息。我们的测地线混合策略确保混合表征保持在两个表征之间的单位超球上,因为||𝑚 𝜆 (u, v)|| = 1。如图 5(a)所示,我们将这些混合表示视为负样本,这种负样本同时考虑了时间序列数据的数值和结构模式,从而区分出属于不同类别的时间序列。正样本保留了公式 8 中使用的原始序列图像损失,从而产生了新的测地线混合对比损失:
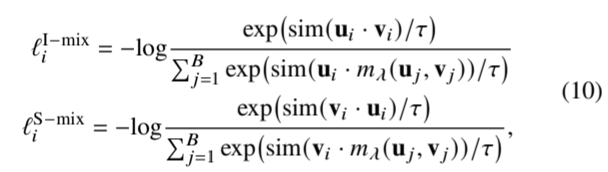 其中,ℓ I-mix 𝑖 是指在一次批量组合后,𝑖 次图像表征与所有表征的对比度;ℓ S-mix 𝑖 是指在一次批量组合后,𝑖 次时间序列表征与所有表征的对比度。测地线混合对比损失定义为:
其中,ℓ I-mix 𝑖 是指在一次批量组合后,𝑖 次图像表征与所有表征的对比度;ℓ S-mix 𝑖 是指在一次批量组合后,𝑖 次时间序列表征与所有表征的对比度。测地线混合对比损失定义为:
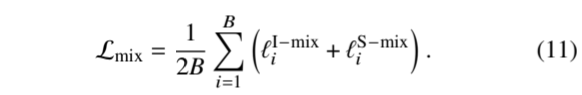 将这两种损失相加,就得到了序列-图像对比学习训练的综合损失:
将这两种损失相加,就得到了序列-图像对比学习训练的综合损失:
![]()
其中,𝛽是一个超参数。
(有罪,现在是2025年7月20日的15:38. 都放暑假了,哦,我是牛马,我没有暑假. 我开始补天坑了.)
(7月24日了,你把这篇论文结束了吧,别拖了,烦了.)
(坏,昨天有事,25日了,继续,今天结束.)
V. 实验
A. 实验设置
1) 数据集:
a) 预训练数据集:Monash 档案库 [49] 包含 19 个未标注数据集,其中 4 个为单变量数据集,15 个为多变量数据集。这些数据集涵盖多个领域,包含 24 至 4000 个观测值。
b) 目标数据集:UCR 档案库 [50] 包含 128 个不同领域的单变量数据集,这些数据集已标注对应的类别。UEA 档案库 [51] 包含 30 个多变量数据集。我们使用来自这两个档案库的158个数据集,以及以下数据集对AimTS在下游任务中的性能进行了评估:SleepEEG [52]、Epilepsy [53]、FD-B [54]、Gesture [55] 和 EMG [56]。每个数据集的训练集用于微调 AimTS 的预训练参数并训练分类器,随后在测试集上进行测试。
c) 少样本学习数据集:遵循 UniTS [9],我们在 6 个数据集上进行少样本学习。ECG200和StarLightCurves来自UCR档案库。Epilepsy、Handwriting、RacketSports和SelfRegulationSCP1来自UEA档案库。我们使用这6个下游数据集的训练集的5%、15%和20%对AimTS和其他基线模型进行微调,并分别在测试集上评估其性能。
2) 基线方法:我们在三个范式下将 AimTS 与 29 种基线方法进行比较。个案范式包括表示学习(如 TS-TCC [57]、TS2Vec [6]、Data2Vec [58])、时间序列分析方法(如 TEST [59]、PatchTST [60]、 TimesNet [5]),以及时间序列分类方法(如OS-CNN [61]、TapNet [62]、Rocket [4])。所有基线方法均在个案分析范式下进行训练。
单一来源泛化范式中的模型(例如TFC [7]、SimMTM [8]、SoftCLT [31])在分类任务中通常依赖于UEA和UCR之外的标注数据。这些方法通常在 SleepEEG 数据集 [52] 或癫痫数据集 [53] 上进行预训练,随后使用癫痫数据集 [53]、FD-B 数据集 [54]、手势数据集 [55] 和 EMG 数据集 [56] 的训练集进行微调,最后分别在各自的测试集上进行评估。由于不同方法受其预训练数据集的影响,统一评估较为困难,因此我们采用其论文中报告的最佳结果作为基线。多源适应基础模型可用于TSC。MOMENT [10]从4个任务特定的、广泛使用的公共仓库(包括UCR和UEA档案)中收集多时间序列进行多源预训练。UniTS [9] 在多个来源的 38 个数据集上进行预训练,包括来自 UEA 和 UCR 档案库的 20 个预测数据集和 18 个分类数据集。有关详细信息,请参阅 MOMENT [10] 和 UniTS [9]。我们使用完整的 UCR 和 UEA 档案库对其进行评估。
3) 实现细节: 对于预训练,我们使用PyTorch [63]实现AimTS,所有实验均在1块NVIDIA A800 80GB GPU上进行。我们使用Adam [64],初始学习率为7 × 10^(−3),随机种子为3407,批量大小为16,并采用StepLR方法实现学习率衰减的预训练。
预训练 2 个 epoch 后,可获得 TS 编码器的参数。我们将预训练模型通过完全微调 [65] 转移到每个下游任务,并训练一个 MLP 作为分类器。默认情况下,优化器使用 Adam,学习率为 0.001,随机种子为 3407。在获取时间序列表示时,我们采用通道独立性[60]、[66]对样本进行处理,分别对时间序列的每个维度进行编码。
4) 数据增强:遵循先前研究[13]、[36]、[37],我们选择5种数据增强方法,包括抖动、缩放、时间扭曲、切片和窗口扭曲。
5) 评估指标:遵循TS2Vec [6],我们使用多个被认为对评估分类器重要的指标,包括实现最高准确率的数据集数量(Num. Top-1)、平均准确率(Avg. ACC)[67]、平均排名(Avg. Rank)[68]以及关键差异(CD)图[68]。Num. Top-1 显示模型在多少个数据集上达到最高准确率,不包括多个方法并列第一的情况。Avg. ACC [67] 是多个数据集准确率的平均值,反映了模型的整体能力,数值越高表示性能越好。Avg. Rank 通过降低极端准确率值对单个数据集的影响,数值越低表示性能越好。CD 图通过统计检验方法更直观地反映不同模型之间的性能差异。通过水平线连接的模型在弗里德曼检验后不存在统计学差异。
B. 主要结果
1) 与逐个案例范式相比:为了说明AimTS学习到的表示可以推广到不同的分类任务,我们将它与最近提出的用于时间序列的表示学习方法进行比较,并在表I中报告了结果。此外,我们在图6中展示了所有数据集的Nemenyi检验的CD图(𝛼 = 0.05),表明AimTS在UCR档案库和UEA档案库中均实现了最佳的整体平均排名,且优于现有表示学习方法。值得注意的是,AimTS在UCR数据集上显著优于这些方法。
表I:在个案分析范式下与最先进表示学习方法的比较。
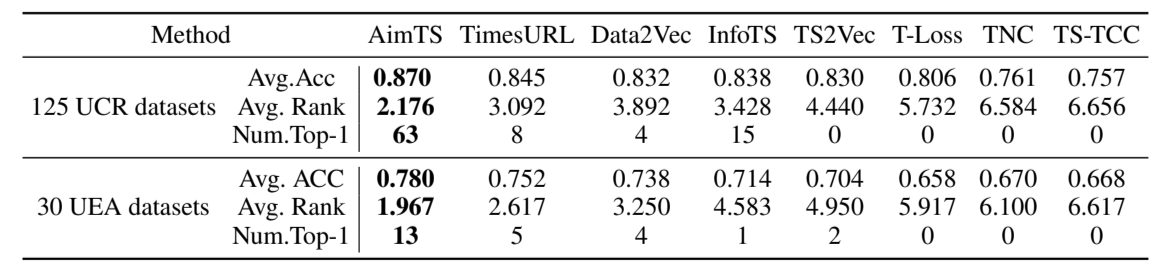

图6:在UCR和UEA数据集上,以95%置信水平表示的表示学习方法的CD图。
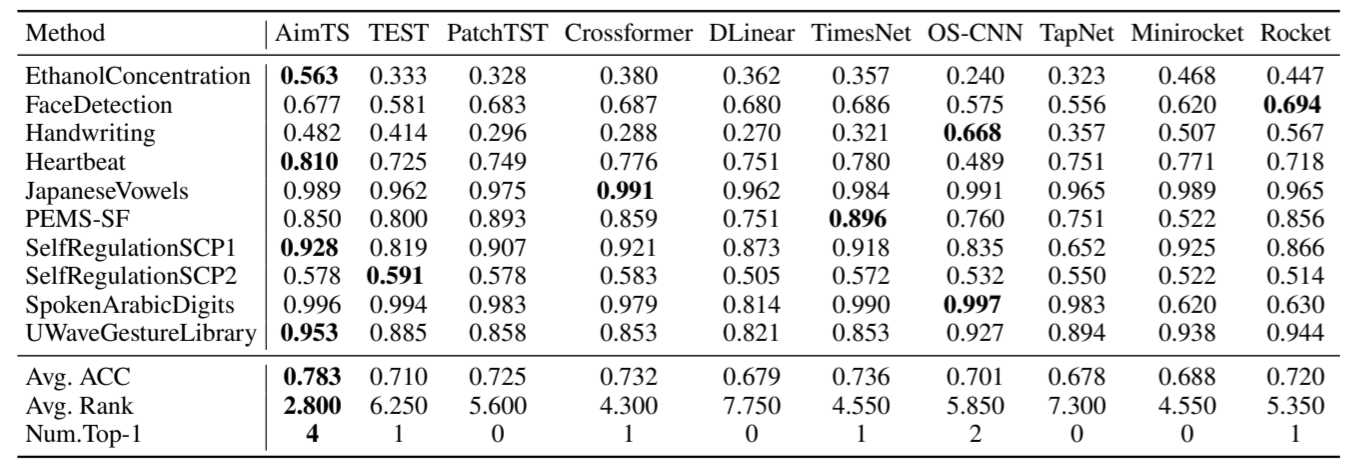
遵循TimesNet [5]的方法,我们在10个UEA数据集上进行了实验,以比较AimTS与现有基于案例的监督方法的性能。尽管Num. Top-1在一定程度上可以反映模型的性能,但如果它在这一单一指标上表现优异,但在平均指标上却表现不佳,这表明该方法可能仅在特定数据集上有效。在10个数据集上,AimTS的Avg. AimTS 的 ACC 为 0.764,比排名第二的 TimesNet 准确率 0.736 高出 2.8%。此外,AimTS 在 10 个数据集上的 Avg. Rank 为 2.8,比排名第二的 Crossformer(Avg. Rank 为 4.3)高出 1.5。这些平均指标反映了我们的模型在不同数据集上的通用能力。
表II:在10个UEA数据集上,基于案例分析范式与其他最先进方法的比较。
2) 与单源泛化范式相比:为进一步验证 AimTS 在多源预训练中学习的表示的泛化能力,我们在 4 个数据集上将 AimTS 与单源泛化范式中的现有方法进行了比较,结果如表 III 所示。由于预训练数据集与微调数据集之间的差异,基线方法在大多数任务中表现不佳。AimTS 在大多数数据集上均优于其他基线方法。值得注意的是,对于FDB数据集,AimTS显著超越了之前的最先进方法SoftCLT,准确率达到1。这些结果表明,AimTS在多源预训练过程中有效捕获了有价值的知识,并在各种下游任务中实现了强大的分类性能。
表III:与单源泛化范式中的最先进方法相比。

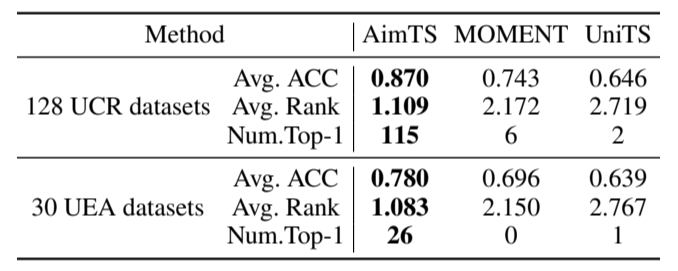
3) 与多源适应范式相比:为了全面比较各种范式,我们还将时间序列基础模型纳入评估。如表IV所示,AimTS在UCR档案库的128个数据集中有115个数据集以及UEA档案库的30个数据集中有26个数据集上取得了最佳结果。此外,与第二好的基线相比,它平均提高了128个UCR数据集的分类准确率12.7%和30个UEA数据集的分类准确率8.4%。
表IV:与多源适应范式中的最先进方法相比。
与三个范式中的多个基线模型进行全面比较,进一步验证了AimTS的有效性。
C. 少样本学习
作为预训练模型,AimTS 展现出强大的少样本学习能力。本节中,我们将 AimTS 与其他具备少样本学习能力的预训练模型在六个下游数据集上进行对比,包括 UniTS [9] 和 MOMENT [10]。各数据集的详细结果见表 V。
表V:在6个下游数据集上的少样本学习。
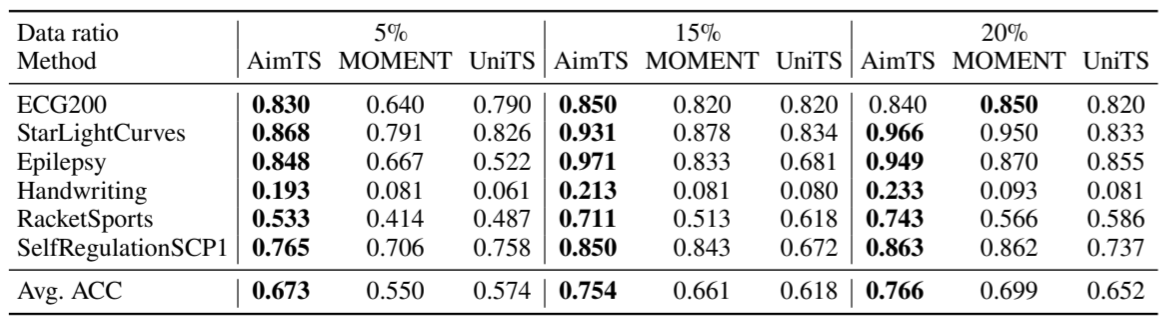
与其他基础模型相比,AimTS仅使用 5% 的数据即可实现卓越性能,其分类准确率几乎与其他基线模型使用 15% 数据时达到的准确率相当。此外,AimTS 在所有数据比例下均超越所有基线模型,在每种情况下均实现最高平均准确率。这些实验结果凸显了 AimTS 卓越的泛化能力,即使在数据匮乏的条件下仍能保持优异性能。
D. 消融研究
为验证AimTS中各组件的有效性,我们根据论文中的关键贡献将其分解为四个部分。采用统一的实验设置:在Monash数据集上进行预训练,随后在128个下游UCR数据集上进行测试。结果如表VI所示。
表VI:AimTS在128个UCR数据集上的消融研究。

1) 跨原型对比学习的效果:我们在表VI中首先验证了跨原型对比学习的有效性。在此实验中,原型通过简单地对不同增强方式的表示进行平均获得,然后在这些原型之间应用对比学习。结果表明,该方法取得了显著的性能,甚至超越了许多基线,这证明了使用多样化增强的必要性以及原型使用的有效性。
2) 原型基对比学习的效果:我们采用完整的两级原型基对比学习进行训练,该方法同时包含跨原型对比损失和原型内对比损失。结果如表VI的第二行所示。与仅使用跨原型对比学习相比,完整方法的准确率达到0.858,证实了调整增强表示分布的必要性。
3) 基于朴素序列-图像的对比学习效果:为验证图像模态在AimTS中的关键作用,我们仅使用序列图像对比损失进行模型训练,在UCR上实现0.858的准确率,如表VI所示。该结果也超越了大多数基线,进一步证明了我们方法的有效性。
4) 测地线混合策略的影响:为验证测地线序列-图像混合策略的有效性,我们使用完整的序列-图像对比损失进行预训练,该损失结合了朴素的序列-图像对比损失和测地线混合对比损失。如表VI所示,将混合样本纳入对比学习进一步提升了模型性能至0.865。
E. 参数研究
为了分析本文提出的损失函数对模型性能的贡献,我们对每个损失函数相关的权重超参数进行了实验。此外,在时间序列图像对比度中,混淆系数 𝜆 来自贝塔分布 Beta ( 𝛾, 𝛾 ),其中 𝛾 是超参数。我们探讨了 𝛾 对整体模型性能的影响。我们从UCR数据集选取AllGestureWiimoteX、AllGestureWiimoteY和AllGestureWiimoteZ数据集进行实验。AimTS对这些参数的敏感性基于这些数据集的平均准确率进行评估。
1) 𝛼的影响:我们考察基于原型对比学习中,原型内对比损失的权重𝛼。在此实验中,𝛽 = 0.1且𝛾 = 0.1。我们在预训练过程中将𝛼在0.9、0.8、0.7和0.6之间变化,并评估其在下游数据集上的性能。如图7(a)所示,𝛼对AimTS的性能影响有限。当𝛼 = 0.7时,AimTS达到最佳准确率,而当𝛼 = 0.6时性能略有下降。值得注意的是,由于 intra-prototype 对比学习的目的是精化原型,我们未测试小于0.5的值。

图7:(a)(b) 不同参数下AimTS的运行结果。 (c)(d) StarLightCurves上GPU内存使用量及效率对比。
2) 𝛽 的影响:同样,我们探讨了 𝛽 对序列图像对比学习中混淆对比损失的影响。我们固定参数 𝛼 = 0.1,𝛾 = 0.1。𝛽 分别设置为 0.9、0.8、0.7 和 0.6,结果如图 7(a) 所示。为了确保时间序列与图像表示之间的准确对应关系,序列-图像对比损失被赋予了更高的权重。结果表明𝛽的影响微乎其微,当𝛽 = 0.9时性能最佳。
3) 𝛾的影响:在混合对比学习中,混淆系数𝜆 ∼ Beta(𝛾, 𝛾)是一个随机系数,用于控制图像与序列模态表示的比例。𝛾影响贝塔分布的形状,通常在0到1之间。为了调查不同形式的贝塔分布是否影响混淆策略,我们通过改变𝛾进行实验,如图7(b)所示。当参数𝛼 = 0.1、𝛽 = 0.1时,AimTS的性能在𝛾设置为0.1、0.3、0.5和0.7时保持稳定,这表明该混淆策略对超参数不敏感,是一种可泛化的方法。
F. 内存使用与效率
我们对比了AimTS与5个基线方法在StarLightCurves数据集上的GPU内存使用量及效率。对于AimTS、MOMENT [10]和UniTS [9],我们对预训练参数进行微调,并在数据集的训练集上训练分类器。其他基线模型的参数直接使用数据集的训练集进行训练。为确保公平性,所有方法的批量大小均设置为8,训练 epoch 数为10。
图7(c)展示了所有方法在微调或训练过程中达到的最大GPU内存使用量。图7(d)报告了所有方法的微调或训练总时间以及推理时间。在微调和推理过程中,AimTS仅需927 MB的GPU内存,比第二基线TimesNet低14.72%。除了更低的内存需求外,AimTS还实现了75秒的总时间,比其他模型更快。总之,AimTS实现了更高的效率,在不牺牲性能的情况下,显著减少了内存和时间需求。
G. 可扩展性研究
为了评估AimTS的可扩展性,我们分析了三个关键因素对GPU内存使用量以及微调和测试总时间的影响:数据集大小、时间序列长度和模型参数。与其他时间序列任务不同,在时间序列分类中,时间序列的长度不会影响模型参数,而是影响每个批次处理的数据量。因此,时间序列长度被作为一个独立的因素进行分析。所有实验均在 SleepEEG 数据集上进行,除研究对象外,所有设置保持一致。对于每个因素,我们通过线图进行了详细分析,如图8(a)(b)(c)所示。
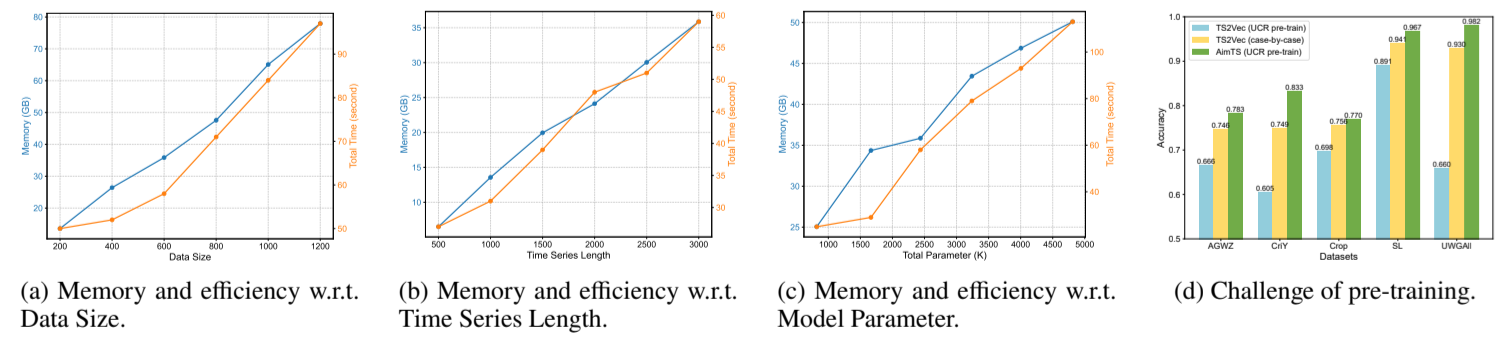
图8:(a)(b)(c) SleepEEG数据集上的可扩展性比较。(d) TS2Vec在逐个案例设置中的结果,TS2Vec使用多领域数据集预训练,以及AimTS。
1) 数据规模:为评估数据规模对GPU内存使用量和总运行时间的影响,我们固定时间序列长度为3000、模型参数为2437K,同时增加用于微调的数据量。如图8(a)所示,GPU内存使用量和运行时间与微调数据集的大小呈线性关系。随着数据规模的增长,GPU内存使用量稳步增加,反映了对更大批量数据存储的需求。同样,由于处理更大数据集所需的迭代次数增加,总训练时间也以相似的比例增长。
2) 时间序列长度:在此实验中,微调数据集大小为600,总参数配置为2437K。我们记录了在分类不同长度时间序列时,AimTS微调所需的最大GPU内存使用量和总时间。如图8(b)所示,GPU内存使用量和训练时间均随时间序列长度的增加呈线性增长。这种行为是预期的,因为更长的时间序列需要相应的计算资源和内存分配。重要的是,线性扩展突显了AimTS在处理长时间序列时的计算效率,使其非常适合具有长时间序列长度的下游任务。
3) 模型参数:在分析模型参数的影响时,我们将数据规模固定为600,时间序列长度固定为3000。AimTS对参数规模的可扩展性如图8(c)所示。如预期,内存使用量和运行时间均随参数数量增加而增长,且增长率较为温和。
H. 附加分析
1) 多源预训练的挑战:由于数据来自不同领域,语义差异给预训练带来了挑战。本节通过实验展示了先前方法难以处理此类问题,而AimTS成功克服了这些挑战。TSVec 用作基线,TS2Vec 和 AimTS 在 UCR 数据集的训练集上进行预训练,并在 5 个下游数据集上进行微调。如图 8(d) 所示,当使用多源预训练和微调范式时,TS2Vec 的性能低于逐个案例范式,这表明多源预训练导致了负面迁移。AimTS在使用多源数据集时,在下游任务中表现卓越,展现出其强大的泛化能力。
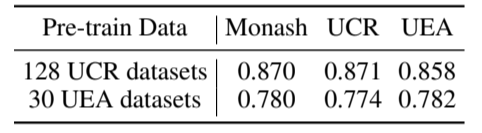
2) 不同预训练数据集的比较:为验证AimTS能否通过在不同多源数据集上进行预训练获得泛化表示,我们对多个数据集进行了预训练。使用UCR数据集对AimTS进行预训练表明,我们将来自128个数据集的训练样本合并为一个预训练数据集。我们使用UEA档案中的训练数据对AimTS进行预训练。表VII比较了使用三个多源数据集预训练的AimTS的平均准确率。这一结果证实了AimTS能够在不同多源数据集上获得泛化表示。此外,结果表明,当AimTS在预训练过程中接触过这些数据集时,其在下游数据集上的性能更优,这进一步印证了引言中提到的Paradigm 3作为更直观方法的有效性。
表VII:在不同数据集上预训练的AimTS。
3) 数据增强引发的语义变化案例研究:为展示基于原型的对比学习的动机,我们进行了一项案例研究,以展示数据增强可能改变数据语义的现象。图 9 分别展示了 (a) StarLightCurves 数据集中的原始时间序列数据片段,(b) 通过切片增强 [69] 技术(随机裁剪输入时间序列并线性插值恢复至原始长度)生成的增强数据,以及 (c) 通过多种增强技术生成的原型。我们使用训练数据集将TS2Vec训练为分类器,并测试时间序列数据是否仍对应原始标签,从而评估增强是否影响分类准确性。每个子图右上角的气泡图表示分类器的准确性。
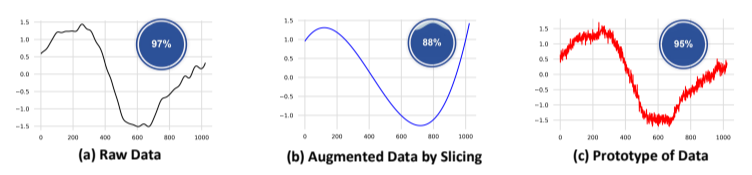
图9:使用不同数据进行测试。
分类器在原始测试数据集上的准确率为0.97,如图9(a)所示。当在通过切片增强的测试数据集上进行测试时,准确率为0.88,如图9(b)所示。这表明切片增强改变了许多测试数据样本的语义,导致它们不再与原始标签对应。在测试数据原型上测试时,准确率为0.95,如图9(c)所示,与原始数据集的准确率接近。此外,在图9的三个部分中,分类器正确分类了原始数据和数据原型,但错误分类了通过切片增强的数据。这表明某些数据增强方法可能会改变语义信息,而使用原型有助于保持语义一致性。
VI. 结论
本文提出了一种名为AimTS的多源预训练框架,旨在学习通用表示并提升各类下游时间序列分类任务的性能。AimTS提出了一种基于原型的两级对比学习方法,能够有效利用多种数据增强技术,同时避免多源预训练中因数据增强引起的语义混淆。考虑到时间序列模态内的数据增强不足以解决分布偏移引起的分类问题,AimTS引入图像模态以捕获时间序列数据的结构信息。实验表明,通过AimTS预训练的表示可用于多种分类任务的微调,其性能优于现有最先进方法,同时在内存使用和计算成本方面也展现出高效性。
(gdx,现在7月25日的22:10,写完了,无语......)
(明天把最近着急要看的一篇综述看了好吧,算我拜托你了,你学一会,等肠胃炎好了买奶茶喝好不好,嗯,好的.(自我劝学版))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号